
Sadržaj
Pretpostavimo da želite izbrisati prvi broj reda u nizovima ispod. Svi takvi brojevi počinju znakom hash (#) i sadrže točno 5 znamenki. Dakle, možemo ih identificirati pomoću ovog regularnog izraza:
Uzorak : #\d{5}\b
Granica riječi \b navodi da odgovarajući podniz ne može biti dio većeg niza kao što je #10000001.
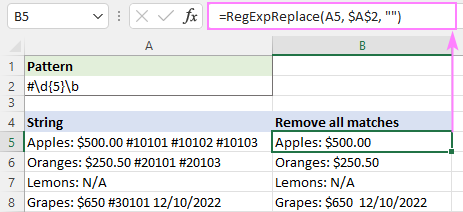
Za uklanjanje svih podudaranja, argument instance_num nije definiran:
=RegExpReplace(A5, "#\d{5}\b", "")
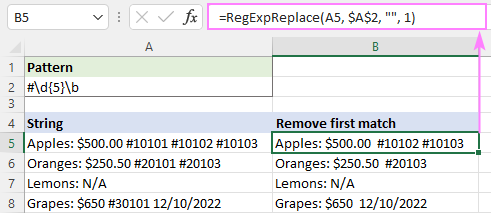
Da bismo iskorijenili samo prvo pojavljivanje, postavili smo argument instance_num na 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex za uklanjanje određenih znakova
Za uklanjanje određenih znakova iz niza, samo zapišite sve neželjene znakove i odvojite ih okomitom crtomsintaksa bez VBA RegExp ograničenja, i drugo, ne zahtijevaju umetanje bilo kakvog VBA koda u vaše radne knjige jer svu integraciju koda obavljamo mi u pozadini.
Vaš je dio posla konstruirati regularni izraz i poslužite ga funkciji :) Pokazat ću vam kako to učiniti na praktičnom primjeru.
Kako ukloniti tekst u zagradama i zagradama pomoću regularnog izraza
U dugim tekstualnim nizovima, manje važne informacije često se nalazi u [zagradama] i (zagradama). Kako ukloniti te nebitne detalje zadržavajući sve ostale podatke?
Zapravo, već smo napravili sličan regularni izraz za brisanje html oznaka, tj. teksta unutar uglastih zagrada. Očito, iste će metode funkcionirati i za uglate i okrugle zagrade.
Uzorak : (\(.*?\))
Jeste li ikada pomislili koliko bi Excel bio moćan kada bi netko mogao obogatiti njegovu alatnu kutiju regularnim izrazima? Ne samo da smo razmišljali, već smo i radili na tome :) A sada možete dodati ovu prekrasnu RegEx funkciju u svoje vlastite radne knjige i brisati podnizove koji odgovaraju uzorku u tren oka!
Prošlog smo tjedna pogledali kako koristiti regularne izraze za zamjenu nizova u Excelu. Za to smo izradili prilagođenu funkciju Regex Replace. Kako se pokazalo, funkcija nadilazi svoju primarnu upotrebu i može ne samo zamijeniti nizove, već ih i ukloniti. Kako je to moglo biti? U smislu Excela, uklanjanje vrijednosti nije ništa drugo nego njezina zamjena praznim nizom, nešto u čemu je naša Regex funkcija vrlo dobra!
VBA RegExp funkcija za uklanjanje podnizova u Excelu
Kao što svi znamo, regularni izrazi nisu podržani u Excelu prema zadanim postavkama. Da biste ih omogućili, morate stvoriti vlastitu korisnički definiranu funkciju. Dobra vijest je da je takva funkcija već napisana, testirana i spremna za korištenje. Sve što trebate učiniti je kopirati ovaj kod, zalijepiti ga u svoj VBA uređivač, a zatim spremiti datoteku kao radnu knjigu s omogućenim makronaredbama (.xlsm).
Funkcija ima sljedeća sintaksa:
RegExpReplace(text, pattern, replacement, [instance_num], [match_case])Prva tri argumenta su obavezna, posljednja dva su izborna.
Gdje:
- Tekst - tekstualni niz za pretraživanjemoguće dok ne pronađe zatvorenu zagradu.
Koji god uzorak odabrali, rezultat će biti apsolutno isti.
