
ສາລະບານ
ໃນສະຕຣິງລຸ່ມນີ້, ສົມມຸດວ່າທ່ານຕ້ອງການລຶບໝາຍເລກລຳດັບທຳອິດ. ຕົວເລກດັ່ງກ່າວທັງໝົດເລີ່ມຕົ້ນດ້ວຍເຄື່ອງໝາຍ hash (#) ແລະມີ 5 ຕົວເລກແທ້. ດັ່ງນັ້ນ, ພວກເຮົາສາມາດລະບຸພວກມັນໄດ້ໂດຍໃຊ້ regex ນີ້:
Pattern : #\d{5}\b
ຄຳວ່າ boundary \b ກຳນົດວ່າສະຕຣິງຍ່ອຍທີ່ກົງກັນບໍ່ສາມາດເປັນໄດ້. ສ່ວນໜຶ່ງຂອງສະຕຣິງທີ່ໃຫຍ່ກວ່າເຊັ່ນ #10000001.
ເພື່ອລຶບຂໍ້ມູນທີ່ກົງກັນທັງໝົດ, argument instance_num ບໍ່ໄດ້ຖືກກຳນົດ:
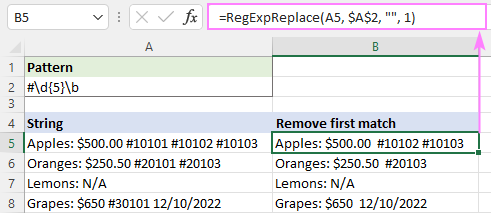
=RegExpReplace(A5, "#\d{5}\b", "")
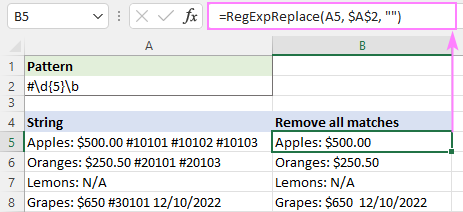
ເພື່ອລົບລ້າງພຽງແຕ່ການປະກົດຕົວຄັ້ງທໍາອິດ, ພວກເຮົາຕັ້ງ instance_num argument ເປັນ 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex ເພື່ອເອົາຕົວອັກສອນບາງຕົວອອກ
ເພື່ອຖອດຕົວອັກສອນບາງຕົວອອກຈາກສະຕຣິງ, ພຽງແຕ່ຂຽນຕົວອັກສອນທີ່ບໍ່ຕ້ອງການທັງໝົດ ແລະແຍກພວກມັນອອກດ້ວຍແຖບຕັ້ງ.syntax ທີ່ບໍ່ມີຂໍ້ຈໍາກັດຂອງ VBA RegExp, ແລະອັນທີສອງ, ບໍ່ຈໍາເປັນຕ້ອງໃສ່ລະຫັດ VBA ໃດໆໃນປື້ມບັນທຶກຂອງທ່ານຍ້ອນວ່າການລວມລະຫັດທັງຫມົດແມ່ນເຮັດໂດຍພວກເຮົາຢູ່ໃນ backend.
ສ່ວນຫນຶ່ງຂອງວຽກຂອງທ່ານແມ່ນເພື່ອສ້າງການສະແດງອອກປົກກະຕິແລະ ຮັບໃຊ້ມັນໃຫ້ກັບຟັງຊັນ :) ໃຫ້ຂ້ອຍສະແດງວິທີເຮັດແນວນັ້ນໃນຕົວຢ່າງພາກປະຕິບັດ.
ວິທີລຶບຂໍ້ຄວາມໃນວົງເລັບ ແລະວົງເລັບໂດຍໃຊ້ regex
ໃນສະຕຣິງຂໍ້ຄວາມຍາວ, ຂໍ້ມູນທີ່ມີຄວາມສໍາຄັນຫນ້ອຍ. ມັກຈະຖືກຫຸ້ມຢູ່ໃນ [ວົງເລັບ] ແລະ (ວົງເລັບ). ເຈົ້າເອົາລາຍລະອຽດທີ່ບໍ່ກ່ຽວຂ້ອງເຫຼົ່ານັ້ນໄປຮັກສາຂໍ້ມູນອື່ນໆທັງໝົດໄດ້ແນວໃດ?
ໃນຄວາມເປັນຈິງແລ້ວ, ພວກເຮົາໄດ້ສ້າງ regex ທີ່ຄ້າຍຄືກັນສໍາລັບການລຶບແທັກ html, ເຊັ່ນ: ຂໍ້ຄວາມພາຍໃນວົງເລັບມຸມ. ແນ່ນອນ, ວິທີການດຽວກັນຈະໃຊ້ໄດ້ກັບວົງເລັບສີ່ຫຼ່ຽມ ແລະ ວົງມົນ.
ຮູບແບບ : (\.*?\))
ທ່ານເຄີຍຄິດບໍ່ວ່າ Excel ຈະມີປະສິດທິພາບຂະໜາດໃດ ຖ້າຜູ້ໃດຜູ້ໜຶ່ງສາມາດເສີມສ້າງກ່ອງເຄື່ອງມືຂອງຕົນດ້ວຍການສະແດງອອກເປັນປົກກະຕິ? ພວກເຮົາບໍ່ພຽງແຕ່ຄິດແຕ່ເຮັດວຽກກັບມັນ :) ແລະດຽວນີ້, ທ່ານສາມາດເພີ່ມຟັງຊັນ RegEx ທີ່ດີເລີດນີ້ໃສ່ປຶ້ມວຽກຂອງເຈົ້າເອງ ແລະລຶບຂໍ້ຄວາມຍ່ອຍທີ່ກົງກັບຮູບແບບໃນບໍ່ດົນນີ້!
