
Cuprins
V-ați gândit vreodată cât de puternic ar fi Excel dacă cineva ar putea să-și îmbogățească setul de instrumente cu expresii regulate? Noi nu numai că ne-am gândit, dar am și lucrat la asta :) Și acum, puteți adăuga această minunată funcție RegEx la propriile cărți de lucru și puteți șterge substringurile care se potrivesc cu un model în cel mai scurt timp!
Săptămâna trecută, am analizat cum să folosim expresii regulate pentru a înlocui șiruri de caractere în Excel. Pentru aceasta, am creat o funcție Regex Replace personalizată. După cum s-a dovedit, funcția depășește utilizarea sa primară și poate nu numai să înlocuiască șiruri de caractere, ci și să le elimine. Cum se poate întâmpla acest lucru? În ceea ce privește Excel, eliminarea unei valori nu este altceva decât înlocuirea acesteia cu un șir gol, lucru pe care funcția noastră Regex estefoarte bun la!
Funcția VBA RegExp pentru a elimina subșirurile în Excel
După cum știm cu toții, expresiile regulate nu sunt acceptate în Excel în mod implicit. Pentru a le activa, trebuie să creați propria funcție definită de utilizator. Vestea bună este că o astfel de funcție este deja scrisă, testată și gata de utilizare. Tot ce trebuie să faceți este să copiați acest cod, să îl lipiți în editorul VBA și apoi să salvați fișierul ca o funcție registru de lucru activat de macro (.xlsm).
Funcția are următoarea sintaxă:
RegExpReplace(text, pattern, replacement, [instance_num], [match_case])Primele trei argumente sunt obligatorii, iar ultimele două sunt opționale.
Unde:
- Text - șirul de text în care se efectuează căutarea.
- Model - expresia regulată care trebuie căutată.
- Înlocuire - textul cu care se înlocuiește. To eliminați subșirurile care se potrivește cu modelul, utilizați un șir gol (""") pentru înlocuire.
- Număr_instanță (opțional) - instanța care trebuie înlocuită. Dacă se omite, se înlocuiesc toate corespondențele găsite (valoare implicită).
- Cazul_de_corespondență (opțional) - o valoare booleană care indică dacă trebuie să se potrivească sau să se ignore majusculele din text. Pentru o potrivire sensibilă la majuscule și minuscule, se utilizează TRUE (valoare implicită); pentru o potrivire insensibilă la majuscule și minuscule - FALSE.
Pentru mai multe informații, consultați funcția RegExpReplace.
Sfat. În cazuri simple, puteți elimina anumite caractere sau cuvinte din celule cu ajutorul formulelor Excel. Dar expresiile regulate oferă mult mai multe opțiuni în acest sens.
Cum să eliminați șiruri de caractere utilizând expresii regulate - exemple
După cum s-a menționat mai sus, pentru a elimina părțile de text care corespund unui model, trebuie să le înlocuiți cu un șir de caractere gol. Deci, o formulă generică are această formă:
RegExpReplace(text, pattern, "", [instance_num], [match_case])Exemplele de mai jos prezintă diverse implementări ale acestui concept de bază.
Eliminarea tuturor corespondențelor sau a unei anumite corespondențe
Funcția RegExpReplace este concepută pentru a găsi toate subșirurile care se potrivesc cu un regex dat. Ce apariții să elimine este controlat de al 4-lea argument opțional, numit număr_instanță .
Valoarea implicită este "toate meciurile" - atunci când număr_instanță este omis, toate corespondențele găsite sunt eliminate. Pentru a elimina o anumită corespondență, definiți numărul instanței.
În șirurile de mai jos, să presupunem că doriți să ștergeți primul număr de ordine. Toate aceste numere încep cu semnul hash (#) și conțin exact 5 cifre. Deci, le putem identifica folosind acest regex:
Model : #\d{5}\b
Limita cuvântului \b specifică faptul că o subșiră care se potrivește nu poate face parte dintr-un șir mai mare, cum ar fi #10000001.
