
Tartalomjegyzék
Gondoltál már arra, milyen erős lenne az Excel, ha valaki szabályos kifejezésekkel gazdagítaná az eszköztárát? Mi nem csak gondoltunk rá, hanem dolgoztunk is rajta :) És most már ezt a csodálatos RegEx funkciót hozzáadhatod a saját munkafüzeteidhez, és pillanatok alatt kitörölheted a mintának megfelelő részláncokat!
Múlt héten azt néztük meg, hogyan használhatunk reguláris kifejezéseket karakterláncok cseréjére az Excelben. Ehhez létrehoztunk egy saját Regex Replace függvényt. Mint kiderült, a függvény túlmutat az elsődleges felhasználásán, és nem csak karakterláncokat tud helyettesíteni, hanem el is tudja távolítani azokat. Hogyan lehetséges ez? Az Excel szempontjából egy érték eltávolítása nem más, mint egy üres karakterlánccal való helyettesítése, amit a Regex függvényünknagyon jó!
VBA RegExp függvény az Excelben lévő részláncok eltávolításához
Mint tudjuk, a reguláris kifejezések alapértelmezés szerint nem támogatottak az Excelben. Ahhoz, hogy engedélyezze őket, saját, felhasználó által definiált függvényt kell létrehoznia. A jó hír az, hogy egy ilyen függvény már meg van írva, tesztelve és készen áll a használatra. Csak annyit kell tennie, hogy bemásolja ezt a kódot, beilleszti a VBA-szerkesztőjébe, majd elmenti a fájlját makroképes munkafüzet (.xlsm).
A függvény szintaxisa a következő:
RegExpReplace(text, pattern, replacement, [instance_num], [match_case])Az első három argumentum kötelező, az utolsó kettő opcionális.
Hol:
- Szöveg - a keresendő szöveges karakterlánc.
- Mintázat - a keresendő reguláris kifejezés.
- Csere - a szöveget, amellyel helyettesíteni kell. To részláncok eltávolítása a mintának megfelelő, használjon egy üres karakterlánc ("") a cseréhez.
- Instance_num (opcionális) - a kicserélendő példány. Ha elhagyja, az összes talált egyezést kicseréli a rendszer (alapértelmezett).
- Match_case (opcionális) - egy bóluszi érték, amely azt jelzi, hogy a szöveg nagy- és kisbetűinek egyezése vagy figyelmen kívül hagyása esetén használjuk a TRUE értéket (alapértelmezett); a nagy- és kisbetűket nem figyelembe vevő esetben a FALSE értéket.
További információért lásd a RegExpReplace funkciót.
Tipp. Egyszerű esetekben Excel-képletekkel eltávolíthat bizonyos karaktereket vagy szavakat a cellákból. A reguláris kifejezések azonban sokkal több lehetőséget biztosítanak erre.
Hogyan távolítsunk el karakterláncokat reguláris kifejezésekkel - példák
Mint fentebb említettük, a mintának megfelelő szövegrészek eltávolításához egy üres karakterlánccal kell helyettesíteni őket. Tehát egy általános formula a következő formát ölti:
RegExpReplace(text, pattern, "", [instance_num], [match_case])Az alábbi példák ennek az alapkoncepciónak a különböző megvalósításait mutatják be.
Az összes találat vagy egy adott találat eltávolítása
A RegExpReplace függvény célja, hogy megtalálja az összes olyan részláncot, amely megfelel egy adott regexnek. Azt, hogy mely előfordulásokat távolítsa el, a 4. opcionális argumentum határozza meg, amelynek neve instance_num .
Az alapértelmezett beállítás az "összes egyezés" - amikor a instance_num argumentum elhagyása esetén az összes talált találat törlődik. Egy adott találat törléséhez adja meg a példányszámot.
Tegyük fel, hogy az alábbi karakterláncokból az első sorszámot szeretnénk törölni. Minden ilyen szám hash-jel (#) kezdetű és pontosan 5 számjegyet tartalmaz. Így a regex segítségével azonosíthatjuk őket:
Mintázat : #\d{5}\b
A szóhatár \b azt határozza meg, hogy a megfelelő részlánc nem lehet része egy nagyobb karakterláncnak, például a #10000001-nek.