ອາທິດທີ່ຜ່ານມາ, ພວກເຮົາໄດ້ເບິ່ງ ໃນວິທີການໃຊ້ expression ປົກກະຕິເພື່ອທົດແທນ strings ໃນ Excel. ສໍາລັບການນີ້, ພວກເຮົາໄດ້ສ້າງຫນ້າທີ່ກໍາຫນົດເອງ Regex Replace. ຍ້ອນວ່າມັນໄດ້ຫັນອອກ, ຟັງຊັນເກີນກວ່າການນໍາໃຊ້ຕົ້ນຕໍຂອງມັນແລະບໍ່ພຽງແຕ່ສາມາດທົດແທນສາຍແຕ່ຍັງເອົາພວກມັນອອກ. ມັນເປັນໄປໄດ້ແນວໃດ? ໃນແງ່ຂອງ Excel, ການຖອນຄ່າແມ່ນບໍ່ມີຫຍັງນອກ ເໜືອ ຈາກການທົດແທນມັນດ້ວຍສະຕຣິງຫວ່າງເປົ່າ, ບາງສິ່ງບາງຢ່າງທີ່ຟັງຊັນ Regex ຂອງພວກເຮົາແມ່ນດີຫຼາຍ!
ຟັງຊັນ VBA RegExp ເພື່ອເອົາສາຍຍ່ອຍໃນ Excel
ດັ່ງທີ່ພວກເຮົາທຸກຄົນຮູ້ວ່າ, ການສະແດງອອກປົກກະຕິແມ່ນບໍ່ໄດ້ສະຫນັບສະຫນູນໃນ Excel ໂດຍຄ່າເລີ່ມຕົ້ນ. ເພື່ອເປີດໃຊ້ພວກມັນ, ທ່ານຈໍາເປັນຕ້ອງສ້າງຫນ້າທີ່ກໍານົດໂດຍຜູ້ໃຊ້ຂອງທ່ານເອງ. ຂ່າວດີແມ່ນວ່າຟັງຊັນດັ່ງກ່າວໄດ້ຖືກຂຽນແລ້ວ, ທົດສອບ, ແລະກຽມພ້ອມສໍາລັບການນໍາໃຊ້. ສິ່ງທີ່ທ່ານຕ້ອງເຮັດຄືການສຳເນົາລະຫັດນີ້, ວາງໃສ່ໃນຕົວແກ້ໄຂ VBA ຂອງທ່ານ, ແລະຈາກນັ້ນບັນທຶກໄຟລ໌ຂອງທ່ານເປັນ ປຶ້ມວຽກທີ່ເປີດໃຊ້ Macro (.xlsm).
ຟັງຊັນມີ syntax ຕໍ່ໄປນີ້:
RegExpReplace(ຂໍ້ຄວາມ, ຮູບແບບ, ການທົດແທນ, [instance_num], [match_case])ຕ້ອງການສາມ argument ທໍາອິດ, ສອງອັນສຸດທ້າຍແມ່ນທາງເລືອກ.
ຢູ່ໃສ:
- ຂໍ້ຄວາມ - ຂໍ້ຄວາມເພື່ອຄົ້ນຫາເປັນໄປໄດ້ຈົນກ່ວາມັນຊອກຫາວົງເລັບປິດ.
ບໍ່ວ່າທ່ານຈະເລືອກຮູບແບບໃດ, ຜົນໄດ້ຮັບຈະຄືກັນຢ່າງແທ້ຈິງ.
ຕົວຢ່າງ, ເພື່ອເອົາແທັກ html ທັງໝົດອອກຈາກສະຕຣິງ A5 ແລະອອກຈາກຂໍ້ຄວາມ, ສູດແມ່ນ:
=RegExpReplace(A5, "]*>", "")
ຫຼືທ່ານສາມາດນໍາໃຊ້ຕົວກໍານົດປະລິມານຂີ້ກຽດຕາມທີ່ສະແດງຢູ່ໃນຫນ້າຈໍ:
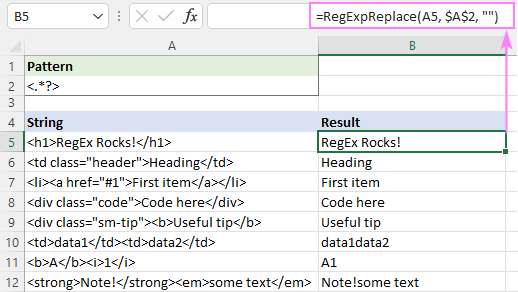
ການແກ້ໄຂນີ້ເຮັດວຽກຢ່າງສົມບູນສໍາລັບ ຂໍ້ຄວາມດຽວ (ແຖວ 5 - 9). ສໍາລັບບົດເລື່ອງຫຼາຍ (ແຖວທີ 10 - 12), ຜົນໄດ້ຮັບແມ່ນຄໍາຖາມ - ຂໍ້ຄວາມຈາກ tags ທີ່ແຕກຕ່າງກັນຖືກລວມເຂົ້າໄປໃນຫນຶ່ງ. ອັນນີ້ຖືກຕ້ອງຫຼືບໍ່? ຂ້ອຍຢ້ານ, ມັນບໍ່ແມ່ນສິ່ງທີ່ສາມາດຕັດສິນໃຈໄດ້ງ່າຍ - ທັງຫມົດແມ່ນຂຶ້ນກັບຄວາມເຂົ້າໃຈຂອງເຈົ້າກ່ຽວກັບຜົນໄດ້ຮັບທີ່ຕ້ອງການ. ຕົວຢ່າງ, ໃນ B11, ຜົນໄດ້ຮັບ "A1" ຄາດວ່າຈະ; ໃນຂະນະທີ່ຢູ່ໃນ B10, ທ່ານອາດຈະຕ້ອງການໃຫ້ "data1" ແລະ "data2" ແຍກອອກດ້ວຍຊ່ອງຫວ່າງ.
