
Πίνακας περιεχομένων
Σε αυτό το σεμινάριο, θα μάθετε πώς να χρησιμοποιείτε κανονικές εκφράσεις στο Excel για να βρίσκετε και να εξάγετε υποσύνολα που ταιριάζουν σε ένα δεδομένο μοτίβο.
Το Microsoft Excel παρέχει μια σειρά από συναρτήσεις για την εξαγωγή κειμένου από τα κελιά. Αυτές οι συναρτήσεις μπορούν να αντιμετωπίσουν τις περισσότερες από τις προκλήσεις εξαγωγής συμβολοσειρών στα φύλλα εργασίας σας. Τις περισσότερες, αλλά όχι όλες. Όταν οι συναρτήσεις κειμένου σκοντάφτουν, οι κανονικές εκφράσεις έρχονται να σας σώσουν. Περιμένετε... το Excel δεν έχει συναρτήσεις RegEx! Σωστά, δεν έχει ενσωματωμένες συναρτήσεις. Αλλά δεν υπάρχει τίποτα που να σας εμποδίζει να χρησιμοποιήσετε τις δικές σας :)
Συνάρτηση Regex του Excel VBA για την εξαγωγή συμβολοσειρών
Για να προσθέσετε μια προσαρμοσμένη λειτουργία Regex Extract στο Excel σας, επικολλήστε τον ακόλουθο κώδικα στον επεξεργαστή VBA. Για να ενεργοποιήσουμε τις κανονικές εκφράσεις στην VBA, χρησιμοποιούμε το ενσωματωμένο αντικείμενο RegExp της Microsoft.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionΑν έχετε μικρή εμπειρία με το VBA, ένας οδηγός χρήστη βήμα προς βήμα μπορεί να αποδειχθεί χρήσιμος: Πώς να εισάγετε κώδικα VBA στο Excel.
Σημείωση. Για να λειτουργήσει η λειτουργία, βεβαιωθείτε ότι έχετε αποθηκεύσει το αρχείο σας ως βιβλίο εργασίας με δυνατότητα μακροεντολών (.xlsm).
Σύνταξη RegExpExtract
Το RegExpExtract αναζητά μια συμβολοσειρά εισόδου για τιμές που ταιριάζουν με μια κανονική έκφραση και εξάγει μία ή όλες τις αντιστοιχίες.
Η συνάρτηση έχει την ακόλουθη σύνταξη:
RegExpExtract(text, pattern, [instance_num], [match_case])Πού:
- Κείμενο (υποχρεωτικό) - η συμβολοσειρά κειμένου για αναζήτηση.
- Μοτίβο (υποχρεωτικό) - η κανονική έκφραση που πρέπει να ταιριάζει. Όταν παρέχεται απευθείας σε έναν τύπο, το μοτίβο πρέπει να περικλείεται σε διπλά εισαγωγικά.
- Instance_num (προαιρετικό) - ένας αύξων αριθμός που υποδεικνύει ποια περίπτωση θα εξαχθεί. Αν παραλειφθεί, επιστρέφει όλες τις αντιστοιχίες που βρέθηκαν (προεπιλογή).
- Match_case (προαιρετικό) - καθορίζει εάν θα γίνεται αντιστοίχιση ή αγνόηση της πεζότητας του κειμένου. Εάν TRUE ή παραλείπεται (προεπιλογή), γίνεται αντιστοίχιση με ευαισθησία στη πεζότητα- εάν FALSE - χωρίς ευαισθησία στη πεζότητα.
Η λειτουργία λειτουργεί σε όλες τις εκδόσεις του Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 και Excel 2010.
4 πράγματα που πρέπει να γνωρίζετε για το RegExpExtract
Για να χρησιμοποιήσετε αποτελεσματικά τη συνάρτηση στο Excel σας, υπάρχουν μερικά σημαντικά πράγματα που πρέπει να προσέξετε:
- Από προεπιλογή, η συνάρτηση επιστρέφει όλοι οι αγώνες που βρέθηκαν σε γειτονικά κελιά, όπως φαίνεται σε αυτό το παράδειγμα. Για να λάβετε μια συγκεκριμένη εμφάνιση, δώστε έναν αντίστοιχο αριθμό στην εντολή instance_num επιχείρημα.
- Από προεπιλογή, η συνάρτηση είναι case-sensitive Για αντιστοίχιση χωρίς ευαισθησία στη πεζότητα, ορίστε το match_case Λόγω των περιορισμών της VBA, η κατασκευή (?i) που δεν λαμβάνει υπόψη την πεζότητα δεν θα λειτουργήσει.
- Εάν ένα δεν βρέθηκε έγκυρο μοτίβο , η συνάρτηση δεν επιστρέφει τίποτα (κενή συμβολοσειρά).
