
Satura rādītājs
Vai esat kādreiz domājuši, cik spēcīgs Excel būtu, ja kāds varētu bagātināt savu rīku komplektu ar regulārām izteiksmēm? Mēs ne tikai domājām, bet arī strādājām pie tā :) Un tagad jūs varat pievienot šo brīnišķīgo RegEx funkciju savām darbgrāmatām un izdzēst apakšvirknes, kas atbilst rakstam, bez laika!
Pagājušajā nedēļā mēs aplūkojām, kā izmantot regulāras izteiksmes, lai aizvietotu virknes programmā Excel. Šim nolūkam mēs izveidojām pielāgotu funkciju Regex Replace. Kā izrādījās, šī funkcija pārsniedz tās primāro lietojumu un var ne tikai aizstāt virknes, bet arī noņemt tās. Kā tas varētu būt? Runājot par Excel, vērtības noņemšana nav nekas cits kā tās aizstāšana ar tukšu virkni, kaut kas, ko mūsu Regex funkcija irļoti labi!
VBA RegExp funkcija, lai noņemtu apakšrindas programmā Excel
Kā mēs visi zinām, regulārās izteiksmes pēc noklusējuma programmā Excel netiek atbalstītas. Lai tās iespējotu, jums ir jāizveido sava lietotāja definēta funkcija. Labā ziņa ir tā, ka šāda funkcija jau ir uzrakstīta, pārbaudīta un gatava lietošanai. Viss, kas jums jādara, ir nokopēt šo kodu, ielīmēt to savā VBA redaktorā un pēc tam saglabāt savu failu kā. darbgrāmata ar iespējotu makru (.xlsm).
Funkcijai ir šāda sintakse:
RegExpReplace(teksts, modelis, aizvietošana, [instance_num], [match_case])Pirmie trīs argumenti ir obligāti, bet pēdējie divi nav obligāti.
Kur:
- Teksts - teksta virkne, kurā jāveic meklēšana.
- Modelis - regulārā izteiksme, pēc kuras meklēt.
- Nomaiņa - tekstu, ar ko aizstāt. dzēst apakšvirsrakstus atbilst šablonam, izmantojiet tukša virkne ("") nomaiņai.
- Instance_num (nav obligāts) - aizstājamais gadījums. Ja netiek norādīts, tiek aizstāti visi atrastie sakritības gadījumi (noklusējuma iestatījums).
- Match_case (nav obligāts) - logaritma vērtība, kas norāda, vai teksta burtu un atbilžu gadījumā lietot TRUE (noklusējuma iestatījums); ja teksta burtu un atbilžu gadījumā burtu un atbilžu gadījumā burtu un atbilžu gadījumā nav jūtama burtu un atbilžu gadījumā - FALSE.
Plašāku informāciju skatiet sadaļā RegExpReplace funkcija.
Padoms. Vienkāršos gadījumos varat no šūnām noņemt konkrētas rakstzīmes vai vārdus, izmantojot Excel formulas. Taču regulārās izteiksmes nodrošina daudz vairāk iespēju.
Kā noņemt virknes, izmantojot regulārās izteiksmes - piemēri
Kā minēts iepriekš, lai noņemtu teksta daļas, kas atbilst šablonam, tās jāaizstāj ar tukšu virkni. Tātad vispārīgā formula ir šāda:
RegExpReplace(teksts, modelis, "", [instance_num], [match_case])Zemāk dotajos piemēros ir parādītas dažādas šīs pamatkoncepcijas implementācijas.
Dzēst visus vai konkrētus sakritības variantus
RegExpReplace funkcija ir paredzēta, lai atrastu visas apakšvirknes, kas atbilst dotajam regeksam. To, kuri gadījumi tiks izņemti, nosaka 4. izvēles arguments ar nosaukumu instance_num .
Noklusējuma iestatījums ir "visas spēles" - kad instance_num arguments ir izlaists, tiek dzēsti visi atrastie sakritības gadījumi. Lai dzēstu konkrētu sakritību, norādiet gadījuma numuru.
Pieņemsim, ka tālāk redzamajās virknēs vēlaties izdzēst pirmās kārtas numuru. Visi šādi numuri sākas ar hash zīmi (#) un satur tieši 5 ciparus. Tātad mēs tos varam identificēt, izmantojot šo regeksi:
Modelis : #\d{5}\b
Vārda robeža \b norāda, ka atbilstošā apakšvirkne nevar būt daļa no lielākas virknes, piemēram, #10000001.
