
Kazalo
Ste kdaj pomislili, kako zmogljiv bi bil Excel, če bi nekdo obogatil njegov nabor orodij z regularnimi izrazi? Nismo samo razmišljali, ampak smo tudi delali na tem :) In zdaj lahko to čudovito funkcijo RegEx dodate v svoje delovne zvezke in v trenutku izbrišete podrejene nize, ki ustrezajo vzorcu!
Prejšnji teden smo si ogledali, kako uporabiti regularne izraze za zamenjavo nizov v Excelu. V ta namen smo ustvarili lastno funkcijo Regex Replace. Izkazalo se je, da funkcija presega svojo osnovno uporabo in ne more samo zamenjati nizov, temveč jih lahko tudi odstrani. Kako je to mogoče? V Excelu odstranitev vrednosti ni nič drugega kot zamenjava s praznim nizom, kar je naša funkcija Regexzelo dobro!
Funkcija VBA RegExp za odstranjevanje podrejenih nizov v programu Excel
Kot vsi vemo, regularni izrazi v Excelu privzeto niso podprti. Če jih želite omogočiti, morate ustvariti lastno uporabniško definirano funkcijo. Dobra novica je, da je taka funkcija že napisana, preizkušena in pripravljena za uporabo. Vse, kar morate storiti, je, da kopirate to kodo, jo vstavite v urejevalnik VBA in nato shranite datoteko kot Delovni zvezek z omogočenimi makri (.xlsm).
Funkcija ima naslednjo sintakso:
RegExpReplace(besedilo, vzorec, zamenjava, [številka primera], [primerjava_primera])Prvi trije argumenti so obvezni, zadnja dva sta neobvezna.
Kje:
- Besedilo - besedilni niz za iskanje.
- Vzorec - regularni izraz za iskanje.
- Zamenjava - besedilo, ki ga želite nadomestiti. Na odstranjevanje podrejenih nizov ki ustreza vzorcu, uporabite prazen niz ("") za zamenjavo.
- Instance_num (neobvezno) - primerek, ki se nadomesti. Če je izpuščen, se nadomestijo vsi najdeni primerki (privzeto).
- Match_case (neobvezno) - logična vrednost, ki označuje, ali naj se ujemajo ali zanemarjajo velike in male črke besedila. Za ujemanje, občutljivo na velike in male črke, uporabite TRUE (privzeto); za ujemanje, neobčutljivo na velike in male črke - FALSE.
Za več informacij glejte funkcijo RegExpReplace.
Nasvet. V preprostih primerih lahko iz celic odstranite določene znake ali besede z Excelovimi formulami. Vendar imajo regularni izrazi za to veliko več možnosti.
Kako odstraniti nize z uporabo regularnih izrazov - primeri
Kot smo že omenili, če želite odstraniti dele besedila, ki ustrezajo vzorcu, jih nadomestite s praznim nizom. Splošna formula ima torej to obliko:
RegExpReplace(besedilo, vzorec, "", [številka primera], [match_case])Spodnji primeri prikazujejo različne izvedbe tega osnovnega koncepta.
Odstranite vsa ujemanja ali določeno ujemanje
Funkcija RegExpReplace je zasnovana tako, da poišče vse podrejene nize, ki ustrezajo danemu regex-u. Katera pojavljanja je treba odstraniti, je odvisno od četrtega neobveznega argumenta, imenovanega instance_num .
Privzeta vrednost je "vsa ujemanja" - ko instance_num argument je izpuščen, se odstranijo vsa najdena ujemanja. Če želite odstraniti določeno ujemanje, določite številko primera.
