
विषयसूची
नीचे दिए गए स्ट्रिंग्स में, मान लें कि आप पहले आदेश संख्या को हटाना चाहते हैं। ऐसी सभी संख्याएँ हैश चिन्ह (#) से शुरू होती हैं और ठीक 5 अंकों की होती हैं। इसलिए, हम इस रेगेक्स का उपयोग करके उनकी पहचान कर सकते हैं:
पैटर्न : #\d{5}\b
शब्द सीमा \b निर्दिष्ट करता है कि एक मिलान सबस्ट्रिंग नहीं हो सकता एक बड़ी स्ट्रिंग का हिस्सा जैसे #10000001।
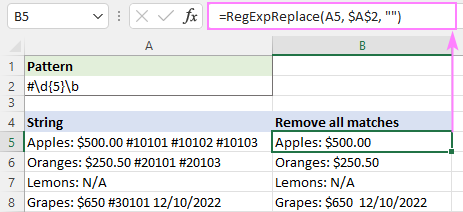
सभी मैचों को हटाने के लिए, instance_num तर्क परिभाषित नहीं है:
=RegExpReplace(A5, "#\d{5}\b", "")
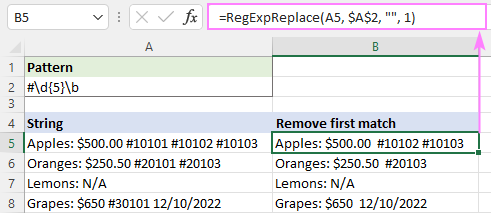
केवल पहली घटना को मिटाने के लिए, हम instance_num तर्क को 1 पर सेट करते हैं:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex कुछ वर्णों को हटाने के लिए
किसी स्ट्रिंग से कुछ वर्णों को निकालने के लिए, बस सभी अवांछित वर्णों को लिख लें और उन्हें लंबवत पट्टी से अलग कर देंVBA RegExp सीमाओं से मुक्त सिंटैक्स, और दूसरी बात, आपकी कार्यपुस्तिकाओं में कोई VBA कोड डालने की आवश्यकता नहीं है क्योंकि बैकएंड पर हमारे द्वारा सभी कोड एकीकरण किया जाता है।
आपके काम का हिस्सा एक नियमित अभिव्यक्ति का निर्माण करना है और इसे फंक्शन में सर्व करें :) मैं आपको दिखाता हूं कि एक व्यावहारिक उदाहरण पर यह कैसे करना है।
रेगेक्स का उपयोग करके कोष्ठक और कोष्ठक में टेक्स्ट कैसे हटाएं
लंबी टेक्स्ट स्ट्रिंग्स में, कम महत्वपूर्ण जानकारी अक्सर [कोष्ठक] और (कोष्ठक) में संलग्न होता है। आप अन्य सभी डेटा को रखते हुए उन अप्रासंगिक विवरणों को कैसे हटाते हैं?
वास्तव में, हमने HTML टैग्स को हटाने के लिए पहले से ही एक समान रेगेक्स बनाया है, यानी कोण कोष्ठक के भीतर पाठ। जाहिर है, यही तरीके चौकोर और गोल कोष्ठकों के लिए भी काम करेंगे।
पैटर्न : (\(.*?\))
क्या आपने कभी सोचा है कि अगर कोई अपने टूलबॉक्स को रेगुलर एक्सप्रेशंस से समृद्ध कर सकता है तो एक्सेल कितना शक्तिशाली होगा? हमने न केवल सोचा है बल्कि इस पर काम किया है :) और अब, आप इस अद्भुत RegEx फ़ंक्शन को अपनी कार्यपुस्तिकाओं में जोड़ सकते हैं और कुछ ही समय में एक पैटर्न से मेल खाने वाले सबस्ट्रिंग्स को मिटा सकते हैं!
पिछले सप्ताह, हमने देखा एक्सेल में स्ट्रिंग्स को बदलने के लिए रेगुलर एक्सप्रेशन का उपयोग कैसे करें। इसके लिए, हमने एक कस्टम रेगेक्स रिप्लेस फंक्शन बनाया। जैसा कि यह निकला, फ़ंक्शन अपने प्राथमिक उपयोग से परे चला जाता है और न केवल तारों को बदल सकता है बल्कि उन्हें हटा भी सकता है। यह कैसे हो सकता है? एक्सेल के संदर्भ में, किसी मान को हटाना और कुछ नहीं है, बल्कि इसे एक खाली स्ट्रिंग से बदलना है, कुछ ऐसा है जिसमें हमारा रेगेक्स फ़ंक्शन बहुत अच्छा है!
