
Obsah
Napadlo vás niekedy, aký by bol Excel mocný, keby niekto obohatil jeho sadu nástrojov o regulárne výrazy? Nielenže sme sa nad tým zamýšľali, ale aj sme na tom pracovali :) A teraz môžete túto úžasnú funkciu RegEx pridať do svojich vlastných zošitov a v okamihu vymazať podreťazce zodpovedajúce vzoru!
Minulý týždeň sme sa pozreli na to, ako používať regulárne výrazy na nahrádzanie reťazcov v programe Excel. Na tento účel sme vytvorili vlastnú funkciu Regex Replace. Ako sa ukázalo, funkcia presahuje svoje primárne použitie a dokáže reťazce nielen nahrádzať, ale aj odstraňovať. Ako je to možné? Z hľadiska programu Excel nie je odstránenie hodnoty nič iné ako jej nahradenie prázdnym reťazcom, čo naša funkcia Regexveľmi dobré!
Funkcia VBA RegExp na odstránenie podreťazcov v programe Excel
Ako všetci vieme, regulárne výrazy nie sú v programe Excel štandardne podporované. Ak ich chcete aktivovať, musíte si vytvoriť vlastnú používateľskú funkciu. Dobrou správou je, že takáto funkcia je už napísaná, otestovaná a pripravená na použitie. Stačí, ak si tento kód skopírujete, vložíte ho do editora VBA a potom súbor uložíte ako zošit s povolenými makrami (.xlsm).
Funkcia má nasledujúcu syntax:
RegExpReplace(text, vzor, náhrada, [číslo_inštancie], [prípad_zhody])Prvé tri argumenty sú povinné, posledné dva sú nepovinné.
Kde:
- Text - textový reťazec, v ktorom sa má vyhľadávať.
- Vzor - regulárny výraz, ktorý sa má vyhľadať.
- Náhrada - text, ktorý sa má nahradiť. Na odstrániť podreťazce zodpovedajúce vzoru, použite prázdny reťazec ("") na výmenu.
- Instance_num (nepovinné) - inštancia, ktorá sa má nahradiť. Ak sa vynechá, nahradia sa všetky nájdené zhody (predvolené).
- Match_case (nepovinné) - logická hodnota, ktorá určuje, či sa má porovnať alebo ignorovať veľkosť písmen v texte. Pre porovnávanie citlivé na veľkosť písmen použite TRUE (predvolené); pre porovnávanie bez citlivosti na veľkosť písmen - FALSE.
Viac informácií nájdete v časti Funkcia RegExpReplace.
Tip. V jednoduchých prípadoch môžete z buniek odstrániť konkrétne znaky alebo slová pomocou vzorcov programu Excel. Regulárne výrazy však poskytujú oveľa viac možností.
Ako odstrániť reťazce pomocou regulárnych výrazov - príklady
Ako už bolo spomenuté, ak chcete odstrániť časti textu zodpovedajúce vzoru, máte ich nahradiť prázdnym reťazcom. Všeobecný vzorec má teda tento tvar:
RegExpReplace(text, pattern, "", [instance_num], [match_case])Nižšie uvedené príklady ukazujú rôzne implementácie tohto základného konceptu.
Odstrániť všetky zhody alebo konkrétnu zhodu
Funkcia RegExpReplace je navrhnutá tak, aby našla všetky podreťazce zodpovedajúce zadanému regexu. Ktoré výskyty sa majú odstrániť, sa riadi štvrtým nepovinným argumentom s názvom instance_num .
Predvolené nastavenie je "všetky zhody" - keď instance_num argument je vynechaný, odstránia sa všetky nájdené zhody. Ak chcete odstrániť konkrétnu zhodu, definujte číslo inštancie.
Predpokladajme, že v nižšie uvedených reťazcoch chcete odstrániť číslo prvého poradia. Všetky takéto čísla začínajú znakom hash (#) a obsahujú presne 5 číslic. Môžeme ich teda identifikovať pomocou tohto regexu:
Vzor : #\d{5}\b
Hranica slov \b určuje, že zodpovedajúci podreťazec nemôže byť súčasťou väčšieho reťazca, napríklad #10000001.
