
Преглед садржаја
У низовима испод, претпоставимо да желите да избришете први број поруџбине. Сви такви бројеви почињу хеш знаком (#) и садрже тачно 5 цифара. Дакле, можемо их идентификовати помоћу овог редовног израза:
Образац : #\д{5}\б
Граница речи \б специфицира да одговарајући подниз не може бити део већег стринга као што је #10000001.
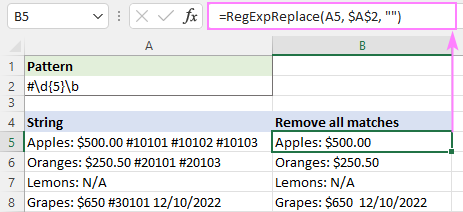
Да бисте уклонили сва подударања, аргумент инстанце_нум није дефинисан:
=RegExpReplace(A5, "#\d{5}\b", "")
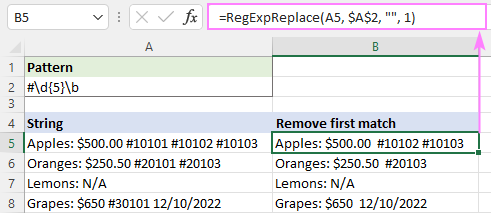
Да бисмо елиминисали само прво појављивање, поставили смо аргумент инстанце_нум на 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Регек за уклањање одређених знакова
Да бисте уклонили одређене знакове из стринга, само запишите све нежељене знакове и раздвојите их вертикалном тракомсинтаксу без ВБА РегЕкп ограничења, и друго, не захтева уметање ВБА кода у ваше радне свеске јер сву интеграцију кода вршимо ми у позадини.
Ваш део посла је да конструишете регуларни израз и послужите га функцији :) Дозволите ми да вам покажем како то да урадите на практичном примеру.
Како уклонити текст у заградама и заградама користећи регек
У дугим текстуалним низовима, мање важне информације се често ставља у [заграде] и (заграде). Како уклањате те небитне детаље задржавајући све остале податке?
У ствари, већ смо направили сличан регек за брисање хтмл ознака, тј. текста унутар угаоних заграда. Очигледно, исте методе ће функционисати и за угласте и округле заграде.
Образац : (\(.*?\))
Да ли сте икада помислили колико би Екцел моћан био када би неко могао да обогати његов оквир са алаткама регуларним изразима? Не само да смо размишљали, већ смо и радили на томе :) А сада, можете додати ову дивну РегЕк функцију у своје радне свеске и за трен обрисати поднизове који одговарају шаблону!
Прошле недеље смо погледали како да користите регуларне изразе за замену стрингова у Екцел-у. За ово смо креирали прилагођену функцију Регек Реплаце. Како се испоставило, функција превазилази своју примарну употребу и може не само да замени стрингове већ и да их уклони. Како би то могло бити? Што се тиче Екцел-а, уклањање вредности није ништа друго него замена празним стрингом, нешто у чему је наша функција Регек веома добра!
ВБА РегЕкп функција за уклањање подстрингова у Екцел-у
Као што сви знамо, регуларни изрази нису подржани у Екцел-у подразумевано. Да бисте их омогућили, потребно је да креирате сопствену функцију коју дефинише корисник. Добра вест је да је таква функција већ написана, тестирана и спремна за употребу. Све што треба да урадите је да копирате овај код, налепите га у свој ВБА едитор, а затим сачувате датотеку као радну свеску са омогућеним макроима (.клсм).
Функција има следећа синтакса:
РегЕкпРеплаце(текст, образац, замена, [број_инстанце], [матцх_цасе])Прва три аргумента су обавезна, последња два су опциона.
Где:
- Тект - текстуални низ за претрагумогуће док не пронађе заграду за затварање.
Који год образац да одаберете, резултат ће бити потпуно исти.