ເພື່ອເອົາແທັກ html ແລະແຍກຂໍ້ຄວາມທີ່ຍັງເຫຼືອອອກດ້ວຍຍະຫວ່າງ, ທ່ານສາມາດດໍາເນີນການດ້ວຍວິທີນີ້:
- ແທນທີ່ແທັກດ້ວຍຍະຫວ່າງ " ", ບໍ່ແມ່ນສະຕຣິງຫວ່າງເປົ່າ:
=RegExpReplace(A5, "]*>", " ") - ຫຼຸດຊ່ອງຫວ່າງຫຼາຍຊ່ອງໃສ່ຕົວອັກສອນດຽວ:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - ຕັດຊ່ອງນຳໜ້າ ແລະຕໍ່ທ້າຍ:
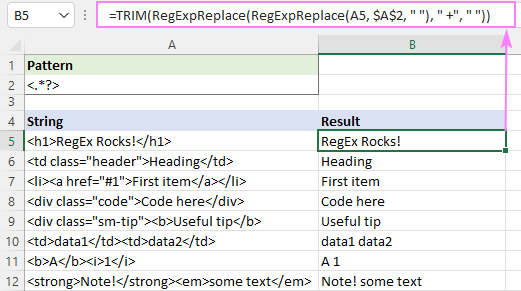
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
ຜົນໄດ້ຮັບຈະເປັນແບບນີ້:
Ablebits Regex Remove Tool
ຖ້າທ່ານໄດ້ມີໂອກາດໃຊ້ Ultimate Suite ຂອງພວກເຮົາສໍາລັບ Excel, ທ່ານອາດຈະໄດ້ຄົ້ນພົບ Regex Tools ໃໝ່ທີ່ນຳສະເໜີກັບລຸ້ນທີ່ຜ່ານມາ. ຄວາມງາມຂອງຟັງຊັນ Regex ທີ່ອີງໃສ່ .NET ເຫຼົ່ານີ້ແມ່ນວ່າ, ທໍາອິດ, ສະຫນັບສະຫນູນການສະແດງອອກປົກກະຕິຢ່າງເຕັມທີ່.ທາງເລືອກ Remove , ແລະກົດ Remove .
ເພື່ອໃຫ້ໄດ້ຮັບຜົນໄດ້ຮັບເປັນສູດ, ບໍ່ແມ່ນຄ່າ, ເລືອກ Insert as a formula check box.
ເພື່ອເອົາຂໍ້ຄວາມພາຍໃນວົງເລັບອອກຈາກ strings ໃນ A2:A5, ພວກເຮົາກໍານົດການຕັ້ງຄ່າ. ດັ່ງລຸ່ມນີ້:
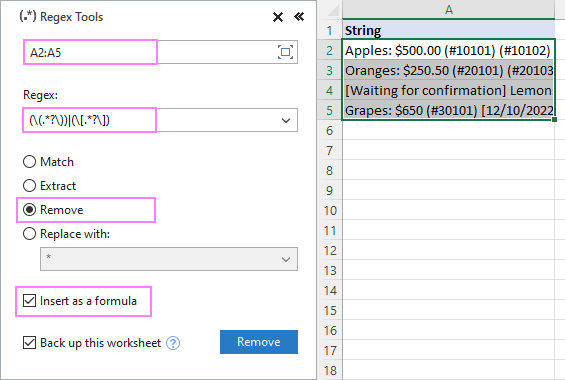
ດັ່ງນີ້, ຟັງຊັນ AblebitsRegexRemove ຖືກໃສ່ໃນຖັນໃໝ່ຖັດຈາກຂໍ້ມູນຕົ້ນສະບັບຂອງທ່ານ.
ໃນຖານະທີ່ AblebitsRegexRemove ຖືກອອກແບບມາເພື່ອເອົາຂໍ້ຄວາມອອກ, ມັນຕ້ອງການພຽງແຕ່ສອງອາກິວເມັນ - ຂໍ້ຄວາມຕົ້ນສະບັບ ແລະ regex. ທັງສອງພາລາມິເຕີສາມາດຖືກກໍານົດໂດຍກົງໃນສູດຫຼືສະຫນອງໃນຮູບແບບການອ້າງອີງເຊນ. ຖ້າຕ້ອງການ, ຟັງຊັນແບບກຳນົດເອງນີ້ສາມາດໃຊ້ຮ່ວມກັບອັນໃດກໍໄດ້.
