
সুচিপত্র
নীচের স্ট্রিংগুলিতে, ধরুন আপনি প্রথম অর্ডার নম্বরটি মুছতে চান৷ এই জাতীয় সমস্ত সংখ্যা হ্যাশ চিহ্ন (#) দিয়ে শুরু হয় এবং ঠিক 5 সংখ্যা থাকে। সুতরাং, আমরা এই regex ব্যবহার করে তাদের সনাক্ত করতে পারি:
প্যাটার্ন : #\d{5}\b
শব্দ সীমানা \b নির্দিষ্ট করে যে একটি মিলিত সাবস্ট্রিং হতে পারে না একটি বড় স্ট্রিং এর অংশ যেমন #10000001।
সমস্ত মিল মুছে ফেলার জন্য, instance_num আর্গুমেন্টটি সংজ্ঞায়িত করা হয়নি:
=RegExpReplace(A5, "#\d{5}\b", "")
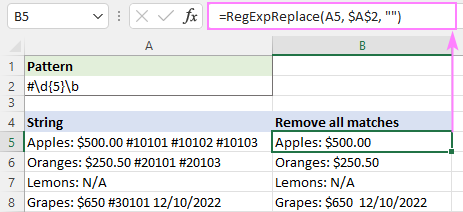
শুধুমাত্র প্রথম ঘটনাটি মুছে ফেলার জন্য, আমরা instance_num আর্গুমেন্টকে 1 এ সেট করি:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
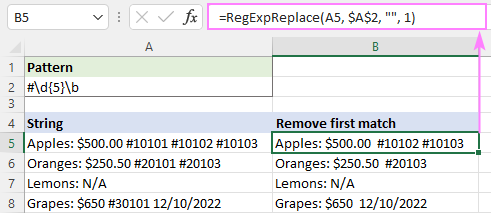
Regex নির্দিষ্ট কিছু অক্ষর অপসারণ করতে
একটি স্ট্রিং থেকে নির্দিষ্ট অক্ষর বাদ দিতে, শুধু সমস্ত অবাঞ্ছিত অক্ষর লিখুন এবং একটি উল্লম্ব বার দিয়ে আলাদা করুনVBA RegExp সীমাবদ্ধতা ছাড়া সিনট্যাক্স মুক্ত, এবং দ্বিতীয়ত, আপনার ওয়ার্কবুকে কোনো VBA কোড ঢোকানোর প্রয়োজন নেই কারণ সমস্ত কোড ইন্টিগ্রেশন আমাদের দ্বারা ব্যাকএন্ডে করা হয়।
আপনার কাজের অংশ হল একটি রেগুলার এক্সপ্রেশন তৈরি করা এবং এটিকে ফাংশনে পরিবেশন করুন :) একটি ব্যবহারিক উদাহরণে এটি কীভাবে করতে হয় তা আমি আপনাকে দেখাই৷
রেজেক্স ব্যবহার করে বন্ধনী এবং বন্ধনীর পাঠ্য কীভাবে সরানো যায়
লম্বা পাঠ্য স্ট্রিংগুলিতে, কম গুরুত্বপূর্ণ তথ্য প্রায়ই [বন্ধনী] এবং (বন্ধনী) এ আবদ্ধ থাকে। অন্যান্য সমস্ত ডেটা রেখে আপনি কীভাবে সেই অপ্রাসঙ্গিক বিবরণগুলি সরিয়ে ফেলবেন?
আসলে, আমরা ইতিমধ্যেই এইচটিএমএল ট্যাগগুলি মুছে ফেলার জন্য একটি অনুরূপ রেজেক্স তৈরি করেছি, অর্থাত্ কোণ বন্ধনীর মধ্যে পাঠ্য৷ স্পষ্টতই, একই পদ্ধতিগুলি বর্গাকার এবং বৃত্তাকার বন্ধনীগুলির জন্যও কাজ করবে৷
প্যাটার্ন : (\(.*?\))
আপনি কি কখনও ভেবে দেখেছেন যে কেউ যদি রেগুলার এক্সপ্রেশন দিয়ে এর টুলবক্সকে সমৃদ্ধ করতে পারে তাহলে Excel কতটা শক্তিশালী হবে? আমরা শুধু চিন্তাই করিনি কিন্তু এটি নিয়ে কাজ করেছি :) এবং এখন, আপনি আপনার নিজের ওয়ার্কবুকগুলিতে এই দুর্দান্ত RegEx ফাংশনটি যুক্ত করতে পারেন এবং কিছুক্ষণের মধ্যে একটি প্যাটার্নের সাথে মিলে যাওয়া সাবস্ট্রিংগুলি মুছে ফেলতে পারেন!