На пример, да бисте уклонили све хтмл ознаке из низа у А5 и оставили текст, формула је:
=RegExpReplace(A5, "]*>", "")
Или можете користити лењи квантификатор као што је приказано на снимку екрана:
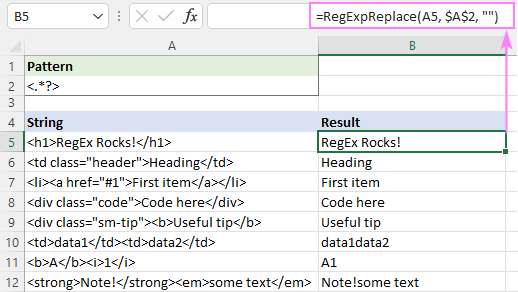
Ово решење савршено функционише за појединачни текст (редови 5 - 9). За више текстова (редови 10 - 12), резултати су упитни - текстови из различитих ознака су спојени у један. Да ли је ово тачно или није? Бојим се да се то не може лако одлучити - све зависи од вашег разумевања жељеног исхода. На пример, у Б11 се очекује резултат "А1"; док у Б10 можда желите да „подаци1“ и „подаци2“ буду раздвојени размаком.
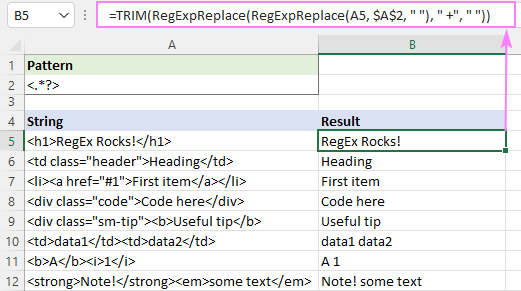
Да бисте уклонили хтмл ознаке и раздвојили преостале текстове размацима, можете да поступите на следећи начин:
- Замените ознаке размацима „ “, а не празним стринговима:
=RegExpReplace(A5, "]*>", " ") - Смањи више размака на један знак за размак:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Скратите почетне и задње размаке:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
Резултат ће изгледати отприлике овако:
Аблебитс Регек Ремове Тоол
Ако сте имали прилику да користите наш Ултимате Суите фор Екцел, вероватно сте већ открили нове Регек алате представљене у недавном издању. Лепота ових Регек функција заснованих на .НЕТ-у је у томе што оне, прво, подржавају регуларни израз са пуним функцијамаопцију Уклони и притисните Уклони .
Да бисте добили резултате као формуле, а не вредности, потврдите избор у пољу за потврду Убаци као формулу .
Да бисмо уклонили текст унутар заграда из стрингова у А2:А5, конфигуришемо подешавања на следећи начин:
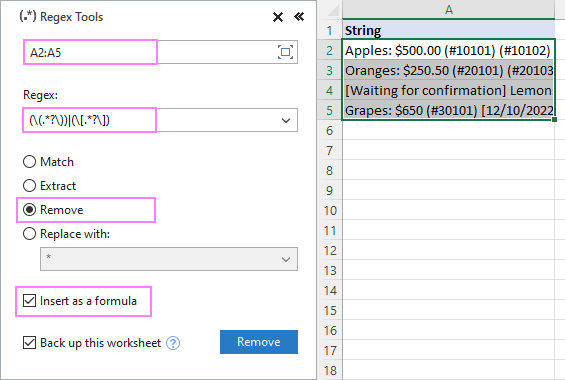
Као резултат, функција АблебитсРегекРемове се убацује у нову колону поред ваших оригиналних података.
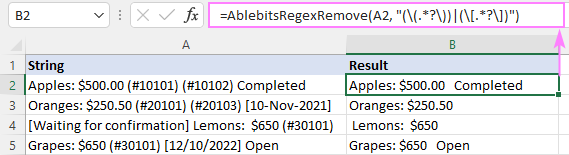
Функција се такође може унети директно у ћелију преко стандардног Инсерт Фунцтион оквира за дијалог, где је категорисана под АблебитсУДФс .
