
Tartalomjegyzék
Ebben a bemutatóban megtanulhatja, hogyan használhatja a reguláris kifejezéseket az Excelben egy adott mintának megfelelő részláncok keresésére és kivonására.
A Microsoft Excel számos függvényt biztosít a szöveg cellákból történő kinyeréséhez. Ezek a függvények a legtöbb karakterlánc-kivonási kihívással megbirkóznak a munkalapokon. A legtöbbel, de nem az összesel. Amikor a szövegfüggvények megbotlanak, a reguláris kifejezések jönnek segítségül. Várjunk csak... az Excelnek nincsenek RegEx függvényei! Igaz, nincsenek beépített függvények. De semmi sem akadályozza meg, hogy sajátokat használjon :)
Excel VBA Regex funkció a karakterláncok kivonatához
Ha egyéni Regex Extract funkciót szeretne hozzáadni az Excelhez, illessze be az alábbi kódot a VBA-szerkesztőbe. A szabályos kifejezések VBA-ban történő engedélyezéséhez a beépített Microsoft RegExp objektumot használjuk.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ( "VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.ignorecase = False Else regex.ignorecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Function ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionHa kevés tapasztalattal rendelkezik a VBA-val kapcsolatban, hasznos lehet egy lépésről lépésre történő felhasználói útmutató: Hogyan illesszünk be VBA-kódot az Excelbe.
Megjegyzés: Ahhoz, hogy a funkció működjön, mindenképpen mentsük el a fájlt makroképes munkafüzet (.xlsm).
RegExpExtract szintaxis
A RegExpExtract függvény egy bemeneti karakterláncban keres olyan értékeket, amelyek megfelelnek egy reguláris kifejezésnek, és kivon egy vagy az összes találatot.
A függvény szintaxisa a következő:
RegExpExtract(text, pattern, [instance_num], [match_case])Hol:
- Szöveg (kötelező) - a keresendő szöveges karakterlánc.
- Mintázat (kötelező) - az egyezni kívánt reguláris kifejezés. Ha közvetlenül egy képletben adjuk meg, a mintát dupla idézőjelek közé kell zárni.
- Instance_num (opcionális) - egy sorszám, amely jelzi, hogy melyik példányt kell kinyerni. Ha elhagyja, az összes talált egyezést adja vissza (alapértelmezett).
- Match_case (opcionális) - meghatározza, hogy a szöveg esetek szerinti megfeleltetése vagy figyelmen kívül hagyása történjen-e. Ha TRUE vagy elhagyja (alapértelmezett), akkor a szövegek eset-érzékeny megfeleltetése történik; ha FALSE - eset-érzéketlen.
A funkció az Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 és Excel 2010 összes verziójában működik.
4 dolog, amit a RegExpExtract-ról tudnia kell
Ahhoz, hogy hatékonyan használhassa a funkciót az Excelben, néhány fontos dolgot figyelembe kell vennie:
- Alapértelmezés szerint a függvény visszaadja a minden talált találat a szomszédos cellákba, ahogyan a példában látható. Egy adott előforduláshoz adjon meg egy megfelelő számot a instance_num érv.
- Alapértelmezés szerint a funkció case-sensitive Nagy- és kisbetű-független megfeleltetéshez állítsa be a match_case argumentumot FALSE-re. A VBA korlátai miatt a nagy- és kisbetűket nem érzékelő konstrukció (?i) nem fog működni.
- Ha egy érvényes minta nem található , a függvény nem ad vissza semmit (üres karakterlánc).
- Ha a a minta érvénytelen , #VALUE! hiba lép fel.
Mielőtt elkezdené használni ezt az egyéni függvényt a munkalapjain, meg kell értenie, hogy mire képes, igaz? Az alábbi példák néhány gyakori felhasználási esetet fednek le, és elmagyarázzák, hogy miért különbözhet a viselkedés a Dynamic Array Excel (Microsoft 365 és Excel 2021) és a hagyományos Excel (2019 és régebbi verziók) esetében.