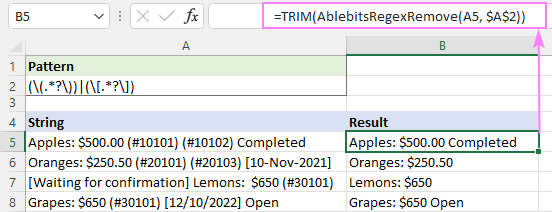
ຕົວຢ່າງ, ເພື່ອຕັດຊ່ອງຫວ່າງເພີ່ມເຕີມໃນສະຕຣິງທີ່ໄດ້ຮັບຜົນ, ທ່ານສາມາດໃຊ້ຟັງຊັນ TRIM ເປັນ wrapper:
=TRIM(AblebitsRegexRemove(A5, $A$2))
ນັ້ນຄືວິທີລຶບສະຕຣິງໃນ Excel ໂດຍໃຊ້ຕົວສະແດງປົກກະຕິ. ຂ້າພະເຈົ້າຂໍຂອບໃຈທ່ານສໍາລັບການອ່ານແລະຫວັງວ່າຈະໄດ້ພົບທ່ານໃນ blog ຂອງພວກເຮົາໃນອາທິດຕໍ່ໄປ!
ມີໃຫ້ດາວໂຫລດ
ລຶບ strings ໂດຍໃຊ້ regex - ຕົວຢ່າງ (ໄຟລ໌ .xlsm)
Ultimate Suite - ລຸ້ນທົດລອງ (ໄຟລ໌ .exe)
in.ສຳລັບຂໍ້ມູນເພີ່ມເຕີມ, ກະລຸນາເບິ່ງຟັງຊັນ RegExpReplace.
ເຄັດລັບ. ໃນກໍລະນີງ່າຍດາຍ, ທ່ານສາມາດເອົາຕົວອັກສອນຫຼືຄໍາສັບຕ່າງໆອອກຈາກຈຸລັງດ້ວຍສູດ Excel. ແຕ່ສຳນວນປົກກະຕິໃຫ້ທາງເລືອກຫຼາຍອັນສຳລັບອັນນີ້.
ວິທີລຶບສະຕຣິງໂດຍໃຊ້ສຳນວນປົກກະຕິ - ຕົວຢ່າງ
ດັ່ງທີ່ກ່າວມາຂ້າງເທິງ, ເພື່ອລຶບສ່ວນຕ່າງໆຂອງຂໍ້ຄວາມທີ່ກົງກັບຮູບແບບໃດໜຶ່ງ, ເຈົ້າຕ້ອງປ່ຽນແທນພວກມັນ. ດ້ວຍສາຍເປົ່າ. ດັ່ງນັ້ນ, ສູດທົ່ວໄປໃຊ້ຮູບແບບນີ້:
RegExpReplace(ຂໍ້ຄວາມ, ຮູບແບບ, "", [instance_num], [match_case])ຕົວຢ່າງຂ້າງລຸ່ມນີ້ສະແດງໃຫ້ເຫັນການຈັດຕັ້ງປະຕິບັດແນວຄວາມຄິດພື້ນຖານນີ້.
ເອົາອອກ. ການແຂ່ງຂັນທັງໝົດ ຫຼືການຈັບຄູ່ສະເພາະ
ຟັງຊັນ RegExpReplace ຖືກອອກແບບມາເພື່ອຊອກຫາສາຍຍ່ອຍທັງໝົດທີ່ກົງກັບ regex ທີ່ໃຫ້ໄວ້. ການປະກົດຕົວທີ່ຈະເອົາອອກແມ່ນຄວບຄຸມໂດຍອາກິວເມັນທາງເລືອກທີ 4, ຊື່ instance_num .
ຄ່າເລີ່ມຕົ້ນແມ່ນ "ກົງກັນທັງໝົດ" - ເມື່ອ instance_num ຕົວປະຕິບັດການຕິດຕໍ່ກັນ (&) ແລະຟັງຊັນຂໍ້ຄວາມ ເຊັ່ນ: ຂວາ, ກາງ ແລະ ຊ້າຍ.
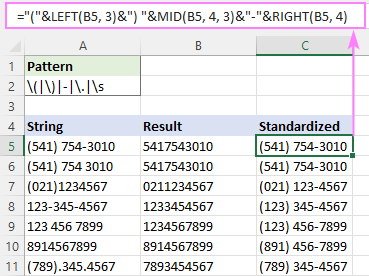
ຕົວຢ່າງ, ເພື່ອຂຽນເບີໂທລະສັບທັງໝົດໃນຮູບແບບ (123) 456-7890, ສູດແມ່ນ:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
ບ່ອນທີ່ B5 ເປັນຜົນຜະລິດຂອງຟັງຊັນ RegExpReplace.
