
Spis treści
W tym poradniku dowiesz się, jak używać wyrażeń regularnych w Excelu, aby znaleźć i wyodrębnić podciągi pasujące do danego wzorca.
Microsoft Excel udostępnia szereg funkcji do wyodrębniania tekstu z komórek. Funkcje te radzą sobie z większością wyzwań związanych z wyodrębnianiem ciągów znaków w Twoich arkuszach. Z większością, ale nie ze wszystkimi. Gdy funkcje tekstowe się potkną, na ratunek przychodzą wyrażenia regularne. Zaraz... Excel nie ma funkcji RegEx! Prawda, nie ma wbudowanych funkcji. Ale nic nie stoi na przeszkodzie, abyś używał własnych :)
Excel VBA Funkcja Regex do wyodrębniania ciągów znaków
Aby dodać niestandardową funkcję Regex Extract do Excela, wklej poniższy kod w edytorze VBA. Aby umożliwić wyrażenia regularne w VBA, używamy wbudowanego obiektu Microsoft RegExp.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Then.regex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End Function.Jeśli masz niewielkie doświadczenie z VBA, pomocny może okazać się przewodnik użytkownika krok po kroku: Jak wstawić kod VBA w Excelu.
Uwaga. Aby funkcja działała, należy zapisać plik jako skoroszyt z obsługą makr (.xlsm).
Składnia RegExpExtract
Na stronie RegExpExtract Funkcja przeszukuje łańcuch wejściowy w poszukiwaniu wartości pasujących do wyrażenia regularnego i wyodrębnia jedno lub wszystkie dopasowania.
Funkcja ma następującą składnię:
RegExpExtract(text, pattern, [instance_num], [match_case])Gdzie:
- Tekst (wymagane) - ciąg tekstowy do wyszukiwania w.
- Wzór (wymagane) - wyrażenie regularne do dopasowania. W przypadku podania bezpośrednio w formule, wzorzec powinien być ujęty w podwójne cudzysłowy.
- Liczba instancji (opcjonalne) - numer seryjny, który wskazuje, która instancja ma zostać wyodrębniona. Jeżeli pominięty, zwraca wszystkie znalezione dopasowania (domyślnie).
- Dopasowanie (opcjonalne) - określa, czy dopasowywać czy ignorować wielkość liter w tekście. Jeżeli TRUE lub pominięte (domyślnie), to jest wykonywane dopasowanie z uwzględnieniem wielkości liter; jeżeli FALSE - bez uwzględniania wielkości liter.
Funkcja działa we wszystkich wersjach programów Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 i Excel 2010.
4 rzeczy, które powinieneś wiedzieć o RegExpExtract
Aby skutecznie wykorzystać funkcję w swoim Excelu, należy zwrócić uwagę na kilka ważnych rzeczy:
- Domyślnie funkcja zwraca wszystkie znalezione mecze w sąsiednich komórkach, jak pokazano w tym przykładzie. Aby uzyskać konkretne wystąpienie, podaj odpowiednią liczbę do instancja_numer argument.
- Domyślnie funkcja ta to. rozróżnianie wielkości liter Dla dopasowania bez rozróżniania wielkości liter należy ustawić dopasowanie_przypadku Ze względu na ograniczenia VBA, konstrukcja rozróżniająca wielkość liter (?i) nie będzie działać.
- Jeżeli nie znaleziono prawidłowego wzoru , funkcja nie zwraca nic (pusty ciąg).
- Jeśli wzór jest nieprawidłowy , pojawia się błąd #VALUE!
Zanim zaczniesz używać tej niestandardowej funkcji w swoich arkuszach, musisz zrozumieć, do czego jest zdolna, prawda? Poniższe przykłady obejmują kilka typowych przypadków użycia i wyjaśniają, dlaczego zachowanie może się różnić w Dynamic Array Excel (Microsoft 365 i Excel 2021) i tradycyjnym Excelu (2019 i starsze wersje).