গত সপ্তাহে, আমরা দেখেছিলাম এক্সেলে স্ট্রিং প্রতিস্থাপন করতে রেগুলার এক্সপ্রেশন কীভাবে ব্যবহার করবেন। এর জন্য, আমরা একটি কাস্টম রেজেক্স রিপ্লেস ফাংশন তৈরি করেছি। যেহেতু এটি পরিণত হয়েছে, ফাংশনটি তার প্রাথমিক ব্যবহারের বাইরে চলে যায় এবং শুধুমাত্র স্ট্রিংগুলিকে প্রতিস্থাপন করতে পারে না তবে সেগুলিকে সরিয়েও দিতে পারে৷ এটা কিভাবে হতে পারে? এক্সেলের পরিপ্রেক্ষিতে, একটি মান অপসারণ করা একটি খালি স্ট্রিং দিয়ে প্রতিস্থাপন করা ছাড়া আর কিছুই নয়, এমন কিছু যা আমাদের রেজেক্স ফাংশন খুব ভাল!
VBA RegExp ফাংশন এক্সেলের সাবস্ট্রিংগুলি সরাতে
আমরা সবাই জানি, রেগুলার এক্সপ্রেশন এক্সেলে ডিফল্টরূপে সমর্থিত নয়। তাদের সক্ষম করতে, আপনাকে আপনার নিজস্ব ব্যবহারকারী-সংজ্ঞায়িত ফাংশন তৈরি করতে হবে। ভাল খবর হল যে এই ধরনের একটি ফাংশন ইতিমধ্যে লিখিত, পরীক্ষিত এবং ব্যবহারের জন্য প্রস্তুত। আপনাকে যা করতে হবে তা হল এই কোডটি অনুলিপি করতে হবে, এটি আপনার VBA সম্পাদকে পেস্ট করতে হবে এবং তারপরে আপনার ফাইলটিকে একটি ম্যাক্রো-সক্ষম ওয়ার্কবুক (.xlsm) হিসাবে সংরক্ষণ করতে হবে।
ফাংশনে রয়েছে নিম্নলিখিত সিনট্যাক্স:
RegExpReplace(টেক্সট, প্যাটার্ন, প্রতিস্থাপন, [instance_num], [match_case])প্রথম তিনটি আর্গুমেন্ট প্রয়োজন, শেষ দুটি ঐচ্ছিক৷
কোথায়:
- টেক্সট - অনুসন্ধান করার জন্য পাঠ্য স্ট্রিংএটি একটি ক্লোজিং ব্র্যাকেট না পাওয়া পর্যন্ত সম্ভব।
আপনি যে প্যাটার্নটি বেছে নিন না কেন, ফলাফলটি সম্পূর্ণ একই হবে।
উদাহরণস্বরূপ, A5-এ একটি স্ট্রিং থেকে সমস্ত html ট্যাগ মুছে ফেলা এবং পাঠ্য ছেড়ে দিতে, সূত্রটি হল:
=RegExpReplace(A5, "]*>", "")
অথবা স্ক্রিনশটে দেখানো হিসাবে আপনি অলস কোয়ান্টিফায়ার ব্যবহার করতে পারেন:
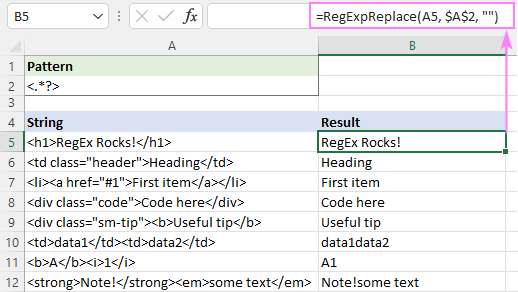