Az összes találat eltávolításához a instance_num argumentum nincs definiálva:
=RegExpReplace(A5, "#\d{5}\b", "")
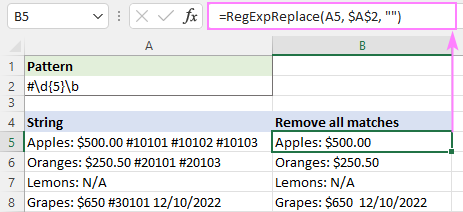
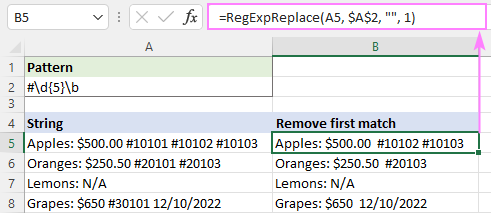
Ahhoz, hogy csak az első előfordulást töröljük, beállítjuk a instance_num érv értéke 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex bizonyos karakterek eltávolítására
Bizonyos karakterek eltávolításához egy karakterláncból csak írja le az összes nem kívánt karaktert, és válassza el őket egy függőleges vonallal.
Például a különböző formátumokban írt telefonszámok szabványosításához először meg kell szabadulnunk bizonyos karakterektől, mint például a zárójelektől, kötőjelektől, pontoktól és szóközöktől.
Mintázat : \(
=RegExpReplace(A5, "\(
A művelet eredménye egy 10 számjegyű szám, például "1234567890".
Az egyszerűség kedvéért a regexet egy külön cellába is beírhatja, és abszolút hivatkozással, például $A$2-vel hivatkozhat a cellára:
=RegExpReplace(A5, $A$2, "")
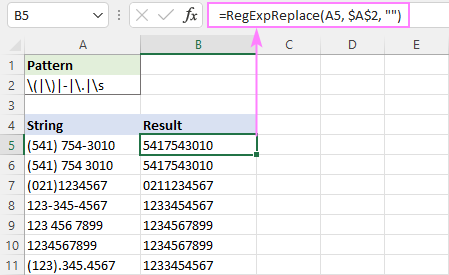
Ezután a formázást a kívánt módon szabványosíthatja az összekapcsolási operátor (&) és a Text függvények, például a RIGHT, MID és LEFT használatával.
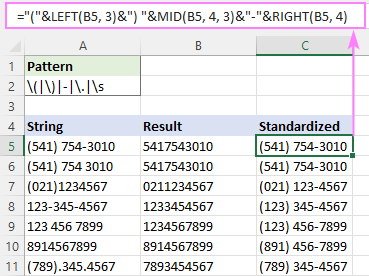
Ha például az összes telefonszámot (123) 456-7890 formátumban szeretnénk megadni, a képlet a következő:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Ahol B5 a RegExpReplace függvény kimenete.
Speciális karakterek eltávolítása regex használatával
Egyik oktatóanyagunkban azt néztük meg, hogyan lehet eltávolítani a nem kívánt karaktereket az Excelben beépített és egyéni függvények segítségével. A reguláris kifejezések sokkal egyszerűbbé teszik a dolgot! Ahelyett, hogy felsorolná az összes törölni kívánt karaktert, csak adja meg azokat, amelyeket meg szeretne tartani :)
A minta alapja negált karakterosztályok - a [^ ] karakterosztályon belül egy caret kerül elhelyezésre, hogy bármely, zárójelben NEM lévő karaktert egyezzen. A + kvantor arra kényszeríti, hogy az egymást követő karaktereket egyetlen egyezésnek tekintse, így a csere a megfelelő részláncra történik, nem pedig minden egyes karakterre.
Igényeitől függően válasszon az alábbi regexek közül.