Megjegyzés: A kiadott regex példák tündérien egyszerű adathalmazokra íródtak. Nem tudjuk garantálni, hogy hibátlanul működnek majd a valódi munkalapokon. Akiknek van tapasztalatuk a regexszel, egyetértenek abban, hogy a reguláris kifejezések írása egy soha véget nem érő út a tökéletesség felé - szinte mindig van mód arra, hogy elegánsabbá tegyük, vagy hogy a bemeneti adatok szélesebb körét tudjuk kezelni.
Regex szám kivonásához a stringből
Az "egyszerűtől a bonyolultig" tanítás alapelvét követve egy nagyon egyszerű esettel kezdünk: szám kivonása stringből.
Az első dolog, amit el kell döntenie, hogy melyik számot kéri le: az elsőt, az utolsót, egy adott előfordulást vagy az összes számot.
Az első szám kivonása
Ez a legegyszerűbb regex, amit csak lehet. Mivel a \d 0 és 9 közötti bármely számjegyet jelent, a + pedig egy vagy több számjegyet, a reguláris kifejezésünk a következő formát ölti:
Mintázat : \d+
Állítsa be a instance_num 1-re, és megkapja a kívánt eredményt:
=RegExpExtract(A5, "\d+", 1)
Ahol A5 az eredeti karakterlánc.
Az egyszerűség kedvéért a mintát egy előre meghatározott cellába is beírhatja ($A$2 ), és a címét a $ jellel rögzítheti:
=RegExpExtract(A5, $A$2, 1) 
Utolsó szám lekérdezése
Egy karakterlánc utolsó számának kinyeréséhez a következő mintát kell használni:
Mintázat : (\d+)(?!.*\d)
Emberi nyelvre lefordítva azt mondja: keress egy olyan számot, amelyet nem követ (sehol, nem csak közvetlenül) semmilyen más szám. Ennek kifejezésére negatív előretekintést használunk (?!.*\d), ami azt jelenti, hogy a mintától jobbra nem lehet más számjegy (\d), függetlenül attól, hogy hány karakter van előtte.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Tippek:
- Ahhoz, hogy egy konkrét előfordulás , használja a \d+ -t a minta és a megfelelő sorozatszámot a instance_num .
- A kivonási képlet minden szám a következő példában tárgyaljuk.
Regex az összes egyezés kivonatolásához
Ha a példánkat egy kicsit továbbvisszük, tegyük fel, hogy egy karakterláncból az összes számot ki akarjuk nyerni, nem csak egyet.
Mint emlékezhetsz, a kivont találatok számát az opcionális instance_num Az alapértelmezett az összes találat, így egyszerűen elhagyhatja ezt a paramétert:
=RegExpExtract(A2, "\d+")
A képlet egyetlen cella esetében szépen működik, de a viselkedés különbözik a Dynamic Array Excel és a nem dinamikus verziókban.
Excel 365 és Excel 2021
A dinamikus tömbök támogatásának köszönhetően egy szabályos képlet automatikusan annyi cellába ömlik, ahány cellára szükség van az összes számított eredmény megjelenítéséhez. Az Excel szempontjából ezt ömlesztett tartománynak nevezzük: 
Excel 2019 és alacsonyabb
A dinamikus Excel előtti Excelben a fenti képlet csak egy találatot adna vissza. Ahhoz, hogy több találatot kapjon, tömbképletet kell készítenie. Ehhez jelölje ki a cellatartományt, írja be a képletet, majd a Ctrl + Shift + Enter billentyűkombinációval fejezze be.
Ennek a megközelítésnek a hátránya, hogy egy csomó #N/A hiba jelenik meg az "extra cellákban". Sajnos, ez ellen semmit sem lehet tenni (sem az IFERROR, sem az IFNA nem tudja kijavítani, sajnos). 