Како је АблебитсРегекРемове дизајниран да уклони текст, потребна су му само два аргумента – изворни стринг и регуларни израз. Оба параметра се могу дефинисати директно у формули или дати у облику референци ћелија. Ако је потребно, ова прилагођена функција се може користити заједно са било којом изворном функцијом.
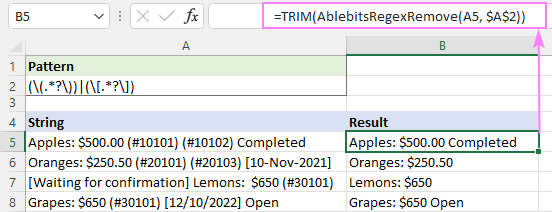
На пример, да бисте скратили додатне размаке у резултујућим стринговима, можете да користите функцију ТРИМ као омотач:
=TRIM(AblebitsRegexRemove(A5, $A$2))
Тако можете уклонити стрингове у Екцел-у користећи регуларне изразе. Захваљујем вам на читању и радујем се што ћу вас видети на нашем блогу следеће недеље!
Доступна преузимања
Уклоните стрингове користећи регуларни израз - примери (.клсм датотека)
Ултимате Суите - пробна верзија (.еке датотека)
ин.За више информација погледајте функцију РегЕкпРеплаце.
Савет. У једноставним случајевима можете уклонити одређене знакове или речи из ћелија помоћу Екцел формула. Али регуларни изрази пружају много више опција за ово.
Како уклонити стрингове користећи регуларне изразе - примери
Као што је горе поменуто, да бисте уклонили делове текста који одговарају шаблону, морате их заменити са празним низом. Дакле, генеричка формула поприма овај облик:
РегЕкпРеплаце(тект, паттерн, "", [инстанце_нум], [матцх_цасе])Доле наведени примери показују различите имплементације овог основног концепта.
Уклони сва подударања или специфично подударање
Функција РегЕкпРеплаце је дизајнирана да пронађе све подстрингове који одговарају датом редовном изразу. Које појаве треба уклонити контролише 4. опциони аргумент, под називом инстанце_нум .
Подразумевано је „сва подударања“ – када је инстанце_нум оператор конкатенације (&амп;) и функције текста као што су ДЕСНО, СРЕДИНА и ЛЕВО.
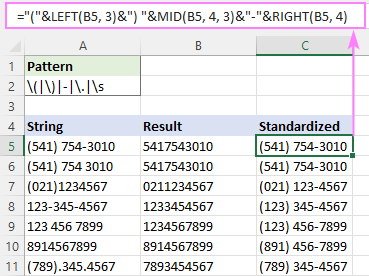
На пример, да бисте уписали све телефонске бројеве у формату (123) 456-7890, формула је:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Где је Б5 излаз функције РегЕкпРеплаце.
Уклоните специјалне знакове користећи регек
У једном од наших туторијала, погледали смо како да уклонимо нежељене знакове у Екцел-у користећи уграђене и прилагођене функције. Регуларни изрази чине ствари много лакшим! Уместо да наведете све знакове за брисање, само наведите оне које желите да задржите :)
Шаблон је заснован на негативним класама знакова - у класу знакова се ставља курсор [^ ] да одговара било ком појединачном знаку НЕ у заградама. Квантификатор + га приморава да посматра узастопне знакове као једно подударање, тако да се замена врши за одговарајући подниз уместо за сваки појединачни знак.
У зависности од ваших потреба, изаберите један од следећих регуларних израза.
Да бисте уклонили не-алфанумеричке знакове, тј. све знакове осим слова и цифара:
Образац : [^0-9а-зА-З] +
Да бисте обрисали све знакове осим слова , цифара и размака :
Образац : [^0-9а-зА-З ]+
Да бисте избрисали све знакове осим слова , цифара и доње црте , можете користити \ В који означава било који знак који НИЈЕ алфанумерички знак илидоња црта:
Образац : \В+
Ако желите да задржите неке друге знакове , нпр. знакове интерпункције, ставите их у заграде.
