
Sisukord
Selles õpetuses saate teada, kuidas kasutada regulaarseid väljendeid Excelis, et leida ja eraldada antud mustrile vastavaid alamsõnu.
Microsoft Excel pakub mitmeid funktsioone teksti lahtritest väljavõtmiseks. Need funktsioonid saavad hakkama enamiku stringide väljavõtmise probleemidega teie töölehtedel. Enamiku, kuid mitte kõigiga. Kui tekstifunktsioonid komistavad, tulevad appi regulaaravaldised. Oot... Excelil ei ole RegEx-funktsioone! Tõsi, sisseehitatud funktsioone ei ole. Aga miski ei takista teid kasutamast oma funktsioone :)
Exceli VBA Regex funktsioon stringide väljavõtmiseks
Selleks, et lisada Excelisse kohandatud Regex Extract funktsioon, kleepige VBA redaktorisse järgmine kood. Selleks, et VBA-s regulaarseid väljendeid lubada, kasutame sisseehitatud Microsoft RegExp objekti.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionKui teil on VBAga vähe kogemusi, võib abiks olla samm-sammult kasutamisjuhend: Kuidas sisestada VBA-koodi Excelis.
Märkus. Funktsiooni toimimiseks tuleb fail kindlasti salvestada failina makrotoimingutega töövihik (.xlsm).
RegExpExtract süntaks
The RegExpExtract funktsioon otsib sisendistringist väärtusi, mis vastavad regulaaravaldisele, ja eraldab ühe või kõik vasted.
Funktsioonil on järgmine süntaks:
RegExpExtract(text, pattern, [instance_num], [match_case])Kus:
- Tekst (nõutav) - tekstirida, mille järgi otsitakse.
- Muster (nõutav) - vastav regulaarväljend. Kui see esitatakse otse valemis, tuleb muster sulgeda topeltlausejoonistega.
- Instance_num (valikuline) - seerianumber, mis näitab, millist eksemplari ekstraheerida. Kui see jäetakse välja, tagastatakse kõik leitud vasted (vaikimisi).
- Match_case (valikuline) - määrab, kas teksti suur- ja väiketähelepanu arvestatakse või ignoreeritakse. Kui TRUE või jäetakse välja (vaikimisi), siis tehakse suur- ja väiketähelepanu arvestamine; kui FALSE - suur- ja väiketähelepanu ei arvestata.
Funktsioon töötab kõigis Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 ja Excel 2010 versioonides.
4 asja, mida peaksite teadma RegExpExtracti kohta
Funktsiooni tõhusaks kasutamiseks Excelis on mõned olulised asjad, mida tuleb tähele panna:
- Vaikimisi tagastab funktsioon kõik leitud vasted naaberruutudesse, nagu on näidatud selles näites. Konkreetse esinemise saamiseks tuleb anda vastav number, et instance_num argument.
- Vaikimisi on funktsioon suur- ja väiketähelepanu Suur- ja väiketähtedest sõltumata sobitamiseks tuleb määrata parameeter match_case argumenti FALSE. VBA piirangute tõttu ei tööta suur- ja väiketähelepanuta konstruktsioon (?i).
- Kui kehtivat mustrit ei ole leitud , siis funktsioon ei tagasta midagi (tühi string).
- Kui muster on kehtetu , tekib #VALUE! viga.
Enne kui hakkate seda kohandatud funktsiooni oma töölehtedel kasutama, peate mõistma, milleks see on võimeline, eks? Allpool toodud näited hõlmavad mõnda levinud kasutusjuhtumit ja selgitavad, miks käitumine võib erineda Dynamic Array Excelis (Microsoft 365 ja Excel 2021) ja traditsioonilises Excelis (2019 ja vanemad versioonid).
Märkus. Välja toodud regexi näited on kirjutatud õiglase lihtsa andmekogumi jaoks. Me ei saa garanteerida, et need toimivad veatult teie reaalsetes töölehtedes. Need, kellel on regexiga kogemusi, nõustuvad, et regulaaravaldiste kirjutamine on lõputu tee täiuslikkuse poole - peaaegu alati on võimalus seda elegantsemaks muuta või võimeline töötlema laiemat valikut sisendandmeid.
Regex numbri väljavõtmiseks stringist
Järgides põhilist õpetamise põhimõtet "lihtsast keeruliseks", alustame väga lihtsa juhtumiga: numbri väljavõtmine stringist.