Uwaga. Przykłady wyrażeń regularnych są napisane dla bardzo prostych zestawów danych. Nie możemy zagwarantować, że będą one działać bezbłędnie w twoich rzeczywistych arkuszach. Ci, którzy mają doświadczenie z regexem zgodzą się, że pisanie wyrażeń regularnych jest niekończącą się drogą do doskonałości - prawie zawsze jest sposób, aby uczynić je bardziej eleganckim lub zdolnym do obsługi szerszego zakresu danych wejściowych.
Regex do wyodrębnienia liczby z ciągu znaków
Kierując się podstawową maksymą nauczania "od prostego do złożonego", zaczniemy od bardzo prostego przypadku: wyodrębniania liczby z ciągu znaków.
Pierwszą rzeczą, o której musisz zdecydować, jest to, który numer chcesz odzyskać: pierwszy, ostatni, konkretne wystąpienie lub wszystkie numery.
Wyciągnij pierwszą liczbę
To jest tak proste, jak tylko może być regex. Biorąc pod uwagę, że № oznacza dowolną cyfrę od 0 do 9, a + oznacza jeden lub więcej razy, nasze wyrażenie regularne ma taką postać:
Wzór : \d+
Ustaw instancja_numer do 1, a uzyskasz pożądany rezultat:
=RegExpExtract(A5, "\", 1)
Gdzie A5 jest oryginalną struną.
Dla wygody można wprowadzić wzorzec do wcześniej zdefiniowanej komórki ($A$2 ) i zablokować jej adres znakiem $:
=RegExpExtract(A5, $A$2, 1) 
Uzyskaj ostatni numer
Aby wyodrębnić ostatnią liczbę w ciągu, oto wzór do użycia:
Wzór : (?!.*)(?)
Przetłumaczone na ludzki język mówi: znajdź liczbę, po której nie następuje (nigdzie, nie tylko od razu) żadna inna liczba. Aby to wyrazić, używamy ujemnego lookahead (?!.*), co oznacza, że na prawo od wzoru nie powinna znajdować się żadna inna cyfra (Ą) niezależnie od tego, ile innych znaków jest przed nią.
=RegExpExtract(A5, "(ą+)(?!.*)") 
Wskazówki:
- Aby uzyskać szczególne wystąpienie , użyj \u200 dla wzór oraz odpowiedni numer seryjny dla instancja_numer .
- Wzór na wyodrębnienie wszystkie liczby jest omówiony w kolejnym przykładzie.
Regex do wyodrębnienia wszystkich dopasowań
Popychając nasz przykład nieco dalej, załóżmy, że chcesz uzyskać wszystkie liczby z ciągu, a nie tylko jeden.
Jak być może pamiętasz, liczba wyodrębnionych dopasowań jest kontrolowana przez opcjonalne instancja_numer Domyślnie są to wszystkie mecze, więc wystarczy pominąć ten parametr:
=RegExpExtract(A2, "\")
Formuła działa pięknie dla pojedynczej komórki, ale zachowanie różni się w Dynamic Array Excel i niedynamicznych wersjach.
Excel 365 i Excel 2021
Dzięki obsłudze tablic dynamicznych formuła zwykła automatycznie rozlewa się na tyle komórek, ile potrzeba do wyświetlenia wszystkich obliczonych wyników. W kategoriach Excela nazywa się to rozlanym zakresem: 
Excel 2019 i niższe
W przeddynamicznym Excelu powyższa formuła zwróciłaby tylko jedno dopasowanie. Aby uzyskać wiele dopasowań, musisz uczynić ją formułą tablicową. W tym celu wybierz zakres komórek, wpisz formułę i naciśnij Ctrl + Shift + Enter, aby ją zakończyć.
Wadą tego podejścia jest masa błędów #N/A pojawiających się w "dodatkowych komórkach". Niestety, nic nie da się z tym zrobić (ani IFERROR, ani IFNA nie potrafią tego naprawić, niestety). 