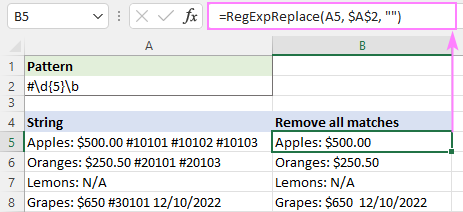
Predpostavimo, da želite v spodnjih nizih izbrisati številko prvega reda. Vse take številke se začnejo z znakom hash (#) in vsebujejo natanko 5 številk. Zato jih lahko prepoznamo s tem regexom:
Vzorec : #\d{5}\b
Besedna meja \b določa, da ujemajoči se podrejeni niz ne more biti del večjega niza, na primer #10000001.
Če želite odstraniti vsa ujemanja, lahko instance_num argument ni opredeljen:
=RegExpReplace(A5, "#\d{5}\b", "")
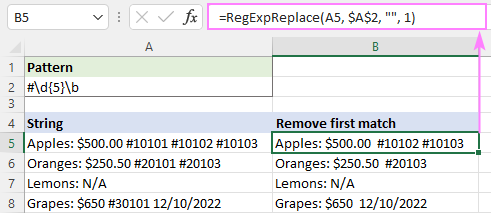
Da bi izkoreninili samo prvo pojavitev, nastavimo instance_num na 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex za odstranitev določenih znakov
Če želite iz niza odstraniti določene znake, zapišite vse neželene znake in jih ločite z navpično črto.
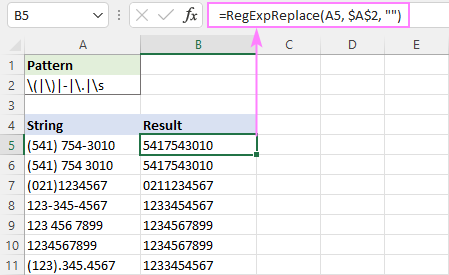
Če želimo na primer standardizirati telefonske številke, zapisane v različnih oblikah, se najprej znebimo določenih znakov, kot so oklepaji, pomišljaji, pike in beli presledki.
Vzorec : \(
=RegExpReplace(A5, "\(
Rezultat te operacije je desetmestno število, na primer "1234567890".
Zaradi priročnosti lahko vnesete regex v ločeno celico in se nanjo sklicujete z absolutno referenco, na primer $A$2:
=RegExpReplace(A5, $A$2, "")
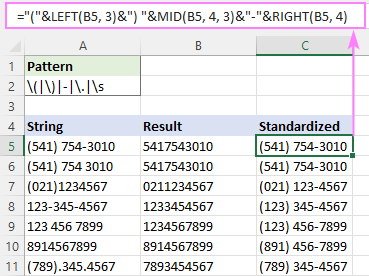
Oblikovanje lahko po želji standardizirate z uporabo operatorja združevanja (&) in besedilnih funkcij, kot so RIGHT, MID in LEFT.
Če želite na primer vse telefonske številke zapisati v obliki (123) 456-7890, je formula naslednja:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Pri čemer je B5 rezultat funkcije RegExpReplace.
Odstranjevanje posebnih znakov z uporabo regexa
V enem od naših vodičev smo si ogledali, kako odstraniti neželene znake v Excelu z uporabo vgrajenih funkcij in funkcij po meri. Z regularnimi izrazi je vse veliko lažje! Namesto da bi naštevali vse znake za odstranitev, samo določite tiste, ki jih želite ohraniti :)
Vzorec temelji na razredi z zanikanimi znaki - caret se vstavi v razred znakov [^ ], da se ujema s katerim koli posameznim znakom, ki NI v oklepajih. Kvantifikator + prisili, da se zaporedni znaki obravnavajo kot eno ujemanje, tako da se zamenjava izvede za ujemajoči se podreženj in ne za vsak posamezni znak.
Glede na svoje potrebe izberite enega od naslednjih regeksov.
Odstranitev nealfanumerični znaki, tj. vsi znaki razen črk in številk:
Vzorec : [^0-9a-zA-Z]+
Čiščenje vseh znakov razen črk , številke in . prostori :
Vzorec : [^0-9a-zA-Z ]+
Brisanje vseh znakov razen črk , številke in . podčrtanka , lahko uporabite \W, ki pomeni kateri koli znak, ki NI alfanumerični znak ali podčrtanka:
Vzorec : \W+
Če želite ohranite nekatere druge like. npr. ločila, jih vstavite v oklepaj.
