
Obsah
Napadlo vás někdy, jak mocný by byl Excel, kdyby někdo dokázal obohatit jeho sadu nástrojů o regulární výrazy? Nejenže jsme o tom přemýšleli, ale také jsme na tom pracovali :) A nyní můžete tuto úžasnou funkci RegEx přidat do svých vlastních sešitů a v mžiku vymazat podřetězce odpovídající vzoru!
Minulý týden jsme se zabývali tím, jak používat regulární výrazy k nahrazování řetězců v Excelu. K tomu jsme vytvořili vlastní funkci Regex Replace. Jak se ukázalo, funkce přesahuje své primární použití a dokáže řetězce nejen nahrazovat, ale také odstraňovat. Jak je to možné? Z hlediska Excelu není odstranění hodnoty nic jiného než její nahrazení prázdným řetězcem, což naše funkce Regex jevelmi dobré!
Funkce VBA RegExp pro odstranění podřetězců v aplikaci Excel
Jak všichni víme, regulární výrazy nejsou ve výchozím nastavení Excelu podporovány. Abyste je mohli používat, musíte si vytvořit vlastní uživatelsky definovanou funkci. Dobrou zprávou je, že taková funkce je již napsána, otestována a připravena k použití. Stačí jen zkopírovat tento kód, vložit jej do editoru VBA a poté soubor uložit jako sešit s povolenými makry (.xlsm).
Funkce má následující syntaxi:
RegExpReplace(text, vzor, náhrada, [číslo_instance], [případ_zápasu])První tři argumenty jsou povinné, poslední dva jsou nepovinné.
Kde:
- Text - textový řetězec, ve kterém se má hledat.
- Vzor - regulární výraz, který se má hledat.
- Náhrada - text, který se má nahradit. Na odstranit podřetězce odpovídající vzoru, použijte prázdný řetězec ("") pro výměnu.
- Instance_num (nepovinné) - instance, která se má nahradit. Pokud není uvedeno, nahradí se všechny nalezené shody (výchozí).
- Match_case (nepovinné) - logická hodnota určující, zda se mají porovnávat nebo ignorovat velká a malá písmena textu. Pro porovnávání s rozlišováním velkých a malých písmen použijte TRUE (výchozí); pro porovnávání bez rozlišování velkých a malých písmen - FALSE.
Další informace naleznete v části Funkce RegExpReplace.
Tip: V jednoduchých případech můžete z buněk odstranit konkrétní znaky nebo slova pomocí vzorců aplikace Excel. Regulární výrazy však poskytují mnohem více možností.
Jak odstranit řetězce pomocí regulárních výrazů - příklady
Jak bylo uvedeno výše, chcete-li odstranit části textu odpovídající vzoru, nahradíte je prázdným řetězcem. Obecný vzorec má tedy tento tvar:
RegExpReplace(text, pattern, "", [instance_num], [match_case])Níže uvedené příklady ukazují různé implementace tohoto základního konceptu.
Odstranění všech shod nebo konkrétní shody
Funkce RegExpReplace je určena k nalezení všech podřetězců odpovídajících zadanému regexu. Které výskyty se mají odstranit, určuje čtvrtý nepovinný argument s názvem instance_num .
Výchozí nastavení je "všechny shody" - když se instance_num je argument vynechán, jsou odstraněny všechny nalezené shody. Chcete-li odstranit konkrétní shodu, zadejte číslo instance.
Předpokládejme, že v níže uvedených řetězcích chcete odstranit číslo prvního pořadí. Všechna taková čísla začínají hashovým znakem (#) a obsahují přesně 5 číslic. Můžeme je tedy identifikovat pomocí tohoto regexu:
Vzor : #\d{5}\b
Hranice slov \b určuje, že odpovídající podřetězec nemůže být součástí většího řetězce, například #10000001.
Chcete-li odstranit všechny shody, použijte instance_num argument není definován:
=RegExpReplace(A5, "#\d{5}\b", "")
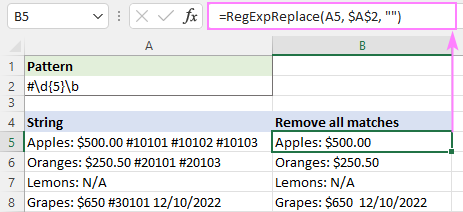
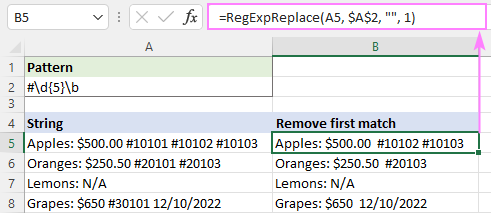
Abychom odstranili pouze první výskyt, nastavíme hodnotu instance_num na 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex pro odstranění určitých znaků
Chcete-li z řetězce odstranit určité znaky, napište všechny nežádoucí znaky a oddělte je svislou čarou.