Ak chcete odstrániť všetky zhody. instance_num argument nie je definovaný:
=RegExpReplace(A5, "#\d{5}\b", "")
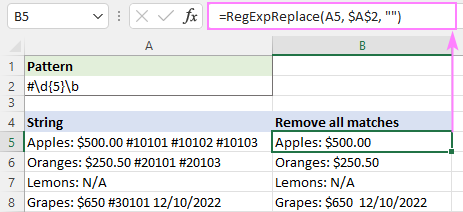
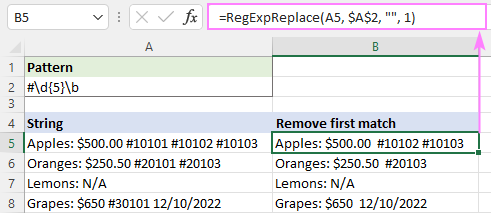
Ak chceme odstrániť len prvý výskyt, nastavíme instance_num na 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex na odstránenie určitých znakov
Ak chcete z reťazca odstrániť určité znaky, napíšte všetky nechcené znaky a oddeľte ich zvislou čiarou.
Ak chceme napríklad štandardizovať telefónne čísla zapísané v rôznych formátoch, najprv sa zbavíme špecifických znakov, ako sú zátvorky, pomlčky, bodky a biele miesta.
Vzor : \(
=RegExpReplace(A5, "\(
Výsledkom tejto operácie je 10-miestne číslo, napríklad "1234567890".
Pre väčšie pohodlie môžete regex zadať do samostatnej bunky a odkazovať na ňu pomocou absolútneho odkazu, napríklad $A$2:
=RegExpReplace(A5, $A$2, "")
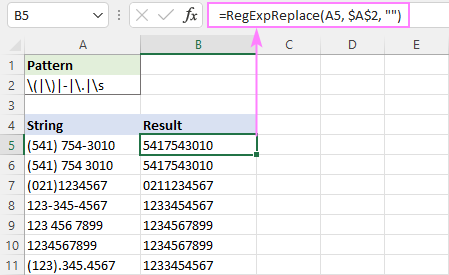
A potom môžete formátovanie štandardizovať podľa svojich potrieb pomocou operátora zlučovania (&) a textových funkcií, ako sú RIGHT, MID a LEFT.
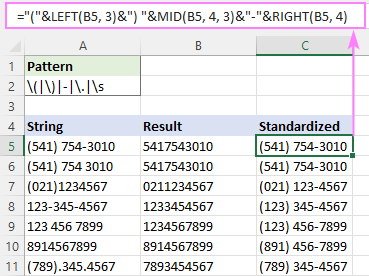
Ak chcete napríklad zapísať všetky telefónne čísla vo formáte (123) 456-7890, vzorec je:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Kde B5 je výstup funkcie RegExpReplace.
Odstránenie špeciálnych znakov pomocou regexu
V jednom z našich návodov sme sa pozreli na to, ako odstrániť nežiaduce znaky v programe Excel pomocou vstavaných a vlastných funkcií. Regulárne výrazy vám to výrazne uľahčia! Namiesto vymenovania všetkých znakov na odstránenie stačí zadať tie, ktoré chcete zachovať :)
Vzor je založený na negované triedy znakov - caret sa vloží dovnútra triedy znakov [^ ], aby zodpovedal akémukoľvek jednotlivému znaku, ktorý NIE JE v zátvorkách. Kvantifikátor + ho núti považovať za jednu zhodu po sebe idúce znaky, takže sa nahradí zodpovedajúci podreťazec, a nie každý jednotlivý znak.
V závislosti od vašich potrieb vyberte jeden z nasledujúcich regexov.