Kõigepealt tuleb otsustada, millist numbrit soovite välja otsida: esimest, viimast, konkreetset esinemist või kõiki numbreid.
Väljavõte esimesest numbrist
Arvestades, et \d tähendab mis tahes numbrit vahemikus 0 kuni 9 ja + tähendab ühte või mitut korda, on meie regulaaravaldis sellisel kujul:
Muster : \d+
Komplekt instance_num väärtuseks 1 ja saad soovitud tulemuse:
=RegExpExtract(A5, "\d+", 1)
Kus A5 on algne string.
Mugavuse huvides võite sisestada mustri eelnevalt määratud lahtrisse ($A$2 ) ja lukustada selle aadressi $-märgiga:
=RegExpExtract(A5, $A$2, 1) 
Hangi viimane number
Stringi viimase numbri väljavõtmiseks tuleb kasutada järgmist mustrit:
Muster : (\d+)(?!.*\d)
Inimkeelde tõlgituna ütleb see: leia number, millele ei järgne (mitte kusagil, mitte ainult kohe) ükski teine number. Selle väljendamiseks kasutame negatiivset lookahead (?!.*\d), mis tähendab, et mustrist paremal ei tohiks olla ühtegi teist numbrit (\d), sõltumata sellest, kui palju teisi sümboleid on enne seda.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Näpunäited:
- Et saada konkreetne esinemine , kasutage \d+ jaoks muster ja asjakohane seerianumber instance_num .
- Valem väljavõtte saamiseks kõik numbrid käsitletakse järgmises näites.
Regex kõigi vastete väljavõtmiseks
Kui meie näide läheb veidi kaugemale, siis oletame, et soovite saada stringist kõiki numbreid, mitte ainult ühte.
Nagu te ehk mäletate, kontrollitakse ekstraheeritud vastete arvu valikulise parameetriga instance_num Vaikimisi on kõik vasted, seega jätate selle parameetri lihtsalt välja:
=RegExpExtract(A2, "\d+")
Valem töötab ilusti ühe lahtri puhul, kuid dünaamilise massiivi Exceli ja mittedünaamilise versiooni käitumine erineb.
Excel 365 ja Excel 2021
Tänu dünaamiliste massiividega seotud toetusele valgub tavaline valem automaatselt nii paljudesse lahtritesse, kui on vaja kõigi arvutatud tulemuste kuvamiseks. Exceli mõistes nimetatakse seda valgustatud vahemikuks: 
Excel 2019 ja madalam
Dünaamikaeelses Excelis tagastaks ülaltoodud valem ainult ühe vaste. Mitme vaste saamiseks peate tegema sellest massiivi valemi. Selleks valige lahtrite vahemik, sisestage valem ja vajutage Ctrl + Shift + Enter, et seda täiendada.
Selle lähenemisviisi puuduseks on hunnik #N/A vigu, mis ilmnevad "lisarakkudes". Kahjuks ei saa selle vastu midagi teha (ei IFERROR ega IFNA ei saa seda paraku parandada). 
Väljavõte kõik vasted ühes lahtris
Andmete veeru töötlemisel ülaltoodud lähenemine ilmselgelt ei toimi. Sellisel juhul oleks ideaalne lahendus kõigi vastete tagastamine ühes lahtris. Selleks andke RegExpExtract'i tulemused funktsioonile TEXTJOIN ja eraldage need suvalise eraldaja, näiteks koma ja tühikuga:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Märkus. Kuna funktsioon TEXTJOIN on saadaval ainult Excelis Microsoft 365, Excel 2021 ja Excel 2019, ei tööta valem vanemates versioonides.
Regex teksti väljavõtmiseks stringist
Teksti väljavõtmine tähtnumbrilisest stringist on Excelis üsna keeruline ülesanne. Regeksiga muutub see lihtsaks kui pirukas. Kasutage lihtsalt eitavat klassi, et sobitada kõike, mis ei ole number.
Muster : [^\d]+
Üksikute lahtrite alajaotuste saamiseks (spill range) on valem:
=RegExpExtract(A5, "[^\d]+") 
Kõikide vastete väljastamiseks ühte lahtrisse pesastage funktsioon RegExpExtract funktsioonis TEXTJOIN järgmiselt:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Regex väljavõtte e-posti aadressi string
Et tõmmata e-posti aadressi välja stringist, mis sisaldab palju erinevat teavet, kirjutage regulaaravaldis, mis jäljendab e-posti aadressi struktuuri.