Az összes találat kivonása egy cellába
Egy adatoszlop feldolgozásakor a fenti megközelítés nyilvánvalóan nem fog működni. Ebben az esetben ideális megoldás lenne az összes találat egyetlen cellában történő visszaadása. Ehhez a RegExpExtract eredményeit a TEXTJOIN függvénynek kell kiszolgáltatni, és tetszőleges elválasztójelekkel, például vesszővel és szóközzel elválasztani:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Megjegyzés: Mivel a TEXTJOIN funkció csak a Microsoft 365, az Excel 2021 és az Excel 2019 Excelben érhető el, a képlet nem működik a régebbi verziókban.
Regex a szöveg kivonásához a karakterláncból
A szöveg kivonása egy alfanumerikus karakterláncból elég nagy kihívást jelentő feladat az Excelben. A regex segítségével ez olyan egyszerűvé válik, mint a pite. Csak használjon egy negált osztályt, hogy minden olyan dologgal megegyezzen, ami nem számjegy.
Mintázat : [^\d]+
Az egyes cellákban lévő részláncok (kiöntési tartomány) kinyeréséhez a képlet a következő:
=RegExpExtract(A5, "[^\d]+") 
Az összes találat egy cellába történő kimenetéhez a RegExpExtract függvényt a TEXTJOIN függvénybe fészkelje be a következőképpen:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\\d]+")) 
Regex az e-mail cím kivonásához a karakterláncból
Ha egy e-mail címet szeretne kiemelni egy sok különböző információt tartalmazó karakterláncból, írjon egy olyan reguláris kifejezést, amely lemásolja az e-mail cím szerkezetét.
Mintázat : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Ha lebontjuk ezt a regexet, a következőt kapjuk:
- [\w\.\-]+ egy felhasználónév, amely tartalmazhat 1 vagy több alfanumerikus karaktert, aláhúzásokat, pontokat és kötőjeleket.
- @ szimbólum
- [A-Za-z0-9\.\-]+ egy domain név, amely a következőkből áll: nagy- és kisbetűk, számjegyek, kötőjelek és pontok (aldomainek esetén). Az aláhúzás itt nem megengedett, ezért 3 különböző karakterkészletet (például A-Z a-z és 0-9) használnak a \w helyett, amely bármely betűre, számjegyre vagy aláhúzásra megfelel.
- \.[A-Za-z]{2,24} egy felső szintű domain. Egy pontból áll, amelyet nagy- és kisbetűk követnek. A legtöbb felső szintű domain 3 betűből áll (pl. .com .org, .edu stb.), de elméletileg 2 és 24 betű között lehet (a leghosszabb bejegyzett TLD).
Feltételezve, hogy a karakterlánc az A5-ben, a minta pedig az A2-ben található, az e-mail cím kinyeréséhez a következő képletet kell használni:
=RegExpExtract(A5, $A$2) 
Regex a domain kivonásához az e-mailből
Amikor az e-mail tartomány kinyeréséről van szó, az első gondolat, ami eszünkbe jut, az egy elfogó csoport használata a @ karaktert közvetlenül követő szöveg megtalálására.
Mintázat : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Adjuk meg a RegExp függvényünknek:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
És ezt az eredményt kapod: 
A klasszikus reguláris kifejezéseknél a megragadó csoporton kívül eső dolgok nem kerülnek bele a kivonatolásba. Senki sem tudja, hogy a VBA RegEx miért működik másképp, és miért ragadja meg a "@" karaktert is. Hogy megszabaduljon tőle, az első karaktert eltávolíthatja az eredményből, ha üres karakterlánccal helyettesíti.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, "") 
Szabályos kifejezés a telefonszámok kivonásához
A telefonszámokat sokféleképpen lehet írni, ezért szinte lehetetlen minden körülmények között működő megoldást találni. Mindazonáltal felírhatja az adatállományában használt összes formátumot, és megpróbálhatja megfeleltetni őket.
Ebben a példában egy olyan regexet hozunk létre, amely a fenti formátumok bármelyikében kivonja a telefonszámokat:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Mintázat : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Az első rész \(?\d{3} megfelel nulla vagy egy nyitó zárójelnek, amelyet három számjegy d{3} követ.