- Εάν η το μοτίβο είναι άκυρο , εμφανίζεται σφάλμα #VALUE!
Πριν αρχίσετε να χρησιμοποιείτε αυτή την προσαρμοσμένη συνάρτηση στα φύλλα εργασίας σας, πρέπει να καταλάβετε τι μπορεί να κάνει, σωστά; Τα παρακάτω παραδείγματα καλύπτουν μερικές κοινές περιπτώσεις χρήσης και εξηγούν γιατί η συμπεριφορά μπορεί να διαφέρει στο Dynamic Array Excel (Microsoft 365 και Excel 2021) και στο παραδοσιακό Excel (2019 και παλαιότερες εκδόσεις).
Σημείωση. Τα παραδείγματα των out regex είναι γραμμένα για απλά σύνολα δεδομένων fairy. Δεν μπορούμε να εγγυηθούμε ότι θα λειτουργούν άψογα στα πραγματικά σας φύλλα εργασίας. Όσοι έχουν εμπειρία με τις regex θα συμφωνήσουν ότι η συγγραφή κανονικών εκφράσεων είναι ένας ατέλειωτος δρόμος προς την τελειότητα - σχεδόν πάντα υπάρχει ένας τρόπος να την κάνετε πιο κομψή ή ικανή να χειριστεί ένα ευρύτερο φάσμα δεδομένων εισόδου.
Regex για την εξαγωγή αριθμού από συμβολοσειρά
Ακολουθώντας το βασικό αξίωμα της διδασκαλίας "από το απλό στο σύνθετο", θα ξεκινήσουμε με μια πολύ απλή περίπτωση: εξαγωγή αριθμού από συμβολοσειρά.
Το πρώτο πράγμα που πρέπει να αποφασίσετε είναι ποιον αριθμό θα ανακτήσετε: τον πρώτο, τον τελευταίο, συγκεκριμένο περιστατικό ή όλους τους αριθμούς.
Απόσπασμα πρώτου αριθμού
Δεδομένου ότι \d σημαίνει οποιοδήποτε ψηφίο από το 0 έως το 9 και + σημαίνει μία ή περισσότερες φορές, η κανονική μας έκφραση έχει την εξής μορφή:
Μοτίβο : \d+
Ορίστε instance_num στο 1 και θα έχετε το επιθυμητό αποτέλεσμα:
=RegExpExtract(A5, "\d+", 1)
Όπου Α5 είναι η αρχική συμβολοσειρά.
Για ευκολία, μπορείτε να εισαγάγετε το μοτίβο σε ένα προκαθορισμένο κελί ($A$2 ) και να κλειδώσετε τη διεύθυνσή του με το σύμβολο $:
=RegExpExtract(A5, $A$2, 1) 
Λάβετε τον τελευταίο αριθμό
Για να εξαγάγετε τον τελευταίο αριθμό σε μια συμβολοσειρά, εδώ είναι το μοτίβο που πρέπει να χρησιμοποιήσετε:
Μοτίβο : (\d+)(?!.*\d)
Μεταφρασμένο σε ανθρώπινη γλώσσα, λέει: βρείτε έναν αριθμό που δεν ακολουθείται (πουθενά, όχι μόνο αμέσως) από κανέναν άλλο αριθμό. Για να το εκφράσουμε αυτό, χρησιμοποιούμε αρνητικό lookahead (?!.*\d), που σημαίνει ότι στα δεξιά του μοτίβου δεν πρέπει να υπάρχει κανένα άλλο ψηφίο (\d) ανεξάρτητα από το πόσοι άλλοι χαρακτήρες βρίσκονται πριν από αυτό.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Συμβουλές:
- Για να πάρετε ένα συγκεκριμένο περιστατικό , χρησιμοποιήστε \d+ για μοτίβο και έναν κατάλληλο σειριακό αριθμό για instance_num .
- Ο τύπος για την εξαγωγή όλοι οι αριθμοί συζητείται στο επόμενο παράδειγμα.
Regex για την εξαγωγή όλων των αντιστοιχιών
Προχωρώντας το παράδειγμά μας λίγο παραπέρα, ας υποθέσουμε ότι θέλετε να πάρετε όλους τους αριθμούς από μια συμβολοσειρά, όχι μόνο έναν.
Όπως ίσως θυμάστε, ο αριθμός των εξαγόμενων αντιστοιχιών ελέγχεται από την προαιρετική επιλογή instance_num Η προεπιλογή είναι όλες οι αντιστοιχίες, οπότε απλά παραλείπετε αυτή την παράμετρο:
=RegExpExtract(A2, "\d+")
Ο τύπος λειτουργεί άψογα για ένα μόνο κελί, αλλά η συμπεριφορά διαφέρει στις εκδόσεις του Excel με δυναμική συστοιχία και στις μη δυναμικές εκδόσεις.