Odstránenie nealfanumerické znaky, t. j. všetky znaky okrem písmen a číslic:
Vzor : [^0-9a-zA-Z]+
Vyčistenie všetkých znakov okrem písmen , číslice a priestory :
Vzor : [^0-9a-zA-Z ]+
Odstránenie všetkých znakov okrem písmen , číslice a podčiarkovník , môžete použiť \W, ktoré znamená akýkoľvek znak, ktorý NIE JE alfanumerický znak alebo podčiarkovník:
Vzor : \W+
Ak chcete ponechať si niektoré ďalšie postavy , napr. interpunkčné znamienka, vložte ich do zátvoriek.
Ak chcete napríklad odstrániť akýkoľvek iný znak ako písmeno, číslicu, bodku, čiarku alebo medzeru, použite nasledujúci regex:
Vzor : [^0-9a-zA-Z\., ]+
Týmto spôsobom sa úspešne odstránia všetky špeciálne znaky, ale biele znaky navyše zostanú.
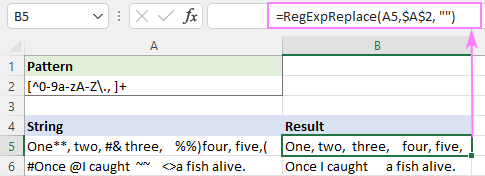
Ak to chcete napraviť, môžete vyššie uvedenú funkciu vložiť do inej funkcie, ktorá nahradí viacero medzier jedným znakom medzery.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
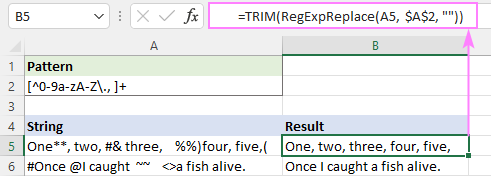
Alebo jednoducho použite natívnu funkciu TRIM s rovnakým účinkom:
=TRIM(RegExpReplace(A5, $A$2, ""))
Regex na odstránenie nečíselných znakov
Ak chcete z reťazca odstrániť všetky nečíselné znaky, môžete použiť buď tento dlhý vzorec, alebo jeden z veľmi jednoduchých regexov uvedených nižšie.
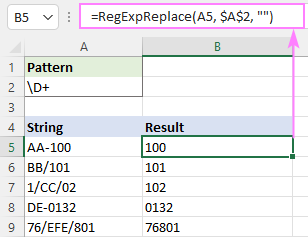
Zodpovedá akémukoľvek znaku, ktorý NIE JE číslica:
Vzor : \D+
Odstránenie nečíselných znakov pomocou negovaných tried:
Vzor : [^0-9]+
Vzor : [^\d]+
Tip. Ak je vaším cieľom odstrániť text a zvyšné čísla rozsypať do samostatných buniek alebo ich všetky umiestniť do jednej bunky oddelenej určeným oddeľovačom, potom použite funkciu RegExpExtract, ako je vysvetlené v časti Ako extrahovať čísla z reťazca pomocou regulárnych výrazov.
Regex na odstránenie všetkého za medzerou
Ak chcete vymazať všetko, čo nasleduje za medzerou, použite na vyhľadanie prvej medzery znak medzery ( ) alebo bielych znakov (\s) a na porovnanie všetkých znakov za medzerou znak .*.
Ak máte jednoriadkové reťazce, ktoré obsahujú iba normálne medzery (hodnota 32 v 7-bitovom systéme ASCII), nezáleží na tom, ktorý z nižšie uvedených regexov použijete. V prípade viacriadkových reťazcov je to rozdiel.
Odstránenie všetkého za znakom medzery , použite tento regex:
Vzor : " .*"
=RegExpReplace(A5, " .*", "")
Tento vzorec odstráni všetko, čo sa nachádza za prvou medzerou v každý riadok . Aby sa výsledky zobrazovali správne, nezabudnite zapnúť funkciu Wrap Text.
Zbaviť sa všetkého za bielym bodom (vrátane medzery, tabulátora, návratu vozíka a nového riadku), regex je:
Vzor : \s.*
=RegExpReplace(A5, "\s.*", "")
Pretože \s zodpovedá niekoľkým rôznym typom bielych znakov vrátane nový riadok (\n), tento vzorec vymaže všetko, čo sa nachádza za prvou medzerou v bunke, bez ohľadu na to, koľko riadkov sa v nej nachádza.
