
目次
このチュートリアルでは、Excelで正規表現を使用して、与えられたパターンに一致する部分文字列を検索して抽出する方法について学習します。
Microsoft Excelには、セルからテキストを抽出するための関数がいくつか用意されています。 これらの関数を使えば、ワークシートの文字列抽出のほとんどの問題に対処できます。 ほとんどですが、すべてではありません。 テキスト関数がつまずいたときには、正規表現が助けてくれます。 待って、ExcelにはRegEx関数がない! 確かに内蔵関数もありませんが、独自のものを使えないわけではありません(笑)。
Excel VBA Regex関数で文字列を抽出する
ExcelにカスタムRegex Extract関数を追加するには、VBAエディタに次のコードを貼り付けます。 VBAで正規表現を有効にするために、組み込みのMicrosoft RegExpオブジェクトを使用しています。
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Then.regex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionVBAの使用経験が少ない場合は、ステップバイステップのユーザーガイド「ExcelにVBAコードを挿入する方法」が役に立ちます。
注意:この機能を動作させるためには、必ずファイルを マクロ可能なワークブック (.xlsm)です。
RegExpExtractの構文
があります。 RegExpExtract 関数は,入力文字列から正規表現にマッチする値を検索し,1つあるいはすべて のマッチを抽出する。
この関数は次のような構文になっています。
RegExpExtract(text, pattern, [instance_num], [match_case])どこで
- テキスト (必須) - 検索するためのテキスト文字列です。
- パターン (必須) - 一致させる正規表現です。 式で直接指定する場合は、パターンを二重引用符で囲む必要があります。
- インスタンス番号 (オプション) - 抽出するインスタンスを示す通し番号。 省略した場合は、見つかったすべてのマッチを返します (デフォルト)。
- マッチケース (オプション) - テキストの大文字小文字を区別するかどうかを定義します。 TRUE あるいは省略した場合 (デフォルト)、 大文字小文字を区別してマッチングします。
この機能は、Excel 365、Excel 2021、Excel 2019、Excel 2016、Excel 2013、Excel 2010のすべてのバージョンで使用できます。
RegExpExtractについて知っておくべき4つのこと
Excelでこの関数を効果的に使うには、いくつか注意すべき点があります。
- デフォルトでは、この関数は ぜんしょうてつづきずもう のように、隣り合ったセルに分けて表示させることができます。 インスタンス番号 の議論になります。
- デフォルトでは、この関数は ケースセンシティブ 大文字・小文字を区別しないマッチングを行う場合は マッチケース VBAの制限により、大文字と小文字を区別しない構成(?i)は機能しません。
- がある場合 有効なパターンが見つからない の場合、この関数は何も返しません(空文字列)。
- もし パターンが無効 の場合、#VALUE!エラーが発生します。
ワークシートでこのカスタム関数を使い始める前に、その機能を理解しておく必要がありますよね。 以下の例では、よくある使用例をいくつか取り上げ、動的配列 Excel(Microsoft 365 および Excel 2021)と従来の Excel(2019 および古いバージョン)で動作が異なる場合がある理由を説明します。
注意:Out regexの例は妖精のような簡単なデータセット用に書かれています。 実際のワークシートで完璧に動作することは保証できません。 正規表現を書いた経験のある人なら、正規表現を書くことは完璧への終わりのない道であることに同意するでしょう。ほとんど常に、よりエレガントで、より広範囲の入力データを処理できる方法があるのです。
文字列から数値を抽出する正規表現
単純なものから複雑なものへ」という教え方の基本に従って、まずは文字列から数字を取り出すという非常に平易なケースから始めてみましょう。
まず、最初の番号、最後の番号、特定の発生番号、すべての番号のどれを取得するかを決定します。
最初の数字を抽出する
正規表現は、0から9までの数字が「"d"」、1回以上の回数が「"+"」とすると、このような形になります。
パターン : \d+
セット インスタンス番号 を1にすれば、期待通りの結果が得られます。
=RegExpExtract(A5, "\d+", 1)
ここで、A5は元の文字列です。
便利なことに、あらかじめ定義されたセル($A$2 )にパターンを入力し、そのアドレスを$記号でロックしておくことができるのだ。
=RegExpExtract(A5, $A$2, 1) 
最後の番号を取得する
文字列の最後の数字を取り出すには、次のようなパターンを使用します。
パターン : (˶‾‾‾‾˵)(˵‾‾‾‾˵)
人間の言葉に置き換えると、「他の数字が(すぐではなく)どこにも続かない数字を見つけなさい」ということです。 これを表現するために、「パターンの右側には、その前に何文字あっても他の数字( \d )があってはならない」という負のルックアヘッド(?