Excel 365 και Excel 2021
Λόγω της υποστήριξης δυναμικών πινάκων, ένας κανονικός τύπος διαχέεται αυτόματα σε όσα κελιά απαιτούνται για την εμφάνιση όλων των υπολογισμένων αποτελεσμάτων. Όσον αφορά το Excel, αυτό ονομάζεται διαχεόμενη περιοχή: 
Excel 2019 και χαμηλότερα
Στο προ-δυναμικό Excel, ο παραπάνω τύπος θα επέστρεφε μόνο μία αντιστοιχία. Για να λάβετε πολλαπλές αντιστοιχίες, πρέπει να τον μετατρέψετε σε τύπο συστοιχίας. Για το σκοπό αυτό, επιλέξτε μια περιοχή κελιών, πληκτρολογήστε τον τύπο και πατήστε Ctrl + Shift + Enter για να τον ολοκληρώσετε.
Ένα μειονέκτημα αυτής της προσέγγισης είναι ένα σωρό λάθη #N/A που εμφανίζονται σε "επιπλέον κελιά". Δυστυχώς, δεν μπορεί να γίνει τίποτα γι' αυτό (ούτε το IFERROR ούτε το IFNA μπορούν να το διορθώσουν, δυστυχώς). 
Εξαγωγή όλων των αντιστοιχιών σε ένα κελί
Όταν επεξεργάζεστε μια στήλη δεδομένων, η παραπάνω προσέγγιση προφανώς δεν θα λειτουργήσει. Σε αυτή την περίπτωση, μια ιδανική λύση θα ήταν η επιστροφή όλων των αντιστοιχιών σε ένα μόνο κελί. Για να γίνει αυτό, σερβίρετε τα αποτελέσματα της RegExpExtract στη συνάρτηση TEXTJOIN και διαχωρίστε τα με όποιο διαχωριστικό θέλετε, ας πούμε ένα κόμμα και ένα κενό:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Σημείωση: Επειδή η λειτουργία TEXTJOIN είναι διαθέσιμη μόνο στο Excel για το Microsoft 365, το Excel 2021 και το Excel 2019, ο τύπος δεν θα λειτουργήσει σε παλαιότερες εκδόσεις.
Regex για την εξαγωγή κειμένου από συμβολοσειρά
Η εξαγωγή κειμένου από μια αλφαριθμητική συμβολοσειρά είναι μια αρκετά δύσκολη εργασία στο Excel. Με την regex, γίνεται πανεύκολη. Απλώς χρησιμοποιήστε μια αρνητική κλάση για να ταιριάξετε με οτιδήποτε δεν είναι ψηφίο.
Μοτίβο : [^\d]+
Για να λάβετε υποσύνολα σε μεμονωμένα κελιά (εύρος διαρροής), ο τύπος είναι:
=RegExpExtract(A5, "[^\d]+") 
Για να εξάγετε όλες τις αντιστοιχίες σε ένα κελί, τοποθετήστε τη συνάρτηση RegExpExtract στο TEXTJOIN ως εξής:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex για την εξαγωγή διεύθυνσης email από συμβολοσειρά
Για να ανασύρετε μια διεύθυνση ηλεκτρονικού ταχυδρομείου από μια συμβολοσειρά που περιέχει πολλές διαφορετικές πληροφορίες, γράψτε μια κανονική έκφραση που αναπαράγει τη δομή της διεύθυνσης ηλεκτρονικού ταχυδρομείου.
Μοτίβο : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Αν αναλύσουμε αυτό το regex, θα δούμε τι έχουμε:
- [\w\.\-]+ είναι ένα όνομα χρήστη που μπορεί να περιλαμβάνει 1 ή περισσότερους αλφαριθμητικούς χαρακτήρες, υπογράμμιση, τελείες και παύλες.
- @ σύμβολο
- [A-Za-z0-9\.\-]+ είναι ένα όνομα τομέα που αποτελείται από: κεφαλαία και πεζά γράμματα, ψηφία, παύλες και τελείες (σε περίπτωση υποτομέων). Οι υποκορισμοί δεν επιτρέπονται εδώ, επομένως χρησιμοποιούνται 3 διαφορετικά σύνολα χαρακτήρων (όπως A-Z a-z και 0-9) αντί του \w που ταιριάζει με οποιοδήποτε γράμμα, ψηφίο ή υποκοριστικό.