- A [-\. \)]* rész a szögletes zárójelben lévő bármely karaktert jelenti, amely 0 vagy több alkalommal jelenik meg: kötőjel, pont, szóköz vagy záró zárójel.
- Ezután ismét három számjegy d{3}, amelyet egy kötőjel, pont vagy szóköz [-\. ]? követ, amely 0 vagy 1 alkalommal jelenik meg.
- Ezután következik egy négy számjegyből álló csoport \d{4}.
- Végül van egy szóhatár \b, amely meghatározza, hogy a keresett telefonszám nem lehet egy nagyobb szám része.
A teljes képlet a következő formát ölti:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Kérjük, vegye figyelembe, hogy a fenti regex néhány hamis pozitív eredményt adhat vissza, mint például 123) 456 7899 vagy (123 456 7899. Az alábbi verzió kijavítja ezeket a problémákat. Ez a szintaxis azonban csak a VBA RegExp függvényekben működik, a klasszikus reguláris kifejezésekben nem.
Mintázat : (\(\d{3}\)
Regex a dátum kivonásához a karakterláncból
A dátum kinyerésére szolgáló reguláris kifejezés attól függ, hogy a dátum milyen formátumban jelenik meg a karakterláncon belül. Például:
Az olyan dátumok kinyeréséhez, mint 1/1/21 vagy 01/01/2021, a regex a következő: \d{1,2}\/\d{1,2}\/(\d{4})
Egy 1 vagy 2 számjegyből álló d{1,2} csoportot keres, amelyet egy kötőjel követ, majd egy másik 1 vagy 2 számjegyből álló csoportot, amelyet egy kötőjel követ, majd egy 4 vagy 2 számjegyből álló csoportot (\d{4}az első feltétel a váltakozó VAGY konstrukcióban szerepel, a többi feltétel nem kerül ellenőrzésre.
Az olyan dátumok lekérdezéséhez, mint 1-Jan-21 vagy 01-Jan-2021, a minta a következő: \d{1,2}-[A-Za-z]{3}-\d{2,4}
1 vagy 2 számjegyből álló csoportot keres, amelyet egy kötőjel követ, majd egy 3 nagy- vagy kisbetűből álló betűcsoportot, amelyet egy kötőjel követ, majd egy 4 vagy 2 számjegyből álló csoportot.
A két minta kombinálása után a következő regexet kapjuk:
Mintázat : \b\d{1,2}[\/-](\d{1,2}
Hol:
- Az első rész 1 vagy 2 számjegyű: \d{1,2}
- A második rész 1 vagy 2 számjegy vagy 3 betű: (\d{1,2}
- A harmadik rész egy 4 vagy 2 számjegyből álló csoport: (\d{4}
- Az elválasztójel vagy egy előremenő perjel vagy kötőjel: [\/-]
- A \b szóhatár mindkét oldalon szerepel, hogy egyértelművé tegye, hogy a dátum egy különálló szó, és nem egy nagyobb karakterlánc része.