Na primjer, da uklonite sve html oznake iz niza u A5 i ostavite tekst, formula je:
=RegExpReplace(A5, "]*>", "")
Ili možete upotrijebiti lijeni kvantifikator kao što je prikazano na snimci zaslona:
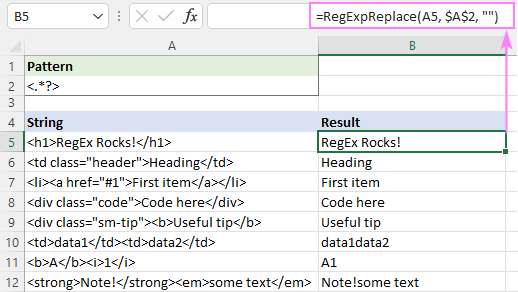
Ovo rješenje savršeno funkcionira za jedan tekst (redovi 5 - 9). Za više tekstova (redovi 10 - 12), rezultati su upitni - tekstovi iz različitih oznaka se spajaju u jednu. Je li to točno ili nije? Bojim se da to nije nešto o čemu se može lako odlučiti - sve ovisi o vašem razumijevanju željenog ishoda. Na primjer, u B11 očekuje se rezultat "A1"; dok u B10 možda želite da "podaci1" i "podaci2" budu odvojeni razmakom.
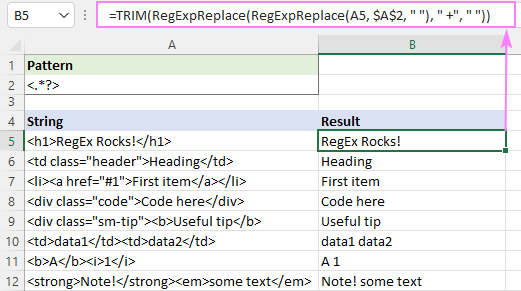
Da biste uklonili html oznake i odvojili preostale tekstove razmacima, možete nastaviti na ovaj način:
- Zamijenite oznake razmacima " ", a ne praznim nizovima:
=RegExpReplace(A5, "]*>", " ") - Smanjite više razmaka na jedan razmak:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Skratite razmake na početku i na kraju:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
Rezultat će izgledati otprilike ovako:
Alat za uklanjanje Ablebits Regex
Ako ste imali priliku koristiti naš Ultimate Suite za Excel, vjerojatno ste već otkrili nove alate za regularne izraze predstavljene u nedavnom izdanju. Ljepota ovih Regex funkcija temeljenih na .NET-u je u tome što one, kao prvo, podržavaju regularne izraze s punim značajkamaopciju Ukloni i pritisnite Ukloni .
Da biste dobili rezultate kao formule, a ne vrijednosti, odaberite potvrdni okvir Umetni kao formulu .
Za uklanjanje teksta unutar zagrada iz nizova u A2:A5, konfiguriramo postavke kako slijedi:
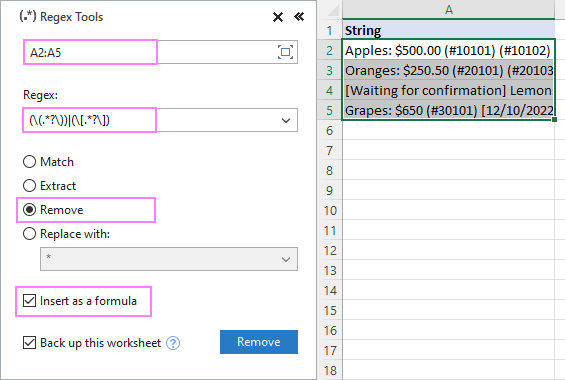
Kao rezultat, funkcija AblebitsRegexRemove umetnuta je u novi stupac pored vaših originalnih podataka.
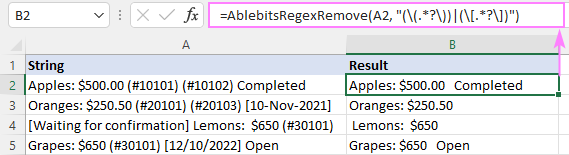
Funkcija se također može unijeti izravno u ćeliju putem standardnog dijaloškog okvira Insert Function , gdje je kategorizirana pod AblebitsUDFs .
Kako je AblebitsRegexRemove dizajniran za uklanjanje teksta, zahtijeva samo dva argumenta - izvorni niz i regularni izraz. Oba se parametra mogu definirati izravno u formuli ili dostaviti u obliku referenci ćelija. Ako je potrebno, ova se prilagođena funkcija može koristiti zajedno s bilo kojom izvornom funkcijom.