Lai noņemtu visas sakritības, instance_num arguments nav definēts:
=RegExpReplace(A5, "#\d{5}\b", "")
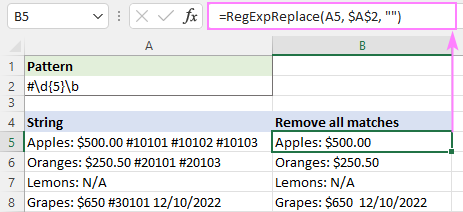
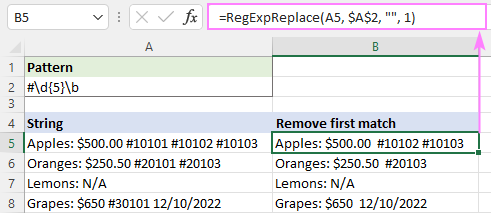
Lai iznīdētu tikai pirmo gadījumu, mēs iestatām instance_num argumentu uz 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex, lai noņemtu noteiktas rakstzīmes
Lai no virknes izņemtu noteiktas rakstzīmes, vienkārši ierakstiet visas nevēlamās rakstzīmes un atdaliet tās ar vertikālu svītru.
Piemēram, lai standartizētu dažādos formātos rakstītus tālruņa numurus, vispirms jāatbrīvojas no specifiskām rakstzīmēm, piemēram, iekavām, defisēm, punktiem un baltajiem laukumiem.
Modelis : \(
=RegExpReplace(A5, "\(
Šīs operācijas rezultāts ir 10 ciparu skaitlis, piemēram, "1234567890".
Ērtības labad regekss var tikt ievadīts atsevišķā šūnā un atsaukties uz šo šūnu, izmantojot absolūtu atsauci, piemēram, $A$2:
=RegExpReplace(A5, $A$2, "")
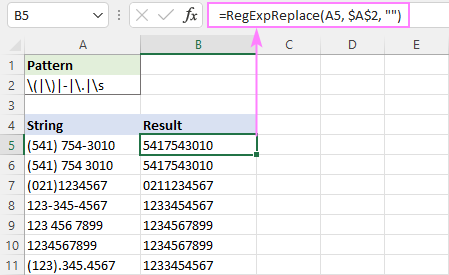
Pēc tam formatējumu var standartizēt pēc saviem ieskatiem, izmantojot apvienošanas operatoru (&) un teksta funkcijas, piemēram, RIGHT, MID un LEFT.
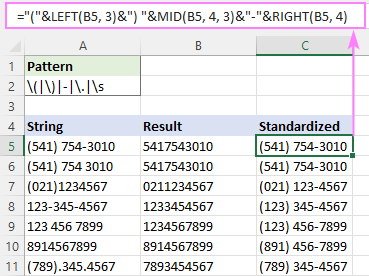
Piemēram, lai visus tālruņa numurus ierakstītu formātā (123) 456-7890, formula ir šāda:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
kur B5 ir RegExpReplace funkcijas rezultāts.
Īpašo rakstzīmju noņemšana, izmantojot regex
Vienā no mūsu pamācībām mēs aplūkojām, kā no Excel dzēst nevēlamas rakstzīmes, izmantojot iebūvētās un pielāgotās funkcijas. Regulārās izteiksmes atvieglo darbu! Tā vietā, lai uzskaitītu visas dzēšamās rakstzīmes, vienkārši norādiet tās, kuras vēlaties saglabāt :)
Modeļa pamatā ir noliegtās rakstzīmju klases - caret tiek ievietots rakstzīmju klases [^ ] iekšpusē, lai atbilstu jebkurai atsevišķai rakstzīmei, kas NAV iekavās. Kvantifikators + liek uzskatīt secīgas rakstzīmes par vienu atbilstību, lai aizstāšana tiktu veikta atbilstošajai apakšrinkai, nevis katrai atsevišķai rakstzīmei.
Atkarībā no savām vajadzībām izvēlieties vienu no šādām regeksēm.
