
İçindekiler
Bu eğitimde, belirli bir desenle eşleşen alt dizeleri bulmak ve ayıklamak için Excel'de düzenli ifadeleri nasıl kullanacağınızı öğreneceksiniz.
Microsoft Excel, hücrelerden metin çıkarmak için bir dizi işlev sağlar. Bu işlevler, çalışma sayfalarınızdaki dize çıkarma zorluklarının çoğuyla başa çıkabilir. Çoğu, ama hepsi değil. Metin işlevleri tökezlediğinde, düzenli ifadeler kurtarmaya gelir. Bekleyin... Excel'in RegEx işlevleri yoktur! Doğru, dahili işlevler yok. Ancak kendi işlevlerinizi kullanmanızı engelleyecek hiçbir şey yok :)
Dizeleri ayıklamak için Excel VBA Regex işlevi
Excel'inize özel bir Regex Extract işlevi eklemek için, aşağıdaki kodu VBA düzenleyicisine yapıştırın. VBA'da düzenli ifadeleri etkinleştirmek için, yerleşik Microsoft RegExp nesnesini kullanıyoruz.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionVBA ile çok az deneyiminiz varsa, adım adım kullanım kılavuzu yararlı olabilir: Excel'de VBA kodu nasıl eklenir?
Not: İşlevin çalışması için, dosyanızı şu şekilde kaydettiğinizden emin olun makro özellikli çalışma kitabı (.xlsm).
RegExpExtract sözdizimi
Bu RegExpExtract işlevi, bir girdi dizesinde düzenli bir ifadeyle eşleşen değerleri arar ve bir veya tüm eşleşmeleri ayıklar.
Fonksiyon aşağıdaki sözdizimine sahiptir:
RegExpExtract(text, pattern, [instance_num], [match_case])Nerede?
- Metin (gerekli) - içinde arama yapılacak metin dizesi.
- Desen (gerekli) - eşleştirilecek normal ifade. Doğrudan bir formülde sağlandığında, desen çift tırnak işareti içine alınmalıdır.
- Instance_num (isteğe bağlı) - hangi örneğin çıkarılacağını gösteren bir seri numarası. Atlanırsa, bulunan tüm eşleşmeleri döndürür (varsayılan).
- Match_case (isteğe bağlı) - metin büyük/küçük harfinin eşleştirilip eşleştirilmeyeceğini tanımlar. TRUE veya atlanırsa (varsayılan), büyük/küçük harfe duyarlı eşleştirme gerçekleştirilir; FALSE ise - büyük/küçük harfe duyarsız.
İşlev, Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 ve Excel 2010'un tüm sürümlerinde çalışır.
RegExpExtract hakkında bilmeniz gereken 4 şey
İşlevi Excel'inizde etkili bir şekilde kullanmak için dikkat etmeniz gereken birkaç önemli nokta vardır:
- Varsayılan olarak, fonksiyon şunları döndürür bulunan tüm eşleşmeler Belirli bir oluşumu elde etmek için, bu örnekte gösterildiği gibi komşu hücrelere karşılık gelen bir sayı girin. instance_num Tartışma.
- Varsayılan olarak, işlev büyük/küçük harfe duyarlı . Büyük/küçük harfe duyarlı olmayan eşleştirme için match_case VBA sınırlamaları nedeniyle, büyük/küçük harfe duyarlı olmayan yapı (?i) çalışmayacaktır.
- Eğer bir geçerli desen bulunamadı fonksiyon hiçbir şey döndürmez (boş dize).
- Eğer desen geçersiz , bir #VALUE! hatası oluşur.
Bu özel işlevi çalışma sayfalarınızda kullanmaya başlamadan önce, neler yapabileceğini anlamanız gerekir, değil mi? Aşağıdaki örnekler birkaç yaygın kullanım durumunu kapsar ve davranışın Dinamik Dizi Excel (Microsoft 365 ve Excel 2021) ile geleneksel Excel'de (2019 ve daha eski sürümler) neden farklı olabileceğini açıklar.