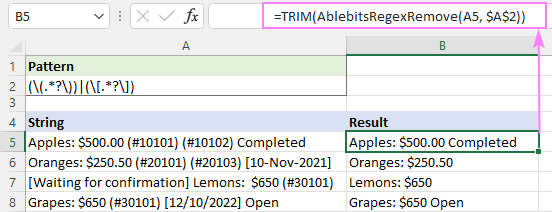
Na primjer, za smanjenje dodatnih razmaka u rezultirajućim nizovima, možete koristiti funkciju TRIM kao omotač:
=TRIM(AblebitsRegexRemove(A5, $A$2))
Evo kako ukloniti nizove u Excelu pomoću regularnih izraza. Zahvaljujem vam na čitanju i radujem se što ćemo vas vidjeti na našem blogu sljedeći tjedan!
Dostupna preuzimanja
Uklonite nizove pomoću regularnog izraza - primjeri (.xlsm datoteka)
Ultimate Suite - probna verzija (.exe datoteka)
in.Za više informacija pogledajte funkciju RegExpReplace.
Savjet. U jednostavnim slučajevima možete ukloniti određene znakove ili riječi iz ćelija pomoću Excel formula. Ali regularni izrazi pružaju mnogo više mogućnosti za to.
Kako ukloniti nizove pomoću regularnih izraza - primjeri
Kao što je gore spomenuto, da biste uklonili dijelove teksta koji odgovaraju uzorku, morate ih zamijeniti s praznim nizom. Dakle, generička formula ima ovaj oblik:
RegExpReplace(text, pattern, "", [instance_num], [match_case])Sljedeći primjeri pokazuju različite implementacije ovog osnovnog koncepta.
Ukloni sva podudaranja ili određena podudaranja
Funkcija RegExpReplace dizajnirana je za pronalaženje svih podnizova koji odgovaraju danom regularnom izrazu. Koje pojavljivanja ukloniti kontrolira 4. izborni argument, pod nazivom instance_num .
Zadana postavka je "sva podudaranja" - kada instance_num operator ulančavanja (&) i tekstualne funkcije kao što su RIGHT, MID i LEFT.
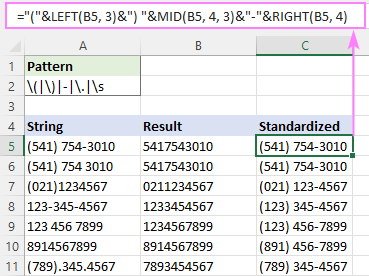
Na primjer, za pisanje svih telefonskih brojeva u formatu (123) 456-7890, formula je:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Gdje je B5 izlaz funkcije RegExpReplace.
Uklonite posebne znakove pomoću regularnog izraza
U jednom od naših vodiča, pogledali smo kako ukloniti neželjene znakove u Excelu pomoću ugrađenih i prilagođenih funkcija. Regularni izrazi uvelike olakšavaju stvari! Umjesto popisa svih znakova za brisanje, samo odredite one koje želite zadržati :)
Uzorak se temelji na negiranim klasama znakova - karet se stavlja unutar klase znakova [^ ] za podudaranje s bilo kojim pojedinačnim znakom NE u zagradama. Kvantifikator + prisiljava ga da uzastopne znakove smatra jednim podudaranjem, tako da se zamjena vrši za odgovarajući podniz, a ne za svaki pojedinačni znak.
Ovisno o vašim potrebama, odaberite jedan od sljedećih regularnih izraza.
Za uklanjanje nealfanumeričkih znakova, tj. svih znakova osim slova i znamenki:
Uzorak : [^0-9a-zA-Z] +
Za brisanje svih znakova osim slova , znamenki i razmaka :
Uzorak : [^0-9a-zA-Z ]+
Za brisanje svih znakova osim slova , znamenki i podvlake , možete koristiti \ W koji označava bilo koji znak koji NIJE alfanumerički znak ilipodvlaka:
Uzorak : \W+
Ako želite zadržati neke druge znakove , npr. interpunkcijskih znakova, stavite ih unutar zagrada.
Na primjer, da uklonite bilo koji znak osim slova, znamenke, točke, zareza ili razmaka, koristite sljedeći regularni izraz:
Uzorak : [^0-9a-zA-Z\., ]+
Ovo uspješno uklanja sve posebne znakove, ali ostaje dodatni razmak.