Pentru a elimina toate corespondențele, se folosește opțiunea număr_instanță nu este definit:
=RegExpReplace(A5, "#\d{5}\b", "")
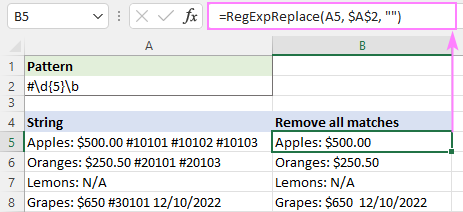
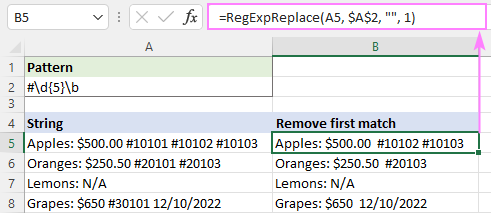
Pentru a eradica doar prima apariție, am stabilit număr_instanță la 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex pentru a elimina anumite caractere
Pentru a elimina anumite caractere dintr-un șir de caractere, trebuie doar să scrieți toate caracterele nedorite și să le separați cu o bară verticală.
De exemplu, pentru a standardiza numerele de telefon scrise în diferite formate, mai întâi trebuie să eliminăm caracterele specifice, cum ar fi parantezele, cratimele, punctele și spațiile albe.
Model : \(
=RegExpReplace(A5, "\(
Rezultatul acestei operații este un număr de 10 cifre, cum ar fi "1234567890".
Pentru comoditate, puteți introduce regex-ul într-o celulă separată și puteți face referire la acea celulă folosind o referință absolută, cum ar fi $A$2:
=RegExpReplace(A5, $A$2, "")
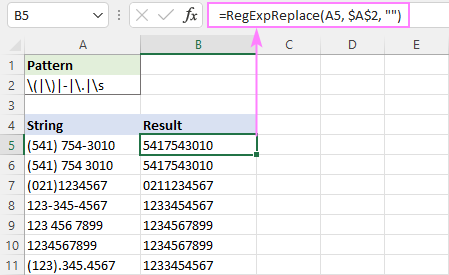
Apoi, puteți standardiza formatarea așa cum doriți, utilizând operatorul de concatenare (&) și funcțiile Text, cum ar fi RIGHT, MID și LEFT.
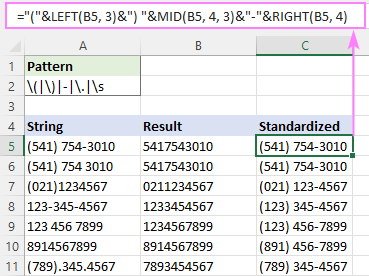
De exemplu, pentru a scrie toate numerele de telefon în formatul (123) 456-7890, formula este:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Unde B5 este rezultatul funcției RegExpReplace.
Eliminați caracterele speciale utilizând regex
Într-unul dintre tutorialele noastre, am analizat cum să eliminăm caracterele nedorite în Excel folosind funcții încorporate și personalizate. Expresiile regulate fac lucrurile mult mai ușoare! În loc să enumerați toate caracterele de eliminat, specificați-le doar pe cele pe care doriți să le păstrați :)
Modelul se bazează pe clase de caractere negate - se pune un caret în interiorul unei clase de caractere [^ ] pentru a se potrivi cu orice caracter unic care NU se află între paranteze. Cuantificatorul + îl forțează să considere caracterele consecutive ca fiind o singură potrivire, astfel încât înlocuirea se face pentru o subșir de caractere care se potrivește mai degrabă decât pentru fiecare caracter în parte.
În funcție de nevoile dumneavoastră, alegeți una dintre următoarele regexuri.
Pentru a elimina non-alfanumeric caractere, adică toate caracterele, cu excepția literelor și a cifrelor:
Model : [^0-9a-zA-Z]+
Pentru a șterge toate caracterele cu excepția literelor , cifre și spații :
Model : [^0-9a-zA-Z ]+
Pentru a șterge toate caracterele cu excepția literelor , cifre și subliniere , puteți utiliza \W, care reprezintă orice caracter care NU este un caracter alfanumeric sau o subliniere:
Model : \W+
Dacă doriți să să păstreze alte personaje , de exemplu semne de punctuație, puneți-le în interiorul parantezelor.