Lai noņemtu ar burtiem un cipariem nesaistīti rakstzīmes, t. i., visas rakstzīmes, izņemot burtus un ciparus:
Modelis : [^0-9a-zA-Z]+
Visu rakstzīmju attīrīšana izņemot burtus , cipari un telpas :
Modelis : [^0-9a-zA-Z ]+
Visu rakstzīmju dzēšana izņemot burtus , cipari un pasvītrojums , varat izmantot \W, kas apzīmē jebkuru rakstzīmi, kas NAV burtciparu rakstzīme vai pasvītrojums:
Modelis : \W+
Ja vēlaties saglabāt dažas citas rakstzīmes piemēram, pieturzīmes, ievietojiet tās iekavās.
Piemēram, lai atņemtu jebkuru rakstzīmi, kas nav burts, cipars, punkts, komats vai atstarpe, izmantojiet šādu regeksus:
Modelis : [^0-9a-zA-Z\., ]+
Tas veiksmīgi novērš visas īpašās rakstzīmes, taču paliek papildu baltās atstarpes.
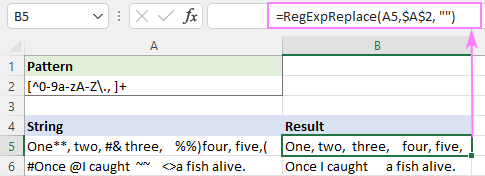
Lai to atrisinātu, iepriekš minēto funkciju var ievietot citā funkcijā, kas vairākas atstarpes aizstāj ar vienu atstarpes rakstzīmi.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
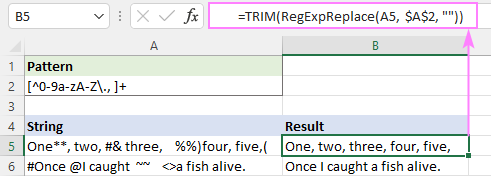
Vai arī vienkārši izmantojiet vietējo TRIM funkciju ar tādu pašu efektu:
=TRIM(RegExpReplace(A5, $A$2, ""))
Regekss, lai noņemtu rakstzīmes, kas nav ciparu zīmes
Lai virknē dzēstu visas zīmes, kas nav ciparu zīmes, varat izmantot šo garo formulu vai kādu no tālāk uzskaitītajām ļoti vienkāršajām regeksēm.
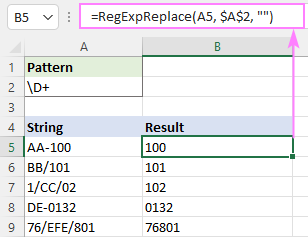
Atbilst jebkurai rakstzīmei, kas NAV cipars:
Modelis : \D+
Numura zīmes, kas nav ciparu zīmes, tiek atdalītas, izmantojot noliegtās klases:
Modelis : [^0-9]+
Modelis : [^\d]+
Padoms. Ja jūsu mērķis ir noņemt tekstu un pārējos skaitļus izliet atsevišķās šūnās vai ievietot tos visus vienā šūnā, atdalot ar noteiktu norobežotāju, izmantojiet funkciju RegExpExtract, kā paskaidrots sadaļā Kā izvilkt skaitļus no virknes, izmantojot regulārās izteiksmes.
Regekss, lai noņemtu visu, kas ir aiz atstarpes
Lai izdzēstu visu, kas atrodas aiz atstarpes, izmantojiet atstarpes ( ) vai baltās atstarpes (\s) rakstzīmi, lai atrastu pirmo atstarpi, un .*, lai saskaņotu visas rakstzīmes pēc tās.
Ja jums ir vienrindu virknes, kas satur tikai parastās atstarpes (vērtība 32 7 bitu ASCII sistēmā), nav nozīmes, kuru no turpmāk minētajiem regeksiem izmantot. Ja ir daudzrindu virknes, tam ir nozīme.
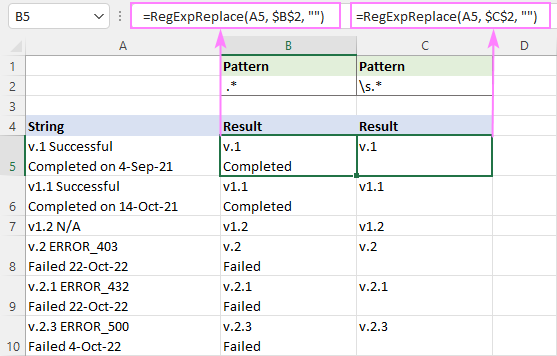
Lai noņemtu visu pēc atstarpes , izmantojiet šo regekss:
Modelis : " .*"
=RegExpReplace(A5, " .*", "")
Šī formula noņems visu, kas atrodas pēc pirmās atstarpes vienskaitlī katra līnija . Lai rezultāti tiktu parādīti pareizi, pārliecinieties, vai ir ieslēgta opcija Wrap Text .