Regex na odstránenie textu po určitom znaku
Pomocou metód z predchádzajúceho príkladu môžete vymazať text po ľubovoľnom zadanom znaku.
Ak chcete spracovať každý riadok samostatne:
Všeobecný vzor : char.*
V jednoriadkových reťazcoch sa odstráni všetko, čo nasleduje za znak Vo viacriadkových reťazcoch sa každý riadok spracuje samostatne, pretože v príchuti VBA Regex sa bodka (.) zhoduje s akýmkoľvek znakom okrem nového riadku.
Spracovanie všetkých riadkov ako jedného reťazca:
Všeobecný vzor : char(.
Ak chcete odstrániť čokoľvek za daným znakom vrátane nových riadkov, k vzoru sa pridá \n.
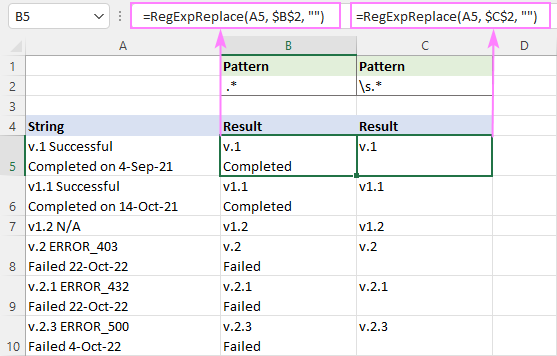
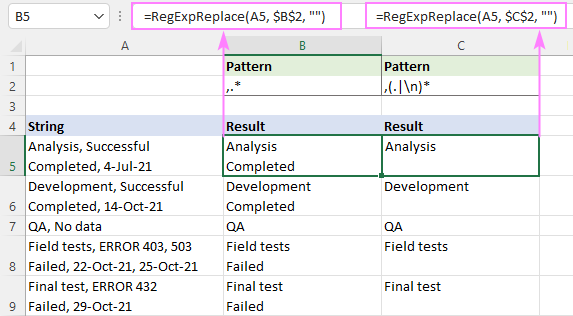
Ak chcete napríklad odstrániť text za prvou čiarkou v reťazci, vyskúšajte tieto regulárne výrazy:
Vzor : ,.*
Vzor : ,(.
Na snímke nižšie si môžete pozrieť, ako sa výsledky líšia.
Regex na odstránenie všetkého pred medzerou
Pri práci s dlhými textovými reťazcami ich niekedy môžete chcieť skrátiť odstránením rovnakej časti informácie vo všetkých bunkách. Nižšie si rozoberieme dva takéto prípady.
Odstráňte všetko pred poslednou medzerou
Podobne ako v predchádzajúcom príklade, regulárny výraz závisí od vášho chápania pojmu "medzera".
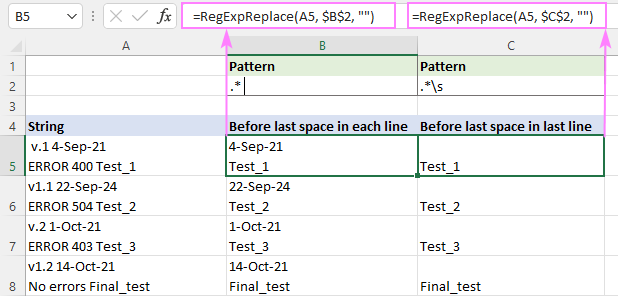
Ak chcete porovnať čokoľvek s posledné miesto (úvodzovky sú pridané, aby bola medzera za hviezdičkou viditeľná).
Vzor : ".* "
Ak chcete priradiť čokoľvek pred posledný biely znak (vrátane medzery, tabulátora, návratu vozíka a nového riadku), použite tento regulárny výraz.
Vzor : .*\s
Rozdiel je viditeľný najmä pri viacriadkových reťazcoch.