De exemplu, pentru a elimina orice alt caracter decât o literă, o cifră, un punct, o virgulă sau un spațiu, utilizați următorul regex:
Model : [^0-9a-zA-Z-Z\, ]+
Acest lucru elimină cu succes toate caracterele speciale, dar rămân spațiile albe suplimentare.
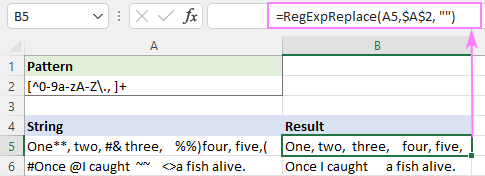
Pentru a remedia acest lucru, puteți anina funcția de mai sus într-o altă funcție care înlocuiește mai multe spații cu un singur caracter de spațiu.
=RegExpReplace(RegExpReplace(A5,$A$2,"""), " +", " " ")
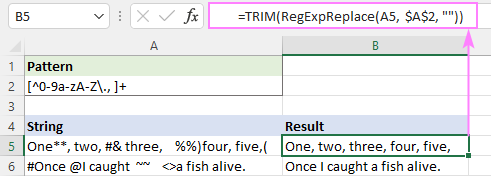
Sau puteți utiliza funcția nativă TRIM cu același efect:
=TRIM(RegExpReplace(A5, $A$2, ""))
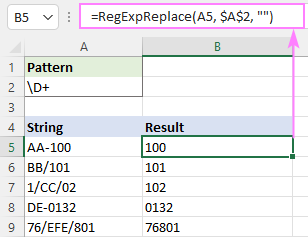
Regex pentru a elimina caracterele nenumerice
Pentru a șterge toate caracterele nenumerice dintr-un șir de caractere, puteți utiliza fie această formulă lungă, fie una dintre regexurile foarte simple enumerate mai jos.
Potrivește orice caracter care NU este o cifră:
Model : \D+
Elimină caracterele nenumerice utilizând clase negate:
Model : [^0-9]+
Model : [^\d]+
Sfat: Dacă obiectivul dvs. este de a elimina textul și de a vărsa numerele rămase în celule separate sau de a le plasa pe toate într-o singură celulă, separate cu un delimitator specificat, utilizați funcția RegExpExtract, așa cum se explică în Cum să extrageți numere dintr-un șir de caractere folosind expresii regulate.
Regex pentru a elimina totul după spațiu
Pentru a șterge tot ceea ce urmează după un spațiu, utilizați fie caracterul spațiu ( ), fie caracterul de spațiu (\s) pentru a găsi primul spațiu și .* pentru a potrivi toate caracterele de după acesta.
Dacă aveți șiruri de caractere de o singură linie care conțin doar spații normale (valoarea 32 în sistemul ASCII pe 7 biți), nu contează care dintre regexurile de mai jos se utilizează. În cazul șirurilor de caractere cu mai multe linii, este o diferență.
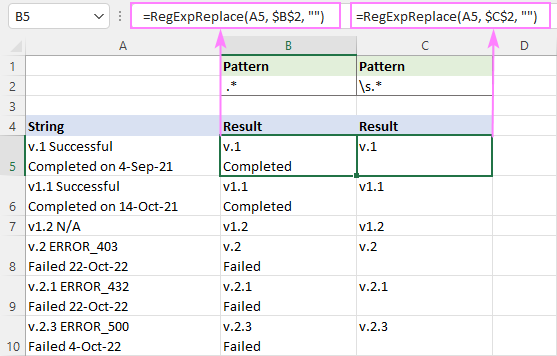
Pentru a elimina totul după un caracter de spațiu , utilizați acest regex:
Model : " .*"
=RegExpReplace(A5, " .*", "")
Această formulă va elimina tot ceea ce se află după primul spațiu din fiecare linie Pentru ca rezultatele să fie afișate corect, asigurați-vă că ați activat opțiunea Wrap Text.