Not. regex örnekleri oldukça basit veri setleri için yazılmıştır. Gerçek çalışma sayfalarınızda kusursuz çalışacaklarını garanti edemeyiz. regex konusunda deneyimi olanlar, düzenli ifadeler yazmanın mükemmelliğe giden hiç bitmeyen bir yol olduğunu kabul edecektir - neredeyse her zaman daha zarif hale getirmenin veya daha geniş bir girdi verisi yelpazesini işleyebilmenin bir yolu vardır.
Dizeden sayı çıkarmak için regex
"Basitten karmaşığa" öğretme temel ilkesini izleyerek, çok basit bir durumla başlayacağız: dizeden sayı çıkarma.
Karar vermeniz gereken ilk şey hangi numarayı alacağınızdır: ilk, son, belirli bir olay veya tüm numaralar.
İlk numarayı çıkar
Bu, regex'in alabileceği kadar basittir. \d'nin 0'dan 9'a kadar herhangi bir rakam ve +'nın bir veya daha fazla kez anlamına geldiği göz önüne alındığında, düzenli ifademiz bu formu alır:
Desen : \d+
Set instance_num 1'e ayarlarsanız istediğiniz sonucu elde edersiniz:
=RegExpExtract(A5, "\d+", 1)
Burada A5 orijinal dizedir.
Kolaylık sağlamak için, deseni önceden tanımlanmış bir hücreye ($A$2 ) girebilir ve adresini $ işaretiyle kilitleyebilirsiniz:
=RegExpExtract(A5, $A$2, 1) 
Son numarayı al
Bir dizedeki son sayıyı ayıklamak için kullanılacak kalıp burada verilmiştir:
Desen : (\d+)(?!.*\d)
İnsan diline çevrildiğinde şu anlama gelir: başka bir sayı tarafından takip edilmeyen (herhangi bir yerde, sadece hemen değil) bir sayı bulun. Bunu ifade etmek için negatif bir lookahead (?!.*\d) kullanıyoruz, bu da kalıbın sağında, kendisinden önce kaç karakter olduğuna bakılmaksızın başka bir rakam (\d) olmaması gerektiği anlamına geliyor.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
İpuçları:
- Almak için spesifik olay için \d+ kullanın. desen için uygun bir seri numarası ve instance_num .
- Çıkarılacak formül tüm numaralar bir sonraki örnekte ele alınmaktadır.
Tüm eşleşmeleri çıkarmak için regex
Örneğimizi biraz daha ileri götürerek, bir dizeden yalnızca bir değil, tüm sayıları almak istediğinizi varsayalım.
Hatırlayabileceğiniz gibi, çıkarılan eşleşme sayısı isteğe bağlı instance_num Varsayılan değer tüm eşleşmelerdir, bu nedenle bu parametreyi atlamanız yeterlidir:
=RegExpExtract(A2, "\d+")
Formül tek bir hücre için güzel bir şekilde çalışır, ancak davranış Dinamik Dizi Excel'de ve dinamik olmayan sürümlerde farklılık gösterir.
Excel 365 ve Excel 2021
Dinamik diziler için destek nedeniyle, normal bir formül otomatik olarak tüm hesaplanan sonuçları görüntülemek için gerektiği kadar hücreye dökülür. Excel açısından buna dökülen aralık denir: 
Excel 2019 ve altı
Dinamik öncesi Excel'de, yukarıdaki formül yalnızca bir eşleşme döndürür. Birden fazla eşleşme elde etmek için, bunu bir dizi formülü haline getirmeniz gerekir. Bunun için, bir hücre aralığı seçin, formülü yazın ve tamamlamak için Ctrl + Shift + Enter tuşlarına basın.
Bu yaklaşımın bir dezavantajı, "ekstra hücrelerde" ortaya çıkan bir grup #N/A hatasıdır. Ne yazık ki, bu konuda hiçbir şey yapılamaz (ne IFERROR ne de IFNA bunu düzeltemez, ne yazık ki). 