=RegExpExtract(A5, "(\d+)(?!.***d)") 
ヒント
- を取得するために 特定事象 には"↵"をつけてください。 雛形 という適切なシリアルナンバーが必要です。 インスタンス番号 .
- を抽出するための式です。 全数 は、次の例で説明します。
すべてのマッチを抽出する正規表現
この例をもう少し進めて、文字列から1つだけでなく、すべての数字を取得したいとします。
覚えているかもしれませんが、抽出されたマッチの数は、オプションの インスタンス番号 デフォルトは all matches なので、このパラメータを省略することができます。
=RegExpExtract(A2, "\d+")
この数式は1つのセルに対してはきれいに動作しますが、動的配列のExcelとそうでないバージョンでは動作が異なります。
Excel 365とExcel 2021
動的配列のサポートにより、通常の数式は、すべての計算結果を表示するために必要な数だけセルに自動的に流出します。 これをExcelで言えば、流出範囲と呼びます。 
Excel 2019以下
ダイナミック以前のExcelでは、上記の数式は1つのマッチを返します。 複数のマッチを得るには、配列数式にする必要があります。 そのためには、セル範囲を選択して数式を入力し、Ctrl + Shift + Enterキーを押して完了させます。
この方法の欠点は、「余分なセル」に#N/Aエラーが大量に現れることです。 残念ながら、これについては何もできません(IFERRORもIFNAも、残念ながらこれを修正することはできません)。 
1つのセルに含まれるすべてのマッチを抽出する
列のデータを処理する場合、上記のアプローチは明らかに機能しません。 この場合、理想的なソリューションは、単一のセルにすべてのマッチを返すことです。 これを行うには、RegExpExtractの結果をTEXTJOIN関数に提供し、任意の区切り文字、例えばカンマとスペースでそれらを区切ります。
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
注)TEXTJOIN関数は、Microsoft 365、Excel 2021、Excel 2019のExcelでのみ利用できるため、それ以前のバージョンでは計算式が使えません。
文字列からテキストを抽出する正規表現
英数字の文字列からテキストを抽出するのは、Excelではかなり難しい作業です。 正規表現を使えば、数字以外のすべての文字にマッチするように、否定クラスを使って簡単にできます。
パターン : [^\d]+
個々のセル(スピルレンジ)の部分文字列を取得する場合は、以下の式になります。
=RegExpExtract(A5, "[^Θd]+") 
すべてのマッチを1つのセルに出力するには、次のようにTEXTJOINにRegExpExtract関数をネストします。
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^Íd]+")) 
文字列から電子メールアドレスを抽出する正規表現
さまざまな情報を含む文字列から電子メールアドレスを取り出すには、電子メールアドレスの構造を再現する正規表現を書きます。
パターン : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
この正規表現を分解すると、以下のようになります。
- [ユーザー名には、1文字以上の英数字、アンダースコア、ドット、ハイフンを含めることができます。
- アットマーク
- [A-Za-z0-9.\-]+ は大文字、小文字、数字、ハイフン、ドット(サブドメインの場合)で構成されるドメイン名です。 アンダースコアは使用できないため、任意の文字、数字、アンダースコアにマッチする \w の代わりに A-Z a-z や 0-9 など3種類の文字セットで使用されます。
- \.[A-Za-z]{2,24}はトップレベルドメインです。 ドットの後に大文字と小文字が続きます。 トップレベルドメインの多くは3文字ですが(例: .com .org, .edu, etc)、理論上は2文字から24文字(最長登録TLD)まで含むことが可能です。
文字列がA5に、パターンがA2にあると仮定すると、メールアドレスを抽出する式は次のようになる。
=RegExpExtract(A5, $A$2) 
電子メールからドメインを抽出するための正規表現
電子メールのドメインを抽出するとなると、まず思いつくのは、キャプチャグループを使って@文字の直後にあるテキストを見つけることです。
パターン : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
これを RegExp 関数に渡します。
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
そして、このような結果を得ることができるのです。 
古典的な正規表現では、捕捉グループの外側にあるものは抽出に含まれません。 VBA RegExの動作が異なり、「@」も捕捉する理由は誰も知りません。 これを取り除くには、最初の文字を空の文字列に置き換えて結果から削除します。
=REPLACE(RegExpExtract(A5, "@([a-zd][a-zd-enta.]*tenta.[a-z]{2,})", 1, FALSE), 1, 1, "") 
電話番号抽出のための正規表現
電話番号はさまざまな書き方があるので、すべての状況下で機能する解決策を考え出すのは不可能に近い。 それでも、データセットで使われているすべての形式を書き出して、それらを照合してみることはできる。
この例では、これらのいずれかの形式の電話番号を抽出する正規表現を作成することにします。
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
パターン : \(?╱?╱) ]*╱?╱?
