
Turinys
Šioje pamokoje sužinosite, kaip "Excel" programoje naudoti reguliariąsias išraiškas, kad surastumėte ir išskirtumėte tam tikrą šabloną atitinkančias posistemes.
"Microsoft Excel" pateikia keletą funkcijų, skirtų tekstui iš langelių išgauti. Šios funkcijos gali susidoroti su daugeliu eilučių ištraukimo iššūkių jūsų darbalapiuose. Dauguma, bet ne visi. Kai teksto funkcijos suklumpa, į pagalbą ateina reguliariosios išraiškos. Palaukite... "Excel" neturi RegEx funkcijų! Tiesa, nėra integruotų funkcijų. Tačiau niekas netrukdo jums naudoti savų :)
"Excel" VBA "Regex" funkcija eilutėms išgauti
Norėdami į "Excel" pridėti pasirinktinę "Regex Extract" funkciją, į VBA redaktorių įklijuokite toliau pateiktą kodą. Norėdami įjungti reguliarias išraiškas VBA, naudojame integruotą "Microsoft RegExp" objektą.
Public Function RegExpExtract(text As String , pattern As String , Optional instance_num As Integer = 0, Optional match_case As Boolean = True ) Dim text_matches() As String Dim matches_index As Integer On Error GoTo ErrHandl RegExpExtract = "" Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Thenregex.igrecase = False Else regex.igrecase = True End If Set matches = regex.Execute(text) If 0 <matches.Count Then If (0 = instance_num) Then If (0 = instance_num) Then ReDim text_matches(matches.Count - 1, 0) For matches_index = 0 To matches.Count - 1 text_matches(matches_index, 0) = matches.Item(matches_index) Next matches_index RegExpExtract = text_matches Else RegExpExtract = matches.Item(instance_num - 1) EndIf End If Exit Funkcija ErrHandl: RegExpExtract = CVErr(xlErrValue) End FunctionJei turite nedaug VBA patirties, jums gali būti naudingas žingsnis po žingsnio parengtas vartotojo vadovas: Kaip įterpti VBA kodą į "Excel".
Pastaba. Kad funkcija veiktų, būtinai išsaugokite failą kaip darbaknygė su makrokomandomis (.xlsm).
RegExpExtract sintaksė
Svetainė RegExpExtract funkcija ieško įvesties eilutėje reikšmių, atitinkančių reguliariąją išraišką, ir ištraukia vieną arba visus atitikmenis.
Šios funkcijos sintaksė yra tokia:
RegExpExtract(tekstas, šablonas, [instance_num], [match_case])Kur:
- Tekstas (privaloma) - teksto eilutė, pagal kurią bus ieškoma.
- Modelis (privaloma) - reguliarioji išraiška, kurią reikia suderinti. Jei šablonas pateikiamas tiesiogiai formulėje, jis turi būti įrašytas dvigubomis kabutėmis.
- Instance_num (neprivaloma) - serijos numeris, nurodantis, kurį egzempliorių išskirti. Jei praleista, grąžinami visi rasti atitikmenys (numatytoji reikšmė).
- Match_case (neprivaloma) - apibrėžia, ar teksto raidės turi būti sutapatinamos, ar ignoruojamos. Jei TRUE arba praleista (numatytoji reikšmė), sutapatinimas atliekamas pagal didžiąsias raides; jei FALSE - neatsižvelgiama į didžiąsias raides.
Funkcija veikia visose "Excel 365", "Excel 2021", "Excel 2019", "Excel 2019", "Excel 2016", "Excel 2013" ir "Excel 2010" versijose.
4 dalykai, kuriuos turėtumėte žinoti apie "RegExpExtract
Kad galėtumėte veiksmingai naudoti šią funkciją "Excel" programoje, reikia atkreipti dėmesį į keletą svarbių dalykų:
- Pagal numatytuosius nustatymus funkcija grąžina visi rasti atitikmenys į gretimus langelius, kaip parodyta šiame pavyzdyje. Norėdami gauti konkretų atvejį, į langelį instance_num argumentas.