Să se dezbrace de tot după un spațiu alb (inclusiv un spațiu, o tabulație, o revenire la cărămidă și o nouă linie), regexul este:
Model : \s.*
=RegExpReplace(A5, "\s.*", "")
Deoarece \s se potrivește cu câteva tipuri diferite de spații albe, inclusiv o nouă linie (\n), această formulă șterge tot ceea ce se află după primul spațiu dintr-o celulă, indiferent de numărul de rânduri pe care le conține.
Regex pentru a elimina textul după un anumit caracter
Utilizând metodele din exemplul anterior, puteți șterge textul după orice caracter pe care îl specificați.
Pentru a trata fiecare linie în parte:
Model generic : char.*
În șirurile de o singură linie, acest lucru va elimina tot ce urmează după char În șirurile de mai multe linii, fiecare linie va fi procesată individual, deoarece în VBA Regex, un punct (.) se potrivește cu orice caracter, cu excepția unei linii noi.
Pentru a procesa toate liniile ca un singur șir de caractere:
Model generic : char(.
Pentru a șterge tot ce urmează după un anumit caracter, inclusiv liniile noi, se adaugă \n la model.
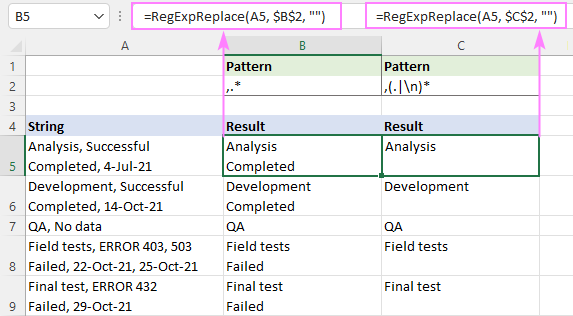
De exemplu, pentru a elimina textul de după prima virgulă dintr-un șir de caractere, încercați aceste expresii regulate:
Model : ,.*
Model : ,(.
În captura de ecran de mai jos, puteți examina modul în care diferă rezultatele.
Regex pentru a elimina totul înainte de spațiu
Atunci când lucrați cu șiruri lungi de text, este posibil ca uneori să doriți să le scurtați prin eliminarea aceleiași părți de informații din toate celulele. Mai jos vom discuta două astfel de cazuri.
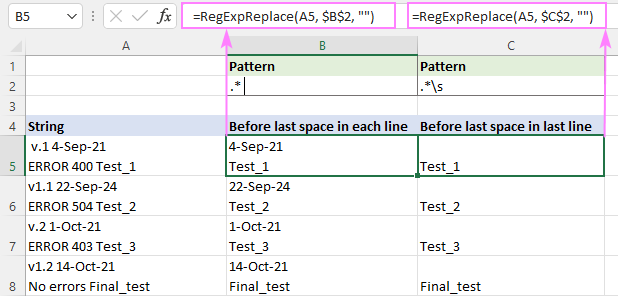
Îndepărtați tot ce se află înainte de ultimul spațiu
Ca și în exemplul anterior, o expresie regulată depinde de ceea ce înțelegeți prin "spațiu".
Pentru a potrivi orice până la ultimul spațiu , această regex va fi suficientă (se adaugă ghilimele pentru a face vizibil un spațiu după un asterisc).
Model : ".* "
Pentru a se potrivi cu orice lucru înainte de ultimul spațiu alb (inclusiv un spațiu, o tabulație, o revenire la cărămidă și o nouă linie), utilizați această expresie regulată.
Model : .*\s
Diferența este vizibilă mai ales în cazul șirurilor de mai multe rânduri.