Muster : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Selle regexi lahtimõtestamisel saame järgmise tulemuse:
- [\w\.\-]+ on kasutajanimi, mis võib sisaldada 1 või enam tähtnumbrilist märki, allakriipsu, punkti ja sidekriipsu.
- @ sümbol
- [A-Za-z0-9\.\-]+ on domeeninimi, mis koosneb suurtest ja väikestest tähtedest, numbritest, sidekriipsudest ja punktidest (alamdomeenide puhul). Allkriipsud ei ole siin lubatud, seetõttu kasutatakse \w asemel 3 erinevat tähemärki (näiteks A-Z a-z ja 0-9), mis vastab mis tahes tähe, numbrile või allkriipsule.
- \.[A-Za-z]{2,24} on tippdomeen. Koosneb punktist, millele järgnevad suur- ja väiketähed. Enamik tippdomeene on 3-tähelised (nt .com .org, .edu jne), kuid teoreetiliselt võib see sisaldada 2 kuni 24 tähte (pikim registreeritud tippdomeen).
Eeldades, et string on A5-s ja muster A2-s, on meiliaadressi väljavõtte valem:
=RegExpExtract(A5, $A$2) 
Regex domeeni ekstraheerimiseks e-kirjast
Kui tegemist on e-posti domeeni ekstraheerimisega, on esimene mõte, mis tuleb pähe, kasutada püüdmisrühma, et leida tekst, mis järgneb kohe @-märgile.
Muster : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Andke see meie RegExp-funktsioonile:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Ja sa saad selle tulemuse: 
Klassikaliste regulaaravaldiste puhul ei kaasata väljavõtte koostamisse kõike, mis asub väljavõtterühmast väljaspool. Keegi ei tea, miks VBA RegEx töötab teisiti ja võtab ka "@". Sellest vabanemiseks saab esimese tähemärgi tulemusest eemaldada, asendades selle tühja stringiga.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Regulaaravaldis telefoninumbrite väljavõtmiseks
Telefoninumbreid võib kirjutada mitmel erineval viisil, mistõttu on peaaegu võimatu välja töötada igal juhul töötavat lahendust. Sellegipoolest võite kirjutada üles kõik oma andmestikus kasutatavad vormingud ja püüda neid sobitada.
Selle näite jaoks loome regexi, mis ekstraheerib telefoninumbrid mis tahes nimetatud formaadis:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Muster : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Esimene osa \(?\d{3} vastab nullile või ühele avatavale sulgemisele, millele järgneb kolm numbrit d{3}.
- Osa [-\. \)]* tähendab mis tahes märki, mis on nurksulgudes ja mida esineb 0 või rohkem korda: sidekriips, punkt, tühik või sulgudes olev tühik.
- Seejärel on meil jälle kolm numbrit d{3}, millele järgneb ükskõik milline sidekriips, punkt või tühik [-\. ]?, mis esineb 0 või 1 kord.
- Pärast seda on neljast numbrist koosnev rühm \d{4}.
- Lõpuks on olemas sõnapiir \b, mis määratleb, et otsitav telefoninumber ei saa olla osa suuremast numbrist.
Täielik valem võtab sellise kuju:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Pange tähele, et ülaltoodud regex võib anda mõned valepositiivsed tulemused, näiteks 123) 456 7899 või (123 456 7899. Allpool esitatud versioon parandab need probleemid. See süntaks töötab siiski ainult VBA RegExp-funktsioonides, mitte klassikalistes regulaaravaldistes.
Muster : (\(\d{3}\)
Regex kuupäeva väljavõtmiseks stringist
Regulaaravaldis kuupäeva väljavõtmiseks sõltub formaadist, milles kuupäev stringis esineb. Näiteks:
Kuupäevade nagu 1/1/21 või 01/01/2021 ekstraheerimiseks on regex: \d{1,2}\/\d{1,2}\/(\d{4})
Otsitakse 1 või 2 numbrist koosnevat rühma d{1,2}, millele järgneb kaldkriips, millele järgneb veel üks 1 või 2 numbrist koosnev rühm, millele järgneb kaldkriips, millele järgneb 4 või 2 numbrist koosnev rühm (\d{4}esimene tingimus on vaheldumisi VÕI-konstruktsioonis, ülejäänud tingimusi ei kontrollita.
Selliste kuupäevade nagu 1-Jan-21 või 01-Jan-2021 saamiseks on muster: \d{1,2}-[A-Za-z]{3}-\d{2,4}.