- Pagal numatytuosius nustatymus funkcija yra , kai atsižvelgiama į mažąsias ir didžiąsias raides. . Jei norite, kad atitiktis būtų atliekama neraiškiai pagal didžiąsias raides, nustatykite match_case argumentas FALSE. Dėl VBA apribojimų konstrukcija (?i), kurioje neskiriama didžioji ir mažoji raidės, neveikia.
- Jei nerastas galiojantis modelis , funkcija nieko negrąžina (tuščia eilutė).
- Jei modelis negalioja , įvyksta #VALUE! klaida.
Prieš pradėdami naudoti šią pasirinktinę funkciją savo darbalapiuose, turite suprasti, ką ji gali, tiesa? Toliau pateiktuose pavyzdžiuose aprašyti keli įprasti naudojimo atvejai ir paaiškinta, kodėl elgsena gali skirtis "Dynamic Array Excel" ("Microsoft 365" ir "Excel 2021") ir tradicinėje "Excel" ("2019" ir senesnės versijos).
Pastaba. Iš regex pavyzdžiai parašyti pasakiškai paprastiems duomenų rinkiniams. Negalime garantuoti, kad jie nepriekaištingai veiks jūsų tikruose darbalapiuose. Turintieji patirties su regex sutiks, kad taisyklingų išraiškų rašymas yra nesibaigiantis kelias į tobulumą - beveik visada galima rasti būdą, kaip jas padaryti elegantiškesnes arba galinčias apdoroti įvairesnius įvesties duomenis.
"Regex", skirta skaičiui išgauti iš eilutės
Vadovaudamiesi pagrindine mokymo nuostata "nuo paprasto prie sudėtingo", pradėsime nuo labai paprasto atvejo: skaičiaus išskyrimo iš eilutės.
Pirmiausia turite nuspręsti, kurį numerį išrinkti: pirmąjį, paskutinįjį, konkretų atvejį ar visus numerius.
Ištrauka Pirmasis skaičius
Atsižvelgiant į tai, kad \d reiškia bet kurį skaitmenį nuo 0 iki 9, o + - vieną ar daugiau kartų, mūsų reguliarioji išraiška yra tokios formos:
Modelis : \d+
Nustatyti instance_num į 1 ir gausite norimą rezultatą:
=RegExpExtract(A5, "\d+", 1)
Kur A5 yra pradinė eilutė.
Kad būtų patogiau, šabloną galite įvesti į iš anksto nustatytą langelį ($A$2 ) ir jo adresą užrakinti ženklu $:
=RegExpExtract(A5, $A$2, 1) 
Gauti paskutinį numerį
Norėdami išgauti paskutinį skaičių eilutėje, naudokite šį šabloną:
Modelis : (\d+)(?!.*\d)
Išvertus į žmonių kalbą, jis skamba taip: raskite skaičių, po kurio (bet kur, ne tik iš karto) neseka joks kitas skaičius. Kad tai išreikštume, naudojame neigiamąjį požymį (?!.*\d), kuris reiškia, kad į dešinę nuo šablono neturi būti jokio kito skaičiaus (\d), nepriklausomai nuo to, kiek kitų ženklų yra prieš jį.
=RegExpExtract(A5, "(\d+)(?!.*\d)") 
Patarimai:
- Norėdami gauti konkretus įvykis naudoti \d+ modelis ir atitinkamą serijos numerį instance_num .
- Išskyrimo formulė visi skaičiai aptariama kitame pavyzdyje.
"Regex", kad būtų išskirtos visos atitiktys
Jei mūsų pavyzdį išplėstume, tarkime, kad iš eilutės norite gauti visus skaičius, o ne tik vieną.