एक्सेल में सबस्ट्रिंग को हटाने के लिए VBA RegExp फ़ंक्शन
जैसा कि हम सभी जानते हैं, रेगुलर एक्सप्रेशन एक्सेल में डिफ़ॉल्ट रूप से समर्थित नहीं हैं। उन्हें सक्षम करने के लिए, आपको अपना स्वयं का उपयोगकर्ता परिभाषित फ़ंक्शन बनाना होगा। अच्छी खबर यह है कि ऐसा फ़ंक्शन पहले से ही लिखित, परीक्षण और उपयोग के लिए तैयार है। आपको केवल इस कोड को कॉपी करना है, इसे अपने VBA संपादक में पेस्ट करना है, और फिर अपनी फ़ाइल को मैक्रो-सक्षम कार्यपुस्तिका (.xlsm) के रूप में सहेजना है।
फ़ंक्शन में यह है निम्न सिंटैक्स:
RegExpReplace(पाठ, पैटर्न, प्रतिस्थापन, [instance_num], [match_case])पहले तीन तर्क आवश्यक हैं, अंतिम दो वैकल्पिक हैं।
कहां:
- टेक्स्ट - खोजने के लिए टेक्स्ट स्ट्रिंगयह तब तक संभव है जब तक कि इसे क्लोजिंग ब्रैकेट नहीं मिल जाता।
आप जो भी पैटर्न चुनते हैं, परिणाम बिल्कुल समान होगा।
उदाहरण के लिए, A5 में एक स्ट्रिंग से सभी html टैग हटाने और टेक्स्ट छोड़ने के लिए, सूत्र है:
=RegExpReplace(A5, "]*>", "")
या आप आलसी क्वांटिफायर का उपयोग कर सकते हैं जैसा कि स्क्रीनशॉट में दिखाया गया है:
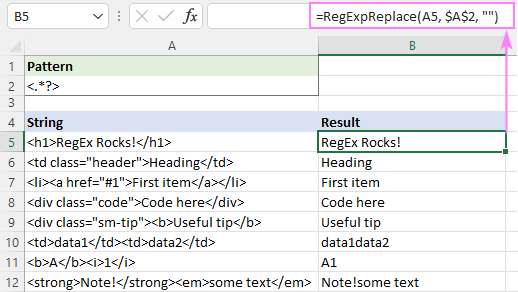
यह समाधान इसके लिए पूरी तरह से काम करता है एकल पाठ (पंक्तियाँ 5 - 9)। कई पाठों (पंक्तियों 10 - 12) के लिए, परिणाम संदिग्ध हैं - विभिन्न टैगों के ग्रंथों को एक में मिला दिया जाता है। यह सही है या नहीं? मुझे डर है, यह ऐसा कुछ नहीं है जिसे आसानी से तय किया जा सकता है - सब कुछ वांछित परिणाम की आपकी समझ पर निर्भर करता है। उदाहरण के लिए, B11 में, परिणाम "A1" अपेक्षित है; जबकि B10 में, आप "data1" और "data2" को एक स्पेस के साथ अलग करना चाहते हैं।
html टैग हटाने और शेष टेक्स्ट को स्पेस के साथ अलग करने के लिए, आप इस तरह से आगे बढ़ सकते हैं:
- टैग को स्पेस से बदलें "", खाली स्ट्रिंग नहीं:
=RegExpReplace(A5, "]*>", " ") - कई स्पेस को सिंगल स्पेस कैरेक्टर में कम करें:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - अग्रणी और अनुगामी रिक्त स्थान ट्रिम करें:
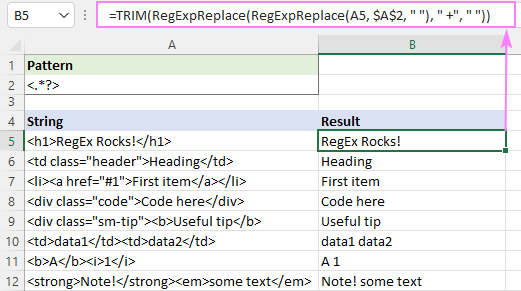
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
परिणाम कुछ इस तरह दिखाई देगा:
Ablebits Regex Remove Tool
यदि आपको एक्सेल के लिए हमारे अल्टीमेट सूट का उपयोग करने का मौका मिला है, तो आप शायद हाल ही में रिलीज के साथ पेश किए गए नए रेगेक्स टूल्स की खोज कर चुके हैं। इन .NET आधारित रेगेक्स कार्यों की सुंदरता यह है कि वे, सबसे पहले, पूर्ण विशेषताओं वाली नियमित अभिव्यक्ति का समर्थन करते हैं निकालें विकल्प, और निकालें हिट करें।
परिणामों को सूत्रों के रूप में प्राप्त करने के लिए, मूल्यों के रूप में नहीं, सूत्र के रूप में सम्मिलित करें चेक बॉक्स का चयन करें। निम्नानुसार:
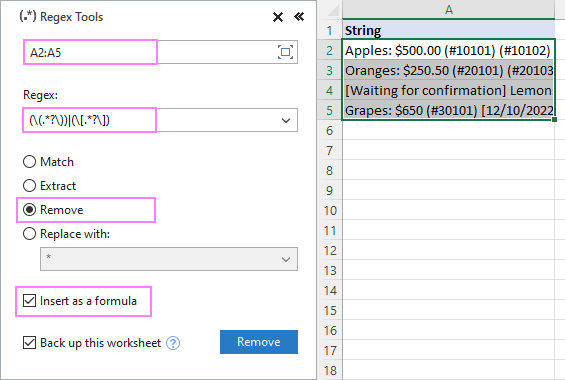
नतीजतन, AblebitsRegexRemove फ़ंक्शन आपके मूल डेटा के बगल में एक नए कॉलम में डाला गया है।
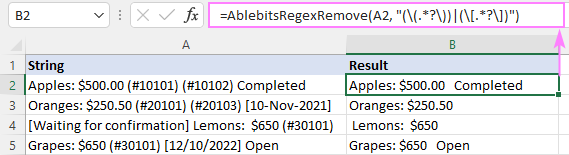
मानक इन्सर्ट फंक्शन संवाद बॉक्स के माध्यम से फ़ंक्शन को सीधे सेल में भी दर्ज किया जा सकता है, जहां इसे AblebitsUDFs के अंतर्गत वर्गीकृत किया गया है।<3
चूंकि AblebitsRegexRemove टेक्स्ट को हटाने के लिए डिज़ाइन किया गया है, इसके लिए केवल दो तर्कों की आवश्यकता होती है - स्रोत स्ट्रिंग और रेगेक्स। दोनों मापदंडों को सीधे एक सूत्र में परिभाषित किया जा सकता है या सेल संदर्भों के रूप में आपूर्ति की जा सकती है। यदि आवश्यक हो, तो इस कस्टम फ़ंक्शन का उपयोग किसी भी नेटिव के साथ किया जा सकता है।
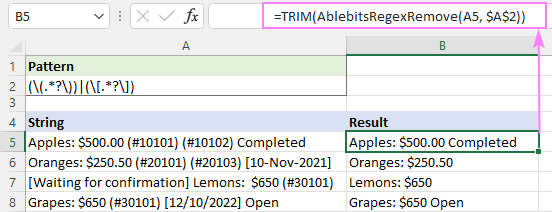
उदाहरण के लिए, परिणामी स्ट्रिंग्स में अतिरिक्त रिक्त स्थान को ट्रिम करने के लिए, आप TRIM फ़ंक्शन को रैपर के रूप में उपयोग कर सकते हैं:
=TRIM(AblebitsRegexRemove(A5, $A$2))
रेगुलर एक्सप्रेशन का उपयोग करके एक्सेल में स्ट्रिंग्स को इस तरह से हटाया जा सकता है। मैं आपको पढ़ने के लिए धन्यवाद देता हूं और अगले सप्ताह आपको हमारे ब्लॉग पर देखने के लिए उत्सुक हूं!