Eliminați totul înainte de primul spațiu
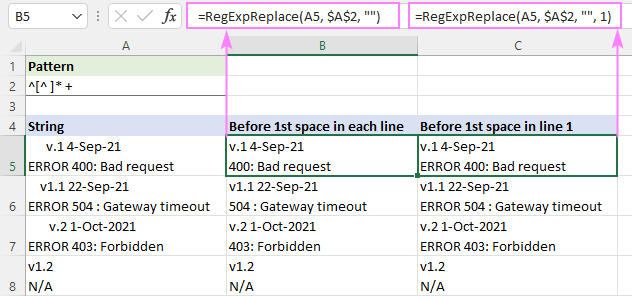
Pentru a potrivi orice până la primul spațiu dintr-un șir de caractere, puteți utiliza această expresie regulată:
Model : ^[^ ]* +
De la începutul unui șir ^, se potrivesc zero sau mai multe caractere fără spații [^ ]* care sunt urmate imediat de unul sau mai multe spații " +". Ultima parte este adăugată pentru a preveni eventualele spații de început în rezultate.
Pentru a elimina textul înainte de primul spațiu de pe fiecare linie, formula este scrisă în modul implicit "toate corespondențele" ( număr_instanță omis):
=RegExpReplace(A5, "^[^ ]* +", "")
Pentru a șterge textul înainte de primul spațiu de pe prima linie și a lăsa toate celelalte linii intacte, se folosește opțiunea număr_instanță este setat la 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex pentru a elimina tot ceea ce este înainte de caracter
Cel mai simplu mod de a elimina tot textul înainte de un anumit caracter este să folosești un regex ca acesta:
Model generic : ^[^char]*char
Tradus într-un limbaj uman, se spune: "de la începutul unui șir de caractere ancorat de ^, potriviți 0 sau mai multe caractere, cu excepția char [^char]* până la prima apariție a lui char .
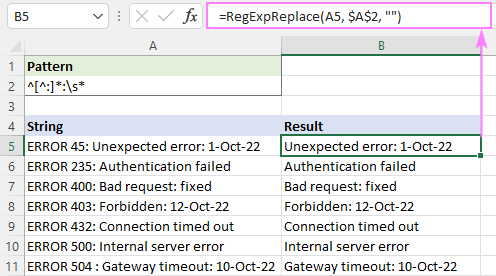
De exemplu, pentru a șterge tot textul de dinaintea primelor două puncte, utilizați această expresie regulată:
Model : ^[^:]*:
Pentru a evita spațiile de început în rezultate, adăugați un caracter de spațiu alb \s* la sfârșit. Acest lucru va elimina tot ceea ce se află înainte de primele două puncte și va tăia toate spațiile de după acestea:
Model : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Sfat. În afară de expresiile regulate, Excel dispune de propriile mijloace de eliminare a textului în funcție de poziție sau de potrivire. Pentru a afla cum să îndepliniți această sarcină cu ajutorul formulelor native, consultați Cum să eliminați textul înainte sau după un caracter în Excel.
Regex pentru a elimina totul, cu excepția
Pentru a elimina toate caracterele dintr-un șir de caractere, cu excepția celor pe care doriți să le păstrați, utilizați clasele de caractere negate.
De exemplu, pentru a elimina toate caracterele cu excepția literelor minuscule și a punctelor, regex-ul este:
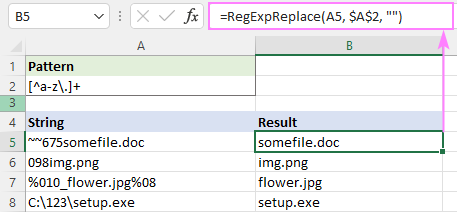
Model : [^a-z\.]+
De fapt, am putea renunța aici la cuantificatorul +, deoarece funcția noastră înlocuiește toate corespondențele găsite. Cuantificatorul face doar ca operațiunea să fie puțin mai rapidă - în loc să tratăm fiecare caracter în parte, înlocuim un subșir.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex pentru a elimina etichetele html în Excel
În primul rând, trebuie remarcat faptul că HTML nu este un limbaj regulat, astfel încât analizarea acestuia folosind expresii regulate nu este cea mai bună metodă. Acestea fiind spuse, regexurile pot ajuta cu siguranță la eliminarea etichetelor din celule pentru a face setul de date mai curat.