এই সমাধানটি পুরোপুরি কাজ করে একক পাঠ্য (সারি 5 - 9)। একাধিক পাঠ্যের জন্য (সারি 10 - 12), ফলাফলগুলি সন্দেহজনক - বিভিন্ন ট্যাগের পাঠ্যগুলিকে একটিতে একত্রিত করা হয়েছে৷ এটা কি সঠিক নাকি? আমি ভয় পাচ্ছি, এটি এমন কিছু নয় যা সহজে সিদ্ধান্ত নেওয়া যায় - সবই আপনার পছন্দসই ফলাফল সম্পর্কে বোঝার উপর নির্ভর করে। উদাহরণস্বরূপ, B11-এ, ফলাফল "A1" প্রত্যাশিত; B10 তে থাকাকালীন, আপনি "data1" এবং "data2" একটি স্পেস দিয়ে আলাদা করতে চাইতে পারেন৷
html ট্যাগগুলি সরাতে এবং অবশিষ্ট পাঠ্যগুলিকে স্পেস দিয়ে আলাদা করতে, আপনি এইভাবে এগিয়ে যেতে পারেন:
- ট্যাগগুলিকে স্পেস দিয়ে প্রতিস্থাপন করুন " ", খালি স্ট্রিং নয়:
=RegExpReplace(A5, "]*>", " ") - একাধিক স্পেসকে একটি একক স্পেস অক্ষরে কমিয়ে দিন:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - প্রধান এবং পিছনের স্থানগুলি ট্রিম করুন:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
ফলাফলটি এরকম দেখাবে:
32>
Ablebits Regex Remove Tool
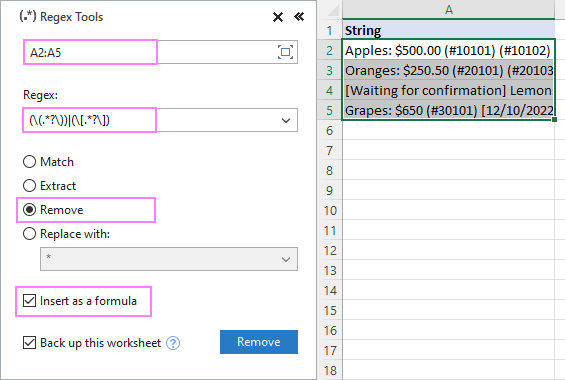
আপনি যদি এক্সেলের জন্য আমাদের আলটিমেট স্যুট ব্যবহার করার সুযোগ পেয়ে থাকেন, আপনি সম্ভবত ইতিমধ্যেই সাম্প্রতিক রিলিজের সাথে প্রবর্তিত নতুন রেজেক্স টুলস আবিষ্কার করেছেন। এই .NET ভিত্তিক Regex ফাংশনগুলির সৌন্দর্য হল যে তারা প্রথমত, পূর্ণ বৈশিষ্ট্যযুক্ত রেগুলার এক্সপ্রেশন সমর্থন করে Remove অপশনটি, এবং Remove চাপুন।
ফলাফলগুলিকে সূত্র হিসাবে পেতে, মান নয়, সূত্র হিসাবে সন্নিবেশ করুন চেক বক্সটি নির্বাচন করুন।
A2:A5-এর স্ট্রিংগুলি থেকে বন্ধনীর মধ্যে পাঠ্য অপসারণ করতে, আমরা সেটিংস কনফিগার করি নিম্নরূপ:
ফলস্বরূপ, AblebitsRegexRemove ফাংশনটি আপনার আসল ডেটার পাশে একটি নতুন কলামে ঢোকানো হয়৷
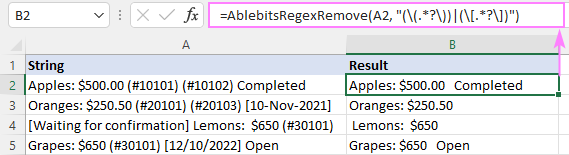
ফাংশনটি স্ট্যান্ডার্ড ইনসার্ট ফাংশন ডায়ালগ বক্সের মাধ্যমেও একটি ঘরে সরাসরি প্রবেশ করা যেতে পারে, যেখানে এটি AblebitsUDFs এর অধীনে শ্রেণীবদ্ধ করা হয়েছে।<3
যেহেতু AblebitsRegexRemove পাঠ্য অপসারণের জন্য ডিজাইন করা হয়েছে, এটির জন্য শুধুমাত্র দুটি আর্গুমেন্ট প্রয়োজন - উৎস স্ট্রিং এবং রেজেক্স। উভয় পরামিতি সরাসরি একটি সূত্রে সংজ্ঞায়িত করা যেতে পারে বা সেল রেফারেন্স আকারে সরবরাহ করা যেতে পারে। যদি প্রয়োজন হয়, এই কাস্টম ফাংশনটি যেকোনো নেটিভের সাথে একসাথে ব্যবহার করা যেতে পারে।