ເອົາຕົວອັກສອນພິເສດອອກໂດຍໃຊ້ regex
ໃນບົດສອນໜຶ່ງຂອງພວກເຮົາ, ພວກເຮົາໄດ້ເບິ່ງວິທີການເອົາຕົວອັກສອນທີ່ບໍ່ຕ້ອງການໃນ Excel ໂດຍໃຊ້ inbuilt ແລະຫນ້າທີ່ກໍາຫນົດເອງ. ການສະແດງອອກເປັນປົກກະຕິເຮັດໃຫ້ສິ່ງຕ່າງໆງ່າຍຂຶ້ນຫຼາຍ! ແທນທີ່ຈະໃຫ້ລາຍຊື່ຕົວອັກສອນທັງຫມົດທີ່ຈະລົບ, ພຽງແຕ່ລະບຸຕົວທີ່ທ່ານຕ້ອງການທີ່ຈະເກັບຮັກສາ :)
ຮູບແບບແມ່ນອີງໃສ່ ລະດັບຕົວອັກສອນທີ່ຖືກລົບ - ຄາລະດູການແມ່ນໄດ້ວາງໄວ້ໃນລະດັບຕົວອັກສອນ [^ ] ເພື່ອໃຫ້ກົງກັບຕົວອັກສອນດຽວທີ່ບໍ່ຢູ່ໃນວົງເລັບ. + quantifier ບັງຄັບໃຫ້ມັນຖືວ່າຕົວລະຄອນຕິດຕໍ່ກັນເປັນການຈັບຄູ່ດຽວ, ດັ່ງນັ້ນການປ່ຽນແທນແມ່ນເຮັດໄດ້ສໍາລັບສະຕຣິງຍ່ອຍທີ່ກົງກັນ ແທນທີ່ຈະເປັນແຕ່ລະຕົວລະຄອນ.
ອີງຕາມຄວາມຕ້ອງການຂອງທ່ານ, ເລືອກຫນຶ່ງໃນ regexes ຕໍ່ໄປນີ້.
ເພື່ອລຶບ ຕົວອັກສອນທີ່ບໍ່ແມ່ນຕົວເລກ ອອກ, ເຊັ່ນ: ຕົວອັກສອນທັງໝົດຍົກເວັ້ນຕົວອັກສອນ ແລະຕົວເລກ:
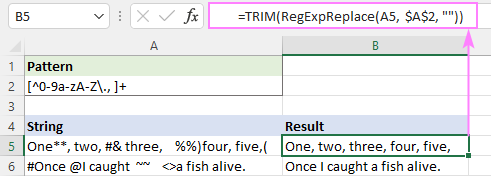
ຮູບແບບ : [^0-9a-zA-Z] +
ເພື່ອລຶບຕົວອັກສອນທັງໝົດ ຍົກເວັ້ນຕົວອັກສອນ , ຕົວເລກ ແລະ ຍະຫວ່າງ :
ຮູບແບບ : [^0-9a-zA-Z ]+
ເພື່ອລຶບຕົວອັກສອນທັງໝົດ ຍົກເວັ້ນຕົວອັກສອນ , ຕົວເລກ ແລະ ຂີດກ້ອງ , ທ່ານສາມາດໃຊ້ \ W ທີ່ຫຍໍ້ມາຈາກຕົວອັກສອນທີ່ບໍ່ແມ່ນຕົວອັກສອນທີ່ເປັນຕົວເລກ ຫຼື ຕົວໜັງສືunderscore:
Pattern : \W+
ຖ້າທ່ານຕ້ອງການ ຮັກສາຕົວອັກສອນອື່ນໆບາງຕົວ , ເຊັ່ນ:. ເຄື່ອງໝາຍວັກຕອນ, ເອົາພວກມັນໃສ່ໃນວົງເລັບ.
ຕົວຢ່າງ, ເພື່ອຖອດຕົວອັກສອນອື່ນນອກເໜືອໄປຈາກຕົວອັກສອນ, ຕົວເລກ, ໄລຍະເວລາ, ເຄື່ອງໝາຍຈຸດ ຫຼືຍະຫວ່າງ, ໃຫ້ໃຊ້ regex ຕໍ່ໄປນີ້:
Pattern : [^0-9a-zA-Z\., ]+
ອັນນີ້ກໍາຈັດຕົວອັກສອນພິເສດທັງໝົດໄດ້ສຳເລັດ, ແຕ່ຊ່ອງຫວ່າງເພີ່ມເຕີມຍັງຄົງຢູ່.
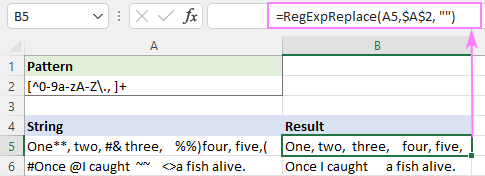
ເພື່ອແກ້ໄຂອັນນີ້, ທ່ານສາມາດວາງຟັງຊັນຂ້າງເທິງໃສ່ໃນອັນອື່ນທີ່ແທນທີ່ຊ່ອງຫວ່າງຫຼາຍຊ່ອງດ້ວຍຕົວອັກສອນຊ່ອງດຽວ.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
ຫຼືພຽງແຕ່ໃຊ້ຟັງຊັນ TRIM ເດີມທີ່ມີຜົນດຽວກັນ. :
=TRIM(RegExpReplace(A5, $A$2, ""))
Regex ເພື່ອລຶບຕົວອັກສອນທີ່ບໍ່ແມ່ນຕົວເລກ
ເພື່ອລຶບຕົວອັກສອນທີ່ບໍ່ແມ່ນຕົວເລກທັງໝົດອອກຈາກສະຕຣິງໃດໜຶ່ງ, ທ່ານສາມາດໃຊ້ ສູດຄຳນວນຍາວນີ້ ຫຼືໜຶ່ງໃນ regexes ງ່າຍໆທີ່ລະບຸໄວ້ຂ້າງລຸ່ມນີ້.