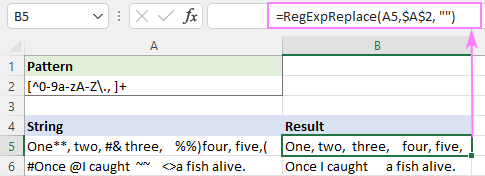
Da biste to popravili, možete ugniježditi gornju funkciju u drugu koja zamjenjuje više razmaka s jednim razmakom.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
Ili jednostavno upotrijebite izvornu funkciju TRIM s istim učinkom :
=TRIM(RegExpReplace(A5, $A$2, ""))
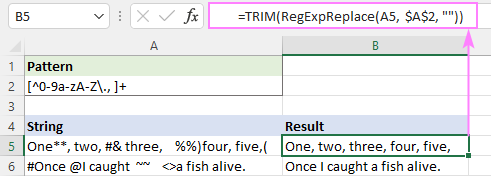
Regularni izraz za uklanjanje nenumeričkih znakova
Da biste izbrisali sve nenumeričke znakove iz niza, možete koristiti ili ovu dugu formulu ili jedan od vrlo jednostavnih regularnih izraza navedenih u nastavku.
Upari bilo koji znak koji NIJE znamenka:
Uzorak : \D+
Uklanjanje nenumeričkih znakova korištenjem negiranih klasa:
Uzorak : [^0-9]+
Uzorak : [^\d] +
Savjet. Ako je vaš cilj ukloniti tekst i preliti preostale brojeve u zasebne ćelije ili ih sve smjestiti u jednu ćeliju odvojenu određenim graničnikom, tada upotrijebite funkciju RegExpExtract kao što je objašnjeno u Kako izvući brojeve iz niza pomoću regularnih izraza.
Regularni izraz za uklanjanje svega nakon razmaka
Da biste izbrisali sve nakon razmaka, koristite ili razmak ( ) iliznak razmaka (\s) za pronalaženje prvog razmaka i .* za podudaranje bilo kojeg znaka nakon njega.
Ako imate nizove od jednog retka koji sadrže samo normalne razmake (vrijednost 32 u 7-bitnom ASCII sustavu) , zapravo nije važno koji od donjih regularnih izraza koristite. U slučaju nizova s više redaka, to čini razliku.
Da biste uklonili sve poslije razmaka , koristite ovaj regularni izraz:
Uzorak : " .*"
=RegExpReplace(A5, " .*", "")
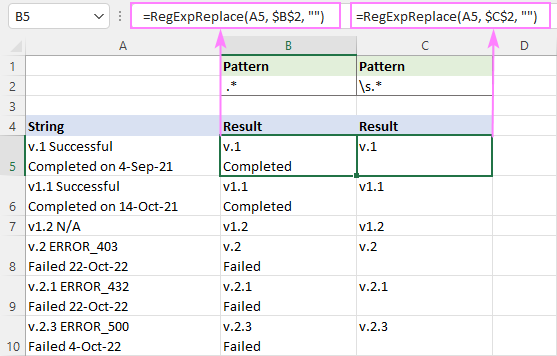
Ova formula će ukloniti sve nakon prvog razmaka u svakom retku . Kako bi se rezultati ispravno prikazali, obavezno uključite Prijelom teksta.
Da biste uklonili sve poslije razmaka (uključujući razmak, tabulator, povratak na početak i novi red), regularni izraz je:
Uzorak : \s.*
=RegExpReplace(A5, "\s.*", "")
Zato što \s odgovara nekoliko različitih vrsta razmaka uključujući novi red (\n), ova formula briše sve nakon prvog razmaka u ćeliji, bez obzira koliko redaka ima u njoj.
Regex za uklanjanje teksta nakon određenog znak
Koristeći metode iz prethodnog primjera, možete izbrisati tekst nakon bilo kojeg znaka koji navedete.
Za obradu svakog retka zasebno:
Generički uzorak : char.*
U jednolinijskim nizovima ovo će ukloniti sve nakon char . U nizovima s više redaka, svaki će se redak pojedinačno obraditi jer u VBA Regex okusu točka (.) odgovara bilo kojem znaku osim novogpočetak niza ^, podudaramo nula ili više znakova koji nisu razmaci [^ ]* nakon kojih odmah slijedi jedan ili više razmaka " +". Posljednji dio dodaje se kako bi se spriječili potencijalni vodeći razmaci u rezultatima.