উদাহরণস্বরূপ, ফলের স্ট্রিংগুলিতে অতিরিক্ত স্পেস ট্রিম করতে, আপনি TRIM ফাংশনটিকে একটি মোড়ক হিসাবে ব্যবহার করতে পারেন:
=TRIM(AblebitsRegexRemove(A5, $A$2))
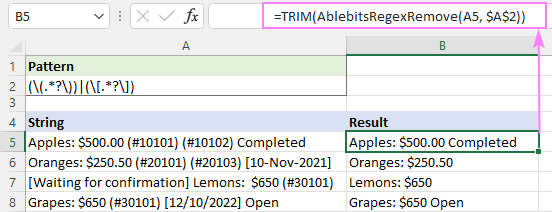
এভাবে রেগুলার এক্সপ্রেশন ব্যবহার করে এক্সেলে স্ট্রিংগুলি সরিয়ে ফেলা যায়। আমি পড়ার জন্য আপনাকে ধন্যবাদ এবং আগামী সপ্তাহে আমাদের ব্লগে আপনাকে দেখার জন্য অপেক্ষা করছি!
উপলব্ধ ডাউনলোড
রেজেক্স ব্যবহার করে স্ট্রিংগুলি সরান - উদাহরণ (.xlsm ফাইল)
আলটিমেট স্যুট - ট্রায়াল সংস্করণ (.exe ফাইল)
in.আরো তথ্যের জন্য, অনুগ্রহ করে RegExpReplace ফাংশন দেখুন৷
টিপ৷ সাধারণ ক্ষেত্রে, আপনি এক্সেল সূত্র সহ কক্ষ থেকে নির্দিষ্ট অক্ষর বা শব্দগুলি সরাতে পারেন। কিন্তু রেগুলার এক্সপ্রেশন এর জন্য অনেক বেশি বিকল্প প্রদান করে।
রেগুলার এক্সপ্রেশন ব্যবহার করে কিভাবে স্ট্রিং অপসারণ করা যায় - উদাহরণ
উপরে উল্লিখিত হিসাবে, একটি প্যাটার্নের সাথে মেলে এমন পাঠ্যের অংশগুলি মুছে ফেলার জন্য, আপনাকে সেগুলি প্রতিস্থাপন করতে হবে একটি খালি স্ট্রিং দিয়ে। সুতরাং, একটি জেনেরিক সূত্র এই আকার নেয়:
RegExpReplace(টেক্সট, প্যাটার্ন, "", [instance_num], [match_case])নীচের উদাহরণগুলি এই মৌলিক ধারণার বিভিন্ন বাস্তবায়ন দেখায়।
সরান সমস্ত মিল বা নির্দিষ্ট মিল
RegExpReplace ফাংশনটি একটি প্রদত্ত রেজেক্সের সাথে মিলে যাওয়া সমস্ত সাবস্ট্রিং খুঁজে বের করার জন্য ডিজাইন করা হয়েছে। কোন ঘটনাগুলি অপসারণ করা হবে তা 4র্থ ঐচ্ছিক আর্গুমেন্ট দ্বারা নিয়ন্ত্রিত হয়, যার নাম instance_num ।
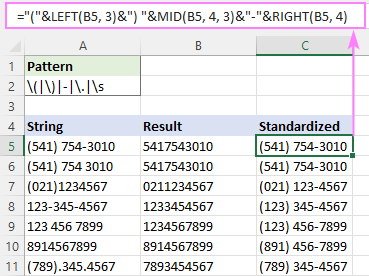
ডিফল্ট হল "সমস্ত ম্যাচ" - যখন instance_num কনক্যাটেনেশন অপারেটর (&) এবং টেক্সট ফাংশন যেমন RIGHT, MID এবং LEFT।
উদাহরণস্বরূপ, (123) 456-7890 ফর্ম্যাটে সমস্ত ফোন নম্বর লিখতে, সূত্রটি হল:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