- 最初の部分 \(?\d{3}) は、0個または1個の開始括弧と3桁のd{3} に一致します。
- の部分は、ハイフン、ピリオド、スペース、閉じ括弧のうち、0回以上出現する角括弧内の文字を意味します。
- 次に、再び3桁の数字d{3}の後に、任意のハイフン、ピリオド、スペース[-. ]が0回または1回出現する。
- そのあと、4桁の数字が並んでいる㊧があります。
- 最後に、探している電話番号がより大きな番号の一部であってはいけないという境界線があります。
完全な数式はこのような形になります。
=RegExpExtract(A5, "\(?\d{3}[-. \])]*┣┣[-.]?\d{4}┣b") 
上記の正規表現では、123) 456 7899 や (123 456 7899) などの誤った結果を返すことがありますのでご注意ください。 以下のバージョンではこれらの問題を修正しています。 ただし、この構文は VBA RegExp 関数でのみ機能し、古典的な正規表現では機能しません。
パターン : (\(\d{3}\)
文字列から日付を抽出する正規表現
日付を抽出するための正規表現は、文字列の中で日付がどのような形式で現れるかに依存する。 たとえば、以下のようなものである。
1/1/21や2021年01月01日のような日付を抽出するには、次のような正規表現を使用します: \d{1,2}/╱d{1,2}/(\d{4})
1桁または2桁のグループd{1,2}の後にスラッシュが続き、さらに1桁または2桁のグループとスラッシュが続き、4桁または2桁のグループ( \d{4} )を検索するものです。が交互に並んでいる場合、残りの条件はチェックされない。
1-Jan-21や01-Jan-2021のような日付を取得する場合は、次のパターンになります: \d{1,2}-[A-Za-z]{3}-d{2,4}
1桁または2桁の数字のグループ、ハイフン、大文字または小文字の3文字のグループ、ハイフン、4桁または2桁の数字のグループの順に検索されます。
2つのパターンを組み合わせると、次のような正規表現になる。
パターン : \d{1,2}[\/-](\d{1,2})
どこで
- 最初の部分は1桁または2桁です: \d{1,2}.
- 第2部は1桁または2桁または3文字: (\d{1,2})
- 第3部は4桁または2桁のグループ:(˶‾᷄ -̫̫ ‾᷅˵)
- デリミタはフォワードスラッシュまたはハイフン:[Ⓐ] です。
- 日付が大きな文字列の一部ではなく、独立した単語であることを明確にするために、両側に単語境界(industry)の"˶"を配置します。
下の画像にあるように、日付はうまく抽出され、11/22/333のような部分文字列は除外されています。 しかし、まだ偽陽性結果を返します。 このケースでは、A9の部分文字列11-ABC-2222は技術的に日付フォーマットに一致します。 dd-mmm-yyyy ということで、抽出されます。 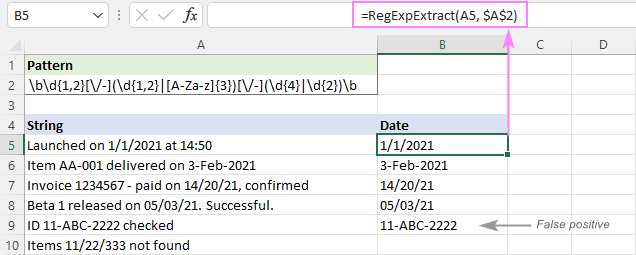
誤検出を防ぐために、[A-Za-z]{3}の部分を3文字の月の略語の全リストに置き換えることができます。
パターン : \d{1,2}[\/-](\d{1,2})
大文字小文字を無視するために、カスタム関数の最後の引数をFALSEに設定しています。
=RegExpExtract(A5, $A$2, 1, FALSE)
そして今回、完璧な結果を得ることができました。 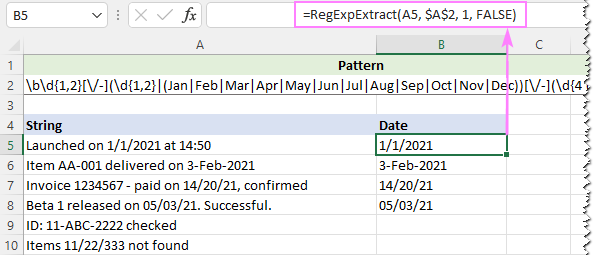
文字列から時刻を抽出する正規表現
での時間を確保すること。 hh:mm または hh:mm:ss 形式の場合、次のような式でうまくいきます。
パターン : \b(0?[0-9]
この正規表現を分解してみると、2つの部分が
表現1 : \b(0?[0-9]
AM/PM付きの時刻を取得します。
時間 は0から12までの任意の数であり,これを求めるには,OR構文([0-9])を用いる.