Tüm eşleşmeleri tek bir hücrede ayıklayın
Bir veri sütununu işlerken, yukarıdaki yaklaşımın işe yaramayacağı açıktır. Bu durumda, ideal çözüm tüm eşleşmeleri tek bir hücrede döndürmek olacaktır. Bunu yapmak için, RegExpExtract sonuçlarını TEXTJOIN işlevine sunun ve bunları istediğiniz herhangi bir sınırlayıcıyla, örneğin virgül ve boşlukla ayırın:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Not: TEXTJOIN işlevi yalnızca Microsoft 365, Excel 2021 ve Excel 2019 için Excel'de kullanılabildiğinden, formül eski sürümlerde çalışmayacaktır.
Dizeden metin çıkarmak için Regex
Excel'de alfanümerik bir dizeden metin ayıklamak oldukça zorlu bir iştir. regex ile bu iş çocuk oyuncağı kadar kolay hale gelir. Rakam olmayan her şeyi eşleştirmek için olumsuzlanmış bir sınıf kullanmanız yeterlidir.
Desen : [^\d]+
Tek tek hücrelerdeki (dökülme aralığı) alt dizeleri almak için formül şöyledir:
=RegExpExtract(A5, "[^\d]+") 
Tüm eşleşmelerin çıktısını tek bir hücreye almak için, RegExpExtract işlevini TEXTJOIN içine şu şekilde yerleştirin:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Dizeden e-posta adresini çıkarmak için regex
Çok sayıda farklı bilgi içeren bir dizeden bir e-posta adresini çıkarmak için, e-posta adresi yapısını kopyalayan bir düzenli ifade yazın.
Desen : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Bu regex'i parçaladığımızda, işte elde ettiğimiz şey:
- [\w\.\-]+ 1 veya daha fazla alfanümerik karakter, alt çizgi, nokta ve tire içerebilen bir kullanıcı adıdır.
- sembolü
- [A-Za-z0-9\.\-]+ şunlardan oluşan bir alan adıdır: büyük ve küçük harfler, rakamlar, kısa çizgiler ve noktalar (alt alan adları durumunda). Burada alt çizgilere izin verilmez, bu nedenle herhangi bir harf, rakam veya alt çizgi ile eşleşen \w yerine 3 farklı karakter kümesi (A-Z a-z ve 0-9 gibi) kullanılır.
- \A-Za-z]{2,24} üst düzey bir alan adıdır. Bir noktadan ve ardından gelen büyük ve küçük harflerden oluşur. Üst düzey alan adlarının çoğu 3 harf uzunluğundadır (örneğin .com .org, .edu, vb.), ancak teoride 2 ila 24 harf içerebilir (en uzun kayıtlı TLD).
Dizenin A5'te ve desenin A2'de olduğunu varsayarsak, bir e-posta adresini ayıklamak için formül şöyledir:
=RegExpExtract(A5, $A$2) 
E-postadan alan adı çıkarmak için regex
E-posta etki alanını ayıklamak söz konusu olduğunda, akla gelen ilk düşünce @ karakterinden hemen sonra gelen metni bulmak için bir yakalama grubu kullanmaktır.
Desen : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
RegExp fonksiyonumuza servis edin:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Ve bu sonucu alacaksınız: 
Klasik düzenli ifadelerde, yakalama grubunun dışında kalan hiçbir şey ayıklamaya dahil edilmez. VBA RegEx'in neden farklı çalıştığını ve "@" işaretini de yakaladığını kimse bilmiyor. Bundan kurtulmak için, ilk karakteri boş bir dizeyle değiştirerek sonuçtan kaldırabilirsiniz.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Telefon numaralarını ayıklamak için düzenli ifade
Telefon numaraları birçok farklı şekilde yazılabilir, bu nedenle her koşulda çalışan bir çözüm bulmak neredeyse imkansızdır. Yine de, veri kümenizde kullanılan tüm formatları yazabilir ve bunları eşleştirmeye çalışabilirsiniz.
Bu örnek için, bu formatlardan herhangi birindeki telefon numaralarını ayıklayacak bir regex oluşturacağız:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Desen : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- İlk kısım \(?\d{3} sıfır veya bir açılış parantezi ve ardından üç basamaklı d{3} ile eşleşir.