Če želite na primer odstraniti vse znake, ki niso črke, številke, pike, vejice ali presledka, uporabite naslednji regex:
Vzorec : [^0-9a-zA-Z\., ]+
S tem uspešno odstranite vse posebne znake, vendar ostane dodaten beli prostor.
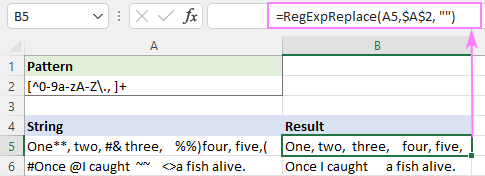
To lahko popravite tako, da zgornjo funkcijo vgradite v drugo funkcijo, ki več presledkov nadomesti z enim samim presledkom.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
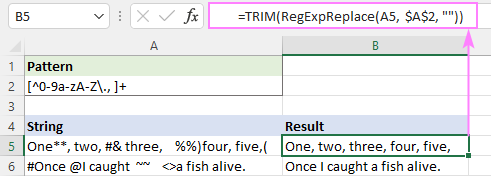
Lahko pa uporabite tudi izvirno funkcijo TRIM z enakim učinkom:
=TRIM(RegExpReplace(A5, $A$2, ""))
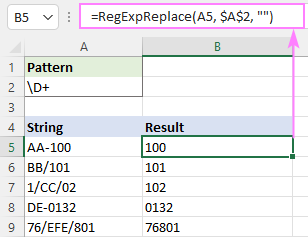
Regex za odstranjevanje nenumeričnih znakov
Če želite iz niza izbrisati vse neštevilske znake, lahko uporabite to dolgo formulo ali enega od preprostih regeksov, navedenih spodaj.
Ujemanje katerega koli znaka, ki NI števka:
Vzorec : \D+
Neštevilske znake odstranite z uporabo zanikanih razredov:
Vzorec : [^0-9]+
Vzorec : [^\d]+
Nasvet. Če želite odstraniti besedilo in preostale številke preliti v ločene celice ali jih vse postaviti v eno celico, ločeno z določenim ločilom, uporabite funkcijo RegExpExtract, kot je razloženo v poglavju Kako izpisati številke iz niza z uporabo regularnih izrazov.
Regex za odstranitev vsega za presledkom
Če želite izbrisati vse za presledkom, uporabite znak presledka ( ) ali beline (\s) za iskanje prvega presledka in znak .* za ujemanje vseh znakov za njim.
Če imate enovrstične nize, ki vsebujejo le običajne presledke (vrednost 32 v 7-bitnem sistemu ASCII), ni pomembno, katerega od spodnjih regeksov boste uporabili. Pri večvrstičnih nizih pa je to pomembno.
Odstranjevanje vsega za znakom presledka , uporabite ta regex:
Vzorec : " .*"
=RegExpReplace(A5, " .*", "")
Ta formula bo odstranila vse, kar je za prvim presledkom v vsaka vrstica . Če želite, da se rezultati pravilno prikažejo, vklopite možnost Wrap Text.
Odstranjevanje vsega po belem presledku (vključno s presledkom, tabulatorjem, povratno vrvico in novo vrstico), je regex:
Vzorec : \s.*
=RegExpReplace(A5, "\s.*", "")
Ker \s ustreza nekaj različnim vrstam belih znakov, vključno z nova vrstica (\n), ta formula izbriše vse, kar sledi prvemu presledku v celici, ne glede na to, koliko vrstic je v njej.
Regex za odstranitev besedila po določenem znaku
Z metodami iz prejšnjega primera lahko izbrišete besedilo za katerim koli znakom, ki ga določite.