Odstráňte všetko pred prvým miestom
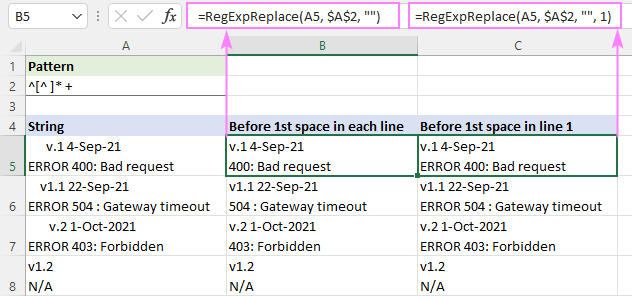
Ak chcete priradiť čokoľvek až po prvú medzeru v reťazci, môžete použiť tento regulárny výraz:
Vzor : ^[^ ]* +
Od začiatku reťazca ^ porovnávame nula alebo viac znakov bez medzier [^ ]*, za ktorými bezprostredne nasleduje jedna alebo viac medzier " +". Posledná časť sa pridáva, aby sa zabránilo prípadným úvodným medzerám vo výsledkoch.
Ak chcete odstrániť text pred prvou medzerou v každom riadku, vzorec sa zapíše v predvolenom režime "všetky zhody" ( instance_num vynechané):
=RegExpReplace(A5, "^[^ ]* +", "")
Ak chcete odstrániť text pred prvou medzerou v prvom riadku a ponechať všetky ostatné riadky nedotknuté, použite instance_num je nastavený na hodnotu 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex na odstránenie všetkého, čo je pred znakom
Najjednoduchší spôsob, ako odstrániť všetok text pred určitým znakom, je použiť regex, ako je tento:
Všeobecný vzor : ^[^char]*char
Preložené do ľudského jazyka to znamená: "od začiatku reťazca zakotveného pomocou ^, porovnajte 0 alebo viac znakov okrem znak [^char]* až po prvý výskyt znak .
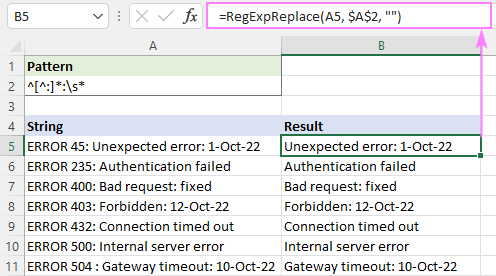
Ak chcete napríklad odstrániť všetok text pred prvou dvojbodkou, použite tento regulárny výraz:
Vzor : ^[^:]*:
Ak sa chcete vyhnúť úvodným medzerám vo výsledkoch, pridajte na koniec biely znak \s*. Tým sa odstráni všetko pred prvou dvojbodkou a orežú sa všetky medzery hneď za ňou:
Vzor : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Tip. Okrem regulárnych výrazov má Excel vlastné prostriedky na odstránenie textu podľa pozície alebo zhody. Ak sa chcete dozvedieť, ako túto úlohu vykonať pomocou vlastných vzorcov, pozrite si článok Ako odstrániť text pred alebo za znakom v programe Excel.
Regex na odstránenie všetkého okrem
Ak chcete z reťazca vymazať všetky znaky okrem tých, ktoré chcete zachovať, použite triedy negovaných znakov.
Ak chcete napríklad odstrániť všetky znaky okrem malých písmen a bodiek, regex je:
Vzor : [^a-z\.]+
V skutočnosti by sme sa tu mohli zaobísť bez kvantifikátora +, pretože naša funkcia nahradí všetky nájdené zhody. Kvantifikátor to len trochu urýchľuje - namiesto spracovania každého jednotlivého znaku nahradíte podreťazec.
=RegExpReplace(A5, "[^a-z\.]+", "")
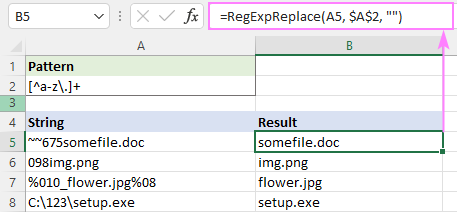
Regex na odstránenie html značiek v programe Excel
Na úvod treba poznamenať, že HTML nie je regulárny jazyk, takže jeho rozbor pomocou regulárnych výrazov nie je najlepší spôsob. Napriek tomu regexy určite pomôžu odstrániť značky z buniek, aby bol súbor údajov čistejší.