Wyodrębnij wszystkie mecze w jednej komórce
Podczas przetwarzania kolumny danych powyższe podejście oczywiście nie zadziała. W tym przypadku idealnym rozwiązaniem byłoby zwrócenie wszystkich dopasowań w jednej komórce. Aby to zrobić, podaj wyniki RegExpExtract do funkcji TEXTJOIN i oddziel je dowolnym delimiterem, który lubisz, powiedzmy przecinkiem i spacją:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\")) 
Uwaga. Ponieważ funkcja TEXTJOIN jest dostępna tylko w programie Excel dla Microsoft 365, Excel 2021 i Excel 2019, formuła nie będzie działać w starszych wersjach.
Regex do wyodrębnienia tekstu z ciągu znaków
Wyodrębnianie tekstu z ciągu alfanumerycznego jest dość trudnym zadaniem w Excelu. Dzięki regexowi staje się to łatwe jak bułka z masłem. Wystarczy użyć klasy zanegowanej, aby dopasować wszystko, co nie jest cyfrą.
Wzór : [^\d]+
Aby uzyskać podciągi w poszczególnych komórkach (zakres rozlany), formuła brzmi:
=RegExpExtract(A5, "[^d]+") 
Aby wyprowadzić wszystkie dopasowania do jednej komórki, zagnieżdż funkcję RegExpExtract w TEXTJOIN w ten sposób:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^d]+")) 
Regex do wyodrębnienia adresu e-mail z ciągu
Aby wyciągnąć adres e-mail z ciągu zawierającego wiele różnych informacji, napisz wyrażenie regularne, które odwzorowuje strukturę adresu e-mail.
Wzór : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Rozbijając ten regex, oto co otrzymujemy:
- [Ę]+ to nazwa użytkownika, która może zawierać 1 lub więcej znaków alfanumerycznych, podkreślników, kropek i myślników.
- @ symbol
- [A-Za-z0-9]+ to nazwa domeny składająca się z: dużych i małych liter, cyfr, myślników i kropek (w przypadku subdomen). Podkreślniki nie są tu dozwolone, dlatego zamiast ą, która pasuje do każdej litery, cyfry lub podkreślnika, używa się 3 różnych zestawów znaków (takich jak A-Z a-z i 0-9).
- \A-Za-z]{2,24} to domena najwyższego poziomu. Składa się z kropki, po której następują duże i małe litery. Większość domen najwyższego poziomu ma długość 3 liter (np. .com .org, .edu, itp.), ale teoretycznie może zawierać od 2 do 24 liter (najdłuższe zarejestrowane TLD).
Zakładając, że ciąg znajduje się w A5, a wzorzec w A2, formuła wyodrębniająca adres e-mail to:
=RegExpExtract(A5, $A$2) 
Regex do wyodrębnienia domeny z wiadomości e-mail
Jeśli chodzi o wyodrębnianie domeny e-mail, pierwszą myślą, która przychodzi do głowy, jest użycie grupy przechwytującej, aby znaleźć tekst, który natychmiast następuje po znaku @.
Wzór : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Podaj ją do naszej funkcji RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
I otrzymasz taki wynik: 
W przypadku klasycznych wyrażeń regularnych wszystko poza grupą przechwytującą nie jest uwzględniane w ekstrakcji. Nikt nie wie, dlaczego VBA RegEx działa inaczej i przechwytuje również "@". Aby się go pozbyć, możesz usunąć pierwszy znak z wyniku, zastępując go pustym ciągiem.
=REPLACE(RegExpExtract(A5, "@([a-z][a-z]{2,})", 1, FALSE), 1, 1, "") 
Wyrażenie regularne do wyodrębniania numerów telefonów
Numery telefonów mogą być zapisywane na wiele różnych sposobów, dlatego wymyślenie rozwiązania działającego we wszystkich okolicznościach jest prawie niemożliwe. Niemniej jednak możesz zapisać wszystkie formaty używane w twoim zestawie danych i spróbować je dopasować.