Če želite obdelati vsako vrstico posebej:
Splošni vzorec : char.*
V enovrstičnih nizih bo to odstranilo vse, kar sledi char . V večvrstičnih nizih bo obdelana vsaka vrstica posebej, saj se v okusu VBA Regex pika (.) ujema s katerim koli znakom, razen z novo vrstico.
Obdelava vseh vrstic kot enega samega niza:
Splošni vzorec : char(.
Če želite izbrisati vse, kar sledi določenemu znaku, vključno z novimi vrsticami, vzorcu dodajte \n.
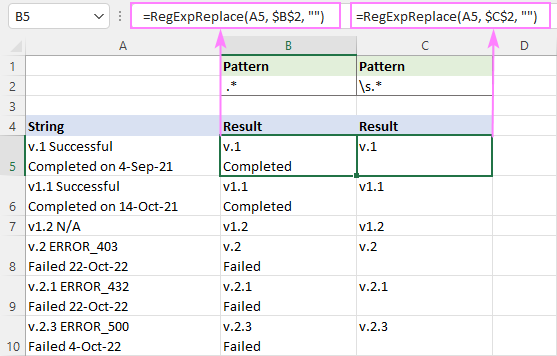
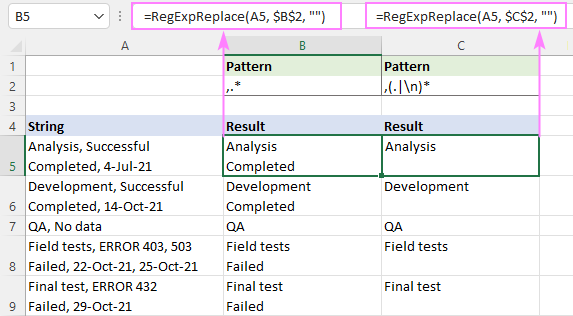
Če želite na primer odstraniti besedilo za prvo vejico v nizu, poskusite s temi regularnimi izrazi:
Vzorec : ,.*
Vzorec : ,(.
Na spodnji sliki zaslona si lahko ogledate, kako se rezultati razlikujejo.
Regex za odstranitev vsega pred presledkom
Pri delu z dolgimi nizi besedila jih včasih želite skrajšati tako, da v vseh celicah odstranite isti del informacije. V nadaljevanju bomo obravnavali dva taka primera.
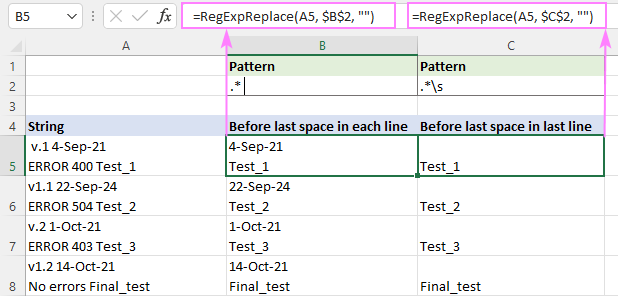
Odstranite vse pred zadnjim presledkom
Tako kot v prejšnjem primeru je tudi tu regularni izraz odvisen od vašega razumevanja pojma "presledek".
Če želite uskladiti karkoli z zadnji prostor , bo uporabljen ta regex (narekovaji so dodani, da je presledek za zvezdico opazen).
Vzorec : ".* "
Če želite ujemati vse pred zadnji beli prostor (vključno s presledkom, tabulatorjem, povratno vrvico in novo vrstico), uporabite ta regularni izraz.
Vzorec : .*\s
Razlika je še posebej opazna pri večvrstičnih nizih.