Vzhľadom na to, že značky html sú vždy umiestnené v uhlových zátvorkách , môžete ich nájsť pomocou jedného z nasledujúcich regexov.
Negovaná trieda:
Vzor : ]*>
V tomto prípade porovnávame úvodnú uhlovú zátvorku, za ktorou nasleduje nula alebo viac výskytov akéhokoľvek znaku okrem uzatváracej uhlovej zátvorky [^>]* až po najbližšiu uzatváraciu uhlovú zátvorku.
Lenivé vyhľadávanie:
Vzor :
V tomto prípade porovnávame čokoľvek od prvej otváracej zátvorky po prvú zatváraciu zátvorku. Otazník núti znak .*, aby porovnával čo najmenej znakov, kým nenájde zatváraciu zátvorku.
Nech už si vyberiete akýkoľvek vzor, výsledok bude úplne rovnaký.
Ak chcete napríklad odstrániť všetky značky html z reťazca v poli A5 a ponechať text, vzorec je:
=RegExpReplace(A5, "]*>", "")
Alebo môžete použiť lenivý kvantifikátor, ako je znázornené na obrázku:
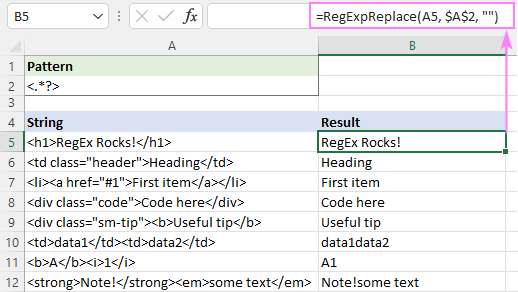
Toto riešenie funguje perfektne pre jeden text (riadky 5 - 9). V prípade viacerých textov (riadky 10 - 12) je výsledok sporný - texty z rôznych značiek sa spoja do jedného. Je to správne alebo nie? Obávam sa, že sa to nedá jednoducho rozhodnúť - všetko závisí od vášho chápania požadovaného výsledku. Napríklad v B11 sa očakáva výsledok "A1", zatiaľ čo v B10 by ste mohli chcieť"data1" a "data2" oddeliť medzerou.
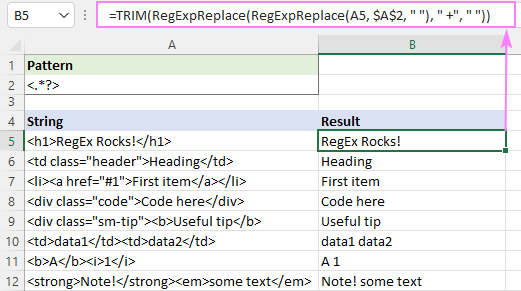
Ak chcete odstrániť značky html a oddeliť zvyšné texty medzerami, môžete postupovať takto:
- Nahraďte značky medzerami " ", nie prázdnymi reťazcami:
=RegExpReplace(A5, "]*>", " ") - Zredukujte viacero medzier na jeden znak medzery:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Orežte úvodné a koncové medzery:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
Výsledok bude vyzerať približne takto:
Ablebits Regex Remove Tool
Ak ste už mali možnosť používať náš balík Ultimate Suite pre Excel, pravdepodobne ste už objavili nové nástroje Regex, ktoré boli predstavené v nedávnej verzii. Krása týchto funkcií Regex založených na technológii .NET spočíva v tom, že po prvé podporujú plnohodnotnú syntax regulárnych výrazov bez obmedzení VBA RegExp a po druhé nevyžadujú vkladanie kódu VBA do vašich zošitov, pretože všetka integrácia kódu sa vykonávanami na zadnej strane.
Vašou úlohou je zostaviť regulárny výraz a naservírovať ho funkcii :) Ukážem vám, ako to urobiť na praktickom príklade.