Noņemt visu pēc baltās atstarpes (ieskaitot atstarpi, tabulatoru, atgriezenisko rindiņu un jaunu rindu), regekss ir šāds:
Modelis : \s.*
=RegExpReplace(A5, "\s.*", "")
Tā kā \s atbilst vairākiem dažādiem baltās atstarpes tipiem, tostarp jauna līnija (\n), šī formula dzēš visu, kas atrodas aiz pirmās atstarpes šūnā, neatkarīgi no tā, cik rindu tajā ir.
Regex, lai noņemtu tekstu pēc konkrētas rakstzīmes
Izmantojot iepriekšējā piemērā aprakstītās metodes, varat izdzēst tekstu pēc jebkuras norādītās rakstzīmes.
Lai apstrādātu katru rindu atsevišķi:
Vispārīgais modelis : char.*
Vienrindas virknēs tiks noņemts viss, kas atrodas pēc char . Daudzrindu virknēs katra rinda tiks apstrādāta atsevišķi, jo VBA Regex garšā punkts (.) atbilst jebkurai rakstzīmei, izņemot jaunu rindu.
Visu rindu apstrāde kā vienas rindas:
Vispārīgais modelis : char(.
Lai dzēstu visu, kas atrodas aiz dotās rakstzīmes, tostarp jaunas rindas, rakstzīmei tiek pievienots \n.
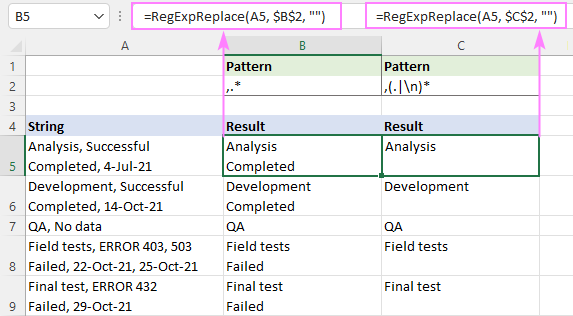
Piemēram, lai dzēstu tekstu pēc pirmā komata virknē, izmēģiniet šīs regulārās izteiksmes:
Modelis : ,.*
Modelis : ,(.
Tālāk redzamajā ekrānšāviņas attēlā varat aplūkot, kā atšķiras rezultāti.
Regekss, lai noņemtu visu, kas atrodas pirms atstarpes
Strādājot ar garām teksta virknēm, dažkārt var būt nepieciešams tās saīsināt, visās šūnās atdalot vienu un to pašu informācijas daļu. Tālāk mēs aplūkosim divus šādus gadījumus.
Noņemiet visu, kas atrodas pirms pēdējās atstarpes
Tāpat kā iepriekšējā piemērā, regulārā izteiksme ir atkarīga no jūsu izpratnes par "atstarpi".
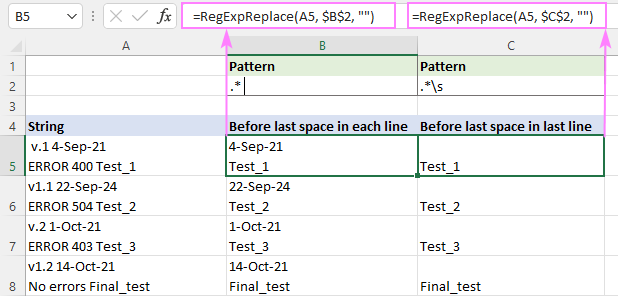
Lai saskaņotu jebko līdz pēdējā vieta (pēdiņas ir pievienotas, lai pēc zvaigznītes būtu pamanāma atstarpe).
Modelis : ".* "
Lai saskaņotu visu, kas atrodas pirms pēdējais baltais laukums (ieskaitot atstarpi, tabulatoru, atgriezenisko rindiņu un jaunu rindu), izmantojiet šo regulāro izteiksmi.
Modelis : .*\s
Atšķirība ir īpaši jūtama daudzrindu virknēs.