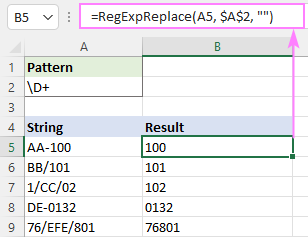
ຈັບຄູ່ຕົວອັກສອນທີ່ບໍ່ແມ່ນຕົວເລກ:
ຮູບແບບ : \D+
ລອກເອົາຕົວອັກສອນທີ່ບໍ່ແມ່ນຕົວເລກໂດຍໃຊ້ຊັ້ນລົບ:
ຮູບແບບ : [^0-9]+
ຮູບແບບ : [^\d] +
ເຄັດລັບ. ຖ້າເປົ້າຫມາຍຂອງທ່ານແມ່ນເພື່ອເອົາຂໍ້ຄວາມອອກແລະຂີ້ເຫຍື້ອຈໍານວນທີ່ຍັງເຫຼືອເຂົ້າໄປໃນຈຸລັງແຍກຕ່າງຫາກຫຼືວາງພວກມັນທັງຫມົດໃນຫນຶ່ງເຊນທີ່ແຍກອອກດ້ວຍຕົວຂັ້ນທີ່ລະບຸ, ຫຼັງຈາກນັ້ນໃຫ້ໃຊ້ຟັງຊັນ RegExpExtract ດັ່ງທີ່ໄດ້ອະທິບາຍໄວ້ໃນວິທີການສະກັດຕົວເລກຈາກສະຕຣິງໂດຍໃຊ້ການສະແດງປົກກະຕິ.
Regex ເພື່ອເອົາທຸກຢ່າງອອກຫຼັງຈາກຍະຫວ່າງ
ເພື່ອລຶບລ້າງທຸກຢ່າງຫຼັງຈາກຍະຫວ່າງ, ໃຫ້ໃຊ້ຊ່ອງຫວ່າງ ( ) ຫຼືຕົວອັກສອນ whitespace (\s) ເພື່ອຊອກຫາຊ່ອງຫວ່າງທຳອິດ ແລະ .* ເພື່ອຈັບຄູ່ຕົວອັກສອນໃດນຶ່ງຫຼັງຈາກມັນ.
ຫາກເຈົ້າມີສາຍແຖວດຽວທີ່ມີຊ່ອງຫວ່າງປົກກະຕິ (ຄ່າ 32 ໃນລະບົບ 7-bit ASCII) , ມັນບໍ່ສໍາຄັນວ່າອັນໃດຂອງ regexes ຂ້າງລຸ່ມນີ້ທີ່ທ່ານໃຊ້. ໃນກໍລະນີຂອງຫຼາຍແຖວ, ມັນເຮັດໃຫ້ມີຄວາມແຕກຕ່າງ.
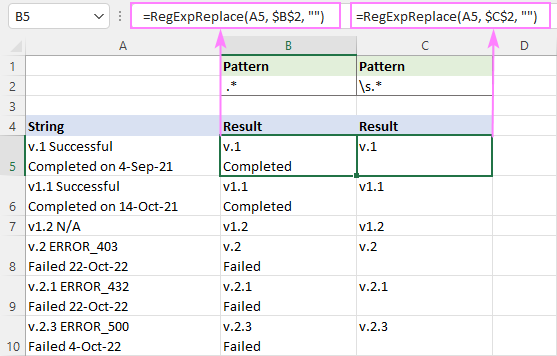
ເພື່ອລຶບທຸກຢ່າງ ຫຼັງຈາກຕົວອັກສອນຍະຫວ່າງ , ໃຊ້ regex ນີ້:
ຮູບແບບ : " .*"
=RegExpReplace(A5, " .*", "")
ສູດນີ້ຈະຕັດອັນໃດອັນໜຶ່ງຫຼັງຈາກຍະຫວ່າງທຳອິດໃນ ແຕ່ລະແຖວ . ເພື່ອໃຫ້ຜົນໄດ້ຮັບສະແດງຢ່າງຖືກຕ້ອງ, ໃຫ້ແນ່ໃຈວ່າໄດ້ເປີດ Wrap Text.
ເພື່ອຖອດທຸກຢ່າງອອກ ຫຼັງຈາກຍະຫວ່າງ (ລວມທັງຊ່ອງຫວ່າງ, ແຖບ, ການກັບຄືນ carriage ແລະແຖວໃຫມ່), regex ແມ່ນ:
ຮູບແບບ : \s.*
=RegExpReplace(A5, "\s.*", "")
ເພາະວ່າ \s ກົງກັບບາງປະເພດຊ່ອງຫວ່າງຕ່າງໆ ລວມທັງ ແຖວໃໝ່ (\n), ສູດນີ້ລຶບທຸກຢ່າງຫຼັງຈາກຊ່ອງທໍາອິດໃນຕາລາງ, ບໍ່ວ່າມີແຖວໃດຢູ່ໃນນັ້ນ.