Dla tego przykładu stworzymy regex, który wyodrębni numery telefonów w każdym z tych formatów:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Wzór : \N(?\\\\\\NNiezależnie od tego, co się dzieje, \NNiezależnie od tego, co się dzieje.
- Pierwsza część \u0026aposiada zero lub jeden nawias otwierający, po którym następują trzy cyfry d{3}.
- Część [-.]* oznacza dowolny znak w nawiasach kwadratowych występujący 0 lub więcej razy: myślnik, kropka, spacja lub nawias zamykający.
- Następnie mamy znowu trzy cyfry d{3}, po których następuje dowolny myślnik, kropka lub spacja [-? występujące 0 lub 1 raz.
- Po niej znajduje się grupa czterech cyfr \u200.
- Wreszcie istnieje słowo granica \u200 określające, że szukany przez nas numer telefonu nie może być częścią większego numeru.
Kompletna formuła przyjmuje taki kształt:
=RegExpExtract(A5, "\"(?\"\"\")]\". 
Należy pamiętać, że powyższy regex może zwrócić kilka fałszywych wyników, takich jak 123) 456 7899 lub (123 456 7899. Poniższa wersja naprawia te problemy. Jednak ta składnia działa tylko w funkcjach VBA RegExp, a nie w klasycznych wyrażeniach regularnych.
Wzór : (\(\d{3}\)
Regex do wyodrębnienia daty z ciągu znaków
Wyrażenie regularne do wyodrębniania daty zależy od formatu, w jakim data pojawia się wewnątrz łańcucha. Na przykład:
Aby wyodrębnić daty takie jak 1/1/21 lub 01/01/2021, regex jest następujący: \u200 \u200 \u200 \u200 \u200 \u200 \u200 \u200
Wyszukuje grupę 1 lub 2 cyfr d{1,2}, po której następuje ukośnik, a następnie kolejną grupę 1 lub 2 cyfr, po której następuje ukośnik, a następnie grupę 4 lub 2 cyfr ({4}pierwszy warunek jest w alternacji LUB konstrukcja jest dopasowana, pozostałe warunki nie są sprawdzane.
Aby pobrać daty takie jak 1-Jan-21 lub 01-Jan-2021, wzór jest następujący: \u200}-[A-Za-z]{3}-\u200}.
Wyszukuje grupę 1 lub 2 cyfr, po których następuje myślnik, a następnie grupę 3 dużych lub małych liter, po których następuje myślnik, a następnie grupę 4 lub 2 cyfr.
Po połączeniu tych dwóch wzorców razem, otrzymujemy następujący regex:
Wzór : ●●[●●](●●)
Gdzie:
- Pierwsza część to 1 lub 2 cyfry:.
- Druga część to albo 1 lub 2 cyfry, albo 3 litery: (ą, ę).
- Trzecia część to grupa 4 lub 2 cyfr: (ą).
- Delimiterem jest ukośnik do przodu lub myślnik: [ą]
- Po obu stronach umieszcza się granicę wyrazów, aby było jasne, że data jest osobnym słowem, a nie częścią większego ciągu.