যেখানে B5 হল RegExpReplace ফাংশনের আউটপুট।
Regex ব্যবহার করে বিশেষ অক্ষরগুলি সরান
আমাদের একটি টিউটোরিয়াল-এ, আমরা ইনবিল্ট এবং কাস্টম ফাংশন ব্যবহার করে এক্সেলের অবাঞ্ছিত অক্ষরগুলি কীভাবে সরিয়ে ফেলা যায় তা দেখেছি। নিয়মিত অভিব্যক্তি জিনিস অনেক সহজ করে তোলে! মুছে ফেলার জন্য সমস্ত অক্ষর তালিকাভুক্ত করার পরিবর্তে, আপনি যেগুলি রাখতে চান তা নির্দিষ্ট করুন :)
প্যাটার্নটি নেগেটেড ক্যারেক্টার ক্লাস এর উপর ভিত্তি করে - একটি ক্যারেট একটি অক্ষর শ্রেণীর ভিতরে রাখা হয় [^ ] বন্ধনীতে নয় এমন কোনো একক অক্ষরের সাথে মেলে। + কোয়ান্টিফায়ার এটিকে পরপর অক্ষরগুলিকে একক মিল হিসাবে বিবেচনা করতে বাধ্য করে, যাতে প্রতিটি পৃথক অক্ষরের পরিবর্তে একটি মিলিত সাবস্ট্রিংয়ের জন্য একটি প্রতিস্থাপন করা হয়৷
আপনার প্রয়োজনের উপর নির্ভর করে, নিম্নলিখিত রেজেক্সগুলির মধ্যে একটি বেছে নিন৷
নন-অ্যালফানিউমেরিক অক্ষরগুলি সরাতে, অর্থাৎ অক্ষর এবং অঙ্কগুলি ছাড়া সমস্ত অক্ষর:
প্যাটার্ন : [^0-9a-zA-Z] +
সমস্ত অক্ষর শুদ্ধ করতে অক্ষর ছাড়া , অঙ্কগুলি এবং স্পেস :
প্যাটার্ন : [^0-9a-zA-Z ]+
অক্ষরগুলি , অঙ্কগুলি এবং আন্ডারস্কোর ব্যতীত সমস্ত অক্ষর মুছতে, আপনি \ ব্যবহার করতে পারেন W যে কোনো অক্ষরকে বোঝায় যেটি বর্ণানুক্রমিক অক্ষর নয় বাআন্ডারস্কোর:
প্যাটার্ন : \W+
যদি আপনি অন্য কিছু অক্ষর রাখতে চান , যেমন বিরাম চিহ্ন, বন্ধনীর ভিতরে রাখুন।
উদাহরণস্বরূপ, একটি অক্ষর, অঙ্ক, পিরিয়ড, কমা বা স্থান ব্যতীত অন্য কোন অক্ষর বাদ দিতে, নিম্নলিখিত রেজেক্স ব্যবহার করুন:
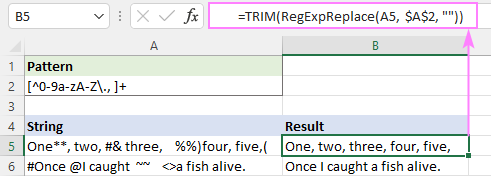
প্যাটার্ন : [^0-9a-zA-Z\., ]+
এটি সফলভাবে সমস্ত বিশেষ অক্ষর মুছে দেয়, কিন্তু অতিরিক্ত হোয়াইটস্পেস থেকে যায়।
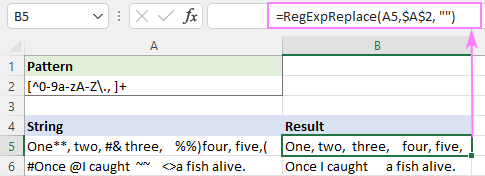
এটি ঠিক করার জন্য, আপনি উপরের ফাংশনটিকে অন্য একটিতে নেস্ট করতে পারেন যা একাধিক স্পেসকে একটি একক স্পেস অক্ষর দিয়ে প্রতিস্থাপন করে।
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