उपलब्ध डाउनलोड
रेगेक्स का उपयोग करके स्ट्रिंग हटाएं - उदाहरण (.xlsm फ़ाइल)
अल्टीमेट सूट - परीक्षण संस्करण (.exe फ़ाइल)
in.अधिक जानकारी के लिए, कृपया RegExpReplace फ़ंक्शन देखें।
युक्ति। साधारण मामलों में, आप Excel फ़ार्मुलों वाले कक्षों से विशिष्ट वर्णों या शब्दों को निकाल सकते हैं। लेकिन रेगुलर एक्सप्रेशन इसके लिए बहुत अधिक विकल्प प्रदान करते हैं।
रेगुलर एक्सप्रेशन का उपयोग करके स्ट्रिंग्स को कैसे हटाएं - उदाहरण
जैसा कि ऊपर उल्लेख किया गया है, पैटर्न से मेल खाने वाले टेक्स्ट के हिस्सों को हटाने के लिए, आपको उन्हें बदलना होगा एक खाली तार के साथ। तो, एक सामान्य सूत्र यह आकार लेता है:
RegExpReplace(text, pattern, "", [instance_num], [match_case])नीचे दिए गए उदाहरण इस मूल अवधारणा के विभिन्न कार्यान्वयन दिखाते हैं।
निकालें सभी मैच या विशिष्ट मैच
RegExpReplace फ़ंक्शन को किसी दिए गए रेगेक्स से मेल खाने वाले सभी सबस्ट्रिंग खोजने के लिए डिज़ाइन किया गया है। किन घटनाओं को हटाने के लिए चौथे वैकल्पिक तर्क द्वारा नियंत्रित किया जाता है, जिसका नाम instance_num है।
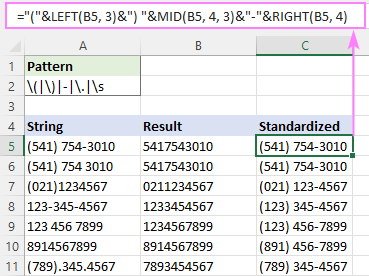
डिफ़ॉल्ट "सभी मिलान" है - जब instance_num कॉन्टेनेशन ऑपरेटर (&) और टेक्स्ट फ़ंक्शन जैसे राइट, मिड और लेफ्ट।
उदाहरण के लिए, (123) 456-7890 प्रारूप में सभी फोन नंबर लिखने के लिए सूत्र है:> ="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
जहां B5 RegExpReplace फ़ंक्शन का आउटपुट है।
regEx का उपयोग करके विशेष वर्ण हटाएं
हमारे एक ट्यूटोरियल में, हमने देखा कि इनबिल्ट और कस्टम फ़ंक्शंस का उपयोग करके एक्सेल में अवांछित वर्णों को कैसे हटाया जाए। रेगुलर एक्सप्रेशन से चीज़ें बहुत आसान हो जाती हैं! हटाए जाने वाले सभी वर्णों को सूचीबद्ध करने के बजाय, केवल उन वर्णों को निर्दिष्ट करें जिन्हें आप रखना चाहते हैं :)
पैटर्न नकारात्मक वर्ण वर्गों पर आधारित है - एक कैरट को एक वर्ण वर्ग के अंदर रखा जाता है [^ ] कोष्ठक में नहीं किसी एक वर्ण से मिलान करने के लिए। + क्वांटिफायर इसे लगातार वर्णों को एक ही मैच के रूप में मानने के लिए बाध्य करता है, ताकि प्रत्येक अलग-अलग वर्ण के बजाय मिलान करने वाले सबस्ट्रिंग के लिए एक प्रतिस्थापन किया जा सके।