Amint az alábbi képen látható, a program sikeresen kiveszi a dátumokat, és elhagyja az olyan részláncokat, mint 11/22/333. Azonban még mindig hamis pozitív eredményeket ad vissza. Esetünkben az A9-ben lévő 11-ABC-2222 részlánc technikailag megfelel a dátumformátumnak. dd-mmm-yyyyyy és ezért kivonják. 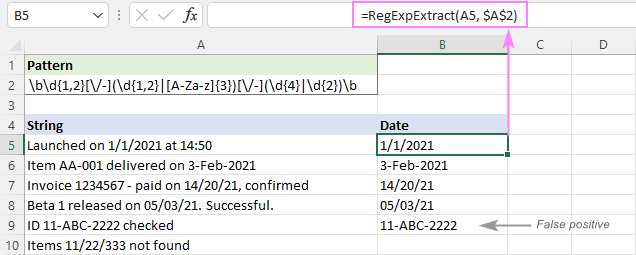
A téves pozitív eredmények kiküszöbölése érdekében a [A-Za-z]{3} részt helyettesítheti a 3 betűs hónapok rövidítéseinek teljes listájával:
Mintázat : \b\d{1,2}[\/-](\d{1,2}
A betűjelek figyelmen kívül hagyásához az egyéni függvényünk utolsó argumentumát FALSE értékre állítjuk:
=RegExpExtract(A5, $A$2, 1, FALSE)
És ezúttal tökéletes eredményt kapunk: 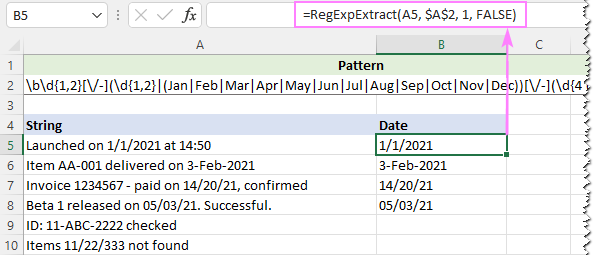
Regex az idő kivonásához a karakterláncból
Hogy időt nyerjen a hh:mm vagy hh:mm:ss formátumban, a következő kifejezés remekül fog működni.
Mintázat : \b(0?[0-9]
Ha ezt a regexet lebontjuk, akkor 2 részt láthatunk, amelyeket a következővel választunk el
Kifejezés 1 : \b(0?[0-9]
AM/PM időpontok lekérdezése.
Óra 0 és 12 közötti bármely szám lehet. Ennek kiszámításához a VAGY konstrukciót használjuk ([0-9]
- [0-9] 0 és 9 közötti bármelyik számra illik.
- 1[0-2] 10 és 12 közötti bármely számmal megegyezik.
Perc [0-5]\d bármely szám 00 és 59 között.
Második (:[0-5]\d)? szintén bármely szám 00 és 59 között. A ? kvantor nulla vagy egy előfordulást jelent, mivel a másodpercek szerepelhetnek vagy nem szerepelhetnek az időértékben.
Kifejezés 2 : \b([0-9]
Kiemeli az időpontokat AM/PM nélkül.
A óra rész lehet bármilyen szám 0 és 32 között. Ehhez egy másik VAGY konstrukció ([0-9]
- [0-9] 0 és 9 közötti bármelyik számra illik.
- [0-1]\d 00 és 19 közötti bármely számmal megegyezik
- 2[0-3] 20 és 23 közötti bármely számmal megegyezik.
A perc és második részek megegyeznek a fenti 1. kifejezésben szereplővel.
A negatív előretekintés (?!:) hozzáadódik az olyan kihagyott karakterláncokhoz, mint például 20:30:80.
Mivel a PM/AM lehet nagy- vagy kisbetűs, a funkciót a nagy- és kisbetűkre nem érzékenyítettük:
=RegExpExtract(A5, $A$2, 1, FALSE) 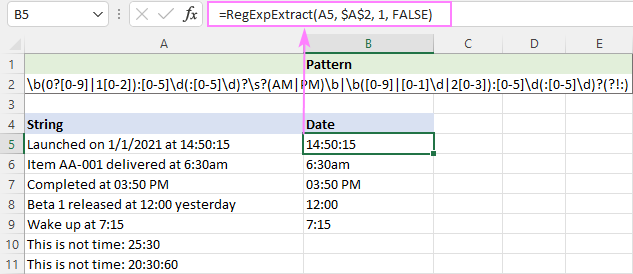
Remélhetőleg a fenti példák adtak néhány ötletet arra, hogyan használhatja a reguláris kifejezéseket az Excel munkalapjain. Sajnos a klasszikus reguláris kifejezések nem minden funkciója támogatott a VBA-ban. Ha a feladatát nem tudja elvégezni a VBA RegExp segítségével, akkor arra bátorítom, hogy olvassa el a következő részt, amely sokkal erősebb .NET Regex funkciókat tárgyal.