Kaip pamenate, išskirtos atitikties skaičių kontroliuoja neprivalomasis parametras instance_num numatytoji reikšmė yra visi atitikmenys, todėl šio parametro paprasčiausiai nepateikite:
=RegExpExtract(A2, "\d+")
Formulė puikiai veikia vienoje ląstelėje, tačiau dinaminio masyvo "Excel" ir nedinaminės versijos skiriasi.
"Excel 365" ir "Excel 2021
Dėl dinaminių masyvų palaikymo įprasta formulė automatiškai išsilieja į tiek langelių, kiek reikia visiems apskaičiuotiems rezultatams rodyti. "Excel" tai vadinama išsiliejusiu diapazonu: 
"Excel 2019" ir žemesnės versijos
Prieš dinaminę "Excel" programą pirmiau pateikta formulė grąžintų tik vieną atitikmenį. Kad gautumėte kelis atitikmenis, turite ją paversti masyvo formule. Tam pasirinkite ląstelių intervalą, įveskite formulę ir paspauskite Ctrl + Shift + Enter, kad ją užbaigtumėte.
Šio metodo trūkumas - daugybė #N/A klaidų, atsirandančių "papildomuose langeliuose". Deja, dėl to nieko negalima padaryti (deja, nei IFERROR, nei IFNA negali to ištaisyti). 
Ištraukti visus atitikmenis vienoje ląstelėje
Apdorojant duomenų stulpelį, pirmiau aprašytas metodas akivaizdžiai neveiks. Šiuo atveju idealus sprendimas būtų grąžinti visus atitikmenis vienoje ląstelėje. Norėdami tai padaryti, pateikite "RegExpExtract" rezultatus funkcijai TEXTJOIN ir atskirkite juos bet kokiu norimu skiriamuoju ženklu, tarkime, kableliu ir tarpeliu:
=TEXTJOIN(", ", TRUE, RegExpExtract(A5, "\d+")) 
Pastaba. Kadangi funkcija TEXTJOIN yra tik "Excel" programose "Microsoft 365", "Excel 2021" ir "Excel 2019", formulė neveiks senesnėse versijose.
"Regex" teksto išskyrimui iš eilutės
Teksto išskyrimas iš raidžių ir skaičių eilutės yra gana sudėtinga užduotis "Excel" programoje. Naudojant "regex", tai tampa paprasta kaip pyragas. Tiesiog naudokite neigiamą klasę, kad atitiktumėte viską, kas nėra skaitmuo.
Modelis : [^\d]+
Norint gauti atskirų langelių (išsiliejimo diapazono) posričių eilutes, formulė yra tokia:
=RegExpExtract(A5, "[^\d]+") 
Norėdami išvesti visus atitikmenis į vieną langelį, įterpkite funkciją RegExpExtract į TEXTJOIN taip:
=TEXTJOIN("", TRUE, RegExpExtract(A5, "[^\d]+")) 
Elektroninio pašto adreso išskyrimas iš eilutės "Regex
Norėdami iš eilutės, kurioje yra daug įvairios informacijos, ištraukti el. pašto adresą, parašykite reguliariąją išraišką, atkartojančią el. pašto adreso struktūrą.
Modelis : [\w\.\-]+@[A-Za-z0-9\.\-]+\.[A-Za-z]{2,24}
Išskaidę šią regex formulę, gauname štai ką:
- [\w\.\-]+ yra vartotojo vardas, kurį gali sudaryti 1 ar daugiau raidinių ir skaitmeninių simbolių, pabraukimų, taškų ir brūkšnelių.
- @ simbolis
- [A-Za-z0-9\.\-]+ yra domeno vardas, sudarytas iš didžiųjų ir mažųjų raidžių, skaitmenų, brūkšnelių ir taškų (subdomenų atveju). Čia neleidžiami apatiniai ženklai, todėl vietoj \w, kuris atitinka bet kokią raidę, skaitmenį ar apatinį ženklą, naudojami 3 skirtingi ženklų rinkiniai (pvz., A-Z a-z ir 0-9).