Chceme-li například standardizovat telefonní čísla zapsaná v různých formátech, zbavíme se nejprve specifických znaků, jako jsou závorky, pomlčky, tečky a bílé znaky.
Vzor : \(
=RegExpReplace(A5, "\(
Výsledkem této operace je desetimístné číslo, například "1234567890".
Pro větší pohodlí můžete regex zadat do samostatné buňky a odkazovat na ni pomocí absolutního odkazu, například $A$2:
=RegExpReplace(A5, $A$2, "")
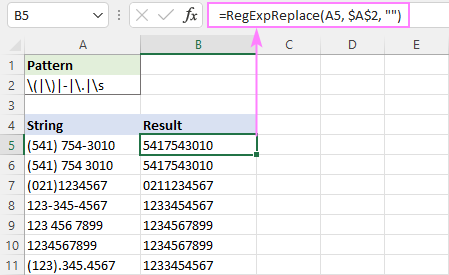
Formátování pak můžete standardizovat podle svých představ pomocí operátoru spojování (&) a textových funkcí, jako jsou RIGHT, MID a LEFT.
Chcete-li například zapsat všechna telefonní čísla ve formátu (123) 456-7890, použijete následující vzorec:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)")
Kde B5 je výstup funkce RegExpReplace.
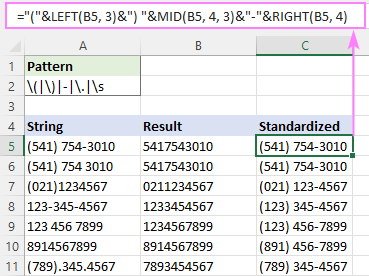
Odstranění speciálních znaků pomocí regexu
V jednom z našich návodů jsme se podívali na to, jak odstranit nežádoucí znaky v Excelu pomocí vestavěných a vlastních funkcí. Regulární výrazy vám to značně usnadní! Místo vypisování všech znaků k odstranění stačí zadat ty, které chcete zachovat :)
Vzor je založen na negované třídy znaků - caret je vložen dovnitř třídy znaků [^ ], aby odpovídal libovolnému jednotlivému znaku, který NENÍ v závorce. Kvantifikátor + nutí považovat po sobě jdoucí znaky za jedinou shodu, takže náhrada se provádí pro odpovídající podřetězec, nikoli pro každý jednotlivý znak.
V závislosti na svých potřebách vyberte jeden z následujících regexů.
Odstranění nealfanumerické tj. všechny znaky kromě písmen a číslic:
Vzor : [^0-9a-zA-Z]+
Vyčištění všech znaků kromě písmen , číslice a prostory :
Vzor : [^0-9a-zA-Z ]+
Odstranění všech znaků kromě písmen , číslice a podtržítko , můžete použít \W, které označuje jakýkoli znak, který NENÍ alfanumerický znak nebo podtržítko:
Vzor : \W+
Pokud chcete ponechat si některé další postavy , např. interpunkční znaménka, vložte je do závorek.
Chcete-li například odstranit jakýkoli jiný znak než písmeno, číslici, tečku, čárku nebo mezeru, použijte následující regex:
Vzor : [^0-9a-zA-Z\., ]+
Tím se úspěšně odstraní všechny speciální znaky, ale bílé znaky navíc zůstanou.
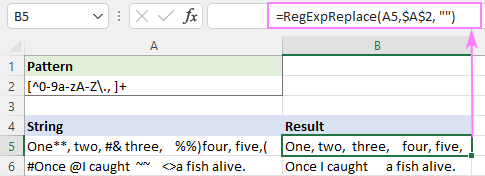
Chcete-li to napravit, můžete výše uvedenou funkci vnořit do jiné funkce, která nahradí více mezer jedním znakem mezery.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
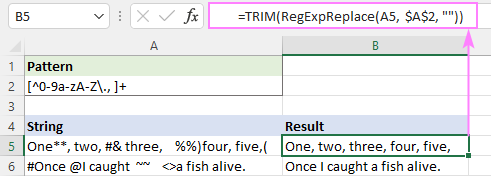
Nebo stačí použít nativní funkci TRIM se stejným účinkem:
=TRIM(RegExpReplace(A5, $A$2, ""))
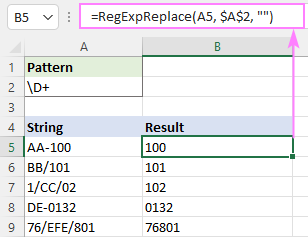
Regex pro odstranění nečíselných znaků
Chcete-li z řetězce odstranit všechny nečíselné znaky, můžete použít buď tento dlouhý vzorec, nebo jeden z velmi jednoduchých regexů uvedených níže.