See otsib 1 või 2 numbrist koosnevat rühma, millele järgneb sidekriips, millele järgneb 3 suur- või väiketähest koosnev rühm, millele järgneb sidekriips, millele järgneb 4 või 2 numbrist koosnev rühm.
Pärast kahe mustri kombineerimist saame järgmise regexi:
Muster : \b\d{1,2}[\/-](\d{1,2}
Kus:
- Esimene osa on 1- või 2-kohaline: \d{1,2}
- Teine osa on kas 1 või 2 numbrit või 3 tähte: (\d{1,2}
- Kolmas osa on 4- või 2-kohaline rühm: (\d{4}
- Eraldaja on kas kaldkriips või sidekriips: [\/-]
- Mõlemale poole pannakse sõnapiir \b, et teha selgeks, et kuupäev on eraldi sõna, mitte osa suuremast stringist.
Nagu allolevalt pildilt näha, tõmbab see edukalt välja kuupäevad ja jätab välja alamjooned nagu 11/22/333. Siiski annab see ikkagi valepositiivseid tulemusi. Meie puhul vastab alamjada 11-ABC-2222 A9 tehniliselt kuupäevaformaadile. dd-mmm-yyyy ja seetõttu ekstraheeritakse. 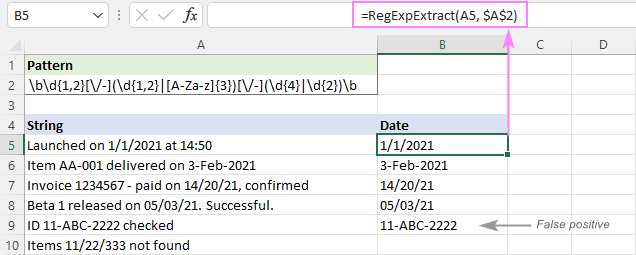
Valepositiivsete leidude kõrvaldamiseks võite asendada [A-Za-z]{3} osa 3-tähelise kuu lühendite täieliku loeteluga:
Muster : \b\d{1,2}[\/-](\d{1,2}
Et mitte arvestada tähtede suurust, seame oma kohandatud funktsiooni viimaseks argumendiks FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Ja seekord saame täiusliku tulemuse: 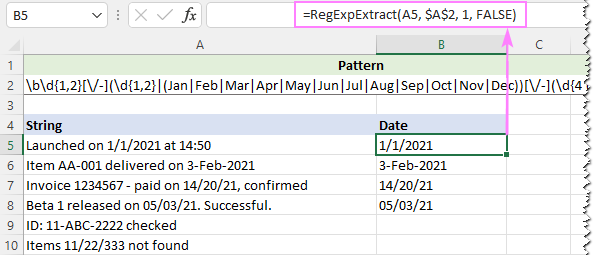
Regex, et ekstraheerida aeg stringist
Et saada aega hh:mm või hh:mm:ss formaadis, siis järgmine väljendus töötab suurepäraselt.
Muster : \b(0?[0-9]
Selle regexi lahtimõtestamisel näete 2 osa, mis on eraldatud järgmiselt
Väljendus 1 : \b(0?[0-9]
Otsib kellaaegasid AM/PM.
Tund võib olla mis tahes number vahemikus 0-12. Selle saamiseks kasutame OR-konstruktsiooni ([0-9]
- [0-9] vastab mis tahes numbrile 0 kuni 9.
- 1[0-2] vastab mis tahes numbrile vahemikus 10 kuni 12.
Hetk [0-5]\d on mis tahes number vahemikus 00-59.
Teine (:[0-5]\d)? on ka mis tahes arv vahemikus 00-59. Kvantifikaator ? tähendab nulli või ühte esinemist, sest sekundid võivad olla aja väärtuses sees või mitte.
Väljendus 2 : \b([0-9]
Väljavõte kellaaegadest ilma AM/PM.
The tund osa võib olla mis tahes number vahemikus 0 kuni 32. Selle saamiseks tuleb kasutada teistsugust OR-konstruktsiooni ([0-9]
- [0-9] vastab mis tahes numbrile 0 kuni 9.
- [0-1]\d vastab mis tahes numbrile vahemikus 00 kuni 19.
- 2[0-3] vastab mis tahes numbrile 20-23
The minut ja teine osad on samad, mis eespool esitatud väljendis 1.
Negatiivne lookahead (?!:) on lisatud sellistele vahelejätmissõnadele nagu 20:30:80.