- \.[A-Za-z]{2,24} yra aukščiausio lygio domenas. Jį sudaro taškas, po kurio eina didžiosios ir mažosios raidės. Dauguma aukščiausio lygio domenų yra 3 raidžių ilgio (pvz., .com .org, .edu ir kt.), tačiau teoriškai jį gali sudaryti nuo 2 iki 24 raidžių (ilgiausias registruotas aukščiausio lygio domenas).
Darant prielaidą, kad eilutė yra eilutėje A5, o šablonas - A2, el. pašto adreso išskyrimo formulė yra tokia:
=RegExpExtract(A5, $A$2) 
Regex išgauti domeną iš el. pašto
Kai kalbama apie el. pašto domeno išskyrimą, pirmiausia į galvą ateina mintis, kad reikia naudoti fiksavimo grupę, kad būtų galima rasti tekstą, kuris eina iš karto po simbolio @.
Modelis : @([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})
Pateikite jį mūsų funkcijai RegExp:
=RegExpExtract(A5, "@([A-Za-z0-9\.\-]+\.[A-Za-z]{2,24})")
Ir gausite šį rezultatą: 
Naudojant klasikines reguliariąsias išraiškas, į išskyrimą neįtraukiama viskas, kas yra už fiksuojančios grupės ribų. Niekas nežino, kodėl VBA RegEx veikia kitaip ir fiksuoja ir "@". Norėdami jo atsikratyti, galite pašalinti pirmąjį simbolį iš rezultato, pakeisdami jį tuščia eilute.
=REPLACE(RegExpExtract(A5, "@([a-z\d][a-z\d\-\.]*\.[a-z]{2,})", 1, FALSE), 1, 1, 1, "") 
Reguliarioji išraiška telefono numeriams išgauti
Telefono numeriai gali būti užrašomi įvairiais būdais, todėl beveik neįmanoma rasti visais atvejais veikiančio sprendimo. Vis dėlto galite užrašyti visus duomenų rinkinyje naudojamus formatus ir pabandyti juos suderinti.
Šiame pavyzdyje sukursime regeksą, kuris išskirs bet kurio iš šių formatų telefono numerius:
(123) 345-6789 (123) 345 6789 (123)3456789 123-345-6789 | 123.345.6789 123 345 6789 1233456789 |
Modelis : \(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b
- Pirmoji dalis \(?\d{3} atitinka nulį arba vieną atidaromąjį skliaustą, po kurio seka trys skaitmenys d{3}.
- Dalis [-\. \)]* reiškia bet kurį simbolį laužtiniuose skliaustuose, esantį 0 ar daugiau kartų: brūkšnį, tašką, tarpą arba uždaromuosius skliaustelius.
- Toliau vėl turime tris skaitmenis d{3}, po kurių eina brūkšnys, taškas arba tarpas [-\. ]?, pasitaikantys 0 arba 1 kartą.
- Po to yra keturių skaitmenų grupė \d{4}.
- Galiausiai yra žodis riba \b, apibrėžiantis, kad ieškomas telefono numeris negali būti didesnio numerio dalis.
Pilna formulė yra tokia:
=RegExpExtract(A5, "\(?\d{3}[-\. \)]*\d{3}[-\. ]?\d{4}\b") 
Atkreipkite dėmesį, kad pirmiau pateikta regex gali grąžinti keletą klaidingų rezultatų, pavyzdžiui, 123) 456 7899 arba (123 456 7899. Toliau pateiktoje versijoje šios problemos išspręstos. Tačiau ši sintaksė veikia tik VBA RegExp funkcijose, o ne klasikinėse reguliariosiose išraiškose.