Jak widać na poniższym obrazku, program z powodzeniem wyciąga daty i pomija podłańcuchy takie jak 11/22/333, jednak nadal zwraca wyniki fałszywie pozytywne. W naszym przypadku podłańcuch 11-ABC-2222 w A9 technicznie pasuje do formatu daty dd-mmm-rrrr i dlatego jest wydobywany. 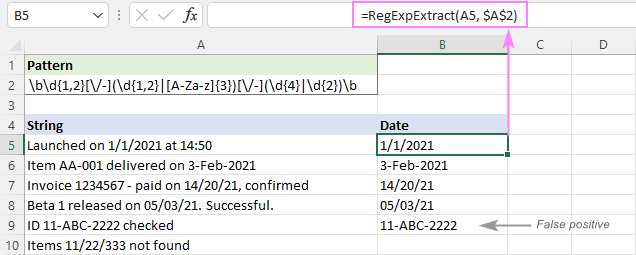
Aby wyeliminować fałszywe pozytywy, możesz zastąpić część [A-Za-z]{3} pełną listą trzyliterowych skrótów miesięcy:
Wzór : ●●[●●](●●)
Aby zignorować wielkość liter, ustawiamy ostatni argument naszej niestandardowej funkcji na FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
I tym razem otrzymujemy doskonały wynik: 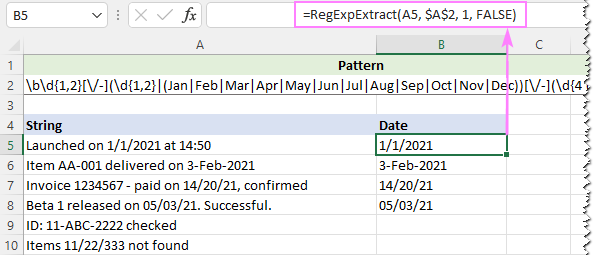
Regex do wyodrębnienia czasu z ciągu znaków
Aby uzyskać czas w hh:mm lub hh:mm:ss format, następujące wyrażenie będzie działało jak należy.
Wzór
Rozbijając ten regex, można zauważyć 2 części oddzielone przez
Wyrażenie 1
Pobiera czasy z AM/PM.
Godzina może być dowolną liczbą od 0 do 12. Aby ją otrzymać, używamy konstrukcji OR ([0-9]
- [0-9] pasuje do każdej liczby od 0 do 9
- 1[0-2] pasuje do każdej liczby od 10 do 12
Minuta [0-5]- to dowolna liczba od 00 do 59.
Druga (:[0-5])? to również dowolna liczba z zakresu od 00 do 59. Kwantyfikator ? oznacza zero lub jedno wystąpienie, ponieważ sekundy mogą być zawarte w wartości czasu lub nie.
Wyrażenie 2 : \b([0-9]
Wyciąga czasy bez AM/PM.
Na stronie godzina część może być dowolną liczbą od 0 do 32. Aby ją uzyskać, należy zastosować inną konstrukcję OR ([0-9]
- [0-9] pasuje do każdej liczby od 0 do 9
- [0-1] pasuje do każdej liczby od 00 do 19.
- 2[0-3] pasuje do każdej liczby od 20 do 23
Na stronie minuta oraz druga części są takie same jak w wyrażeniu 1 powyżej.
Ujemny lookahead (?!:) jest dodawany do ciągów pomijanych, takich jak 20:30:80.
Ponieważ PM/AM mogą być zarówno duże jak i małe litery, czynimy funkcję niewrażliwą na wielkość liter:
=RegExpExtract(A5, $A$2, 1, FALSE) 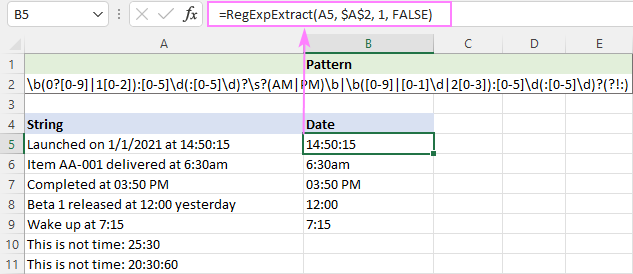
Mam nadzieję, że powyższe przykłady podsunęły Ci kilka pomysłów na wykorzystanie wyrażeń regularnych w arkuszach Excela. Niestety, nie wszystkie funkcje klasycznych wyrażeń regularnych są obsługiwane w VBA. Jeśli Twoje zadanie nie może być zrealizowane za pomocą VBA RegExp, zachęcam do przeczytania kolejnej części, w której omówione zostaną dużo bardziej rozbudowane funkcje .NET Regex.