अपनी आवश्यकताओं के आधार पर, निम्न रेगेक्स में से एक चुनें।
गैर-अल्फ़ान्यूमेरिक वर्णों को हटाने के लिए, यानी अक्षरों और अंकों को छोड़कर सभी वर्ण:
पैटर्न : [^0-9a-zA-Z] +
सभी वर्णों को शुद्ध करने के लिए अक्षरों को छोड़कर , अंकों और रिक्तियों :
पैटर्न : [^0-9a-zA-Z ]+
सभी वर्णों को हटाने के लिए अक्षरों को छोड़कर , अंक और अंडरस्कोर , आप \ का उपयोग कर सकते हैं W जो किसी भी वर्ण के लिए खड़ा है जो अल्फ़ान्यूमेरिक वर्ण नहीं है याअंडरस्कोर:
पैटर्न : \W+
अगर आप कुछ और कैरेक्टर रखना चाहते हैं , उदा. विराम चिह्न, उन्हें कोष्ठक के अंदर रखें।
उदाहरण के लिए, अक्षर, अंक, अवधि, अल्पविराम, या स्थान के अलावा किसी भी वर्ण को हटाने के लिए, निम्नलिखित रेगेक्स का उपयोग करें:
पैटर्न : [^0-9a-zA-Z\., ]+
यह सभी विशेष वर्णों को सफलतापूर्वक हटा देता है, लेकिन अतिरिक्त खाली स्थान बना रहता है।
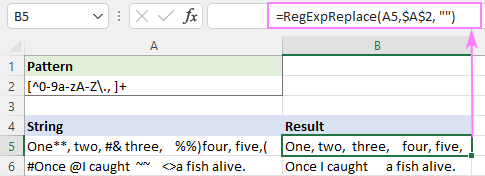
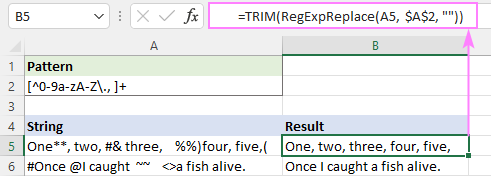
इसे ठीक करने के लिए, आप ऊपर दिए गए फ़ंक्शन को किसी अन्य फ़ंक्शन में नेस्ट कर सकते हैं जो एक ही स्पेस कैरेक्टर के साथ कई स्पेस को बदल देता है। :
=TRIM(RegExpReplace(A5, $A$2, ""))
गैर-संख्यात्मक वर्णों को हटाने के लिए Regex
एक स्ट्रिंग से सभी गैर-संख्यात्मक वर्णों को हटाने के लिए, आप उपयोग कर सकते हैं या तो यह लंबा सूत्र या नीचे सूचीबद्ध बहुत सरल रेगेक्स में से एक।
किसी भी वर्ण से मिलान करें जो अंक नहीं है:>नकारात्मक वर्गों का उपयोग करके गैर-संख्यात्मक वर्णों को हटा दें:
पैटर्न : [^0-9]+
पैटर्न : [^\d] +
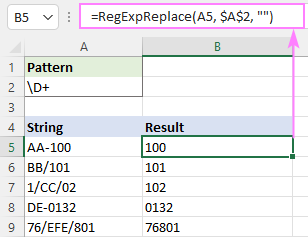
युक्ति। यदि आपका लक्ष्य पाठ को हटाना है और शेष संख्याओं को अलग-अलग कक्षों में फैलाना है या उन सभी को एक निर्दिष्ट सीमांकक के साथ अलग किए गए एक कक्ष में रखना है, तो RegExpExtract फ़ंक्शन का उपयोग करें, जैसा कि रेगुलर एक्सप्रेशन का उपयोग करके स्ट्रिंग से संख्याएं कैसे निकालें में बताया गया है.