Modelis : (\(\d{3}\)
"Regex", skirta datai išgauti iš eilutės
Reguliarioji išraiška datai išgauti priklauso nuo datos formato, kuriuo data pateikiama eilutėje. Pavyzdžiui:
Norint išgauti tokias datas kaip 1/1/21 arba 01/01/2021, regeksas yra toks: \d{1,2}\/\d{1,2}\/(\d{4}
Ieškoma 1 arba 2 skaitmenų grupės d{1,2}, po kurios eina pasvirasis brūkšnys, po kurio eina kita 1 arba 2 skaitmenų grupė, po kurios eina pasvirasis brūkšnys, po kurio eina 4 arba 2 skaitmenų grupė (\d{4}).pirmoji sąlyga yra pakaitos konstrukcija ARBA sutampa, likusios sąlygos netikrinamos.
Norint gauti tokias datas kaip 1-sausio 21 d. arba 2021 m. sausio 01 d., modelis yra toks: \d{1,2}-[A-Za-z]{3}-\d{2,4}
Ieškoma 1 arba 2 skaitmenų grupės, po kurios eina brūkšnelis, 3 didžiųjų arba mažųjų raidžių grupės, po kurios eina brūkšnelis, 4 arba 2 skaitmenų grupės.
Sujungę abu šablonus kartu, gausime tokią regeksą:
Modelis : \b\d{1,2}[\/-](\d{1,2}
Kur:
- Pirmoji dalis yra 1 arba 2 skaitmenys: \d{1,2}
- Antroji dalis yra 1 arba 2 skaitmenys, arba 3 raidės: (\d{1,2})
- Trečioji dalis yra 4 arba 2 skaitmenų grupė: (\d{4})
- Skiriamasis ženklas yra pasvirasis brūkšnys arba brūkšnys: [\/-]
- Žodžio riba \b dedama iš abiejų pusių, kad būtų aišku, jog data yra atskiras žodis, o ne didesnės eilutės dalis.
Kaip matote toliau pateiktame paveikslėlyje, ji sėkmingai ištraukia datas ir praleidžia tokias posričių eilutes kaip 11/22/333. Tačiau ji vis tiek grąžina klaidingai teigiamus rezultatus. Mūsų atveju posričių eilutė 11-ABC-2222 A9 techniškai atitinka datos formatą dd-mmm-ryyyy todėl yra išgaunamas. 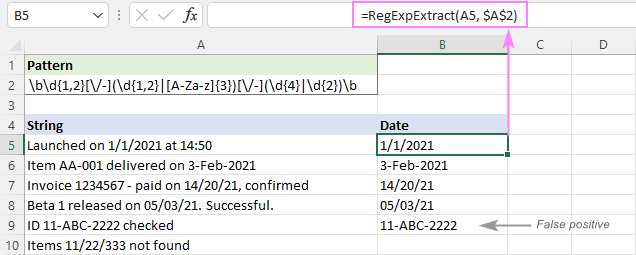
Norėdami pašalinti klaidingus teigiamus rezultatus, dalį [A-Za-z]{3} galite pakeisti pilnu trijų raidžių mėnesių santrumpų sąrašu:
Modelis : \b\d{1,2}[\/-](\d{1,2}
Norėdami ignoruoti raidžių raidę, nustatome, kad mūsų pasirinktinės funkcijos paskutinis argumentas būtų FALSE:
=RegExpExtract(A5, $A$2, 1, FALSE)
Šį kartą rezultatas puikus: 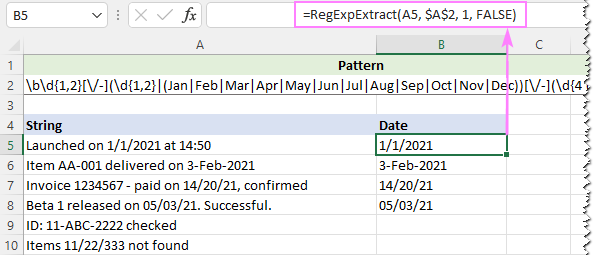
"Regex", skirta išgauti laiką iš eilutės
Norėdami gauti laiko hh:mm arba hh:mm:ss formatas, puikiai tiks ši išraiška.