Shoduje se s libovolným znakem, který NENÍ číslice:
Vzor : \D+
Odstranění nečíselných znaků pomocí negovaných tříd:
Vzor : [^0-9]+
Vzor : [^\d]+
Tip: Pokud je vaším cílem odstranit text a zbývající čísla rozsypat do samostatných buněk nebo je umístit všechna do jedné buňky oddělené zadaným oddělovačem, pak použijte funkci RegExpExtract, jak je vysvětleno v části Jak extrahovat čísla z řetězce pomocí regulárních výrazů.
Regex pro odstranění všeho za mezerou
Chcete-li vymazat vše, co následuje za mezerou, použijte buď mezeru ( ), nebo bílý znak (\s) pro vyhledání první mezery a .* pro porovnání všech znaků za ní.
Pokud máte jednořádkové řetězce, které obsahují pouze normální mezery (hodnota 32 v 7bitovém systému ASCII), nezáleží na tom, který z níže uvedených regexů použijete. V případě víceřádkových řetězců je to rozdíl.
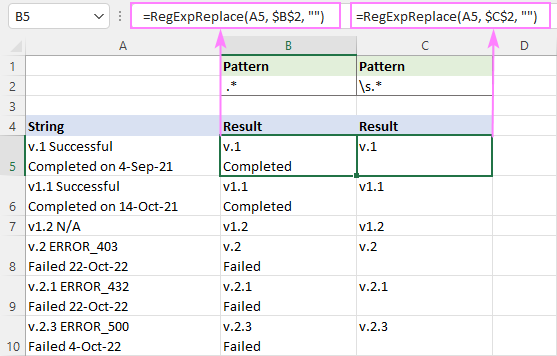
Odstranění všeho za znakem mezery , použijte tento regex:
Vzor : " .*"
=RegExpReplace(A5, " .*", "")
Tento vzorec odstraní vše, co se nachází za první mezerou ve slově každý řádek . Aby se výsledky zobrazovaly správně, nezapomeňte zapnout funkci Wrap Text.
Všechno svléknout za bílým znakem (včetně mezery, tabulátoru, návratu vozíku a nového řádku), regex je:
Vzor : \s.*
=RegExpReplace(A5, "\s.*", "")
Protože \s odpovídá několika různým typům bílých znaků včetně nový řádek (\n), tento vzorec odstraní vše, co se nachází za první mezerou v buňce, bez ohledu na počet řádků v buňce.
Regex pro odstranění textu za určitým znakem
Pomocí metod z předchozího příkladu můžete vymazat text za libovolným zadaným znakem.
Pro zpracování každého řádku zvlášť:
Obecný vzor : char.*
V jednořádkových řetězcích se odstraní vše, co následuje po řetězci znak . Ve víceřádkových řetězcích bude každý řádek zpracován samostatně, protože v příchuti VBA Regex tečka (.) odpovídá jakémukoli znaku kromě nového řádku.
Zpracování všech řádků jako jednoho řetězce:
Obecný vzor : char(.
Chcete-li odstranit cokoli za daným znakem, včetně nových řádků, přidá se ke vzoru \n.
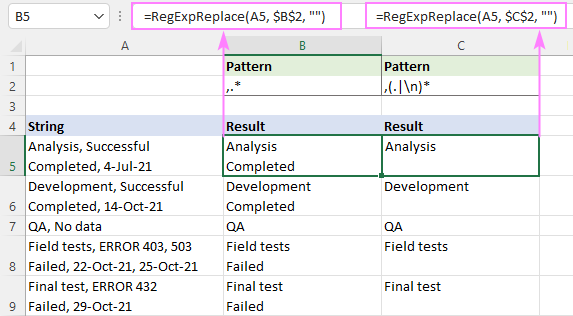
Chcete-li například odstranit text za první čárkou v řetězci, vyzkoušejte tyto regulární výrazy:
Vzor : ,.*
Vzor : ,(.