Eltávolítani nem alfanumerikus karakterek, azaz a betűk és számjegyek kivételével minden karakter:
Mintázat : [^0-9a-zA-Z]+
Az összes karakter törlése kivéve a betűket , számjegyek és terek :
Mintázat : [^0-9a-zA-Z ]+
Az összes karakter törlése kivéve a betűket , számjegyek és aláhúzás , használhatja a \W karaktert, amely bármely olyan karaktert jelöl, amely NEM alfanumerikus karakter vagy aláhúzás:
Mintázat : \W+
Ha azt szeretné, hogy tarts meg néhány más karaktert , pl. írásjelek, tegye őket a zárójelek közé.
Például, ha a betűn, számjegyen, ponton, vesszőn vagy szóközön kívül bármely más karaktert el akar távolítani, használja a következő regexet:
Mintázat : [^0-9a-zA-Z\., ]+
Ez sikeresen eltávolítja az összes speciális karaktert, de az extra szóköz megmarad.
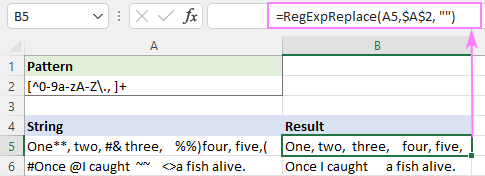
Ennek kijavításához a fenti függvényt beágyazhatja egy másik függvénybe, amely több szóközt egyetlen szóköz karakterrel helyettesít.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
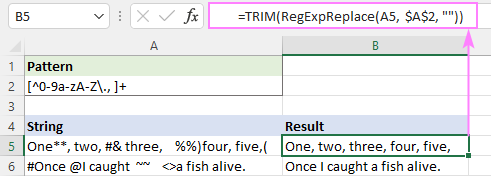
Vagy használja a natív TRIM funkciót ugyanezzel a hatással:
=TRIM(RegExpReplace(A5, $A$2, ""))
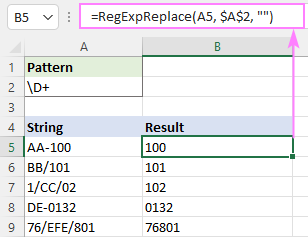
Regex a nem numerikus karakterek eltávolításához
Ha az összes nem számjegyet szeretné törölni egy karakterláncból, használhatja ezt a hosszú képletet vagy az alábbiakban felsorolt nagyon egyszerű regexek egyikét.
Bármely olyan karakterrel egyezik, amely NEM számjegy:
Mintázat : \D+
A nem számjegyek eltávolítása negált osztályok használatával:
Mintázat : [^0-9]+
Mintázat : [^\d]+
Tipp: Ha az a cél, hogy eltávolítsa a szöveget, és a megmaradt számokat külön cellákba öntse, vagy egy megadott elválasztójelekkel elválasztva egy cellában helyezze el őket, akkor használja a RegExpExtract függvényt, ahogyan azt a Hogyan vonjunk ki számokat a karakterláncból szabályos kifejezések segítségével című részben ismertettük.
Regex, hogy mindent eltávolítson a szóköz után
Ha mindent ki akar törölni egy szóköz után, használja a szóköz ( ) vagy a szóköz (\s) karaktert az első szóköz megtalálásához, és a .* karaktert az azt követő karakterek kereséséhez.
Ha olyan egysoros karakterláncokat használ, amelyek csak normál szóközöket tartalmaznak (a 7 bites ASCII rendszerben 32-es érték), akkor nem igazán számít, hogy az alábbi regexek közül melyiket használja. Többsoros karakterláncok esetén azonban nem mindegy.
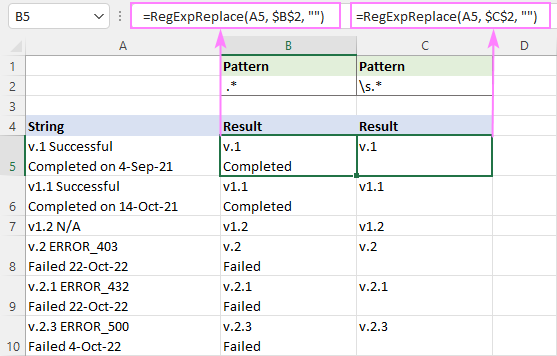
Mindent eltávolítani szóköz karakter után , használja ezt a regexet:
Mintázat : " .*"
=RegExpReplace(A5, " .*", "")
Ez a képlet eltávolít mindent, ami az első szóköz után van a minden egyes sor Ahhoz, hogy az eredmények helyesen jelenjenek meg, mindenképpen kapcsolja be a Szövegtörlés funkciót.