Noņemiet visu, kas atrodas pirms pirmās atstarpes
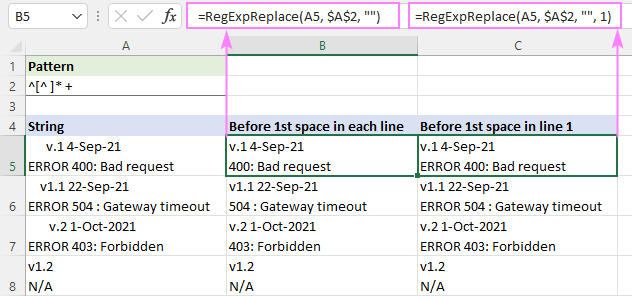
Lai virknē saskaņotu visu līdz pat pirmajai atstarpītei, varat izmantot šo regulāro izteiksmi:
Modelis : ^[^ ]* +
Sākot no virknes ^, tiek atlasītas nulle vai vairākas zīmes bez atstarpes [^ ]*, kurām tūlīt aiz tām seko viena vai vairākas atstarpes " +". Pēdējā daļa tiek pievienota, lai novērstu iespējamās sākuma atstarpes rezultātos.
Lai noņemtu tekstu pirms pirmās atstarpes katrā rindā, formula tiek rakstīta noklusējuma režīmā "visas atbilstības" ( instance_num izlaists):
=RegExpReplace(A5, "^[^ ]* +", "")
Lai dzēstu tekstu pirms pirmās atstarpes pirmajā rindā un visas pārējās rindas saglabātu neskartas, ir jāizmanto instance_num arguments ir iestatīts uz 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex, lai noņemtu visu, kas atrodas pirms rakstzīmes
Visvienkāršākais veids, kā noņemt visu tekstu pirms konkrētas rakstzīmes, ir, izmantojot šādu regekses formulējumu:
Vispārīgais modelis : ^[^[^char]*char
Tulkojot cilvēciskā valodā, tajā teikts: "no virknes, kas sākas ar ^, saskaņojiet 0 vai vairāk rakstzīmju, izņemot char [^char]* līdz pirmajam ierakstam char .
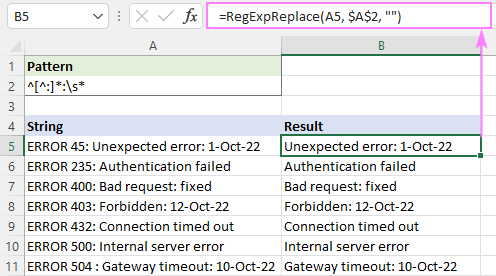
Piemēram, lai dzēstu visu tekstu pirms pirmā divstūra, izmantojiet šo regulāro izteiksmi:
Modelis : ^[^:]*:
Lai izvairītos no atstarpēm rezultātos, beigās pievienojiet baltās atstarpes rakstzīmi \s*. Tā tiks noņemts viss pirms pirmā divstūra un nogrieztas atstarpes uzreiz pēc tā:
Modelis : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Padoms. Papildus regulārajām izteiksmes formām Excel ir arī savi līdzekļi teksta noņemšanai pēc pozīcijas vai sakritības. Lai uzzinātu, kā veikt šo uzdevumu, izmantojot vietējās formulas, skatiet sadaļu Kā noņemt tekstu pirms vai pēc rakstzīmes programmā Excel.
Regex, lai noņemtu visu, izņemot
Lai dzēstu no virknes visas rakstzīmes, izņemot tās, kuras vēlaties saglabāt, izmantojiet noliegto rakstzīmju klases.
Piemēram, lai noņemtu visas rakstzīmes, izņemot mazos burtus un punktus, regekss ir šāds:
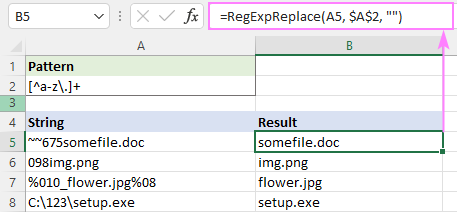
Modelis : [^a-z\.]+
Patiesībā mēs šeit varētu iztikt arī bez kvantifikatora +, jo mūsu funkcija aizvieto visus atrastos sakritības simbolus. Kvantifikators tikai padara to nedaudz ātrāku - tā vietā, lai apstrādātu katru atsevišķu rakstzīmi, jūs aizstāt apakšrindu.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex, lai noņemtu html tagus programmā Excel
Vispirms jāatzīmē, ka HTML nav regulārā valoda, tāpēc tās analīze, izmantojot regulārās izteiksmes, nav labākais veids. Tomēr regekses noteikti var palīdzēt noņemt tagus no šūnām, lai datu kopa būtu tīrāka.