Na obrázku níže si můžete prohlédnout, jak se výsledky liší.
Regex pro odstranění všeho před mezerou
Při práci s dlouhými řetězci textu je někdy můžete chtít zkrátit odstraněním stejné části informace ve všech buňkách. Níže si probereme dva takové případy.
Odstraňte vše před posledním místem
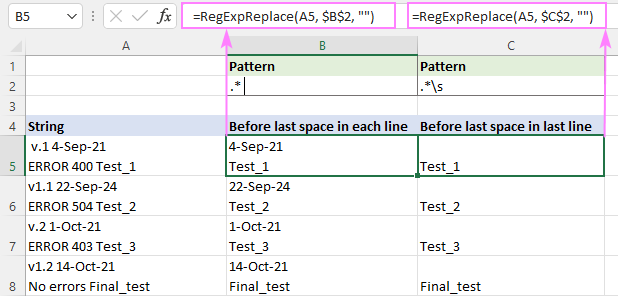
Stejně jako v předchozím příkladu závisí regulární výraz na vašem chápání pojmu "mezera".
Srovnání čehokoli s poslední místo , bude stačit tento regex (uvozovky jsou přidány, aby byla mezera za hvězdičkou patrná).
Vzor : ".* "
Shoda s čímkoli před poslední bílé místo (včetně mezery, tabulátoru, návratu vozíku a nového řádku), použijte tento regulární výraz.
Vzor : .*\s
Rozdíl je patrný zejména u víceřádkových řetězců.
Odstranění všeho před prvním mezerníkem
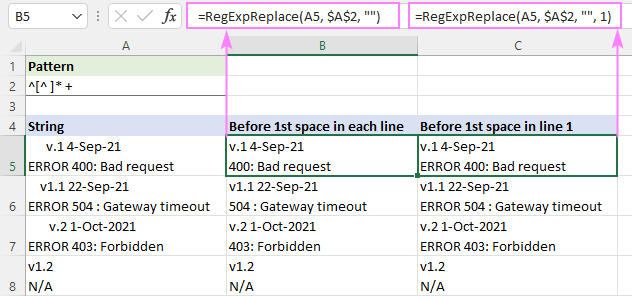
Pro porovnání čehokoli až po první mezeru v řetězci můžete použít tento regulární výraz:
Vzor : ^[^ ]* +
Od začátku řetězce ^ porovnáváme nula nebo více znaků bez mezery [^ ]*, za kterými bezprostředně následuje jedna nebo více mezer " +". Poslední část se přidává, aby se zabránilo případným počátečním mezerám ve výsledcích.
Pro odstranění textu před první mezerou v každém řádku je vzorec zapsán ve výchozím režimu "všechny shody" ( instance_num vynecháno):
=RegExpReplace(A5, "^[^ ]* +", "")
Chcete-li odstranit text před první mezerou v prvním řádku a ponechat všechny ostatní řádky nedotčené, použijte příkaz instance_num je nastaven na hodnotu 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex pro odstranění všeho před znakem
Nejjednodušší způsob, jak odstranit veškerý text před určitým znakem, je použít regex, jako je tento:
Obecný vzor : ^[^char]*char
Přeloženo do lidského jazyka, říká: "od začátku řetězce zakotveného pomocí ^, porovnejte 0 nebo více znaků s výjimkou znak [^char]* až po první výskyt znaku znak .
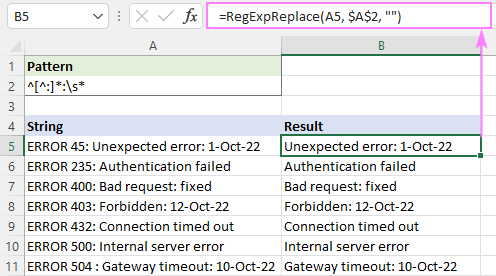
Chcete-li například odstranit veškerý text před první dvojtečkou, použijte tento regulární výraz:
Vzor : ^[^:]*:
Chcete-li se vyhnout úvodním mezerám ve výsledcích, přidejte na konec bílý znak \s*. Ten odstraní vše před první dvojtečkou a ořízne všechny mezery hned za ní:
Vzor : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Tip. Kromě regulárních výrazů má Excel vlastní prostředky pro odstranění textu podle pozice nebo shody. Chcete-li se dozvědět, jak tento úkol provést pomocí nativních vzorců, přečtěte si článek Jak odstranit text před nebo za znakem v aplikaci Excel.