Mindent levetkőzni szóköz után (beleértve a szóközt, a tabulátort, a kocsivisszatérést és az új sort), a regex a következő:
Mintázat : \s.*
=RegExpReplace(A5, "\s.*", "")
Mivel a \s több különböző szóköz-típusra is megfelel, beleértve a egy új sor (\n), ez a képlet töröl mindent, ami az első szóköz után van egy cellában, függetlenül attól, hogy hány sor van benne.
Regex a szöveg eltávolításához egy adott karakter után
Az előző példa módszereivel törölheti a szöveget bármely megadott karakter után.
Az egyes sorok külön-külön történő kezelése:
Általános minta : char.*
Az egysoros karakterláncoknál ez eltávolít mindent, ami a char A többsoros karakterláncokban minden sor külön-külön kerül feldolgozásra, mivel a VBA Regex ízében a pont (.) minden karakterrel megegyezik, kivéve az új sort.
Az összes sor egyetlen karakterláncként történő feldolgozása:
Általános minta : char(.
Ha egy adott karakter után bármit törölni szeretne, beleértve az új sorokat is, \n-t kell hozzáadni a mintához.
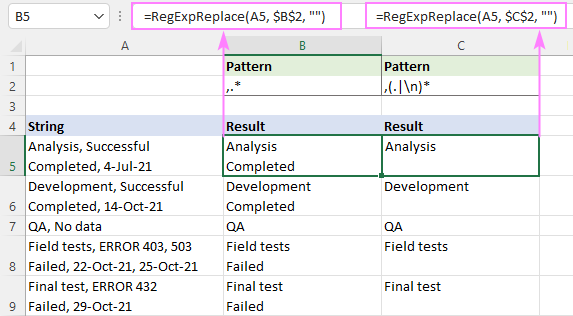
Ha például egy karakterláncban az első vessző utáni szöveget szeretné eltávolítani, próbálja ki a következő szabályos kifejezéseket:
Mintázat : ,.*
Mintázat : ,(.
Az alábbi képernyőképen megvizsgálhatja, hogy az eredmények hogyan különböznek.
Regex, hogy mindent eltávolítson a szóköz előtt
Amikor hosszú szövegrészletekkel dolgozunk, néha érdemes rövidebbé tenni őket azáltal, hogy minden cellában ugyanazt az információrészt eltávolítjuk. Az alábbiakban két ilyen esetet tárgyalunk.
Távolítson el mindent az utolsó szóköz előtt
Az előző példához hasonlóan a reguláris kifejezés is a "szóköz" fogalmától függ.
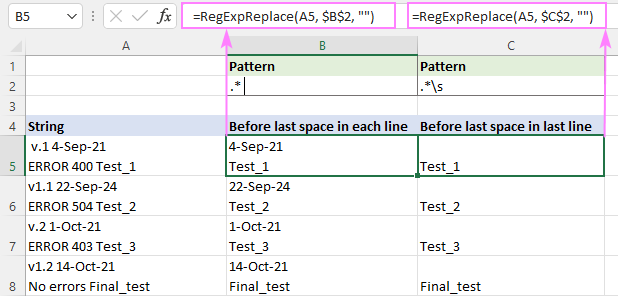
Ahhoz, hogy bármihez is illeszkedjen a utolsó hely , ez a regex is megteszi (idézőjeleket adunk hozzá, hogy a csillag utáni szóköz észrevehető legyen).
Mintázat : ".* "
A utolsó szóköz (beleértve a szóközt, a tabulátort, a kocsivisszatérést és az új sort), használja ezt a szabályos kifejezést.
Mintázat : .*\s
A különbség különösen a többsoros karakterláncoknál érezhető.