Ņemot vērā, ka html tagus vienmēr ievieto leņķa iekavās, tos var atrast, izmantojot kādu no šādām regeksēm.
Noliegtā klase:
Modelis : ]*>
Šajā gadījumā tiek izmantots sākuma leņķa iekavs, kam seko nulle vai vairāk jebkuru rakstzīmju, izņemot aizvēršanas leņķa iekavs [^>]*, līdz tuvākajam aizvēršanas leņķa iekavam.
Lēna meklēšana:
Modelis :
Šajā gadījumā tiek saskaņots viss, sākot no pirmā sākuma iekavās līdz pirmajam aizvēršanas iekavām. Jautājuma zīme liek .* saskaņot pēc iespējas mazāk rakstzīmju, līdz tiek atrasta aizvēršanas iekava.
Neatkarīgi no tā, kādu modeli izvēlaties, rezultāts būs pilnīgi vienāds.
Piemēram, lai no A5 rindas noņemtu visas html birkas un atstātu tekstu, formula ir šāda:
=RegExpReplace(A5, "]*>", "")
Varat arī izmantot slinko kvantifikatoru, kā parādīts ekrānšāviņā:
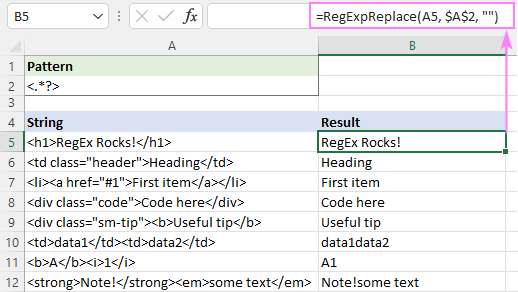
Šis risinājums lieliski darbojas viena teksta gadījumā (5.-9. rinda). Vairāku tekstu gadījumā (10.-12. rinda) rezultāti ir apšaubāmi - dažādu tagu teksti tiek apvienoti vienā. Vai tas ir pareizi vai nē? Baidos, ka to nevar viegli izlemt - viss ir atkarīgs no jūsu izpratnes par vēlamo rezultātu. Piemēram, B11 ir gaidāms rezultāts "A1", bet B10 jūs, iespējams, vēlaties, lai rezultāts būtu "A1"."data1" un "data2" jāatdala ar atstarpi.
Lai noņemtu html tagus un atlikušos tekstus atdalītu ar atstarpēm, varat rīkoties šādi:
- Aizstāt tagus ar atstarpēm " ", nevis tukšām virknēm:
=RegExpReplace(A5, "]*>", " ") - Samaziniet vairākas atstarpes līdz vienai atstarpes rakstzīmei:
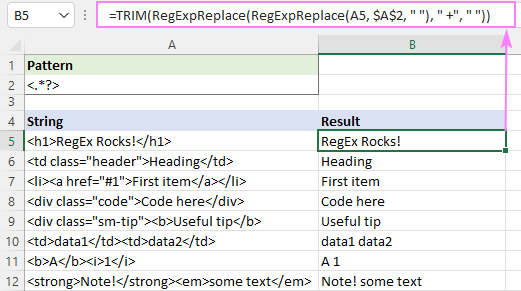
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Apgrieziet priekšējās un aizmugurējās atstarpes:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ")))
Rezultāts izskatīsies apmēram šādi:
Ablebits Regex noņemšanas rīks
Ja jums ir bijusi iespēja izmantot mūsu Excel lietojumprogrammu komplektu Ultimate Suite, jūs, iespējams, jau esat atklājis jaunos Regex rīkus, kas ieviesti ar neseno versiju. Šo uz .NET balstīto Regex funkciju skaistums ir tas, ka tās, pirmkārt, atbalsta pilnvērtīgu regulārās izteiksmes sintaksi bez VBA RegExp ierobežojumiem un, otrkārt, tām nav nepieciešams ievietot VBA kodu darbgrāmatā, jo visa koda integrācija tiek veikta.mēs to veicam aizmugurē.