- \.[A-Za-z]{2,24} είναι ένας τομέας ανωτάτου επιπέδου. Αποτελείται από μια τελεία ακολουθούμενη από κεφαλαία και πεζά γράμματα. Οι περισσότεροι τομείς ανωτάτου επιπέδου έχουν μήκος 3 γραμμάτων (π.χ. .com .org, .edu κ.λπ.), αλλά θεωρητικά μπορεί να περιέχει από 2 έως 24 γράμματα (το μεγαλύτερο εγγεγραμμένο TLD).
Υποθέτοντας ότι η συμβολοσειρά βρίσκεται στο A5 και το μοτίβο στο A2, ο τύπος για την εξαγωγή μιας διεύθυνσης ηλεκτρονικού ταχυδρομείου είναι:
=RegExpExtract(A5, $A$2) 
Regex για να εξαγάγετε domain από email
Όταν πρόκειται για την εξαγωγή του τομέα ηλεκτρονικού ταχυδρομείου, η πρώτη σκέψη που έρχεται στο μυαλό είναι η χρήση μιας ομάδας σύλληψης για την εύρεση κειμένου που ακολουθεί αμέσως μετά τον χαρακτήρα @.
Μοτίβο : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Δώστε το στη συνάρτηση RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Και θα έχετε αυτό το αποτέλεσμα: 
Με τις κλασικές κανονικές εκφράσεις, οτιδήποτε βρίσκεται εκτός μιας ομάδας σύλληψης δεν περιλαμβάνεται στην εξαγωγή. Κανείς δεν γνωρίζει γιατί η VBA RegEx λειτουργεί διαφορετικά και συλλαμβάνει και το "@". Για να απαλλαγείτε από αυτό, μπορείτε να αφαιρέσετε τον πρώτο χαρακτήρα από το αποτέλεσμα αντικαθιστώντας τον με μια κενή συμβολοσειρά.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Κανονική έκφραση για την εξαγωγή αριθμών τηλεφώνου
Οι τηλεφωνικοί αριθμοί μπορούν να γραφούν με πολλούς διαφορετικούς τρόπους, γι' αυτό και είναι σχεδόν αδύνατο να βρεθεί μια λύση που να λειτουργεί υπό όλες τις συνθήκες. Παρ' όλα αυτά, μπορείτε να καταγράψετε όλες τις μορφές που χρησιμοποιούνται στο σύνολο δεδομένων σας και να προσπαθήσετε να τις αντιστοιχίσετε.
Για αυτό το παράδειγμα, θα δημιουργήσουμε ένα regex που θα εξάγει αριθμούς τηλεφώνου σε οποιαδήποτε από αυτές τις μορφές:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Μοτίβο : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Το πρώτο μέρος \(?\d{3} αντιστοιχεί σε μηδέν ή μία ανοιγόμενη παρένθεση ακολουθούμενη από τρία ψηφία d{3}.
- Το μέρος [-\. \)]* σημαίνει οποιονδήποτε χαρακτήρα μέσα σε αγκύλες που εμφανίζεται 0 ή περισσότερες φορές: παύλα, τελεία, κενό ή κλειστή παρένθεση.
- Στη συνέχεια, έχουμε και πάλι τρία ψηφία d{3} ακολουθούμενα από οποιαδήποτε παύλα, τελεία ή κενό [-\. ]; που εμφανίζεται 0 ή 1 φορά.
- Μετά από αυτό, υπάρχει μια ομάδα τεσσάρων ψηφίων \d{4}.
- Τέλος, υπάρχει μια λέξη όριο \b που ορίζει ότι ένας τηλεφωνικός αριθμός που αναζητούμε δεν μπορεί να είναι μέρος ενός μεγαλύτερου αριθμού.
Η πλήρης φόρμουλα έχει αυτή τη μορφή:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Λάβετε υπόψη ότι η παραπάνω regex μπορεί να επιστρέψει μερικά ψευδώς θετικά αποτελέσματα όπως 123) 456 7899 ή (123 456 7899. Η παρακάτω έκδοση διορθώνει αυτά τα προβλήματα. Ωστόσο, αυτή η σύνταξη λειτουργεί μόνο στις συναρτήσεις RegExp της VBA, όχι στις κλασικές κανονικές εκφράσεις.
Μοτίβο : (\(\d{3}\)
Regex για την εξαγωγή ημερομηνίας από συμβολοσειρά
Μια κανονική έκφραση για την εξαγωγή μιας ημερομηνίας εξαρτάται από τη μορφή με την οποία η ημερομηνία εμφανίζεται μέσα σε μια συμβολοσειρά. Για παράδειγμα:
Για την εξαγωγή ημερομηνιών όπως 1/1/21 ή 01/01/2021, η regex είναι: \d{1,2}\/\d{1,2}\/(\d{4}
Ψάχνει για μια ομάδα 1 ή 2 ψηφίων d{1,2} ακολουθούμενη από μια κάθετο, ακολουθούμενη από μια άλλη ομάδα 1 ή 2 ψηφίων, ακολουθούμενη από μια κάθετο, ακολουθούμενη από μια ομάδα 4 ή 2 ψηφίων (\d{4}η πρώτη συνθήκη είναι στην εναλλαγή Ή η κατασκευή OR ταιριάζει, οι υπόλοιπες συνθήκες δεν ελέγχονται.