Modelis : \b(0?[0-9]
Išskaidę šią regex formuluotę, matote 2 dalis, kurias skiria
1 išraiška : \b(0?[0-9]
Ištraukia laikus su AM/PM.
Valanda gali būti bet kuris skaičius nuo 0 iki 12. Norėdami jį gauti, naudojame OR konstrukciją ([0-9]
- [0-9] atitinka bet kurį skaičių nuo 0 iki 9
- 1[0-2] atitinka bet kurį skaičių nuo 10 iki 12
Minutė [0-5]\d yra bet koks skaičius nuo 00 iki 59.
Antrasis (:[0-5]\d)? taip pat yra bet koks skaičius nuo 00 iki 59. Kiekybinis žymuo ? reiškia nulį arba vieną atvejį, nes sekundės gali būti arba nebūti įtrauktos į laiko vertę.
Išraiška 2 : \b([0-9]
Ištraukia laikus be AM/PM.
Svetainė valanda dalis gali būti bet koks skaičius nuo 0 iki 32. Norint ją gauti, reikia naudoti kitą OR konstrukciją ([0-9]
- [0-9] atitinka bet kurį skaičių nuo 0 iki 9
- [0-1]\d atitinka bet kurį skaičių nuo 00 iki 19
- 2[0-3] atitinka bet kurį skaičių nuo 20 iki 23
Svetainė minutė ir antrasis dalys yra tokios pačios kaip ir 1 išraiškoje.
Prie praleidimo eilučių, pavyzdžiui, 20:30:80, pridedamas neigiamasis "lookahead" (?!:).
Kadangi PM/AM gali būti didžiosios arba mažosios raidės, funkcijoje neatsižvelgiama į didžiąsias ir mažąsias raides:
=RegExpExtract(A5, $A$2, 1, FALSE) 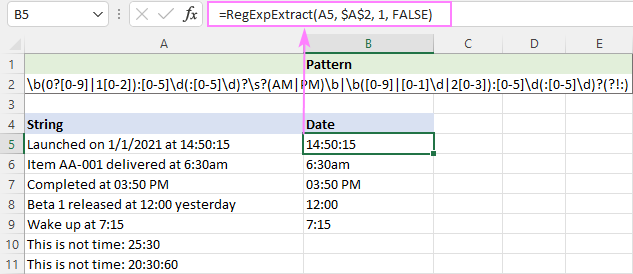
Tikimės, kad pirmiau pateikti pavyzdžiai suteikė jums idėjų, kaip naudoti reguliariąsias išraiškas "Excel" darbalapiuose. Deja, ne visos klasikinių reguliariųjų išraiškų funkcijos yra palaikomos VBA. Jei jūsų užduoties negalima atlikti naudojant VBA RegExp, raginu perskaityti kitą dalį, kurioje aptariamos daug galingesnės .NET Regex funkcijos.
Pasirinktinė .NET pagrįsta "Regex" funkcija tekstui išgauti "Excel" programoje
Skirtingai nuo VBA RegExp funkcijų, kurias gali parašyti bet kuris "Excel" vartotojas, .NET RegEx yra programuotojo sritis. "Microsoft" .NET sistema palaiko visavertę reguliariųjų išraiškų sintaksę, suderinamą su "Perl 5". Šiame straipsnyje neišmokysime, kaip rašyti tokias funkcijas (nesu programuotojas ir neturiu nė menkiausio supratimo, kaip tai padaryti :)
Keturios galingos funkcijos, apdorojamos standartiniu .NET "RegEx" varikliu, jau yra parašytos mūsų kūrėjų ir įtrauktos į "Ultimate Suite" rinkinį. Toliau pademonstruosime keletą praktinių funkcijos, specialiai sukurtos tekstui išgauti "Excel" programoje, panaudojimo būdų.
Patarimas. Informacijos apie .NET Regex sintaksės sintaksę rasite skyriuje .NET reguliariųjų išraiškų kalba.