Niestandardowa funkcja Regex oparta na .NET do wyodrębniania tekstu w Excelu
W przeciwieństwie do funkcji VBA RegExp, które może napisać każdy użytkownik Excela, .NET RegEx to królestwo dewelopera. Microsoft .NET Framework obsługuje w pełni funkcjonalną składnię wyrażeń regularnych zgodną z Perlem 5. Ten artykuł nie nauczy Cię jak pisać takie funkcje (nie jestem programistą i nie mam najmniejszego pojęcia jak to zrobić :)
Cztery potężne funkcje przetwarzane przez standardowy silnik .NET RegEx zostały już napisane przez naszych programistów i zawarte w Ultimate Suite. Poniżej zademonstrujemy kilka praktycznych zastosowań funkcji zaprojektowanej specjalnie do wyodrębniania tekstu w Excelu.
Wskazówka. Informacje na temat składni .NET Regex można znaleźć w .NET Regular Expression Language.
Jak wyodrębnić żądła w Excelu za pomocą wyrażeń regularnych
Zakładając, że masz zainstalowaną najnowszą wersję Ultimate Suite, wyodrębnianie tekstu przy użyciu wyrażeń regularnych sprowadza się do następujących dwóch kroków:
- Na Dane Ablebits zakładka, w Tekst grupa, kliknij Narzędzia Regex .

- Na Narzędzia Regex Wybierz dane źródłowe, wpisz wzór Regex i wybierz Wyciąg Aby otrzymać wynik jako funkcję własną, a nie wartość, wybierz opcję Wstaw jako wzór Po zakończeniu kliknij przycisk Wyciąg przycisk.

Wyniki pojawią się w nowej kolumnie po prawej stronie twoich oryginalnych danych: 
Składnia AblebitsRegexExtract
Nasza niestandardowa funkcja ma następującą składnię:
AblebitsRegexExtract(reference, regular_expression)Gdzie:
- Odnośnik (wymagane) - odwołanie do komórki zawierającej ciąg źródłowy.
- Wyrażenie regularne (wymagane) - wzór regex do dopasowania.
Ważna uwaga! Funkcja działa tylko na maszynach z zainstalowanym pakietem Ultimate Suite for Excel.
Uwagi użytkowe
Aby nauka przebiegała łagodniej, a doświadczenie było przyjemniejsze, proszę zwrócić uwagę na poniższe punkty:
- Aby stworzyć formułę, możesz użyć naszego Narzędzia Regex , lub Excela Funkcja wstawiania Po wstawieniu formuły można nią zarządzać (edytować, kopiować, przenosić) jak każdą inną rodzimą formułą.
- Wzór wprowadzony na Narzędzia Regex Możliwe jest również zachowanie wyrażenia regularnego w osobnej komórce. W tym przypadku należy użyć odwołania do komórki dla drugiego argumentu.
- Funkcja wyodrębnia pierwszy znaleziony mecz .
- Domyślnie funkcja ta to. rozróżnianie wielkości liter Dla dopasowania bez rozróżniania wielkości liter należy użyć wzorca (?i).
- Jeśli nie zostanie znalezione dopasowanie, zwracany jest błąd #N/A.
Regex do wyodrębnienia ciągu pomiędzy dwoma znakami
Aby uzyskać tekst między dwoma znakami, możesz użyć grupy przechwytującej lub obejść.
Powiedzmy, że szukasz wyodrębnienia tekstu między nawiasami. Grupa przechwytująca jest najprostszym sposobem.
Wzór 1 : \[(.*?)\]
Przy pozytywnym spojrzeniu w tył i w przód wynik będzie dokładnie taki sam.