Regex pro odstranění všeho kromě
Chcete-li z řetězce odstranit všechny znaky kromě těch, které chcete zachovat, použijte třídy negovaných znaků.
Například pro odstranění všech znaků kromě malých písmen a teček je regex následující:
Vzor : [^a-z\.]+
Ve skutečnosti bychom se zde mohli obejít bez kvantifikátoru +, protože naše funkce nahrazuje všechny nalezené shody. Kvantifikátor pouze trochu urychluje práci - místo zpracování každého jednotlivého znaku nahrazujete podřetězec.
=RegExpReplace(A5, "[^a-z\.]+", "")
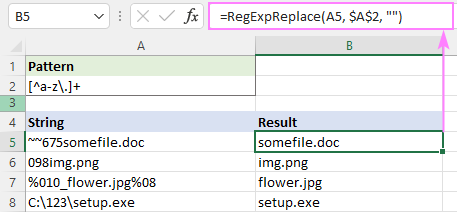
Regex pro odstranění html značek v aplikaci Excel
Nejprve je třeba poznamenat, že HTML není regulární jazyk, takže jeho rozbor pomocí regulárních výrazů není nejlepší způsob. Nicméně regexy mohou rozhodně pomoci odstranit značky z buněk, aby byl soubor dat čistší.
Vzhledem k tomu, že značky html jsou vždy umístěny v hranatých závorkách , můžete je najít pomocí některého z následujících regexů.
Negovaná třída:
Vzor : ]*>
Zde porovnáváme úvodní úhlovou závorku, za kterou následuje nula nebo více výskytů libovolného znaku kromě uzavírací úhlové závorky [^>]* až po nejbližší uzavírací úhlovou závorku.
Líné vyhledávání:
Vzor :
Zde porovnáváme cokoli od první otevírací závorky po první uzavírací závorku. Otazník nutí .* porovnávat co nejméně znaků, dokud nenajde uzavírací závorku.
Ať už si vyberete jakýkoli vzor, výsledek bude naprosto stejný.
Například pro odstranění všech značek html z řetězce A5 a ponechání textu je vzorec následující:
=RegExpReplace(A5, "]*>", "")
Nebo můžete použít líný kvantifikátor, jak je znázorněno na obrázku:
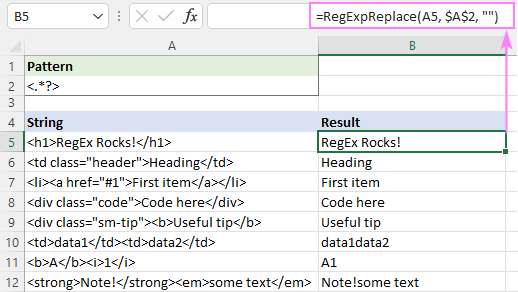
Toto řešení funguje perfektně pro jeden text (řádky 5 - 9). Pro více textů (řádky 10 - 12) je výsledek sporný - texty z různých značek se sloučí do jednoho. Je to správně, nebo ne? Obávám se, že to nelze jednoduše rozhodnout - vše záleží na vašem chápání požadovaného výsledku. Například v B11 se očekává výsledek "A1", zatímco v B10 byste mohli chtít"data1" a "data2" oddělit mezerou.
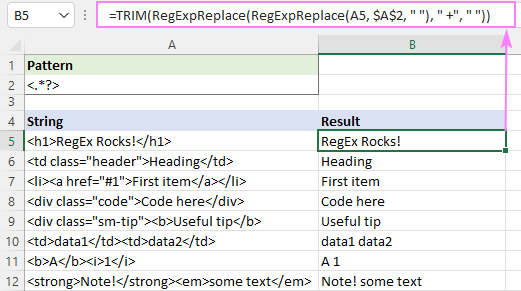
Chcete-li odstranit značky html a oddělit zbývající texty mezerami, můžete postupovat takto:
- Nahradit značky mezerami " ", nikoli prázdnými řetězci:
=RegExpReplace(A5, "]*>", " ") - Zredukujte více mezer na jeden znak mezery:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Ořízněte počáteční a koncové mezery:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
Výsledek bude vypadat asi takto:
Nástroj Ablebits Regex Remove Tool
Pokud jste již měli možnost používat naši sadu Ultimate Suite pro Excel, pravděpodobně jste již objevili nové nástroje Regex, které byly představeny v nedávné verzi. Krása těchto funkcí Regex založených na technologii .NET spočívá v tom, že za prvé podporují plnohodnotnou syntaxi regulárních výrazů bez omezení VBA RegExp a za druhé nevyžadují vkládání žádného kódu VBA do sešitů, protože veškerá integrace kódu je provedena.námi na zadní straně.