Az első szóköz előtt mindent távolítson el
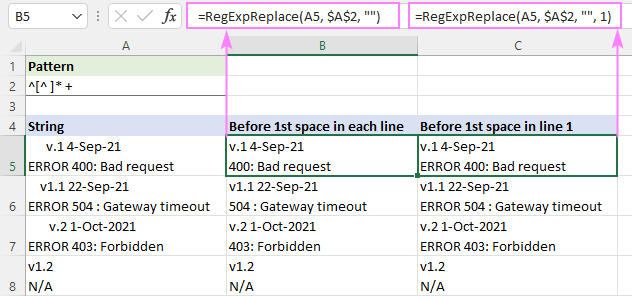
Ha egy karakterláncban az első szóközig bármit meg tud találni, akkor ezt a reguláris kifejezést használhatja:
Mintázat : ^[^ ]* +
A ^ karakterlánc elejétől kezdve nulla vagy több nem szóközös karaktert [^ ]* keresünk, amelyeket közvetlenül egy vagy több szóköz követ " +". Az utolsó rész azért van hozzáadva, hogy megakadályozzuk az esetleges vezető szóközöket az eredményekben.
Az egyes sorok első szóköz előtti szöveg eltávolításához a képletet az alapértelmezett "minden egyezés" üzemmódban írja ( instance_num kihagyva):
=RegExpReplace(A5, "^[^ ]* +", "")
Az első sor első szóköze előtti szöveg törléséhez, és az összes többi sor érintetlenül hagyásához, a instance_num argumentum értéke 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex a karakter előtti minden eltávolítására
A legegyszerűbb módja annak, hogy egy adott karakter előtti összes szöveget eltávolítsuk, egy ilyen regex használata:
Általános minta : ^[^char]*char
Emberi nyelvre lefordítva ez így hangzik: "a ^-vel lehorgonyzott karakterlánc elejétől kezdve 0 vagy több karakterrel egyezzen meg, kivéve a következőket char [^char]* a következő karakterek első előfordulásáig char .
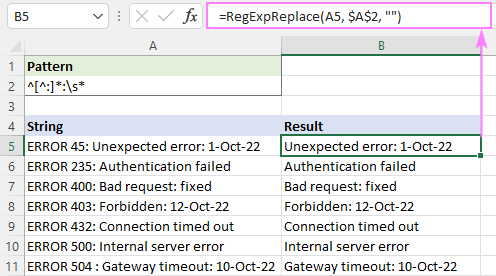
Például az első kettőspont előtti összes szöveg törléséhez használja ezt a szabályos kifejezést:
Mintázat : ^[^:]*:
Hogy elkerülje a szóközöket az eredményekben, adjon a végére egy \s* szóköz karaktert. Ez eltávolít mindent az első kettőspont előtt, és levágja a szóközöket közvetlenül utána:
Mintázat : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Tipp. A reguláris kifejezéseken kívül az Excelnek saját eszközei is vannak a szöveg pozíció vagy egyezés szerinti eltávolítására. A feladat natív képletekkel történő elvégzésének módját lásd a Hogyan távolítsuk el a szöveget egy karakter előtt vagy után az Excelben?
Regex, hogy mindent eltávolítson, kivéve
Ha egy karakterláncból minden karaktert ki akar törölni, kivéve azokat, amelyeket meg akar tartani, használja a negált karakterosztályokat.
Például a kisbetűk és pontok kivételével minden karakter eltávolításához a regex a következő:
Mintázat : [^a-z\.]+
Valójában itt a + kvantor nélkül is meg tudnánk oldani, mivel a függvényünk az összes talált egyezést helyettesíti. A kvantor csak egy kicsit gyorsabbá teszi a műveletet - ahelyett, hogy minden egyes karaktert külön-külön kezelnénk, egy részláncot cserélünk ki.
=RegExpReplace(A5, "[^a-z\.]+", "")
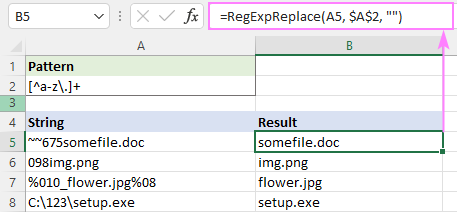
Regex a html címkék eltávolításához az Excelben
Először is, meg kell jegyezni, hogy a HTML nem egy reguláris nyelv, így a reguláris kifejezésekkel történő elemzése nem a legjobb módszer. Ez azt jelenti, hogy a regexek határozottan segíthetnek a címkék eltávolításában a cellákból, hogy az adatállomány tisztább legyen.