অথবা একই প্রভাবের সাথে নেটিভ TRIM ফাংশন ব্যবহার করুন :
=TRIM(RegExpReplace(A5, $A$2, ""))
অ-সংখ্যাসূচক অক্ষরগুলি সরাতে Regex
একটি স্ট্রিং থেকে সমস্ত অ-সংখ্যাসূচক অক্ষর মুছতে, আপনি ব্যবহার করতে পারেন হয় এই দীর্ঘ সূত্র বা নীচে তালিকাভুক্ত খুব সাধারণ রেজেক্সগুলির মধ্যে একটি৷
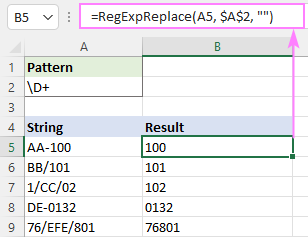
অঙ্ক নয় এমন যেকোনো অক্ষর মিলান:
প্যাটার্ন : \D+
নেগেটেড ক্লাস ব্যবহার করে অ-সংখ্যিক অক্ষর স্ট্রীপ করুন:
প্যাটার্ন : [^0-9]+
প্যাটার্ন : [^\d] +
টিপ। যদি আপনার লক্ষ্য টেক্সট অপসারণ করা এবং অবশিষ্ট সংখ্যাগুলিকে পৃথক কক্ষে ছড়িয়ে দেওয়া বা একটি নির্দিষ্ট সীমারেখা দিয়ে আলাদা করা একটি কক্ষে সেগুলি স্থাপন করা হয়, তাহলে রেগুলার এক্সপ্রেশন ব্যবহার করে স্ট্রিং থেকে সংখ্যাগুলি কীভাবে বের করতে হয় তাতে ব্যাখ্যা করা RegExpExtract ফাংশনটি ব্যবহার করুন।
স্পেসের পরে সবকিছু মুছে ফেলার জন্য রেজেক্স
স্পেসের পরে সবকিছু মুছে ফেলতে, হয় স্পেস ব্যবহার করুন ( ) বাহোয়াইটস্পেস (\s) অক্ষরটি প্রথম স্থান খুঁজে পেতে এবং .* এর পরে যেকোন অক্ষরের সাথে মেলে।
আপনার যদি একক-লাইন স্ট্রিং থাকে যাতে শুধুমাত্র সাধারণ স্পেস থাকে (7-বিট ASCII সিস্টেমে মান 32) , আপনি নীচের কোন রেজেক্স ব্যবহার করেন তা সত্যিই ব্যাপার নয়। মাল্টি-লাইন স্ট্রিং এর ক্ষেত্রে, এটি একটি পার্থক্য করে।
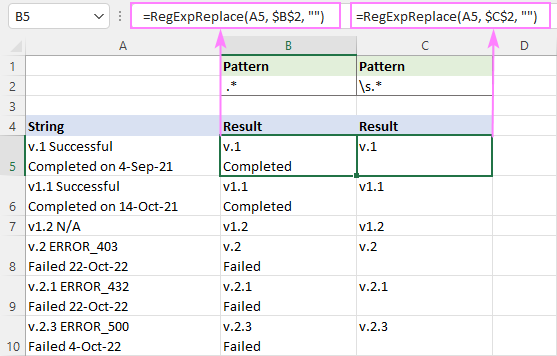
সবকিছু অপসারণ করতে একটি স্পেস অক্ষর পরে, এই রেজেক্স ব্যবহার করুন:
প্যাটার্ন : " .*"
=RegExpReplace(A5, " .*", "")
এই সূত্রটি প্রতিটি লাইনে প্রথম স্থানের পরে যেকোনও কিছু বাদ দেবে। ফলাফলগুলি সঠিকভাবে প্রদর্শনের জন্য, র্যাপ টেক্সট চালু করতে ভুলবেন না।
সব কিছু বন্ধ করতে একটি সাদা স্থানের পরে (একটি স্পেস, ট্যাব, ক্যারেজ রিটার্ন এবং নতুন লাইন সহ), রেজেক্স হল:
প্যাটার্ন : \s.*
=RegExpReplace(A5, "\s.*", "")
কারণ \s একটি নতুন লাইন<সহ কয়েকটি ভিন্ন হোয়াইটস্পেস প্রকারের সাথে মেলে 9> (\n), এই সূত্রটি একটি কক্ষের প্রথম স্থানের পরে সমস্ত কিছু মুছে দেয়, এতে যত লাইনই থাকুক না কেন।