- [0-9]は0から9までの任意の数字にマッチします。
- 1[0-2]は10~12までの任意の数字にマッチします。
分 [0~5]↵は00~59の任意の数字です。
第2回 (:[0-5]\d)? は00~59の任意の数字でもあり、?は時間値に秒が含まれる場合と含まれない場合があるため、0または1の出現を意味します。
表現2 : \b([0-9]
AM/PMを除いた時間を抽出します。
があります。 時 の部分は0から32までの任意の数で、これを得るには、別のOR構成([0-9])が必要です。
- [0-9]は0から9までの任意の数字にマッチします。
- [0-1]⑯は00~19の任意の数字にマッチします。
- 2[0-3]は、20~23の任意の数字にマッチします。
があります。 微細 と 第二 の部分は、上記の式1と同じです。
20:30:80 などのスキップ文字列には、負のルックアヘッド(?
PM/AMは大文字でも小文字でもよいので、大文字小文字を区別しない関数とする。
=RegExpExtract(A5, $A$2, 1, FALSE) 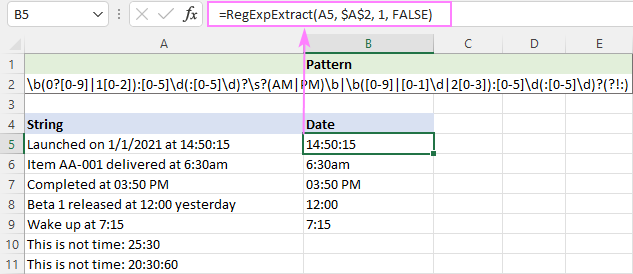
上記の例で、Excelワークシートで正規表現を使用する方法について、いくつかのアイデアを得ることができました。 残念ながら、古典的な正規表現のすべての機能がVBAでサポートされているわけではありません。 VBA RegExpでタスクを達成できない場合、より強力な.NET Regex関数について説明する次のパートを読むことをお勧めします。
Excelのテキストを抽出するための.NETベースのカスタムREGEX関数
VBAのRegExp関数はExcelユーザーなら誰でも書けますが、.NET RegExは開発者の領域です。 Microsoft .NET FrameworkはPerl 5と互換性のあるフル機能の正規表現構文をサポートしています。 この記事では、そのような関数の書き方は教えません(私はプログラマーではないので、その方法は少しもわかりません :))。
標準の.NET RegExエンジンで処理される4つの強力な関数がすでに開発者によって書かれ、Ultimate Suiteに含まれています。 以下では、Excelのテキスト抽出に特化した関数の実際の使い方をいくつか紹介します。
補足: .NET Regexの構文については、「.NET正規表現言語」を参照してください。
正規表現を使ってExcelで刺を抽出する方法
最新版のUltimate Suiteがインストールされていると仮定すると、正規表現を使ったテキストの抽出は、以下の2つのステップに集約されます。
- について エイブルビットのデータ タブで テキスト グループをクリックします。 Regexツール .

- について Regexツール ペインでソースデータを選択し、Regexパターンを入力して 抜粋 値ではなく、カスタム関数として結果を得たい場合は、「カスタム関数」を選択します。 数式として挿入する をクリックします。 抜粋 ボタンをクリックします。

結果は、元のデータの右側に新しい列で表示されます。 
AblebitsRegexExtractの構文
カスタム関数の構文は以下の通りです。
AblebitsRegexExtract(参照、regular_expression)どこで
- 参考 (必須) - ソース文字列を含むセルへの参照。
- 正規表現 (必須) - マッチする正規表現パターン。
重要!この機能は、Ultimate Suite for Excelがインストールされているマシンでのみ動作します。
使用上の注意
よりスムーズに、より楽しく学んでいただくために、以下のポイントにご注意ください。
- 数式を作成するには、当社の Regexツール またはExcelの インサート機能 数式を挿入すると、ネイティブな数式と同じように編集、コピー、移動などの管理ができます。
- で入力したパターンが Regexツール この場合、2番目の引数にはセル参照を使用します。
- を抽出する関数です。 さいしょうこうごう .