स्पेस के बाद सब कुछ हटाने के लिए Regex
स्पेस के बाद सब कुछ मिटाने के लिए, या तो स्पेस ( ) या का उपयोग करेंपहले स्थान को खोजने के लिए व्हाइटस्पेस (\s) वर्ण और .* इसके बाद के किसी भी वर्ण से मिलान करने के लिए।
यदि आपके पास एकल-पंक्ति स्ट्रिंग है जिसमें केवल सामान्य रिक्त स्थान हैं (7-बिट ASCII सिस्टम में मान 32) , यह वास्तव में कोई फर्क नहीं पड़ता कि आप नीचे दिए गए रेगेक्स में से किसका उपयोग करते हैं। मल्टी-लाइन स्ट्रिंग्स के मामले में, इससे फर्क पड़ता है।
सबकुछ हटाने के लिए स्पेस कैरेक्टर के बाद , इस रेगेक्स का उपयोग करें:
पैटर्न : " .*"
=RegExpReplace(A5, " .*", "")
यह सूत्र प्रत्येक पंक्ति में पहली रिक्ति के बाद कुछ भी हटा देगा। परिणामों को सही ढंग से प्रदर्शित करने के लिए, रैप टेक्स्ट को चालू करना सुनिश्चित करें।
व्हाट्सएप के बाद सब कुछ बंद करने के लिए (स्पेस, टैब, कैरिज रिटर्न और नई लाइन सहित), रेगेक्स is:
Pattern : \s.*
=RegExpReplace(A5, "\s.*", "")
क्योंकि \s कुछ अलग-अलग व्हाइटस्पेस प्रकारों से मेल खाता है जिसमें एक नई लाइन<शामिल है। 9> (\n), यह सूत्र किसी सेल में पहले स्थान के बाद सब कुछ हटा देता है, चाहे उसमें कितनी भी पंक्तियाँ क्यों न हों।
विशिष्ट के बाद पाठ को निकालने के लिए Regex चरित्र
पिछले उदाहरण से विधियों का उपयोग करके, आप निर्दिष्ट किसी भी वर्ण के बाद पाठ को मिटा सकते हैं।
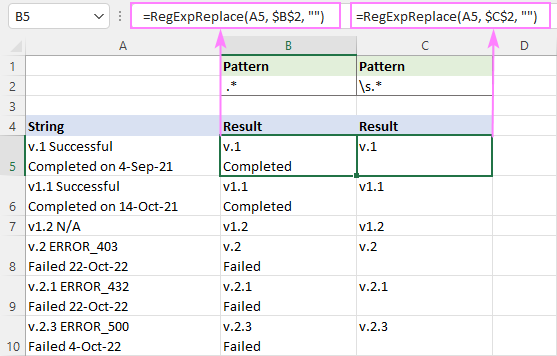
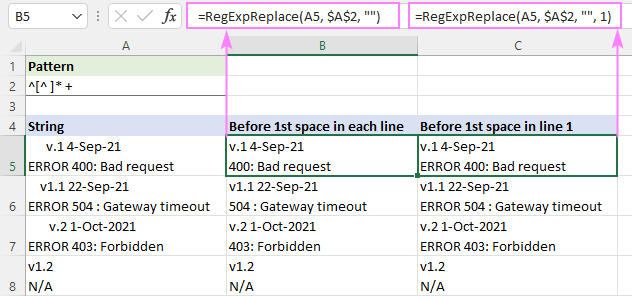
प्रत्येक पंक्ति को अलग से संभालने के लिए:
सामान्य पैटर्न 2>: char.*
सिंगल-लाइन स्ट्रिंग्स में, यह char के बाद सब कुछ हटा देगा। मल्टी-लाइन स्ट्रिंग्स में, प्रत्येक पंक्ति को अलग-अलग संसाधित किया जाएगा क्योंकि वीबीए रेगेक्स स्वाद में, एक अवधि (।) एक नए को छोड़कर किसी भी वर्ण से मेल खाती हैएक स्ट्रिंग की शुरुआत ^, हम शून्य या अधिक गैर-स्थान वर्णों से मेल खाते हैं [^ ]* जिनके तुरंत बाद एक या अधिक रिक्त स्थान "+" होते हैं। परिणामों में संभावित अग्रणी रिक्त स्थान को रोकने के लिए अंतिम भाग जोड़ा गया है।
प्रत्येक पंक्ति में पहले स्थान से पहले पाठ को हटाने के लिए, सूत्र को डिफ़ॉल्ट "सभी मिलान" मोड में लिखा गया है ( instance_num छोड़ा गया):
=RegExpReplace(A5, "^[^ ]* +", "")
पहली पंक्ति में पहले स्थान से पहले पाठ को हटाने के लिए, और अन्य सभी पंक्तियों को बरकरार रखने के लिए, instance_num तर्क 1 पर सेट है:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
चरित्र से पहले सब कुछ अलग करने के लिए Regex
किसी विशिष्ट वर्ण से पहले सभी पाठ को निकालने का सबसे आसान तरीका एक रेगेक्स का उपयोग करना है इस तरह:
जेनेरिक पैटर्न : ^[^char]*char
मानव भाषा में अनुवादित, यह कहता है: "^ द्वारा एंकर की गई स्ट्रिंग की शुरुआत से , char [^char]* को छोड़कर char की पहली घटना तक 0 या अधिक वर्णों का मिलान करें।
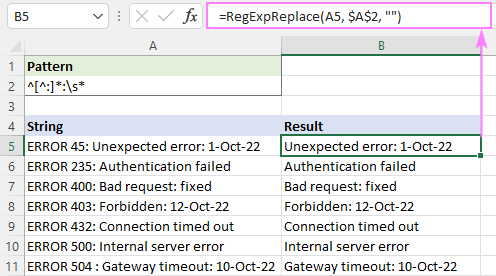
उदाहरण के लिए, पहले कोलन से पहले सभी पाठ को हटाने के लिए , इस रेगुलर एक्सप्रेशन का उपयोग करें:
Pattern : ^[^:]*:
परिणामों में अग्रणी रिक्त स्थान से बचने के लिए, एक खाली स्थान वर्ण \s* जोड़ें खत्म। यह सब कुछ हटा देगा g पहले कोलन से पहले और उसके ठीक बाद किसी भी स्पेस को ट्रिम करें:
Pattern : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
युक्ति। रेगुलर एक्सप्रेशन के अलावा, एक्सेल के पास स्थिति या मिलान के द्वारा टेक्स्ट को हटाने का अपना साधन है। मूल सूत्रों के साथ कार्य को पूरा करने का तरीका जानने के लिए,कृपया एक्सेल में किसी वर्ण के पहले या बाद में टेक्स्ट को कैसे हटाएं देखें।
Regex को छोड़कर सब कुछ हटाने के लिए
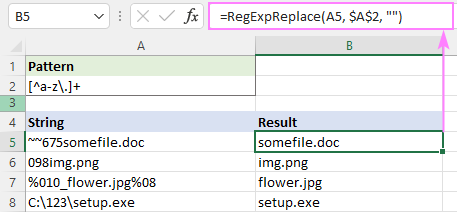
एक स्ट्रिंग से सभी वर्णों को मिटाने के लिए जिन्हें आप रखना चाहते हैं, नकारात्मक वर्ण वर्गों का उपयोग करें।
उदाहरण के लिए, छोटे अक्षरों को छोड़कर सभी वर्णों को हटाने के लिए और डॉट्स, रेगेक्स है:
Pattern : [^a-z\.]+
वास्तव में, हम यहां + क्वांटिफायर के बिना कर सकते हैं क्योंकि हमारा फ़ंक्शन सभी को बदल देता है मेल मिला। क्वांटिफायर इसे थोड़ा तेज़ बनाता है - प्रत्येक व्यक्तिगत चरित्र को संभालने के बजाय, आप एक सबस्ट्रिंग को बदलते हैं।
=RegExpReplace(A5, "[^a-z\.]+", "")
Excel में html टैग हटाने के लिए Regex
सबसे पहले, यह ध्यान दिया जाना चाहिए कि HTML एक नियमित भाषा नहीं है, इसलिए नियमित अभिव्यक्ति का उपयोग करके इसे पार्स करना सबसे अच्छा तरीका नहीं है। उस ने कहा, रेगेक्स निश्चित रूप से आपके डेटासेट को साफ करने के लिए आपके सेल से टैग को हटाने में मदद कर सकता है।
यह देखते हुए कि html टैग हमेशा कोण कोष्ठक के भीतर रखे जाते हैं, आप उन्हें निम्नलिखित रेगेक्स में से किसी एक का उपयोग करके पा सकते हैं।
नकारात्मक क्लास:
पैटर्न : ]*>
यहां, हम एक ओपनिंग एंगल ब्रैकेट से मेल खाते हैं, इसके बाद किसी भी वर्ण की शून्य या अधिक घटनाओं को छोड़कर क्लोजिंग एंगल ब्रैकेट [^>]* निकटतम क्लोजिंग एंगल ब्रैकेट तक।
लेजी सर्च:
पैटर्न :
यहाँ, हम मैच पहले खुलने वाले ब्रैकेट से पहले बंद होने वाले ब्रैकेट तक कुछ भी। प्रश्नवाचक चिह्न .* को कुछ वर्णों से मिलान करने के लिए बाध्य करता हैलाइन।
सभी लाइनों को एक स्ट्रिंग के रूप में संसाधित करने के लिए:
सामान्य पैटर्न : चार (।