Kaip "Excel" programoje išgauti erškėčius naudojant reguliarias išraiškas
Darant prielaidą, kad įdiegta naujausia "Ultimate Suite" versija, teksto išskyrimas naudojant reguliariąsias išraiškas susideda iš šių dviejų veiksmų:
- Dėl Ablebitų duomenys skirtuke Tekstas grupę, spustelėkite "Regex" įrankiai .

- Dėl "Regex" įrankiai lange pasirinkite šaltinio duomenis, įveskite "Regex" šabloną ir pasirinkite Ištrauka norėdami gauti rezultatą kaip pasirinktinę funkciją, o ne kaip vertę, pasirinkite parinktį Įterpti kaip formulę Pažymėkite žymimąjį langelį. Kai tai padarysite, spustelėkite Ištrauka mygtuką.

Rezultatai bus rodomi naujame stulpelyje, esančiame pradinių duomenų dešinėje: 
AblebitsRegexExtract sintaksė
Mūsų pasirinktinės funkcijos sintaksė yra tokia:
Kur:
- Nuoroda (būtina) - nuoroda į ląstelę, kurioje yra šaltinio eilutė.
- Reguliarioji_išraiška (privaloma) - regex šablonas, kurį reikia suderinti.
Svarbi pastaba! Ši funkcija veikia tik kompiuteriuose, kuriuose įdiegta programa "Ultimate Suite for Excel".
Naudojimo pastabos
Kad mokymasis būtų sklandesnis, o patirtis malonesnė, atkreipkite dėmesį į šiuos dalykus:
- Norėdami sukurti formulę, galite naudoti mūsų "Regex" įrankiai arba "Excel Įterpimo funkcija dialogo langą arba įveskite visą funkcijos pavadinimą ląstelėje. Įterpus formulę, galite ją tvarkyti (redaguoti, kopijuoti ar perkelti) kaip ir bet kurią kitą vietinę formulę.
- Raštas, kurį įvedate į "Regex" įrankiai lange pereina prie 2-ojo argumento. Taip pat galima laikyti reguliariąją išraišką atskiroje ląstelėje. Šiuo atveju tiesiog naudokite ląstelės nuorodą 2-ajam argumentui.
- Funkcija išgauna pirmasis rastas atitikmuo .
- Pagal numatytuosius nustatymus funkcija yra , kai atsižvelgiama į mažąsias ir didžiąsias raides. . Jei norite, kad atitiktis būtų atliekama neatsižvelgiant į mažąsias ir didžiąsias raides, naudokite (?i) šabloną.
- Jei atitikmuo nerandamas, grąžinama #N/A klaida.
"Regex" eilutei tarp dviejų simbolių išgauti
Norėdami gauti tekstą tarp dviejų simbolių, galite naudoti užfiksuojančią grupę arba apeinamąsias nuorodas.
Tarkime, kad norite išgauti tekstą tarp skliaustų. Paprasčiausias būdas - užfiksuoti grupę.
1 modelis : \[(.*?)\]
Jei žvilgsnis atgal ir žvilgsnis į priekį bus teigiamas, rezultatas bus lygiai toks pat.
2 modelis : (?<=\[)(.*?)(?=\])
Atkreipkite dėmesį į tai, kad mūsų fiksavimo grupė (.*?) atlieka tingi paieška tekstui tarp dviejų skliaustų - nuo pirmojo [ iki pirmojo ]. Užfiksavus grupę be klausimo ženklo (.*) būtų atliekamas godi paieška ir užfiksuokite viską nuo pirmojo [ iki paskutinio ].
Naudojant A2 pavyzdį, formulė yra tokia:
=AblebitsRegexExtract(A5, $A$2) 
Kaip gauti visas rungtynes
Kaip jau minėta, funkcija AblebitsRegexExtract gali išgauti tik vieną atitikmenį. Norėdami gauti visus atitikmenis, galite naudoti VBA funkciją, kurią aptarėme anksčiau. Tačiau yra viena išlyga - VBA RegExp nepalaiko grupių fiksavimo, todėl pirmiau pateiktas šablonas grąžins ir "ribinius" simbolius, mūsų atveju - skliaustelius.