Kuna PM/AM võib olla nii suur- kui ka väiketähtedega, siis ei ole funktsioonis suur- ja väiketähtedest sõltuv:
=RegExpExtract(A5, $A$2, 1, FALSE) 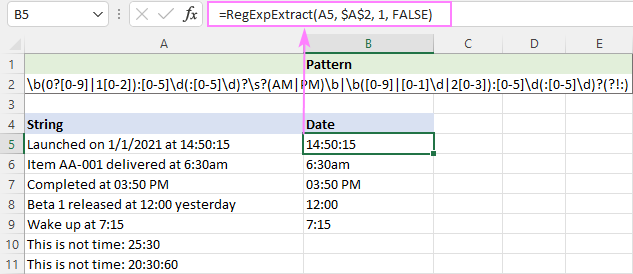
Loodetavasti andsid ülaltoodud näited teile mõned ideed, kuidas kasutada regulaarseid väljendeid oma Exceli töölehtedel. Kahjuks ei toeta VBA kõiki klassikaliste regulaarseid väljendeid. Kui teie ülesanne ei ole VBA RegExpiga saavutatav, soovitan teil lugeda järgmist osa, kus käsitletakse palju võimsamaid .NET Regex-funktsioone.
Kohandatud .NET-põhine Regex-funktsioon teksti väljavõtmiseks Excelis
Erinevalt VBA RegExp funktsioonidest, mida saab kirjutada iga Exceli kasutaja, on .NET RegEx arendajate pärusmaa. Microsoft .NET raamistik toetab täisfunktsionaalset regulaaravaldiste süntaksit, mis ühildub Perl 5. See artikkel ei õpeta teile, kuidas selliseid funktsioone kirjutada (ma ei ole programmeerija ja mul pole vähimatki aimu, kuidas seda teha :)
Meie arendajad on juba kirjutanud neli võimsat funktsiooni, mida töödeldakse standardse .NET RegEx-mootori abil ja mis on lisatud Ultimate Suite'i. Järgnevalt näitame mõningaid praktilisi kasutusvõimalusi, mis on spetsiaalselt mõeldud teksti väljavõtmiseks Excelis.
Vihje. Teavet .NET Regexi süntaksi kohta leiate dokumendist .NET Regular Expression Language.
Kuidas ekstraheerida särge Excelis, kasutades regulaarseid väljendeid
Eeldades, et teil on paigaldatud Ultimate Suite'i uusim versioon, on teksti ekstraheerimine regulaaravaldiste abil piiratud nende kahe sammuga:
- On Ablebits andmed vahekaardil Tekst rühma, klõpsake Regex tööriistad .

- On Regex tööriistad paneel, valige lähteandmed, sisestage oma Regex muster ja valige käsk Väljavõte valiku. Et saada tulemus kohandatud funktsioonina, mitte väärtusena, valige valik Sisesta valemina märkeruut. Kui olete valmis, klõpsake Väljavõte nupp.

Tulemused ilmuvad uues veerus teie algsetest andmetest paremal: 
AblebitsRegexExtract süntaks
Meie kohandatud funktsioonil on järgmine süntaks:
AblebitsRegexExtract(reference, regular_expression)Kus:
- Viide (nõutav) - viide lahtrisse, mis sisaldab lähtekriipsu.
- Regulaarne_väljend (nõutav) - regex-muster, millele tuleb sobitada.
Oluline märkus! Funktsioon töötab ainult masinatel, kus on installitud Ultimate Suite for Excel.
Kasutamise märkused
Selleks, et muuta õppimine sujuvamaks ja kogemus meeldivamaks, pöörake tähelepanu järgmistele punktidele:
- Valemi loomiseks saate kasutada meie Regex tööriistad , või Exceli Sisestage funktsioon Kui valem on sisestatud, saate seda hallata (redigeerida, kopeerida või teisaldada) nagu iga algupärast valemit.
- Muster, mille sisestate Regex tööriistad pane läheb 2. argumendile. Samuti on võimalik hoida regulaaravaldist eraldi lahtris. Sel juhul kasutage 2. argumendi jaoks lihtsalt lahtriviidet.
- Funktsioon eraldab esimene leitud kokkulangevus .
- Vaikimisi on funktsioon suur- ja väiketähelepanu Suur- ja väiketähtedest sõltumatu sobitamise puhul kasutage mustrit (?i).