Vaším úkolem je sestavit regulární výraz a naservírovat ho funkci :) Ukážu vám, jak to udělat na praktickém příkladu.
Jak odstranit text v závorkách a závorkách pomocí regexu
V dlouhých textových řetězcích jsou méně důležité informace často uzavřeny v [závorkách] a (závorkách). Jak tyto nepodstatné údaje odstranit při zachování všech ostatních údajů?
Ve skutečnosti jsme již vytvořili podobný regex pro mazání html značek, tj. textu v hranatých závorkách. Stejné metody budou samozřejmě fungovat i pro hranaté a kulaté závorky.
Vzor : (\(.*?\))
Trik spočívá v použití líného kvantifikátoru (*?), který odpovídá nejkratšímu možnému podřetězci. První skupina (\(.*?\)) odpovídá čemukoli od úvodní závorky po první uzavírací závorku. Druhá skupina (\[.*?\]) odpovídá čemukoli od úvodní závorky po první uzavírací závorku. Svislá čára
Když je vzor určen, "nakrmíme" jím naši funkci Regex Remove. Zde je návod, jak na to:
- Na Data Ablebits na kartě Text klikněte na tlačítko Nástroje Regex .
Chcete-li získat výsledky jako vzorce, nikoli jako hodnoty, vyberte možnost Vložit jako vzorec zaškrtávacího políčka.
Pro odstranění textu v závorkách z řetězců v A2:A5 nakonfigurujeme nastavení následovně:
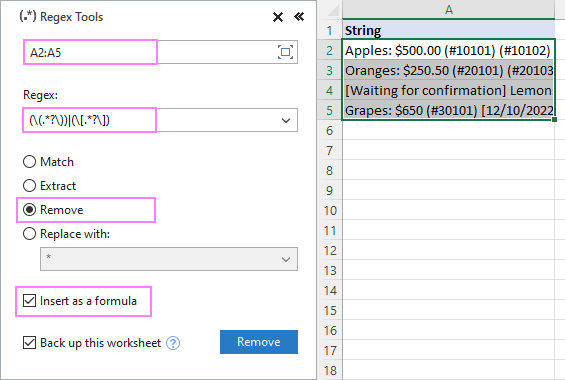
Výsledkem je, že AblebitsRegexRemove se vloží do nového sloupce vedle původních dat.
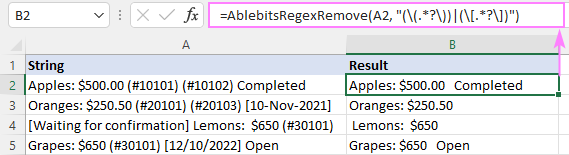
Funkci lze také zadat přímo do buňky pomocí standardní funkce Vložit funkci dialogové okno, kde je zařazen do kategorie AblebitsUDFs .
Jako AblebitsRegexRemove je určena k odstraňování textu, vyžaduje pouze dva argumenty - zdrojový řetězec a regex. Oba parametry lze definovat přímo ve vzorci nebo dodat ve formě odkazů na buňky. V případě potřeby lze tuto vlastní funkci použít společně s některou z nativních funkcí.
Chcete-li například ořezat přebytečné mezery ve výsledných řetězcích, můžete použít funkci TRIM jako obal:
=TRIM(AblebitsRegexRemove(A5, $A$2))
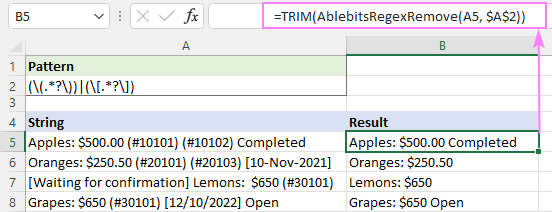
To je návod na odstranění řetězců v Excelu pomocí regulárních výrazů. Děkuji vám za přečtení a těším se na vás na našem blogu příští týden!
Dostupné soubory ke stažení
Odstranění řetězců pomocí regexu - příklady (.xlsm soubor)
Ultimate Suite - zkušební verze (.exe soubor)