=TEXTJOIN(" ", TRUE, RegExpExtract(A5, $A$2)) 
Jei norite atsikratyti skliaustų, pakeiskite juos tuščiomis eilutėmis ("") pagal šią formulę:
=SUBSTITUTE(SUBSTITUTE(TEXTJOIN(", ", ", TRUE, RegExpExtract(A5, $A$2)), "]", ""),"[","")
Kad būtų lengviau skaityti, kaip skirtuką naudojame kablelį. 
"Regex", skirta tekstui tarp dviejų eilučių išskirti
Metodas, kurį naudojome tekstui tarp dviejų simbolių ištraukti, taip pat tinka tekstui tarp dviejų eilučių išgauti.
Pavyzdžiui, norėdami gauti viską, kas yra tarp "test 1" ir "test 2", naudokite šią reguliariąją išraišką.
Modelis : testas 1(.*?)testas 2
Pilna formulė yra tokia:
=AblebitsRegexExtract(A5, "testas 1(.*?)testas 2") 
Regex domenui iš URL išgauti
Net ir naudojant reguliariąsias išraiškas iš URL išgauti domenų vardus nėra triviali užduotis. Pagrindinis elementas, kuris padeda atlikti šį triuką, yra nefiksuojančios grupės. Atsižvelgdami į galutinį tikslą, pasirinkite vieną iš toliau pateiktų regeksų.
Norėdami gauti pilnas domeno vardas įskaitant subdomenus
Modelis : (?:https?\:
Norėdami gauti antrojo lygio domenas be subdomenų
Modelis : (?:https?\:
Dabar pažiūrėkime, kaip šios reguliariosios išraiškos veikia pavyzdžiu "//www.mobile.ablebits.com" kaip pavyzdinį URL adresą:
- (?:https?\:
- \/\/ - du priekiniai pasvirieji brūkšniai (prieš kiekvieną iš jų rašomas atgalinis brūkšnys, kad būtų išvengta specialios priekinio brūkšnio reikšmės ir jis būtų interpretuojamas pažodžiui).
- (?:[A-Za-z\d\-\.]{2,255}\.)? - nefiksuojanti grupė trečiojo, ketvirtojo ir t. t. lygmens domenams, jei tokių yra, identifikuoti ( mobilusis mūsų pavyzdiniame URL). Pirmajame šablone jis įtraukiamas į didesnę užfiksavimo grupę, kad į išskyrimą būtų įtraukti visi tokie subdomenai. Subdomenas gali būti nuo 2 iki 255 simbolių ilgio, todėl naudojamas kvantorius {2,255}.
- ([A-Za-z\d\-]{1,63}\.[A-Za-z]{2,24}) - fiksavimo grupė antrojo lygio domenui išgauti ( ablebits ) ir aukščiausiojo lygio domenas (angl. com ). Maksimalus antrojo lygio domeno ilgis yra 63 simboliai. Ilgiausias šiuo metu egzistuojantis aukščiausio lygio domenas turi 24 simbolius.
Priklausomai nuo to, kokia reguliarioji išraiška įvesta į A2, toliau pateikta formulė duos skirtingus rezultatus:
=AblebitsRegexExtract(A5, $A$2)
Regex išgauti pilnas domeno vardas su visais subdomenais: 
Regex išgauti antrojo lygio domenas be subdomenų: 
Štai kaip išgauti teksto dalis "Excel" programoje naudojant reguliarias išraiškas. Dėkoju, kad perskaitėte, ir laukiu jūsų mūsų tinklaraštyje kitą savaitę!
Galimi atsisiuntimai
"Excel" regeksų išskyrimo pavyzdžiai (.xlsm failas)
"Ultimate Suite" bandomoji versija (.exe failas)