- \)]* kısmı, 0 veya daha fazla kez görünen köşeli parantez içindeki herhangi bir karakter anlamına gelir: kısa çizgi, nokta, boşluk veya kapanış parantezi.
- Ardından, yine üç rakamımız var d{3} ve ardından herhangi bir tire, nokta veya boşluk [-\. ]? 0 veya 1 kez görünür.
- Bundan sonra, \d{4} şeklinde dört rakamdan oluşan bir grup vardır.
- Son olarak, aradığımız bir telefon numarasının daha büyük bir numaranın parçası olamayacağını tanımlayan bir kelime sınırı \b vardır.
Tam formül bu şekli alır:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Lütfen yukarıdaki regex'in 123) 456 7899 veya (123 456 7899 gibi birkaç yanlış pozitif sonuç döndürebileceğini unutmayın. Aşağıdaki sürüm bu sorunları giderir. Ancak, bu sözdizimi klasik düzenli ifadelerde değil, yalnızca VBA RegExp işlevlerinde çalışır.
Desen : (\(\d{3}\)
Dizeden tarih çıkarmak için regex
Bir tarihi ayıklamak için kullanılan düzenli ifade, tarihin bir dize içinde göründüğü biçime bağlıdır. Örneğin:
1/1/21 veya 01/01/2021 gibi tarihleri ayıklamak için regex şöyledir: \d{1,2}\/\d{1,2}\/(\d{4}
1 veya 2 rakamlı bir grubu d{1,2} ve ardından eğik çizgiyi, ardından 1 veya 2 rakamlı başka bir grubu, ardından eğik çizgiyi, ardından 4 veya 2 rakamlı bir grubu (\d{4}ilk koşul VEYA dönüşümünde ise yapı eşleştirilir, kalan koşullar kontrol edilmez.
1-Jan-21 veya 01-Jan-2021 gibi tarihleri almak için kalıp şöyledir: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Bir grup 1 veya 2 rakam, ardından bir kısa çizgi, ardından bir grup 3 büyük veya küçük harf, ardından bir kısa çizgi, ardından bir grup 4 veya 2 rakam arar.
İki kalıbı bir araya getirdikten sonra aşağıdaki regex'i elde ederiz:
Desen : \b\d{1,2}[\/-](\d{1,2}
Nerede?
- İlk kısım 1 veya 2 basamaklıdır: \d{1,2}
- İkinci kısım 1 veya 2 rakam ya da 3 harftir: (\d{1,2}
- Üçüncü kısım 4 veya 2 rakamdan oluşan bir gruptur: (\d{4}
- Sınırlayıcı ileri eğik çizgi veya kısa çizgidir: [\/-]
- Bir tarihin ayrı bir sözcük olduğunu ve daha büyük bir dizenin parçası olmadığını açıkça belirtmek için her iki tarafa da bir sözcük sınırı \b yerleştirilir.