Regex ເພື່ອລຶບຂໍ້ຄວາມອອກຫຼັງຈາກສະເພາະ. ຕົວອັກສອນ
ການນໍາໃຊ້ວິທີການຈາກຕົວຢ່າງທີ່ຜ່ານມາ, ທ່ານສາມາດລົບລ້າງຂໍ້ຄວາມຫຼັງຈາກຕົວອັກສອນໃດຫນຶ່ງທີ່ທ່ານລະບຸ.
ເພື່ອຈັດການແຕ່ລະແຖວແຍກຕ່າງຫາກ:
ແບບທົ່ວໄປ : char.*
ໃນສະຕຣິງແຖວດຽວ, ນີ້ຈະລຶບທຸກຢ່າງຫຼັງຈາກ char . ໃນສາຍສະຕຣິງຫຼາຍສາຍ, ແຕ່ລະສາຍຈະຖືກປະມວນຜົນເປັນສ່ວນບຸກຄົນເພາະວ່າໃນ VBA Regex ລົດຊາດ, ໄລຍະເວລາ (.) ກົງກັບຕົວອັກສອນໃດນຶ່ງ ຍົກເວັ້ນຕົວອັກສອນໃໝ່.ເລີ່ມຕົ້ນຂອງສະຕຣິງ ^, ພວກເຮົາຈັບຄູ່ຕົວອັກສອນທີ່ບໍ່ມີຊ່ອງຫວ່າງສູນ ຫຼືຫຼາຍກວ່ານັ້ນ [^ ]* ທີ່ຕິດຕາມດ້ວຍຊ່ອງຫວ່າງໜຶ່ງ ຫຼືຫຼາຍກວ່າ "+". ສ່ວນສຸດທ້າຍແມ່ນຖືກເພີ່ມເຂົ້າເພື່ອປ້ອງກັນຊ່ອງຫວ່າງທີ່ມີທ່າແຮງໃນຜົນໄດ້ຮັບ.
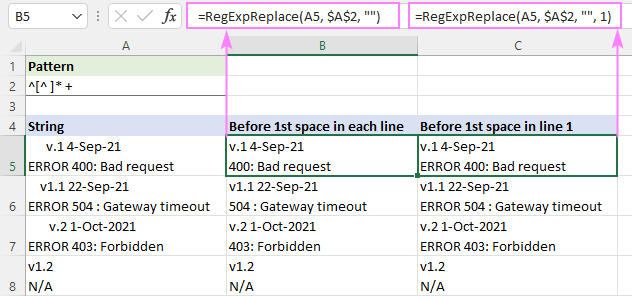
ເພື່ອລຶບຂໍ້ຄວາມອອກກ່ອນຍະຫວ່າງທໍາອິດໃນແຕ່ລະແຖວ, ສູດຄຳນວນຈະຖືກຂຽນໄວ້ໃນໂໝດ "ການຈັບຄູ່ທັງໝົດ" ເລີ່ມຕົ້ນ ( instance_num omitted):
=RegExpReplace(A5, "^[^ ]* +", "")
ເພື່ອລຶບຂໍ້ຄວາມກ່ອນຊ່ອງຫວ່າງໃນແຖວທຳອິດ, ແລະປ່ອຍໃຫ້ແຖວອື່ນທັງໝົດຢູ່ຄົງທີ່, argument instance_num ຖືກຕັ້ງເປັນ 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex ເພື່ອຖອດທຸກຢ່າງອອກກ່ອນຕົວອັກສອນ
ວິທີທີ່ງ່າຍທີ່ສຸດທີ່ຈະລຶບຂໍ້ຄວາມທັງໝົດອອກກ່ອນຕົວອັກສອນສະເພາະແມ່ນໂດຍໃຊ້ regex ເຊັ່ນນີ້:
ຮູບແບບທົ່ວໄປ : ^[^char]*char
ແປເປັນພາສາມະນຸດ, ມັນບອກວ່າ: "ຕັ້ງແຕ່ເລີ່ມຕົ້ນຂອງສາຍທີ່ຍຶດໄວ້ໂດຍ ^. , ຈັບຄູ່ 0 ຕົວອັກສອນ ຫຼືຫຼາຍກວ່ານັ້ນຍົກເວັ້ນ char [^char]* ຈົນເຖິງການປະກົດຕົວທຳອິດຂອງ char .