Având în vedere că etichetele html sunt întotdeauna plasate între paranteze unghiulare , le puteți găsi folosind una dintre următoarele regexuri.
Clasa negată:
Model : ]*>
Aici, se potrivește o paranteză unghiulară de deschidere, urmată de zero sau mai multe apariții ale oricărui caracter, cu excepția parantezei unghiulare de închidere [^>]* până la cea mai apropiată paranteză unghiulară de închidere.
Căutare leneșă:
Model :
Aici, se potrivește orice de la prima paranteză de deschidere până la prima paranteză de închidere. Semnul de întrebare forțează .* să potrivească cât mai puține caractere posibil până când găsește o paranteză de închidere.
Indiferent de modelul pe care îl alegeți, rezultatul va fi absolut același.
De exemplu, pentru a elimina toate etichetele html dintr-un șir de caractere din A5 și a lăsa textul, formula este:
=RegExpReplace(A5, "]*>", "")
Sau puteți utiliza cuantificatorul leneș, așa cum se arată în captura de ecran:
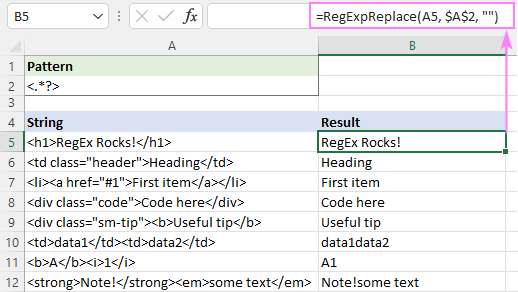
Această soluție funcționează perfect pentru un singur text (rândurile 5 - 9). În cazul textelor multiple (rândurile 10 - 12), rezultatele sunt discutabile - textele din etichete diferite sunt unite într-unul singur. Este corect sau nu? Mă tem că nu este ceva ce poate fi decis cu ușurință - totul depinde de modul în care înțelegeți rezultatul dorit. De exemplu, în B11, se așteaptă rezultatul "A1"; în timp ce în B10, s-ar putea să doriți"data1" și "data2" trebuie să fie separate printr-un spațiu.
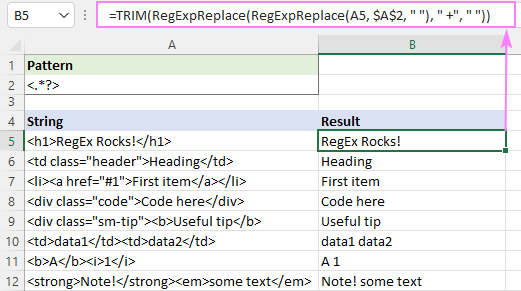
Pentru a elimina etichetele html și a separa textele rămase cu spații, puteți proceda astfel:
- Înlocuiți etichetele cu spații " ", nu cu șiruri de caractere goale:
=RegExpReplace(A5, "]*>", " " ") - Reducerea mai multor spații la un singur caracter de spațiu:
=RegExpReplace(RegExpReplace(A5, "]*>", " " "), " +", " " ") - Tăiați spațiile de început și de sfârșit:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " " "), " +", " " ")))
Rezultatul va arăta cam așa:
Ablebits Regex Remove Tool
Dacă ați avut ocazia să folosiți suita noastră Ultimate Suite pentru Excel, probabil că ați descoperit deja noile instrumente Regex introduse odată cu recenta versiune. Frumusețea acestor funcții Regex bazate pe .NET este că, în primul rând, acceptă o sintaxă de expresie regulată completă, fără limitări VBA RegExp, și în al doilea rând, nu necesită inserarea de cod VBA în registrele de lucru, deoarece toată integrarea codului se realizeazăde către noi în partea din spate.
Partea ta de lucru este să construiești o expresie regulată și să o servești funcției :) Permiteți-mi să vă arăt cum se face acest lucru într-un exemplu practic.