Aşağıdaki resimde görebileceğiniz gibi, tarihleri başarılı bir şekilde çeker ve 11/22/333 gibi alt dizeleri dışarıda bırakır. Ancak, yine de yanlış pozitif sonuçlar döndürür. Bizim durumumuzda, A9'daki 11-ABC-2222 alt dizesi teknik olarak tarih biçimiyle eşleşir dd-mmm-yyyy ve bu nedenle çıkarılır. 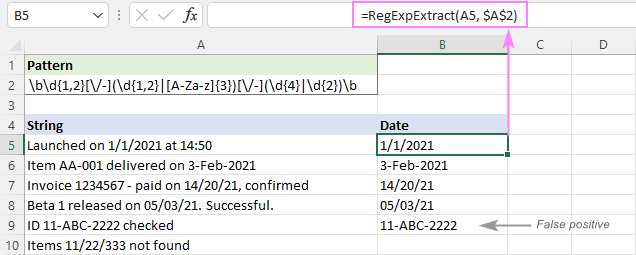
Yanlış pozitifleri ortadan kaldırmak için [A-Za-z]{3} kısmını 3 harfli ay kısaltmalarının tam listesiyle değiştirebilirsiniz:
Desen : \b\d{1,2}[\/-](\d{1,2}
Harf büyüklüğünü yok saymak için özel fonksiyonumuzun son argümanını FALSE olarak ayarlıyoruz:
=RegExpExtract(A5, $A$2, 1, FALSE)
Ve bu sefer, mükemmel bir sonuç elde ettik: 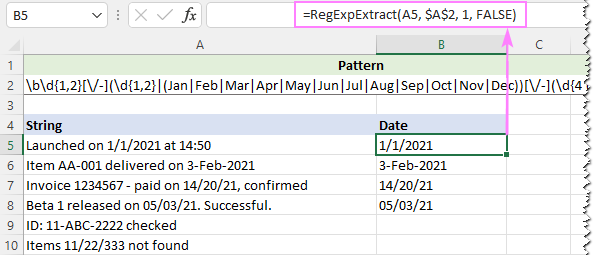
Dizeden zamanı çıkarmak için regex
Zaman kazanmak için hh:mm veya ss:dd:ss biçimini kullanıyorsanız, aşağıdaki ifade işe yarayacaktır.
Desen : \b(0?[0-9]
Bu regex'i parçaladığınızda, aşağıdakilerle ayrılmış 2 parça görebilirsiniz
İfade 1 : \b(0?[0-9]
AM/PM ile saatleri alır.
Saat 0'dan 12'ye kadar herhangi bir sayı olabilir. Bunu elde etmek için OR yapısını kullanırız ([0-9]
- [0-9] 0'dan 9'a kadar herhangi bir sayıyla eşleşir
- 1[0-2] 10 ila 12 arasındaki herhangi bir sayıyla eşleşir
Dakika [0-5]\d 00 ile 59 arasında herhangi bir sayıdır.
İkinci (:[0-5]\d)? aynı zamanda 00 ila 59 arasında herhangi bir sayıdır. Saniyeler zaman değerine dahil edilebileceğinden veya edilmeyebileceğinden, ? niceleyicisi sıfır veya bir oluşum anlamına gelir.
İfade 2 : \b([0-9]
AM/PM olmadan saatleri çıkarır.
Bu saat kısmı 0'dan 32'ye kadar herhangi bir sayı olabilir. Bunu elde etmek için farklı bir OR yapısı ([0-9]
- [0-9] 0'dan 9'a kadar herhangi bir sayıyla eşleşir
- [0-1]\d 00 ila 19 arasındaki herhangi bir sayıyla eşleşir
- 2[0-3] 20'den 23'e kadar herhangi bir sayıyla eşleşir
Bu dakika ve ikinci kısımları yukarıdaki ifade 1 ile aynıdır.
Negatif lookahead (?!:) 20:30:80 gibi atlama dizelerine eklenir.
PM/AM büyük ya da küçük harf olabileceğinden, fonksiyonu büyük/küçük harfe duyarsız hale getiriyoruz:
=RegExpExtract(A5, $A$2, 1, FALSE) 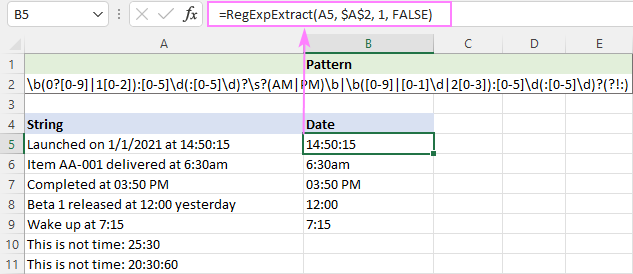
Umarım, yukarıdaki örnekler size Excel çalışma sayfalarınızda düzenli ifadeleri nasıl kullanacağınız konusunda bazı fikirler vermiştir. Ne yazık ki, klasik düzenli ifadelerin tüm özellikleri VBA'da desteklenmemektedir. Göreviniz VBA RegExp ile gerçekleştirilemiyorsa, çok daha güçlü .NET Regex işlevlerini tartışan bir sonraki bölümü okumanızı tavsiye ederim.