Egyéni .NET alapú Regex függvény a szöveg Excelben történő kivonatolásához
A VBA RegExp függvényekkel ellentétben, amelyeket bármely Excel felhasználó megírhat, a .NET RegEx a fejlesztők birodalma. A Microsoft .NET keretrendszer támogatja a Perl 5-tel kompatibilis, teljes értékű reguláris kifejezések szintaxisát. Ez a cikk nem fogja megtanítani, hogyan kell ilyen függvényeket írni (nem vagyok programozó, és a leghalványabb fogalmam sincs, hogyan kell ezt megtenni :)
Négy nagy teljesítményű, a szabványos .NET RegEx motor által feldolgozott függvényt fejlesztőink már megírtak, és az Ultimate Suite tartalmazza őket. Az alábbiakban bemutatjuk a kifejezetten az Excelben lévő szöveg kivonására tervezett függvény néhány gyakorlati felhasználását.
Tipp: A .NET Regex szintaxisáról a .NET Regular Expression Language című fejezetben talál információkat.
Hogyan lehet kivonni a szúrásokat az Excelben szabályos kifejezések használatával
Feltételezve, hogy az Ultimate Suite legújabb verziója van telepítve, a szöveg kinyerése a reguláris kifejezések segítségével a következő két lépésből áll:
- A Ablebits adatok lapon, a Szöveg csoport, kattintson a Regex eszközök .

- A Regex eszközök ablaktáblában jelölje ki a forrásadatokat, adja meg a Regex mintát, és válassza a Kivonat Ha az eredményt nem értékként, hanem egyéni függvényként szeretné megkapni, válassza a Beillesztés képletként Ha kész, kattintson a Kivonat gomb.

Az eredmények egy új oszlopban jelennek meg az eredeti adatok jobb oldalán: 
AblebitsRegexExtract szintaxis
Az egyéni függvényünk a következő szintaxissal rendelkezik:
AblebitsRegexExtract(reference, regular_expression)Hol:
- Hivatkozás (kötelező) - a forrás karakterláncot tartalmazó cellára való hivatkozás.
- Regular_expression (kötelező) - az egyezni kívánt regex minta.
Fontos megjegyzés: A funkció csak azokon a gépeken működik, amelyeken az Ultimate Suite for Excel telepítve van.
Felhasználási megjegyzések
Annak érdekében, hogy a tanulási folyamat zökkenőmentesebb és a tapasztalatai élvezetesebbek legyenek, kérjük, figyeljen az alábbi pontokra:
- Egy képlet létrehozásához használhatja a Regex eszközök , vagy az Excel Beillesztési funkció párbeszédpanelen, vagy írja be a függvény teljes nevét egy cellába. Miután a képlet beillesztésre került, ugyanúgy kezelheti (szerkesztheti, másolhatja vagy áthelyezheti), mint bármely natív képletet.
- A minta, amelyet a Regex eszközök panel a 2. argumentumra megy. Az is lehetséges, hogy a reguláris kifejezést egy külön cellában tartsuk. Ebben az esetben csak használjunk cellahivatkozást a 2. argumentumhoz.
- A függvény kivonja a első találat .
- Alapértelmezés szerint a funkció case-sensitive Nagy- és kisbetűket nem érzékelő párosításhoz használja a (?i) mintát.
- Ha nem talál egyezést, akkor egy #N/A hibaüzenet érkezik vissza.
Regex két karakter közötti karakterlánc kivonatolásához
A két karakter közötti szöveg megszerzéséhez használhat rögzítő csoportot vagy keresőcsoportot.
Tegyük fel, hogy a zárójelek közötti szöveget szeretnénk kinyerni. A legegyszerűbb módja a rögzítő csoport.
1. minta : \[(.*?)\]
Pozitív lookbehind és lookahead esetén az eredmény pontosan ugyanaz lesz.