নির্দিষ্টের পরে পাঠ্য অপসারণ করতে Regex অক্ষর
আগের উদাহরণের পদ্ধতিগুলি ব্যবহার করে, আপনি যে কোনও অক্ষরের পরে পাঠ্য মুছে ফেলতে পারেন যা আপনি নির্দিষ্ট করেছেন৷
প্রতিটি লাইন আলাদাভাবে পরিচালনা করতে:
জেনারিক প্যাটার্ন : char.*
একক-লাইন স্ট্রিং-এ, এটি char -এর পরে সবকিছু সরিয়ে দেবে। মাল্টি-লাইন স্ট্রিংগুলিতে, প্রতিটি লাইন পৃথকভাবে প্রক্রিয়া করা হবে কারণ VBA Regex ফ্লেভারে, একটি পিরিয়ড (.) একটি নতুন ছাড়া যেকোনো অক্ষরের সাথে মেলেএকটি স্ট্রিং ^ এর শুরুতে, আমরা শূন্য বা একাধিক নন-স্পেস অক্ষর [^ ]* মেলে যা অবিলম্বে এক বা একাধিক স্পেস "+" দ্বারা অনুসরণ করা হয়। ফলাফলে সম্ভাব্য অগ্রণী স্থানগুলি রোধ করতে শেষ অংশটি যুক্ত করা হয়েছে৷
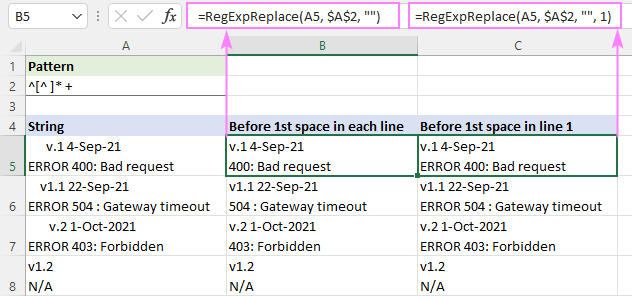
প্রতিটি লাইনে প্রথম স্থানের আগে পাঠ্য অপসারণ করতে, সূত্রটি ডিফল্ট "সমস্ত ম্যাচ" মোডে লেখা হয় ( ইনস্ট্যান্স_সংখ্যা বাদ দেওয়া হয়েছে):
=RegExpReplace(A5, "^[^ ]* +", "")
প্রথম লাইনের প্রথম স্থানের আগে পাঠ্য মুছে ফেলতে এবং অন্য সমস্ত লাইন অক্ষত রাখতে, instance_num আর্গুমেন্টটি 1:<এ সেট করা হয়েছে 3>
=RegExpReplace(A5, "^[^ ]* +", "", 1)
রেজেক্স অক্ষরের আগে সবকিছু খুলে ফেলার জন্য
একটি নির্দিষ্ট অক্ষরের আগে সমস্ত পাঠ্য মুছে ফেলার সবচেয়ে সহজ উপায় হল একটি রেজেক্স ব্যবহার করা এইরকম:
জেনারিক প্যাটার্ন : ^[^char]*char
মানুষের ভাষায় অনুবাদ করা হয়েছে, এটি বলে: "^ দ্বারা নোঙ্গর করা একটি স্ট্রিংয়ের শুরু থেকে , char [^char]* ব্যতীত 0 বা তার বেশি অক্ষর মেলে char এর প্রথম উপস্থিতি পর্যন্ত।
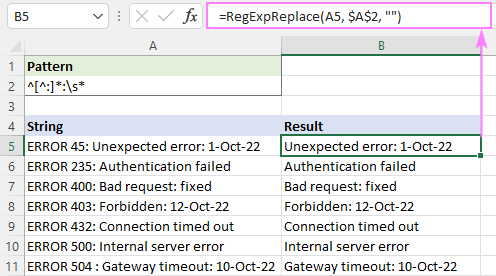
উদাহরণস্বরূপ, প্রথম কোলনের আগে সমস্ত পাঠ্য মুছে ফেলার জন্য , এই রেগুলার এক্সপ্রেশনটি ব্যবহার করুন:
প্যাটার্ন : ^[^:]*:
ফলাফলগুলিতে অগ্রণী স্পেস এড়াতে, একটি হোয়াইটস্পেস অক্ষর \s* যোগ করুন শেষ। এটি সবকিছু মুছে ফেলবে প্রথম কোলনের আগে g এবং এর ঠিক পরে যেকোন স্পেস ট্রিম করুন:
প্যাটার্ন : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
টিপ। রেগুলার এক্সপ্রেশন ছাড়াও, এক্সেলের অবস্থান বা মিল অনুসারে পাঠ্য অপসারণের নিজস্ব উপায় রয়েছে। কিভাবে নেটিভ সূত্র দিয়ে কাজটি সম্পন্ন করতে হয় তা শিখতে,অনুগ্রহ করে দেখুন কিভাবে এক্সেলের অক্ষরের আগে বা পরে টেক্সট মুছে ফেলতে হয়।
রেজেক্স ছাড়া সবকিছু মুছে ফেলার জন্য
আপনি যেগুলি রাখতে চান তা ছাড়া একটি স্ট্রিং থেকে সমস্ত অক্ষর মুছে ফেলতে, নেগেটেড ক্যারেক্টার ক্লাসগুলি ব্যবহার করুন৷
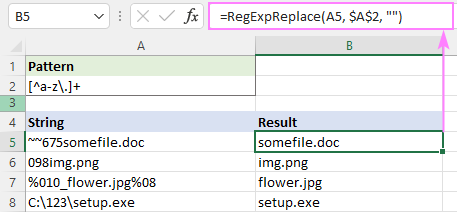
উদাহরণস্বরূপ, ছোট হাতের অক্ষরগুলি ছাড়া সমস্ত অক্ষর সরাতে এবং বিন্দু, regex হল:
প্যাটার্ন : [^a-z\.]+
আসলে, আমরা এখানে + কোয়ান্টিফায়ার ছাড়াই করতে পারি কারণ আমাদের ফাংশন সব প্রতিস্থাপন করে মিল পাওয়া গেছে কোয়ান্টিফায়ার এটিকে একটু দ্রুত করে - প্রতিটি স্বতন্ত্র অক্ষর পরিচালনা করার পরিবর্তে, আপনি একটি সাবস্ট্রিং প্রতিস্থাপন করেন৷
=RegExpReplace(A5, "[^a-z\.]+", "")
এক্সেলে এইচটিএমএল ট্যাগগুলি সরাতে Regex
প্রথমে, এটি লক্ষ করা উচিত যে HTML একটি নিয়মিত ভাষা নয়, তাই রেগুলার এক্সপ্রেশন ব্যবহার করে এটি পার্স করা সর্বোত্তম উপায় নয়। এটি বলেছে, রেজেক্সগুলি অবশ্যই আপনার ডেটাসেটকে পরিষ্কার করতে আপনার কোষ থেকে ট্যাগগুলি বের করে দিতে সাহায্য করতে পারে৷
প্রদত্ত যে html ট্যাগগুলি সর্বদা কোণ বন্ধনীর মধ্যে রাখা হয়, আপনি নিম্নলিখিত রেজেক্সগুলির মধ্যে একটি ব্যবহার করে সেগুলি খুঁজে পেতে পারেন৷
নেগেটেড ক্লাস:
প্যাটার্ন : ]*>
এখানে, আমরা একটি প্রারম্ভিক কোণ বন্ধনীর সাথে মিল করি, যার পরে যেকোন অক্ষরের শূন্য বা তার বেশি ঘটনা ঘটে ক্লোজিং অ্যাঙ্গেল ব্র্যাকেট [^>]* নিকটতম ক্লোজিং অ্যাঙ্গেল ব্র্যাকেট পর্যন্ত।
অলস অনুসন্ধান:
প্যাটার্ন :
এখানে, আমরা মেলে প্রথম খোলার বন্ধনী থেকে প্রথম বন্ধ বন্ধনী পর্যন্ত যেকোনো কিছু। প্রশ্নবোধক চিহ্ন .* যত কম অক্ষর মিলাতে বাধ্য করেলাইন।
একটি স্ট্রিং হিসাবে সমস্ত লাইন প্রক্রিয়া করতে:
জেনারিক প্যাটার্ন : char(.