Ako odstrániť text v zátvorkách a zátvorkách pomocou regexu
V dlhých textových reťazcoch sú menej dôležité informácie často uzavreté v [zátvorkách] a (zátvorkách). Ako odstrániť tieto nepodstatné údaje pri zachovaní všetkých ostatných údajov?
V skutočnosti sme už vytvorili podobný regex na odstraňovanie značiek html, t. j. textu v hranatých zátvorkách. Rovnaké metódy budú samozrejme fungovať aj pre hranaté a okrúhle zátvorky.
Vzor : (\(.*?\))
Trik spočíva v použití lenivého kvantifikátora (*?) na porovnanie čo najkratšieho podreťazca. Prvá skupina (\(.*?\)) sa zhoduje s čímkoľvek od úvodnej zátvorky po prvú zatváraciu zátvorku. Druhá skupina (\[.*?\]) sa zhoduje s čímkoľvek od úvodnej zátvorky po prvú zatváraciu zátvorku.
Keď je vzor určený, "nakŕmime" ním našu funkciu Regex Remove. Tu je postup:
- Na Údaje Ablebits na karte Text kliknite na položku Nástroje Regex .
Ak chcete získať výsledky ako vzorce, nie ako hodnoty, vyberte Vložiť ako vzorec začiarkavacie políčko.
Ak chcete odstrániť text v zátvorkách z reťazcov v A2:A5, nakonfigurujte nastavenia takto:
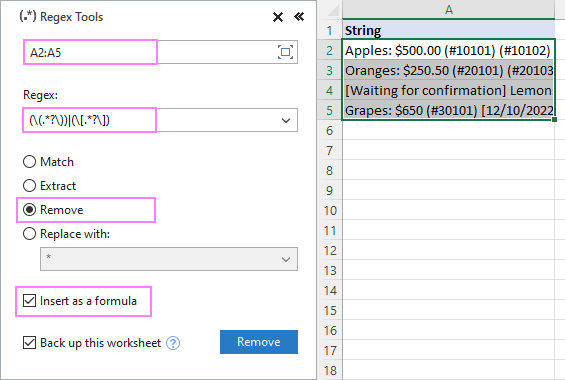
V dôsledku toho sa AblebitsRegexRemove sa vloží do nového stĺpca vedľa pôvodných údajov.
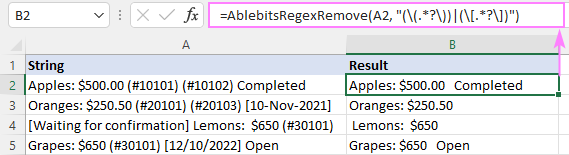
Funkciu je možné zadať aj priamo do bunky pomocou štandardného Vložiť funkciu dialógové okno, kde je zaradená do kategórie AblebitsUDFs .
Ako AblebitsRegexRemove je určená na odstránenie textu, vyžaduje len dva argumenty - zdrojový reťazec a regex. Oba parametre môžu byť definované priamo vo vzorci alebo dodané vo forme odkazov na bunky. V prípade potreby možno túto vlastnú funkciu použiť spolu s niektorými natívnymi funkciami.
Napríklad na orezanie nadbytočných medzier vo výsledných reťazcoch môžete použiť funkciu TRIM ako obal:
=TRIM(AblebitsRegexRemove(A5, $A$2))
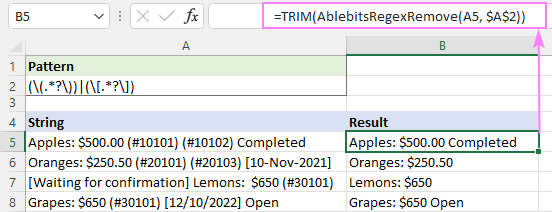
To je spôsob, ako odstrániť reťazce v programe Excel pomocou regulárnych výrazov. Ďakujem vám za prečítanie a teším sa na vás na našom blogu budúci týždeň!
Dostupné súbory na stiahnutie
Odstránenie reťazcov pomocou regexu - príklady (.xlsm súbor)
Ultimate Suite - skúšobná verzia (.exe súbor)