2. minta : (?<=\[)(.*?)(?=\])
Kérjük, figyeljen arra, hogy a rögzítő csoportunk (.*?) egy lusta keresés a két zárójel közötti szövegre - az első [-től az első ]-ig. A kérdőjel nélküli (.*) rögzítő csoport a következő feladatot látja el mohó keresés és rögzítsenek mindent az elsőtől [ az utolsóig ].
Az A2-es mintával a képlet a következőképpen néz ki:
=AblebitsRegexExtract(A5, $A$2) 
Hogyan szerezzen meg minden mérkőzést
Mint már említettük, az AblebitsRegexExtract függvény csak egy találatot tud kinyerni. Az összes találat kinyeréséhez használhatjuk a korábban már tárgyalt VBA függvényt. Van azonban egy kikötés - a VBA RegExp nem támogatja a csoportok rögzítését, így a fenti minta a "határoló" karaktereket is visszaadja, esetünkben a zárójeleket.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
A zárójelek eltüntetéséhez helyettesítse őket üres karakterláncokkal ("") a következő képlet segítségével:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", TRUE, RegExpExtract(A5, $A$2))), "]", ""),"[",""")
A jobb olvashatóság érdekében vesszőt használunk elválasztójelként. 
Regex két karakterlánc közötti szöveg kivonására
A két karakter közötti szöveg kiemelésére kidolgozott megközelítés két karakterlánc közötti szöveg kiemelésére is működik.
Például, ha a "test 1" és a "test 2" között mindent ki akarunk kapni, használjuk a következő reguláris kifejezést.
Mintázat : teszt 1(.*?)teszt 2
A teljes képlet a következő:
=AblebitsRegexExtract(A5, "test 1(.*?)test 2") 
Regex a domain kivonásához az URL-ből
A domainnevek URL-ekből való kinyerése még a reguláris kifejezésekkel sem triviális feladat. A kulcselem, amely a trükköt véghezviszi, a nem elfogó csoportok. A végső céltól függően válasszon az alábbi regexek közül.
Ahhoz, hogy egy teljes domain név beleértve az aldomaineket is
Mintázat : (?:https?\:
Ahhoz, hogy egy másodszintű domain aldomainek nélkül
Mintázat : (?:https?\:
Most pedig nézzük meg, hogyan működnek ezek a reguláris kifejezések a "//www.mobile.ablebits.com" mint minta-URL-en:
- (?:https?\:
- \/\/ - két előremenő kötőjel (mindkettő előtt egy-egy backslash áll, hogy az előremenő kötőjel speciális jelentése megszűnjön, és szó szerint értelmezhető legyen).
- (?:[A-Za-z\d\d\-\.]{2,255}\.)? - nem rögzítő csoport a harmadik szintű, negyedik szintű stb. tartományok azonosítására, ha vannak ( mobil a mi minta-URL-ünkben). Az első mintában egy nagyobb befogadó csoporton belül helyezkedik el, hogy az összes ilyen aldomain bekerüljön a kivonatolásba. Egy aldomain 2 és 255 karakter között lehet hosszú, ezért a {2,255} kvantor.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - a második szintű tartomány kivonásához szükséges rögzítő csoport ( ablebits ) és a legfelső szintű domain ( com A második szintű tartomány maximális hossza 63 karakter. A jelenleg létező leghosszabb felső szintű tartomány 24 karaktert tartalmaz.
Attól függően, hogy melyik reguláris kifejezést adjuk meg az A2-be, az alábbi képlet különböző eredményeket fog eredményezni:
=AblebitsRegexExtract(A5, $A$2)
Regex a teljes domain név az összes aldomainnel: 
Regex egy másodszintű domain aldomainek nélkül: 
Ez az, ahogyan a szöveg részeit kivonhatjuk Excelben a reguláris kifejezések segítségével. Köszönöm, hogy elolvastad, és várom, hogy találkozzunk a blogunkon a jövő héten!
Elérhető letöltések
Excel Regex Extract példák (.xlsm fájl)
Ultimate Suite próbaverzió (.exe fájl)