Odstranite vse pred prvim presledkom
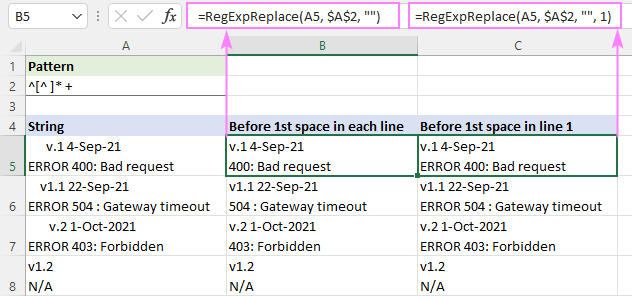
Za ujemanje vsega do prvega presledka v nizu lahko uporabite ta regularni izraz:
Vzorec : ^[^ ]* +
Od začetka niza ^ ujemamo nič ali več znakov brez presledka [^ ]*, ki jim takoj sledi en ali več presledkov " +". Zadnji del je dodan, da se preprečijo morebitni začetni presledki v rezultatih.
Če želite odstraniti besedilo pred prvim presledkom v vsaki vrstici, se formula zapiše v privzetem načinu "vsa ujemanja" ( instance_num izpuščeno):
=RegExpReplace(A5, "^[^ ]* +", "")
Če želite izbrisati besedilo pred prvim presledkom v prvi vrstici in pustiti vse druge vrstice nedotaknjene, uporabite instance_num je nastavljen na 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex za odstranitev vsega pred znakom
Najlažje odstranite vse besedilo pred določenim znakom z uporabo regexa, kot je ta:
Splošni vzorec : ^[^char]*char
Prevedeno v človeški jezik pravi: "z začetka niza, zasidranega z ^, ujemanje 0 ali več znakov, razen char [^char]* do prve pojavitve char .
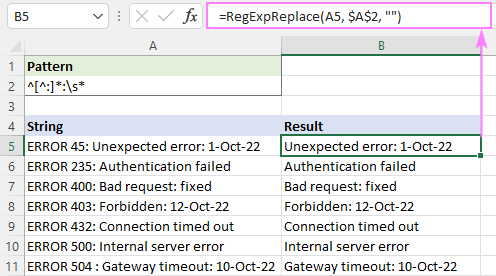
Če želite na primer izbrisati vse besedilo pred prvim dvopičjem, uporabite ta regularni izraz:
Vzorec : ^[^:]*:
Če se želite izogniti vodilnim presledkom v rezultatih, dodajte na konec znak za beli prostor \s*. To bo odstranilo vse pred prvim dvopičjem in odrezalo vse presledke takoj za njim:
Vzorec : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Nasvet. Poleg regularnih izrazov ima Excel tudi lastna sredstva za odstranjevanje besedila po položaju ali ujemanju. Če želite izvedeti, kako to nalogo opraviti z lastnimi formulami, glejte Kako odstraniti besedilo pred ali za znakom v Excelu.
Regex za odstranitev vsega razen
Če želite iz niza izbrisati vse znake, razen tistih, ki jih želite ohraniti, uporabite razrede zanikanih znakov.
Na primer, če želite odstraniti vse znake razen malih črk in pik, je regex naslednji:
Vzorec : [^a-z\.]+
Pravzaprav bi lahko tukaj shajali brez kvantifikatorja +, saj naša funkcija nadomesti vsa najdena ujemanja. Zaradi kvantifikatorja je postopek le nekoliko hitrejši - namesto vsakega posameznega znaka zamenjamo podreženj.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex za odstranjevanje oznak html v Excelu
Najprej je treba opozoriti, da HTML ni regularni jezik, zato njegovo razčlenjevanje z uporabo regularnih izrazov ni najboljši način. Kljub temu lahko regeksi vsekakor pomagajo odstraniti oznake iz celic, da je nabor podatkov čistejši.
Glede na to, da so oznake html vedno nameščene v oglatih oklepajih , jih lahko poiščete z enim od naslednjih regeksov.
Negirani razred:
Vzorec : ]*>
Tu se ujemamo z začetnim oglatim oklepajem, ki mu sledi nič ali več pojavitev kateregakoli znaka razen zaključnega oglatega oklepaja [^>]* do najbližjega zaključnega oglatega oklepaja.