Excel'de metin ayıklamak için özel .NET tabanlı Regex işlevi
Herhangi bir Excel kullanıcısı tarafından yazılabilen VBA RegExp işlevlerinin aksine, .NET RegEx geliştiricinin alanıdır. Microsoft .NET Framework, Perl 5 ile uyumlu tam özellikli düzenli ifade sözdizimini destekler. Bu makale size bu tür işlevlerin nasıl yazılacağını öğretmeyecektir (ben bir programcı değilim ve bunun nasıl yapılacağı hakkında en ufak bir fikrim yok :)
Standart .NET RegEx motoru tarafından işlenen dört güçlü fonksiyon zaten geliştiricilerimiz tarafından yazılmış ve Ultimate Suite'e dahil edilmiştir. Aşağıda, Excel'de metin ayıklamak için özel olarak tasarlanmış fonksiyonun bazı pratik kullanımlarını göstereceğiz.
İpucu .NET Regex sözdizimi hakkında bilgi için lütfen .NET Düzenli İfade Dili bölümüne bakın.
Düzenli ifadeler kullanarak Excel'de iğneler nasıl çıkarılır
Ultimate Suite'in en son sürümünün yüklü olduğunu varsayarsak, düzenli ifadeleri kullanarak metin ayıklamak şu iki adıma bağlıdır:
- Üzerinde Ablebits Verileri sekmesinde Metin grubunu seçin, tıklayın Regex Araçları .

- Üzerinde Regex Araçları bölmesinde kaynak verileri seçin, Regex deseninizi girin ve Özüt Sonucu bir değer olarak değil, özel bir işlev olarak almak için Formül olarak ekle onay kutusunu işaretleyin. Özüt Düğme.

Sonuçlar, orijinal verilerinizin sağında yeni bir sütunda görünecektir: 
AblebitsRegexExtract sözdizimi
Özel fonksiyonumuz aşağıdaki sözdizimine sahiptir:
AblebitsRegexExtract(reference, regular_expression)Nerede?
- Referans (gerekli) - kaynak dizeyi içeren hücreye bir başvuru.
- Regular_expression (gerekli) - eşleşecek regex kalıbı.
Önemli not! Bu işlev yalnızca Ultimate Suite for Excel'in yüklü olduğu makinelerde çalışır.
Kullanım notları
Öğrenme eğrinizi daha yumuşak ve deneyiminizi daha keyifli hale getirmek için lütfen bu noktalara dikkat edin:
- Bir formül oluşturmak için Regex Araçları veya Excel'in Ekleme işlevi iletişim kutusuna veya bir hücreye tam işlev adını yazın. Formül eklendikten sonra, herhangi bir yerel formül gibi onu yönetebilirsiniz (düzenleyebilir, kopyalayabilir veya taşıyabilirsiniz).
- üzerine girdiğiniz desen Regex Araçları bölmesi 2. bağımsız değişkene gider. Düzenli ifadeyi ayrı bir hücrede tutmak da mümkündür. Bu durumda, 2. bağımsız değişken için bir hücre referansı kullanın.
- Fonksiyon, aşağıdakileri çıkarır ilk bulunan eşleşme .
- Varsayılan olarak, işlev büyük/küçük harfe duyarlı . Büyük/küçük harfe duyarlı olmayan eşleştirme için (?i) kalıbını kullanın.
- Bir eşleşme bulunamazsa, #N/A hatası döndürülür.
İki karakter arasında dize ayıklamak için Regex
İki karakter arasındaki metni elde etmek için bir yakalama grubu ya da look-arounds kullanabilirsiniz.
Diyelim ki parantezler arasındaki metni ayıklamak istiyorsunuz. Bir yakalama grubu en kolay yoldur.
Desen 1 : \[(.*?)\]
Geriye ve ileriye olumlu bir bakışla sonuç tamamen aynı olacaktır.