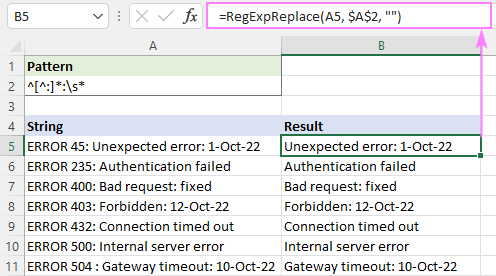
ຕົວຢ່າງ, ເພື່ອລຶບຂໍ້ຄວາມທັງໝົດກ່ອນຈໍ້າສອງເມັດທຳອິດ. , ໃຊ້ການສະແດງຜົນປົກກະຕິນີ້:
ຮູບແບບ : ^[^:]*:
ເພື່ອຫຼີກເວັ້ນຊ່ອງຫວ່າງໃນຜົນການຄົ້ນຫາ, ໃຫ້ເພີ່ມຕົວອັກສອນ \s* ໃສ່ໃນ ສຸດທ້າຍ, ນີ້ຈະເອົາທຸກສິ່ງທຸກຢ່າງ g ຕໍ່ໜ້າຈໍ້າສອງເມັດ ແລະ ຕັດຊ່ອງຫວ່າງໃດໆທັນທີຫຼັງຈາກມັນ:
ຮູບແບບ : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
ເຄັດລັບ. ນອກເຫນືອຈາກການສະແດງອອກປົກກະຕິ, Excel ມີວິທີການຂອງຕົນເອງທີ່ຈະເອົາຂໍ້ຄວາມອອກໂດຍຕໍາແຫນ່ງຫຼືກົງກັນ. ເພື່ອຮຽນຮູ້ວິທີການເຮັດສໍາເລັດວຽກງານດ້ວຍສູດພື້ນເມືອງ,ກະລຸນາເບິ່ງວິທີລຶບຂໍ້ຄວາມກ່ອນ ຫຼືຫຼັງຕົວອັກສອນໃນ Excel.
Regex ເພື່ອລຶບທຸກຢ່າງຍົກເວັ້ນ
ເພື່ອລຶບຕົວອັກສອນທັງໝົດອອກຈາກສະຕຣິງໃດໜຶ່ງ ຍົກເວັ້ນໂຕທີ່ເຈົ້າຕ້ອງການຮັກສາໄວ້, ໃຫ້ໃຊ້ຫ້ອງຮຽນຕົວອັກສອນທີ່ຖືກລົບອອກ.
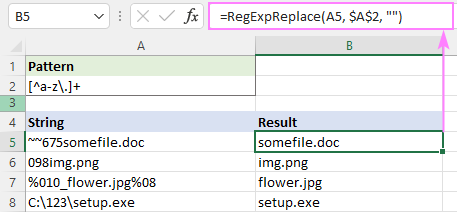
ຕົວຢ່າງ, ເພື່ອລຶບຕົວອັກສອນທັງໝົດຍົກເວັ້ນຕົວອັກສອນຕົວນ້ອຍ. ແລະຈຸດ, regex ແມ່ນ:
Pattern : [^a-z\.]+
ໃນຄວາມເປັນຈິງ, ພວກເຮົາສາມາດເຮັດໄດ້ໂດຍບໍ່ມີ + quantifier ຢູ່ທີ່ນີ້ຍ້ອນວ່າຫນ້າທີ່ຂອງພວກເຮົາປ່ຽນແທນທັງຫມົດ. ພົບການແຂ່ງຂັນ. quantifier ພຽງແຕ່ເຮັດໃຫ້ມັນໄວຂຶ້ນເລັກນ້ອຍ - ແທນທີ່ຈະຈັດການແຕ່ລະຕົວລະຄອນ, ທ່ານປ່ຽນແທນ substring.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex ເພື່ອເອົາແທັກ html ໃນ Excel
ກ່ອນອື່ນໝົດ, ຄວນສັງເກດວ່າ HTML ບໍ່ແມ່ນພາສາປົກກະຕິ, ສະນັ້ນການແຍກມັນໂດຍໃຊ້ສຳນວນປົກກະຕິບໍ່ແມ່ນວິທີທີ່ດີທີ່ສຸດ. ທີ່ເວົ້າວ່າ, regexes ສາມາດຊ່ວຍລຶບແທໍກອອກຈາກເຊລຂອງທ່ານຢ່າງແນ່ນອນເພື່ອເຮັດໃຫ້ຊຸດຂໍ້ມູນຂອງທ່ານສະອາດຂຶ້ນ.
ເນື່ອງຈາກວ່າແທັກ html ແມ່ນຖືກຈັດໃສ່ຢູ່ໃນວົງເລັບມຸມສະເໝີ, ທ່ານສາມາດຊອກຫາພວກມັນໄດ້ໂດຍໃຊ້ໜຶ່ງໃນ regexes ຕໍ່ໄປນີ້.
ຊັ້ນ Negated:
Pattern : ]*>
ຢູ່ນີ້, ພວກເຮົາຈັບຄູ່ວົງເລັບມຸມເປີດ, ຕາມດ້ວຍສູນ ຫຼືຫຼາຍກວ່າການປະກົດຕົວຂອງຕົວອັກສອນໃດໆ ຍົກເວັ້ນ ວົງເລັບມຸມປິດ [^>]* ເຖິງວົງເລັບມຸມປິດທີ່ໃກ້ທີ່ສຸດ.
Lazy search:
ຮູບແບບ :
ນີ້, ພວກເຮົາກົງກັນ. ສິ່ງໃດແດ່ຈາກວົງເລັບເປີດທໍາອິດໄປຫາວົງເລັບປິດທໍາອິດ. ເຄື່ອງໝາຍຄຳຖາມບັງຄັບ .* ໃຫ້ກົງກັບຕົວອັກສອນໜ້ອຍທີ່ສຸດເທົ່າແຖວ.
ເພື່ອປະມວນຜົນທຸກແຖວເປັນສາຍດຽວ:
ຮູບແບບທົ່ວໄປ : char.