Jūsu uzdevums ir izveidot regulāru izteiksmi un iesniegt to funkcijai :) Ļaujiet man parādīt, kā to izdarīt praktiskā piemērā.
Kā noņemt tekstu iekavās un iekavās, izmantojot regex
Garās teksta virknēs mazāk svarīga informācija bieži vien ir ietverta [iekavās] un (iekavās). Kā noņemt šo nebūtisko informāciju, saglabājot visus pārējos datus?
Patiesībā mēs jau esam izveidojuši līdzīgu regeksi html tagu dzēšanai, t. i., teksta dzēšanai leņķa iekavās. Protams, tās pašas metodes darbosies arī kvadrātiekavās un apaļajās iekavās.
Modelis : (\(.*?\))
Triks ir izmantot slinko kvantifikatoru (*?), lai saskaņotu iespējami īsāko apakšrindu. Pirmā grupa (\(.*?\)) saskaņo visu, sākot no sākuma iekavām līdz pirmajai noslēdzošajai iekavai. Otrā grupa (\[.*?\]) saskaņo visu, sākot no sākuma iekavām līdz pirmajai noslēdzošajai iekavai. Vertikālā josla
Kad modelis ir noteikts, "padosim" to mūsu Regex Remove funkcijai. Lūk, kā to izdarīt:
- Par Ablebits dati cilnē Teksts grupu, noklikšķiniet uz Regekses rīki .
Lai iegūtu rezultātus formulu, nevis vērtību veidā, atlasiet vienumu Ievietot kā formulu izvēles rūtiņu.
Lai no A2:A5 virknēm noņemtu tekstu iekavās, konfigurējam iestatījumus šādi:
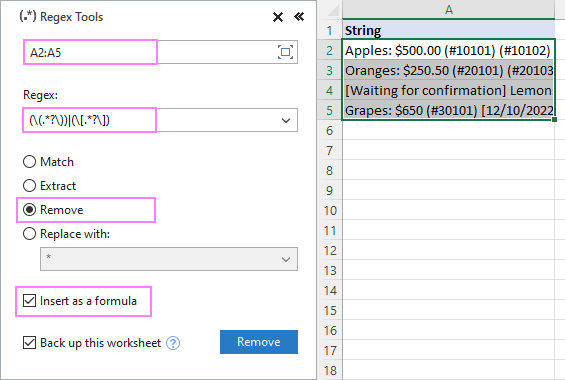
Rezultātā AblebitsRegexRemove funkcija tiek ievietota jaunā slejā blakus sākotnējiem datiem.
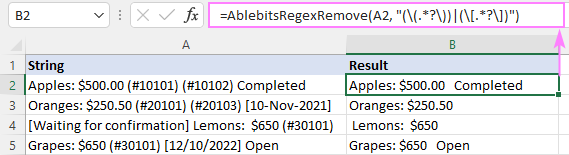
Funkciju var ievadīt arī tieši šūnā, izmantojot standarta Ievietot funkciju dialoglodziņā, kur tas ir iekļauts kategorijā AblebitsUDFs .
Kā AblebitsRegexRemove ir paredzēta teksta noņemšanai, un tai ir nepieciešami tikai divi argumenti - avota virkne un regekss. Abus parametrus var definēt tieši formulā vai sniegt kā atsauces uz šūnām. Ja nepieciešams, šo pielāgoto funkciju var izmantot kopā ar jebkuru vietējo funkciju.
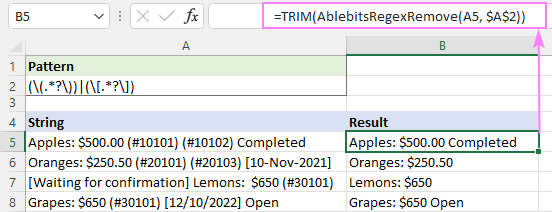
Piemēram, lai izgrieztu papildu atstarpes iegūtajās virknēs, varat izmantot TRIM funkciju kā apvalku:
=TRIM(AblebitsRegexRemove(A5, $A$2))
Tas ir veids, kā noņemt virknes programmā Excel, izmantojot regulārās izteiksmes. Paldies, ka izlasījāt, un ceru jūs redzēt mūsu blogā nākamnedēļ!
Pieejamās lejupielādes
Dzēst virknes, izmantojot regex - piemēri (.xlsm fails)
Ultimate Suite - izmēģinājuma versija (.exe fails)