Για να ανακτήσετε ημερομηνίες όπως 1-Jan-21 ή 01-Jan-2021, το μοτίβο είναι: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Ψάχνει για μια ομάδα 1 ή 2 ψηφίων, ακολουθούμενη από μια παύλα, ακολουθούμενη από μια ομάδα 3 κεφαλαίων ή πεζών γραμμάτων, ακολουθούμενη από μια παύλα, ακολουθούμενη από μια ομάδα 4 ή 2 ψηφίων.
Αφού συνδυάσουμε τα δύο μοτίβα μαζί, έχουμε την ακόλουθη regex:
Μοτίβο : \b\d{1,2}[\/-](\d{1,2}
Πού:
- Το πρώτο μέρος είναι 1 ή 2 ψηφία: \d{1,2}
- Το δεύτερο μέρος είναι είτε 1 ή 2 ψηφία είτε 3 γράμματα: (\d{1,2}
- Το τρίτο μέρος είναι μια ομάδα 4 ή 2 ψηφίων: (\d{4}
- Ο διαχωριστής είναι είτε μια κάθετος ή μια παύλα: [\/-]
- Ένα όριο λέξης \b τοποθετείται και στις δύο πλευρές για να καταστεί σαφές ότι η ημερομηνία είναι ξεχωριστή λέξη και όχι μέρος μιας μεγαλύτερης συμβολοσειράς.
Όπως μπορείτε να δείτε στην παρακάτω εικόνα, αφαιρεί επιτυχώς τις ημερομηνίες και αφήνει εκτός υποσύνολα όπως 11/22/333. Ωστόσο, εξακολουθεί να επιστρέφει ψευδώς θετικά αποτελέσματα. Στην περίπτωσή μας, η υποσύνολο 11-ABC-2222 στο A9 ταιριάζει τεχνικά με τη μορφή ημερομηνίας dd-mmm-yyyy και επομένως εξάγεται. 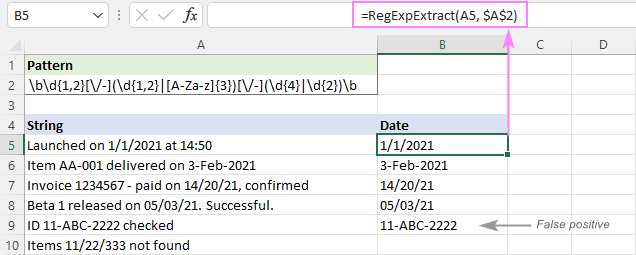
Για να εξαλείψετε τα ψευδώς θετικά αποτελέσματα, μπορείτε να αντικαταστήσετε το μέρος [A-Za-z]{3} με έναν πλήρη κατάλογο των συντομογραφιών των μηνών με 3 γράμματα:
Μοτίβο : \b\d{1,2}[\/-](\d{1,2}
Για να αγνοήσουμε την πεζότητα των γραμμάτων, θέτουμε το τελευταίο όρισμα της προσαρμοσμένης μας συνάρτησης σε FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Και αυτή τη φορά, έχουμε ένα τέλειο αποτέλεσμα: 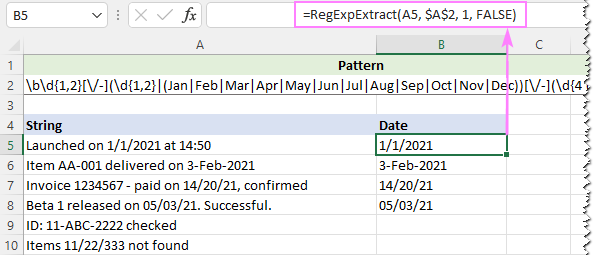
Regex για την εξαγωγή χρόνου από συμβολοσειρά
Για να πάρετε χρόνο στο hh:mm ή hh:mm:ss μορφή, η ακόλουθη έκφραση θα λειτουργήσει άψογα.
Μοτίβο : \b(0?[0-9]
Αν αναλύσουμε αυτή τη regex, μπορούμε να δούμε 2 μέρη που χωρίζονται από
Έκφραση 1 : \b(0?[0-9]
Ανακτά τις ώρες με AM/PM.