Desen 2 : (?<=\[)(.*?)(?=\])
Lütfen yakalama grubumuzun (.*?) bir yakalama gerçekleştirdiğine dikkat edin. tembel arama iki parantez arasındaki metin için - ilk ['dan ilk ]'e. Soru işareti (.*) içermeyen bir yakalama grubu açgözlü arama ve ilk ['den son]'a kadar her şeyi yakalayın.
A2'deki model ile formül aşağıdaki gibi olur:
=AblebitsRegexExtract(A5, $A$2) 
Tüm maçlar nasıl alınır
Daha önce de belirtildiği gibi, AblebitsRegexExtract işlevi yalnızca bir eşleşme çıkarabilir. Tüm eşleşmeleri elde etmek için, daha önce tartıştığımız VBA işlevini kullanabilirsiniz. Ancak, bir uyarı var - VBA RegExp grupları yakalamayı desteklemiyor, bu nedenle yukarıdaki kalıp "sınır" karakterlerini de döndürecek, bizim durumumuzda parantezler.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Parantezlerden kurtulmak için, bu formülü kullanarak bunları boş dizelerle ("") DEĞİŞTİRİN:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Daha iyi okunabilirlik için, sınırlayıcı olarak virgül kullanıyoruz. 
İki dizge arasındaki metni ayıklamak için Regex
İki karakter arasındaki metni çıkarmak için kullandığımız yaklaşım, iki dizgi arasındaki metni çıkarmak için de işe yarayacaktır.
Örneğin, "test 1" ve "test 2" arasındaki her şeyi almak için aşağıdaki düzenli ifadeyi kullanın.
Desen : test 1(.*?)test 2
Tam formül şudur:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
URL'den alan adı çıkarmak için regex
Düzenli ifadelerle bile, URL'lerden alan adlarını çıkarmak önemsiz bir iş değildir. İşi yapan anahtar unsur, yakalayıcı olmayan gruplardır. Nihai hedefinize bağlı olarak, aşağıdaki regex'lerden birini seçin.
Almak için tam alan adı alt alan adları dahil
Desen : (?:https?\:
Almak için ikinci seviye alt alan adları olmayan alan adı
Desen : (?:https?\:
Şimdi, bu düzenli ifadelerin örnek bir URL olarak "//www.mobile.ablebits.com" üzerinde nasıl çalıştığını görelim:
- (?:https?\:
- \/\/ - iki ileri eğik çizgi (ileri eğik çizginin özel anlamından kaçmak ve kelimenin tam anlamıyla yorumlamak için her birinin önünde bir ters eğik çizgi bulunur).
- (?:[A-Za-z\d\-\.]{2,255}\.)? - varsa üçüncü düzey, dördüncü düzey vb. etki alanlarını tanımlamak için yakalayıcı olmayan grup ( mobil İlk kalıpta, bu tür tüm alt alan adlarının çıkarıma dahil edilmesi için daha büyük bir yakalama grubunun içine yerleştirilir. Bir alt alan adı 2 ila 255 karakter uzunluğunda olabilir, dolayısıyla {2,255} niceleyicisi kullanılır.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - ikinci düzey etki alanını çıkarmak için yakalama grubu ( ablebits ) ve üst düzey alan adı ( com İkinci düzey alan adının maksimum uzunluğu 63 karakterdir. Şu anda var olan en uzun üst düzey alan adı 24 karakter içermektedir.
A2'ye hangi düzenli ifadenin girildiğine bağlı olarak, aşağıdaki formül farklı sonuçlar üretecektir:
=AblebitsRegexExtract(A5, $A$2)
Ayıklamak için Regex tam alan adı tüm alt alan adlarıyla birlikte: 
Ayıklamak için Regex ikinci seviye etki alanı alt alan adları olmadan: 
Düzenli ifadeleri kullanarak Excel'de metin parçalarını nasıl ayıklayacağınızı anlattım. Okuduğunuz için teşekkür ediyor ve gelecek hafta sizi blogumuzda görmeyi dört gözle bekliyorum!
Mevcut indirmeler
Excel Regex Extract örnekleri (.xlsm dosyası)
Ultimate Suite deneme sürümü (.exe dosyası)