Leno iskanje:
Vzorec :
V tem primeru se ujemamo z vsemi znaki od prvega začetnega do prvega zaključnega oklepaja. Vprašalni znak prisili .*, da se ujema s čim manj znaki, dokler ne najde zaključnega oklepaja.
Ne glede na to, kateri vzorec izberete, bo rezultat popolnoma enak.
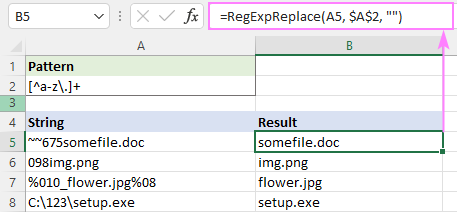
Če želite na primer iz niza v A5 odstraniti vse oznake html in pustiti besedilo, je formula naslednja:
=RegExpReplace(A5, "]*>", "")
Uporabite lahko tudi leni kvantifikator, kot je prikazano na sliki zaslona:
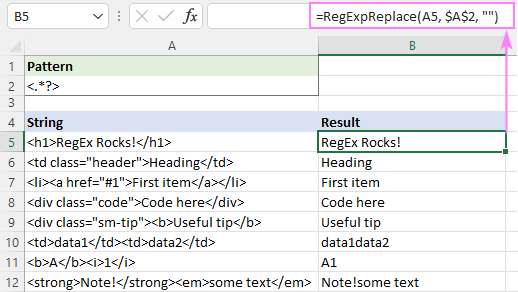
Ta rešitev odlično deluje za eno besedilo (vrstice 5-9). Pri več besedilih (vrstice 10-12) so rezultati vprašljivi - besedila iz različnih oznak so združena v eno. Je to pravilno ali ne? Bojim se, da se o tem ni mogoče preprosto odločiti - vse je odvisno od vašega razumevanja želenega rezultata. Na primer, v B11 se pričakuje rezultat "A1", medtem ko bi v B10 morda želeli"data1" in "data2" morata biti ločena s presledkom.
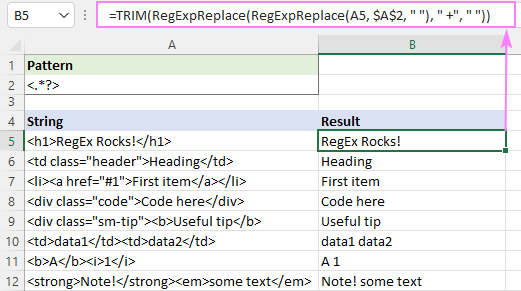
Če želite odstraniti oznake html in preostala besedila ločiti s presledki, lahko nadaljujete na ta način:
- Zamenjajte oznake s presledki " " in ne s praznimi nizi:
=RegExpReplace(A5, "]*>", " ") - Več presledkov zmanjšajte na en sam presledek:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Obrežite začetne in končne presledke:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))Poglej tudi: Vstavljanje vodnega znaka v dokumente Excel
Rezultat bo videti približno takole:
Ablebits Regex odstrani orodje
Če ste imeli priložnost uporabljati naš paket Ultimate Suite za Excel, ste verjetno že odkrili nova orodja Regex, ki so bila predstavljena z nedavno izdajo. Lepota teh funkcij Regex, ki temeljijo na .NET, je v tem, da, prvič, podpirajo polno funkcionalno sintakso regularnih izrazov brez omejitev VBA RegExp in, drugič, ne zahtevajo vstavljanja kode VBA v vaše delovne zvezke, saj je vsa integracija kode opravljenaki jih izvajamo v ozadju.
Vaša naloga je, da sestavite regularni izraz in ga posredujete funkciji :) Naj vam to pokažem na praktičnem primeru.