Ώρα μπορεί να είναι οποιοσδήποτε αριθμός από το 0 έως το 12. Για να τον πάρουμε, χρησιμοποιούμε την κατασκευή OR ([0-9]
- [0-9] αντιστοιχεί σε οποιονδήποτε αριθμό από το 0 έως το 9
- 1[0-2] αντιστοιχεί σε οποιονδήποτε αριθμό από το 10 έως το 12
Λεπτό [0-5]\d είναι οποιοσδήποτε αριθμός από το 00 έως το 59.
Δεύτερο (:[0-5]\d)? είναι επίσης οποιοσδήποτε αριθμός από το 00 έως το 59. Ο ποσοδείκτης ? σημαίνει μηδέν ή μία εμφάνιση, δεδομένου ότι τα δευτερόλεπτα μπορεί να περιλαμβάνονται ή να μην περιλαμβάνονται στην τιμή του χρόνου.
Έκφραση 2 : \b([0-9]
Εξαγάγει χρόνους χωρίς AM/PM.
Το ώρα μέρος μπορεί να είναι οποιοσδήποτε αριθμός από 0 έως 32. Για να το πάρουμε, μια διαφορετική κατασκευή OR ([0-9]
- [0-9] αντιστοιχεί σε οποιονδήποτε αριθμό από το 0 έως το 9
- [0-1]\d ταιριάζει με οποιονδήποτε αριθμό από το 00 έως το 19
- 2[0-3] αντιστοιχεί σε οποιονδήποτε αριθμό από το 20 έως το 23
Το λεπτό και δεύτερο τα μέρη είναι τα ίδια όπως στην έκφραση 1 ανωτέρω.
Το αρνητικό lookahead (?!:) προστίθεται σε συμβολοσειρές παράλειψης όπως 20:30:80.
Καθώς τα PM/AM μπορούν να είναι είτε κεφαλαία είτε πεζά, η συνάρτηση δεν λαμβάνει υπόψη την πεζότητα:
=RegExpExtract(A5, $A$2, 1, FALSE) 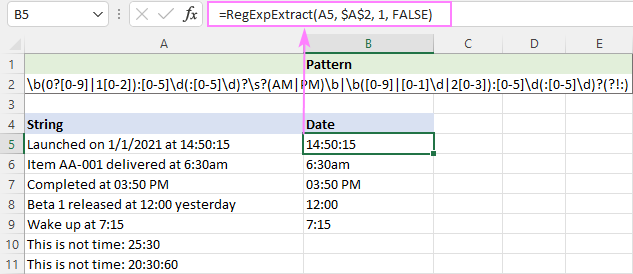
Ελπίζουμε ότι τα παραπάνω παραδείγματα σας έδωσαν κάποιες ιδέες για το πώς να χρησιμοποιήσετε τις κανονικές εκφράσεις στα φύλλα εργασίας του Excel. Δυστυχώς, δεν υποστηρίζονται όλα τα χαρακτηριστικά των κλασικών κανονικών εκφράσεων στη VBA. Εάν η εργασία σας δεν μπορεί να επιτευχθεί με τη RegExp της VBA, σας ενθαρρύνω να διαβάσετε το επόμενο μέρος που εξετάζει πολύ πιο ισχυρές συναρτήσεις Regex του .NET.
Προσαρμοσμένη συνάρτηση Regex με βάση το .NET για την εξαγωγή κειμένου στο Excel
Σε αντίθεση με τις συναρτήσεις VBA RegExp που μπορεί να γράψει οποιοσδήποτε χρήστης του Excel, οι .NET RegEx είναι το βασίλειο του προγραμματιστή. Το Microsoft .NET Framework υποστηρίζει πλήρως εξοπλισμένη σύνταξη κανονικών εκφράσεων συμβατή με την Perl 5. Αυτό το άρθρο δεν θα σας διδάξει πώς να γράψετε τέτοιες συναρτήσεις (δεν είμαι προγραμματιστής και δεν έχω την παραμικρή ιδέα για το πώς να το κάνω αυτό :)
Τέσσερις ισχυρές συναρτήσεις που επεξεργάζονται από την τυπική μηχανή .NET RegEx έχουν ήδη γραφτεί από τους προγραμματιστές μας και περιλαμβάνονται στην Ultimate Suite. Παρακάτω, θα παρουσιάσουμε ορισμένες πρακτικές χρήσεις της συνάρτησης που έχει σχεδιαστεί ειδικά για την εξαγωγή κειμένου στο Excel.
Συμβουλή. Για πληροφορίες σχετικά με τη σύνταξη της γλώσσας .NET Regex, ανατρέξτε στην ενότητα Γλώσσα κανονικών εκφράσεων .NET.