- デフォルトでは、この関数は ケースセンシティブ 大文字と小文字を区別しないマッチングを行う場合は、(?i)パターンを使用します。
- 一致しない場合は、#N/Aエラーが返されます。
2文字に挟まれた文字列を抽出する正規表現
2文字間のテキストを取得するには、キャプチャグループかルックアラウンドのいずれかを使用することができます。
例えば、括弧の間のテキストを抽出する場合、キャプチャグループを使用するのが最も簡単な方法です。
パターン1 : \[(.*?)\]
前向きなルックビハインドとルックアヘッドがあれば、結果はまったく同じになるのです。
パターン2 : (?<=³[)(.*?)(?=³])
キャプチャグループ(.*?)が実行されることに注意してください。 しらみつぶしの検索 は、最初の[ ]から2つの括弧で囲まれたテキストです。 クエスチョンマーク(.*)のないキャプチャグループは、次のような動作をします。 貪欲な探索 を、最初の[から]最後の[まで]すべて捕捉します。
A2のパターンで、計算式は次のようになる。
=AblebitsRegexExtract(A5, $A$2) 
全試合の入手方法
すでに述べたように、AblebitsRegexExtract関数は1つのマッチしか抽出できません。 すべてのマッチを取得するには、先に説明したVBA関数を使用します。 ただし、1つ注意点があります。VBA RegExpはグループの取得をサポートしていないので、上記のパターンは「境界」文字(この場合は括弧)も返すことになります。
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
括弧を取り除くには、次の式で空文字列("")を代入してください。
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "], ""),"[",""")
読みやすくするために、デリミタにカンマを使用しています。 
2つの文字列の間のテキストを抽出する正規表現
2文字間のテキストを取り出すために考え出した方法は、2つの文字列間のテキストを取り出す場合にも有効です。
例えば、「test 1」と「test 2」の間をすべて取得するには、次のような正規表現を使用します。
パターン テスト1(.*?)テスト2
完全な計算式は
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
URLからドメインを抽出する正規表現
正規表現を用いても、URLからドメイン名を抽出することは容易ではありません。 その鍵となるのは、捕捉しないグループです。 最終的な目的に応じて、以下の正規表現のいずれかを選択してください。
を取得するために フルドメイン名 サブドメインを含む
パターン : (?:https?
を取得するために セカンドレベル じゅんりょういき
パターン : (?:https?
では、サンプルURLとして「//www.mobile.ablebits.com」を例に、これらの正規表現がどのように機能するかを見てみましょう。
- (?:https?
- \// - 2つのフォワードスラッシュ(フォワードスラッシュの特別な意味から逃れ、文字通りに解釈するために、それぞれの前にバックスラッシュが付きます)。
- (?:[A-Za-zd-93] {2,255})? - 第3レベル、第4レベルなどのドメインを識別するための非捕捉グループ, if any ( モバイル 最初のパターンでは、そのようなサブドメインがすべて抽出に含まれるように、より大きなキャプチャグループ内に配置されます。 サブドメインは2〜255文字の長さにすることができるため、{2,255}という量記号が使用されます。
- ([A-Za-zd-]{1,63}.[A-Za-z]{2,24}) - 第2レベルドメインを抽出するための捕捉グループ ( ビップ ) とトップレベルドメイン ( コーム 現在存在する最長のトップレベルドメインは24文字です。
A2にどの正規表現を入力するかによって、以下の計算式は異なる結果になります。
=AblebitsRegexExtract(A5, $A$2)
を抽出するための正規表現。 フルドメイン名 をすべてのサブドメインで使用します。 
を抽出するための正規表現。 セカンドレベル 領域 サブドメインなし 
以上、Excelで正規表現を使ってテキストの一部を抽出する方法でした。 読んでいただきありがとうございました!来週のブログでお会いできるのを楽しみにしています。
ダウンロード可能なもの
Excel Regex 抽出例 (.xlsm ファイル)
Ultimate Suite体験版(.exeファイル)