Kako odstraniti besedilo v oklepajih in oklepajih z uporabo regexa
V dolgih besedilnih nizih so manj pomembne informacije pogosto zaprte v [oklepajih] in (oklepajih). Kako odstraniti te nepomembne podrobnosti in pri tem ohraniti vse druge podatke?
Pravzaprav smo že sestavili podoben regex za brisanje oznak html, tj. besedila v oglatih oklepajih. Seveda bodo enake metode delovale tudi za oglate in oglate oklepaje.
Vzorec : (\(.*?\))
Trik je v uporabi lenega kvantifikatorja (*?), ki ustreza najkrajšemu možnemu podredu. Prva skupina (\(.*?\)) ustreza vsemu od začetnega oklepaja do prvega zaključnega oklepaja. Druga skupina (\[.*?\]) ustreza vsemu od začetnega oklepaja do prvega zaključnega oklepaja. Navpična črta
Ko je vzorec določen, ga prenesemo v funkcijo Regex Remove:
- Na Podatkovni zapisi o napravah Ablebits v zavihku Besedilo skupino, kliknite Orodja Regex .
Če želite rezultate dobiti kot formule in ne kot vrednosti, izberite Vstavite kot formulo potrditveno polje.
Če želimo iz nizov v A2:A5 odstraniti besedilo v oklepajih, nastavitve konfiguriramo na naslednji način:
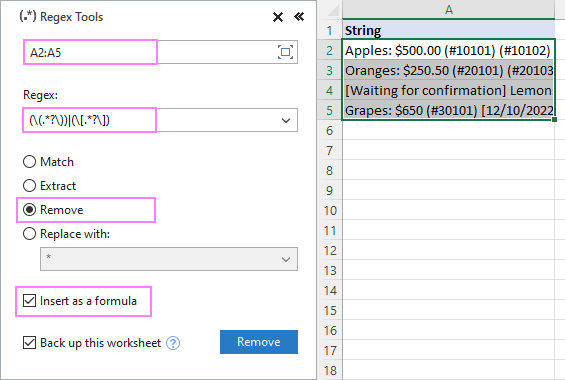
Zaradi tega je AblebitsRegexRemove vstavi v nov stolpec poleg prvotnih podatkov.
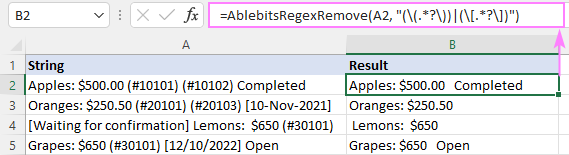
Funkcijo lahko vnesete tudi neposredno v celico s standardnim Funkcija vstavljanja v pogovornem oknu, kjer je razvrščena v kategorijo AblebitsUDFs .
Kot AblebitsRegexRemove je namenjena odstranjevanju besedila in zahteva le dva argumenta - izvorni niz in regex. Oba parametra lahko določite neposredno v formuli ali ju posredujete v obliki referenc na celice. Po potrebi lahko to funkcijo po meri uporabite skupaj s katero koli izvorno funkcijo.
Če želite na primer obrezati dodatne presledke v dobljenih nizih, lahko kot ovoj uporabite funkcijo TRIM:
=TRIM(AblebitsRegexRemove(A5, $A$2))
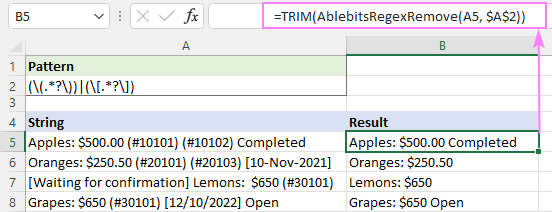
To je način odstranjevanja nizov v Excelu z uporabo regularnih izrazov. Zahvaljujem se vam za branje in se veselim, da se naslednji teden vidimo na našem blogu!
Razpoložljivi prenosi
Odstranjevanje nizov z uporabo regexa - primeri (.xlsm datoteka)
Ultimate Suite - preizkusna različica (.exe datoteka)