Mivel a html címkék mindig szögletes zárójelek között helyezkednek el, a következő regexek valamelyikének használatával találhatja meg őket.
Negált osztály:
Mintázat : ]*>
Itt egy nyitó szögletes zárójelet, majd a záró szögletes zárójel [^>]* kivételével bármely karakter nulla vagy több előfordulását a legközelebbi zárószögletes zárójelig hasonlítjuk össze.
Lusta keresés:
Mintázat :
Itt az első nyitó zárójel és az első zárójel között bármihez illeszkedik. A kérdőjel arra kényszeríti a .*-t, hogy a lehető legkevesebb karakterhez illeszkedjen, amíg nem talál egy zárójelet.
Bármelyik mintát is választja, az eredmény teljesen ugyanaz lesz.
Például, ha az A5-ben lévő karakterláncból el akarjuk távolítani az összes html-címkét, és meghagyjuk a szöveget, a képlet a következő:
=RegExpReplace(A5, "]*>", "")
Vagy használhatja a lazy quantifier-t, ahogy a képernyőképen látható:
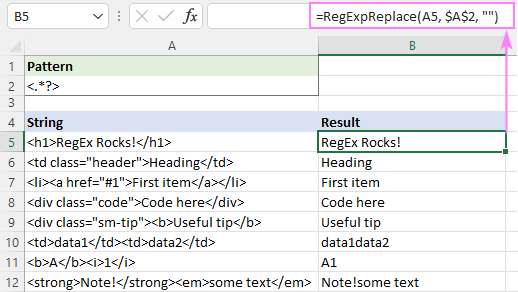
Ez a megoldás tökéletesen működik egyetlen szöveg esetén (5-9. sorok). Több szöveg esetén (10-12. sorok) az eredmény kérdéses - a különböző címkékből származó szövegek egybeolvadnak. Helyes ez vagy sem? Attól tartok, ezt nem lehet könnyen eldönteni - minden attól függ, hogyan értelmezzük a kívánt eredményt. Például a B11-ben az "A1" eredményt várjuk el; míg a B10-ben talán azt szeretnénk, hogy"data1" és "data2" szóközzel elválasztva.
A html címkék eltávolításához és a fennmaradó szövegek szóközökkel való elválasztásához így járhat el:
- A címkéket szóközökkel " " helyettesíti, nem üres karakterláncokkal:
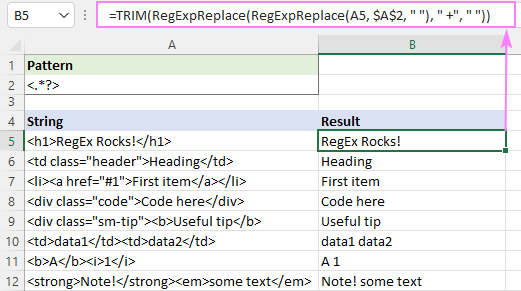
=RegExpReplace(A5, "]*>", " ") - Több szóköz egyetlen szóköz karakterré csökkentése:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Vágja le a vezető és az utolsó szóközöket:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ")))
Az eredmény valahogy így fog kinézni:
Ablebits Regex eltávolító eszköz
Ha volt alkalma használni az Ultimate Suite for Excel programcsomagot, akkor valószínűleg már felfedezte a legutóbbi kiadással bevezetett új Regex eszközöket. Ezeknek a .NET alapú Regex funkcióknak az a szépsége, hogy egyrészt támogatják a teljes körű szabályos kifejezések szintaxisát, amely mentes a VBA RegExp korlátozásoktól, másrészt nem szükséges VBA kódot beilleszteni a munkafüzetekbe, mivel az összes kód integrálása megtörténik.általunk a backendben.
A te feladatod az, hogy felépíts egy reguláris kifejezést, és azt tálald a függvénynek :) Hadd mutassam meg, hogyan kell ezt egy gyakorlati példán.