Wzór 2 : (?<=[)(.*?)(?=])
Proszę zwrócić uwagę, że nasza grupa przechwytująca (.*?) wykonuje leniwe poszukiwanie dla tekstu pomiędzy dwoma nawiasami - od pierwszego [ do pierwszego ]. Grupa przechwytująca bez znaku zapytania (.*) wykona chciwe szukanie i uchwycić wszystko od pierwszego [ do ostatniego ].
Mając wzór w A2, formuła przebiega następująco:
=AblebitsRegexExtract(A5, $A$2) 
Jak zdobyć wszystkie mecze
Jak już wspomniano, funkcja AblebitsRegexExtract może wyodrębnić tylko jedno dopasowanie. Aby uzyskać wszystkie dopasowania, możesz użyć funkcji VBA, którą omówiliśmy wcześniej. Jest jednak jedno zastrzeżenie - VBA RegExp nie obsługuje przechwytywania grup, więc powyższy wzór zwróci również znaki "graniczne", nawiasy w naszym przypadku.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Aby pozbyć się nawiasów, ZASTĄP je pustymi ciągami ("") za pomocą tego wzoru:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[",")
Dla lepszej czytelności używamy przecinka jako delimitera. 
Regex do wyodrębnienia tekstu pomiędzy dwoma ciągami
Podejście, które wypracowaliśmy dla wyciągania tekstu między dwoma znakami, będzie również działać dla wyodrębniania tekstu między dwoma ciągami.
Na przykład, aby uzyskać wszystko między "testem 1" a "testem 2", użyj następującego wyrażenia regularnego.
Wzór : test 1(.*?)test 2
Pełna formuła to:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex do wyodrębnienia domeny z adresu URL
Nawet przy użyciu wyrażeń regularnych, wyodrębnianie nazw domen z adresów URL nie jest trywialnym zadaniem. Kluczowym elementem, który robi tę sztuczkę są grupy nie przechwytujące. W zależności od ostatecznego celu, wybierz jeden z poniższych regexów.
Aby uzyskać pełna nazwa domeny w tym subdomeny
Wzór : (?:https?
Aby uzyskać drugi poziom domena bez subdomen
Wzór : (?:https?
Teraz zobaczmy, jak te wyrażenia regularne działają na przykładzie "//www.mobile.ablebits.com" jako przykładowy adres URL:
- (?:https?
- \/\/ ą - dwa ukośniki w przód (każdy z nich poprzedzony jest odwrotnym ukośnikiem, aby uciec od specjalnego znaczenia ukośnika w przód i zinterpretować go dosłownie).
- (?:[A-Za-zależne] {2,255}} - grupa nie przechwytująca, służąca do identyfikacji domen trzeciego poziomu, czwartego poziomu itd. jeśli istnieją ( mobilny W pierwszym wzorcu jest on umieszczony w większej grupie przechwytującej, aby wszystkie takie subdomeny zostały włączone do ekstrakcji. Subdomena może mieć długość od 2 do 255 znaków, stąd kwantyfikator {2,255}.
- ([A-Za-z]{1,63}) - grupa przechwytująca do wyodrębnienia domeny drugiego poziomu ( ablebits ) oraz domenę najwyższego poziomu ( com ). Maksymalna długość domeny drugiego poziomu wynosi 63 znaki. Najdłuższa obecnie istniejąca domena najwyższego poziomu zawiera 24 znaki.
W zależności od tego, jakie wyrażenie regularne zostanie wpisane w A2, poniższa formuła da różne wyniki:
=AblebitsRegexExtract(A5, $A$2)
Regex do wyodrębnienia pełna nazwa domeny ze wszystkimi subdomenami: 
Regex do wyodrębnienia drugi poziom domena bez subdomen: 
Oto jak wyodrębnić fragmenty tekstu w Excelu za pomocą wyrażeń regularnych. Dziękuję za lekturę i czekam na Ciebie na naszym blogu za tydzień!
Dostępne pliki do pobrania
Przykłady Excel Regex Extract (plik .xlsm)
Wersja próbna Ultimate Suite (plik .exe)