Cum să eliminați textul din paranteze și paranteze folosind regex
În șirurile lungi de text, informațiile mai puțin importante sunt adesea incluse în [paranteze] și (paranteze). Cum puteți elimina aceste detalii irelevante păstrând toate celelalte date?
De fapt, am construit deja un regex similar pentru ștergerea etichetelor html, adică a textului din interiorul parantezelor unghiulare. Evident, aceleași metode vor funcționa și pentru parantezele pătrate și rotunde.
Model : (\(.*?\))
Trucul constă în utilizarea unui cuantificator leneș (*?) pentru a se potrivi cu cea mai scurtă subșiră posibilă. Primul grup (\(.*?\)) se potrivește cu orice, de la o paranteză de deschidere până la prima paranteză de închidere. Al doilea grup (\[.*?\]) se potrivește cu orice, de la o paranteză de deschidere până la prima paranteză de închidere. O bară verticală
După ce am determinat modelul, să îl "alimentăm" cu funcția Regex Remove. Iată cum:
- Pe Date Ablebits în fila Text grup, faceți clic pe Instrumente Regex .
Pentru a obține rezultatele sub formă de formule, nu de valori, selectați opțiunea Introduceți ca o formulă caseta de selectare.
Pentru a elimina textul între paranteze din șirurile de caractere din A2:A5, configurăm setările după cum urmează:
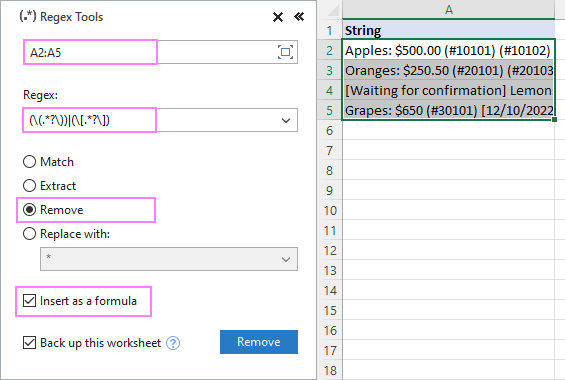
Ca urmare, a rezultat că AblebitsRegexRemove este inserată într-o nouă coloană, alături de datele originale.
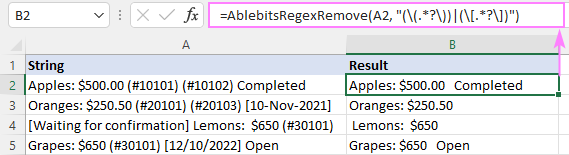
Funcția poate fi, de asemenea, introdusă direct într-o celulă prin intermediul funcției standard Funcția de inserție în care este clasificat la rubrica AblebitsUDFs .
Ca AblebitsRegexRemove este concepută pentru a elimina text, aceasta necesită doar două argumente - șirul sursă și regex. Ambii parametri pot fi definiți direct într-o formulă sau furnizați sub formă de referințe de celule. Dacă este necesar, această funcție personalizată poate fi utilizată împreună cu oricare dintre cele native.
De exemplu, pentru a tăia spațiile în plus din șirurile rezultate, puteți utiliza funcția TRIM ca un înveliș:
=TRIM(AblebitsRegexRemove(A5, $A$2))
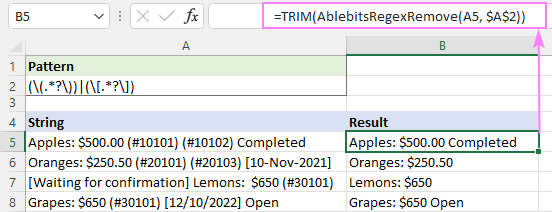
Iată cum să eliminați șiruri de caractere în Excel folosind expresii regulate. Vă mulțumesc pentru lectură și vă aștept pe blogul nostru săptămâna viitoare!
Descărcări disponibile
Eliminarea șirurilor de caractere utilizând regex - exemple (fișier .xlsm)
Ultimate Suite - versiunea de încercare (fișier .exe)