- Kui vastet ei leita, tagastatakse #N/A viga.
Regex kahe tähemärgi vahelise stringi väljavõtmiseks
Kahe tähemärgi vahel oleva teksti saamiseks võite kasutada kas püüdmisrühma või look-aroundi.
Ütleme, et soovite teksti sulgude vahelt välja võtta. Kõige lihtsam viis on kinnipüüdmisrühm.
Muster 1 : \[(.*?)\]
Positiivse lookbehind'i ja lookahead'i puhul on tulemus täpselt sama.
Muster 2 : (?<=\[)(.*?)(?=\])
Palun pöörake tähelepanu sellele, et meie pildistamisrühm (.*?) teostab laisk otsing kahe sulgudes oleva teksti jaoks - esimesest [ kuni esimese ]. Püügirühm ilma küsimärgita (.*) teeksid ahne otsing ja jäädvustada kõik esimesest [ kuni viimaseni ].
A2 mustri puhul on valem järgmine:
=AblebitsRegexExtract(A5, $A$2) 
Kuidas saada kõiki vasteid
Nagu juba mainitud, saab funktsioon AblebitsRegexExtract ainult ühe vaste välja võtta. Kõikide vastete saamiseks võite kasutada VBA funktsiooni, mida me eelnevalt arutasime. Siiski on üks hoiatus - VBA RegExp ei toeta gruppide hõivamist, seega tagastab ülaltoodud muster ka "piirimärgid", meie puhul sulgudes.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Et sulgudest vabaneda, asendage need tühjade stringidega (""), kasutades seda valemit:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Parema loetavuse huvides kasutame eraldajana koma. 
Regex kahe stringi vahelise teksti väljavõtmiseks
Lähenemisviis, mille me oleme välja töötanud kahe tähemärgi vahel oleva teksti väljatõmbamiseks, töötab ka kahe stringi vahel oleva teksti väljatõmbamiseks.
Näiteks, et saada kõik "test 1" ja "test 2" vahele, kasutage järgmist regulaaravaldist.
Muster : test 1(.*?)test 2
Täielik valem on:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex URL-i domeeni ekstraheerimiseks
Isegi regulaaravaldiste abil ei ole domeeninimede eraldamine URL-idest triviaalne ülesanne. Võtmeelemendiks, mis teeb trikki, on mitte-peegeldavad rühmad. Sõltuvalt teie lõppeesmärgist valige üks allpool toodud regexidest.
Et saada täielik domeeninimi sealhulgas alamdomeenid
Muster : (?:https?\:
Et saada teise tasandi domeen ilma alamdomeenideta
Muster : (?:https?\:
Nüüd vaatame, kuidas need regulaaravaldised töötavad näite "//www.mobile.ablebits.com" kui näite-URL-i puhul:
- (?:https?\:
- \/\/ - kaks kaldkriipsu (mõlemale eelneb kaldkriips, et vältida kaldkriipsu erilist tähendust ja tõlgendada seda sõna-sõnalt).
- (?:[A-Za-za-z\d\-\.]{2,255}\.)? - mittekapteeriv rühm kolmanda ja neljanda taseme jne domeenide tuvastamiseks, kui need on olemas ( mobiilne meie näite-URL-is). Esimeses mustris paigutatakse see suurema püüdmisrühma sisse, et saada kõik sellised alamdomeenid ekstraheerimisel arvesse võetud. Alamdomeen võib olla 2 kuni 255 tähemärki pikk, sellest ka kvantifikaator {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - teise tasandi domeeni väljavõtte tegemise rühm ( ablebits ) ja tippdomeen ( com ). Teise taseme domeeni maksimaalne pikkus on 63 tähemärki. Pikim praegu olemasolev tippdomeen sisaldab 24 tähemärki.
Sõltuvalt sellest, milline regulaarväljend on sisestatud A2, annab alltoodud valem erinevaid tulemusi:
=AblebitsRegexExtract(A5, $A$2)
Regex ekstraheerimiseks täielik domeeninimi koos kõigi alamdomeenidega: 
Regex ekstraheerimiseks teise tasandi domeen ilma alamdomeenideta: 
See ongi, kuidas tekstiosasid Excelis regulaaravaldiste abil välja võtta. Tänan teid lugemise eest ja ootan teid järgmisel nädalal meie blogis!
Saadaolevad allalaadimised
Excel Regexi väljavõtte näited (.xlsm fail)
Ultimate Suite'i prooviversioon (.exe fail)