Πώς να εξαγάγετε κεντρίσματα στο Excel χρησιμοποιώντας κανονικές εκφράσεις
Υποθέτοντας ότι έχετε εγκαταστήσει την τελευταία έκδοση της Ultimate Suite, η εξαγωγή κειμένου με χρήση κανονικών εκφράσεων περιορίζεται στα εξής δύο βήματα:
- Στο Δεδομένα Ablebits στην καρτέλα Κείμενο ομάδα, κάντε κλικ στο Εργαλεία Regex .

- Στο Εργαλεία Regex παράθυρο, επιλέξτε τα δεδομένα πηγής, εισαγάγετε το μοτίβο Regex και επιλέξτε την επιλογή Απόσπασμα Για να λάβετε το αποτέλεσμα ως προσαρμοσμένη συνάρτηση και όχι ως τιμή, επιλέξτε την επιλογή Εισαγωγή ως τύπος Όταν τελειώσετε, κάντε κλικ στο Απόσπασμα κουμπί.

Τα αποτελέσματα θα εμφανιστούν σε μια νέα στήλη στα δεξιά των αρχικών σας δεδομένων: 
Σύνταξη AblebitsRegexExtract
Η προσαρμοσμένη μας συνάρτηση έχει την ακόλουθη σύνταξη:
AblebitsRegexExtract(reference, regular_expression)Πού:
- Αναφορά (υποχρεωτικό) - μια αναφορά στο κελί που περιέχει την αρχική συμβολοσειρά.
- Κανονική_έκφραση (υποχρεωτικό) - το μοτίβο regex που θα ταιριάζει.
Σημαντική σημείωση! Η λειτουργία λειτουργεί μόνο σε μηχανήματα με εγκατεστημένο το Ultimate Suite for Excel.
Σημειώσεις χρήσης
Για να κάνετε την πορεία εκμάθησής σας πιο ομαλή και την εμπειρία σας πιο ευχάριστη, παρακαλούμε να δώσετε προσοχή σε αυτά τα σημεία:
- Για να δημιουργήσετε έναν τύπο, μπορείτε να χρησιμοποιήσετε το Εργαλεία Regex , ή του Excel Λειτουργία εισαγωγής ή πληκτρολογήστε το πλήρες όνομα της συνάρτησης σε ένα κελί. Μόλις εισαχθεί ο τύπος, μπορείτε να τον διαχειριστείτε (επεξεργασία, αντιγραφή ή μετακίνηση) όπως οποιονδήποτε εγγενή τύπο.
- Το μοτίβο που εισάγετε στο Εργαλεία Regex παράθυρο πηγαίνει στο 2ο όρισμα. Είναι επίσης δυνατό να διατηρήσετε μια κανονική έκφραση σε ξεχωριστό κελί. Σε αυτή την περίπτωση, χρησιμοποιήστε απλώς μια αναφορά κελιού για το 2ο όρισμα.
- Η συνάρτηση εξάγει το Πρώτη ταύτιση που βρέθηκε .
- Από προεπιλογή, η συνάρτηση είναι case-sensitive Για αντιστοίχιση χωρίς διάκριση πεζών-κεφαλαίων, χρησιμοποιήστε το μοτίβο (?i).
- Εάν δεν βρεθεί αντιστοιχία, επιστρέφεται σφάλμα #N/A.
Regex για την εξαγωγή συμβολοσειράς μεταξύ δύο χαρακτήρων
Για να λάβετε κείμενο μεταξύ δύο χαρακτήρων, μπορείτε να χρησιμοποιήσετε είτε μια ομάδα σύλληψης είτε look-arounds.
Ας πούμε ότι θέλετε να εξάγετε κείμενο μεταξύ παρενθέσεων. Μια ομάδα σύλληψης είναι ο ευκολότερος τρόπος.
Μοτίβο 1 : \[(.*?)\]
Με θετικό lookbehind και lookahead, το αποτέλεσμα θα είναι ακριβώς το ίδιο.
Μοτίβο 2 : (?<=\[)(.*;)(?=\])
Παρακαλείστε να προσέξετε ότι η ομάδα σύλληψης (.*?) εκτελεί ένα τεμπέλικη αναζήτηση για κείμενο μεταξύ δύο παρενθέσεων - από το πρώτο [ έως το πρώτο ]. Μια ομάδα σύλληψης χωρίς ερωτηματικό (.*) θα έκανε μια άπληστη αναζήτηση και να συλλάβετε τα πάντα από το πρώτο [ έως το τελευταίο ].