Hogyan lehet eltávolítani a zárójelben és a zárójelben lévő szöveget a regex segítségével?
A hosszú szöveges karakterláncokban a kevésbé fontos információk gyakran [zárójelekbe] és (zárójelekbe) vannak zárva. Hogyan lehet eltávolítani ezeket a lényegtelen részleteket, megtartva az összes többi adatot?
Valójában már építettünk egy hasonló regexet a html címkék, azaz a szögletes zárójeleken belüli szöveg törlésére. Nyilvánvalóan ugyanazok a módszerek működnek a szögletes és kerek zárójelek esetében is.
Mintázat : (\(.*?\))
A trükk a lusta kvantor (*?) használatában rejlik, hogy a lehető legrövidebb részláncot találja meg. Az első csoport (\(.*?\)) a nyitó zárójelektől az első záró zárójelig mindenre illik. A második csoport (\[.*?\]) a nyitó zárójelektől az első zárójelig mindenre illik. Egy függőleges vonallal
A minta meghatározásával "tápláljuk" be a Regex Remove függvényünket. Így járunk el:
- A Ablebits adatok lapon, a Szöveg csoport, kattintson a Regex eszközök .
Ha az eredményeket képletként szeretné megkapni, nem pedig értékként, válassza a Beillesztés képletként jelölőnégyzet.
A zárójelben lévő szöveg eltávolításához az A2:A5 karakterláncokból a következő beállításokat kell megadnunk:
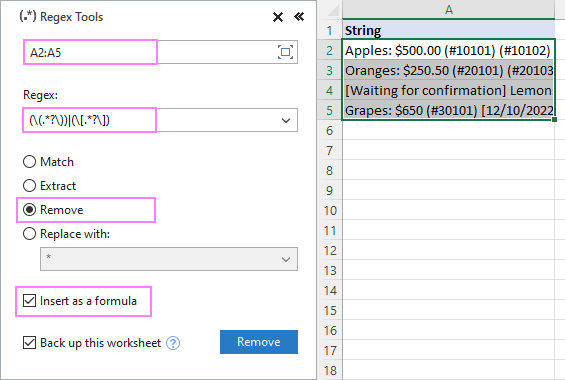
Ennek eredményeként a AblebitsRegexRemove funkciót egy új oszlopba illesztjük az eredeti adatok mellé.
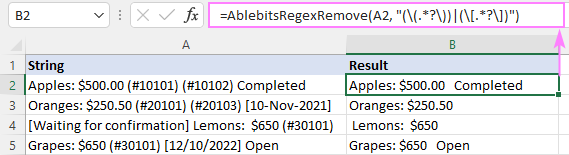
A függvényt közvetlenül is be lehet írni egy cellába a szabványos Beillesztési funkció párbeszédpanelen, ahol a AblebitsUDFs .
Mint AblebitsRegexRemove a szöveg eltávolítására szolgál, és csak két argumentumot igényel - a forrássztringet és a regexet. Mindkét paraméter közvetlenül egy képletben definiálható, vagy cellahivatkozások formájában is megadható. Szükség esetén ez az egyéni függvény bármely natív függvénnyel együtt használható.
Ha például a kapott karakterláncokban lévő extra szóközöket szeretné levágni, akkor a TRIM függvényt használhatja csomagolópapírként:
=TRIM(AblebitsRegexRemove(A5, $A$2))
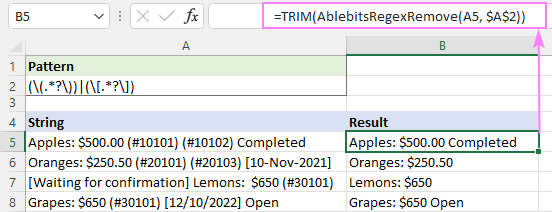
Így távolíthatjuk el a karakterláncokat az Excelben a reguláris kifejezések segítségével. Köszönöm, hogy elolvastad, és várom, hogy jövő héten találkozzunk a blogunkon!
Elérhető letöltések
Szövegek eltávolítása regex használatával - példák (.xlsm fájl)
Ultimate Suite - próbaverzió (.exe fájl)