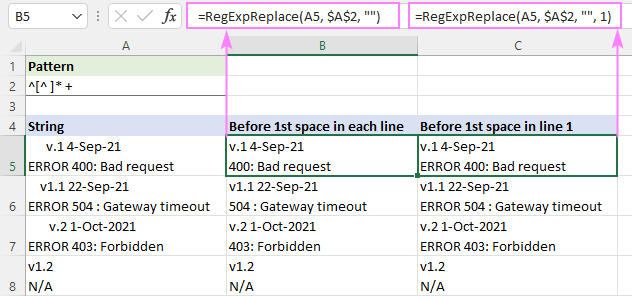
Za uklanjanje teksta prije prvog razmaka u svakom retku, formula se piše u zadanom načinu "sva podudaranja" ( instance_num izostavljeno):
=RegExpReplace(A5, "^[^ ]* +", "")
Za brisanje teksta prije prvog razmaka u prvom retku, a sve druge retke ostaviti netaknutima, argument instance_num postavljen je na 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regularni izraz za uklanjanje svega prije znaka
Najlakši način da uklonite sav tekst prije određenog znaka je pomoću regularnog izraza ovako:
Generički uzorak : ^[^char]*char
Prevedeno na ljudski jezik, kaže: "od početka niza usidren od strane ^ , odgovaraju 0 ili više znakova osim char [^char]* do prvog pojavljivanja char .
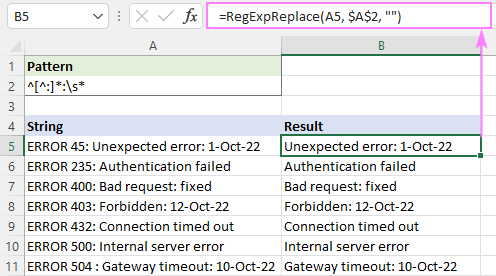
Na primjer, za brisanje cijelog teksta prije prve dvotočke , koristite ovaj regularni izraz:
Uzorak : ^[^:]*:
Da biste izbjegli vodeće razmake u rezultatima, dodajte razmak \s* u kraj. Ovo će ukloniti sve g prije prve dvotočke i izrežite sve razmake odmah iza:
Uzorak : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Savjet. Osim regularnih izraza, Excel ima vlastita sredstva za uklanjanje teksta prema položaju ili podudaranju. Da biste naučili kako izvršiti zadatak izvornim formulama,pogledajte Kako ukloniti tekst ispred ili iza znaka u Excelu.
Regularni izraz za uklanjanje svega osim
Da biste uklonili sve znakove iz niza osim onih koje želite zadržati, upotrijebite klase negiranih znakova.
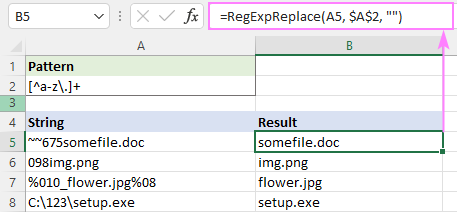
Na primjer, da biste uklonili sve znakove osim malih slova i točkica, regularni izraz je:
Uzorak : [^a-z\.]+
Zapravo, ovdje bismo mogli bez kvantifikatora + jer naša funkcija zamjenjuje sve pronađene utakmice. Kvantifikator ga samo čini malo bržim - umjesto rukovanja svakim pojedinačnim znakom, zamjenjujete podniz.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex za uklanjanje html oznaka u Excelu
Kao prvo, treba napomenuti da HTML nije regularni jezik, tako da njegovo analiziranje korištenjem regularnih izraza nije najbolji način. Ipak, regularni izrazi definitivno mogu pomoći u uklanjanju oznaka iz vaših ćelija kako bi vaš skup podataka bio čišći.
S obzirom da se html oznake uvijek stavljaju unutar uglastih zagrada, možete ih pronaći pomoću jednog od sljedećih regularnih izraza.
Negirana klasa:
Uzorak : ]*>
Ovdje spajamo početnu uglastu zagradu, iza koje slijedi nula ili više pojavljivanja bilo kojeg znaka osim zatvorena uglasta zagrada [^>]* do najbliže zatvorene uglate zagrade.
Lijeno pretraživanje:
Uzorak :
Ovdje se podudaramo sve od prve otvarajuće zagrade do prve zatvarajuće zagrade. Upitnik prisiljava .* da odgovara samo nekoliko znakovalinija.
Za obradu svih linija kao jednog niza:
Generički uzorak : char(.