Με το μοτίβο στο Α2, ο τύπος έχει ως εξής:
=AblebitsRegexExtract(A5, $A$2) 
Πώς να πάρετε όλους τους αγώνες
Όπως έχει ήδη αναφερθεί, η συνάρτηση AblebitsRegexExtract μπορεί να εξάγει μόνο μία αντιστοιχία. Για να πάρετε όλες τις αντιστοιχίες, μπορείτε να χρησιμοποιήσετε τη συνάρτηση VBA που συζητήσαμε νωρίτερα. Ωστόσο, υπάρχει μια προειδοποίηση - η VBA RegExp δεν υποστηρίζει τη σύλληψη ομάδων, οπότε το παραπάνω μοτίβο θα επιστρέψει και τους χαρακτήρες "ορίου", αγκύλες στην περίπτωσή μας.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Για να απαλλαγείτε από τις αγκύλες, αντικαταστήστε τις με κενές συμβολοσειρές ("") χρησιμοποιώντας αυτόν τον τύπο:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Για καλύτερη αναγνωσιμότητα, χρησιμοποιούμε κόμμα για διαχωριστικό. 
Regex για την εξαγωγή κειμένου μεταξύ δύο συμβολοσειρών
Η προσέγγιση που εφαρμόσαμε για την εξαγωγή κειμένου μεταξύ δύο χαρακτήρων θα λειτουργήσει και για την εξαγωγή κειμένου μεταξύ δύο συμβολοσειρών.
Για παράδειγμα, για να πάρετε τα πάντα μεταξύ των "test 1" και "test 2", χρησιμοποιήστε την ακόλουθη κανονική έκφραση.
Μοτίβο : δοκιμή 1(.*;)δοκιμή 2
Ο πλήρης τύπος είναι:
=AblebitsRegexExtract(A5, "test 1(.*;)test 2") 
Regex για την εξαγωγή domain από τη διεύθυνση URL
Ακόμα και με κανονικές εκφράσεις, η εξαγωγή ονομάτων τομέα από διευθύνσεις URL δεν είναι μια απλή εργασία. Το βασικό στοιχείο που κάνει το κόλπο είναι οι ομάδες μη καταγραφής. Ανάλογα με τον τελικό σας στόχο, επιλέξτε μία από τις παρακάτω regexes.
Για να πάρετε ένα πλήρες όνομα τομέα συμπεριλαμβανομένων των υποτομέων
Μοτίβο : (;:https?\:
Για να πάρετε ένα δεύτερο επίπεδο τομέας χωρίς υποτομείς
Μοτίβο : (;:https?\:
Τώρα, ας δούμε πώς λειτουργούν αυτές οι κανονικές εκφράσεις σε ένα παράδειγμα "//www.mobile.ablebits.com" ως δείγμα URL:
- (?:https?\:
- \/\/ - δύο κάθετες προς τα εμπρός (πριν από κάθε μία προηγείται μια backslash για να ξεφύγετε από την ειδική σημασία της κάθετης προς τα εμπρός και να την ερμηνεύσετε κυριολεκτικά).
- (;:[A-Za-z\d\-\.]{2,255}\.); - ομάδα μη καταγραφής για τον προσδιορισμό τομέων τρίτου επιπέδου, τέταρτου επιπέδου κ.λπ., εάν υπάρχουν ( κινητό στο URL του δείγματός μας). Στο πρώτο μοτίβο, τοποθετείται μέσα σε μια μεγαλύτερη ομάδα σύλληψης για να συμπεριληφθούν στην εξαγωγή όλοι οι εν λόγω υποτομείς. Ένας υποτομέας μπορεί να έχει μήκος από 2 έως 255 χαρακτήρες, εξ ου και ο ποσοδείκτης {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - ομάδα σύλληψης για την εξαγωγή του τομέα δεύτερου επιπέδου ( ablebits ) και τον τομέα ανωτάτου επιπέδου ( com ). Το μέγιστο μήκος ενός τομέα δευτέρου επιπέδου είναι 63 χαρακτήρες. Ο μακρύτερος τομέας ανωτάτου επιπέδου που υπάρχει σήμερα περιέχει 24 χαρακτήρες.
Ανάλογα με την κανονική έκφραση που εισάγεται στο A2, ο παρακάτω τύπος θα παράγει διαφορετικά αποτελέσματα:
=AblebitsRegexExtract(A5, $A$2)
Regex για να εξαγάγετε το πλήρες όνομα τομέα με όλους τους υποτομείς: 
Regex για την εξαγωγή ενός δεύτερο επίπεδο τομέας χωρίς subdomains: 
Αυτός είναι ο τρόπος εξαγωγής τμημάτων κειμένου στο Excel χρησιμοποιώντας κανονικές εκφράσεις. Σας ευχαριστώ για την ανάγνωση και ανυπομονώ να σας δω στο blog μας την επόμενη εβδομάδα!
Διαθέσιμες λήψεις
Παραδείγματα Excel Regex Extract (.xlsm αρχείο)
Δοκιμαστική έκδοση Ultimate Suite (.exe αρχείο)