На пример, да бисте уклонили било који знак осим слова, цифре, тачке, зареза или размака, користите следећи регуларни израз:
Образац : [^0-9а-зА-З\., ]+
Ово успешно елиминише све специјалне знакове, али остаје додатни размак.
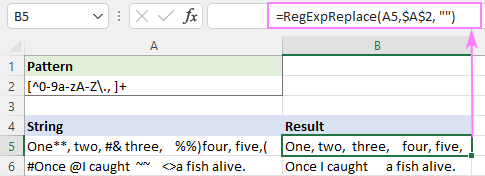
Да бисте ово поправили, можете да угнездите горњу функцију у другу која замењује више размака једним знаком за размак.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
Или једноставно користите изворну функцију ТРИМ са истим ефектом :
=TRIM(RegExpReplace(A5, $A$2, ""))
Регек за уклањање ненумеричких знакова
Да бисте избрисали све ненумеричке знакове из стринга, можете користити или ову дугачку формулу или један од веома једноставних регуларних израза наведених у наставку.
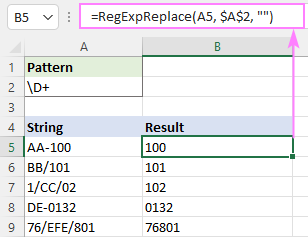
Упарите било који знак који НИЈЕ цифра:
Образац : \Д+
Уклоните ненумеричке знакове користећи негиране класе:
Образац : [^0-9]+
Образац : [^\д] +
Савет. Ако је ваш циљ да уклоните текст и разбаците преостале бројеве у засебне ћелије или их све ставите у једну ћелију одвојену одређеним граничником, онда користите функцију РегЕкпЕктрацт као што је објашњено у Како издвојити бројеве из стринга помоћу регуларних израза.
Регекс за уклањање свега после размака
Да бисте избрисали све после размака, користите размак ( ) илиразмак (\с) знак за проналажење првог размака и .* за подударање са свим знаковима после њега.
Ако имате низове у једном реду који садрже само нормалне размаке (вредност 32 у 7-битном АСЦИИ систему) , заправо није битно који од доле наведених регуларних израза користите. У случају стрингова са више редова, то чини разлику.
Да бисте уклонили све после размака , користите овај регуларни израз:
Образац : " .*"
=RegExpReplace(A5, " .*", "")
Ова формула ће уклонити све после првог размака у сваком реду . Да би се резултати исправно приказали, обавезно укључите Врап Тект.
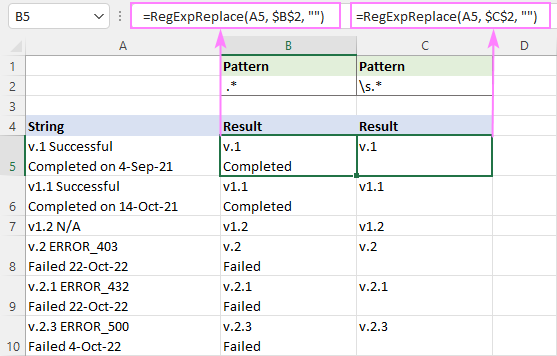
Да бисте уклонили све после размака (укључујући размак, табулатор, повратак и нови ред), регуларни израз је:
Образац : \с.*
=RegExpReplace(A5, "\s.*", "")
Зато што се \с поклапа са неколико различитих типова размака укључујући нови ред (\н), ова формула брише све после првог размака у ћелији, без обзира на то колико редова има у њој.
Регекс за уклањање текста после одређеног цхарацтер
Користећи методе из претходног примера, можете да избришете текст после било ког знака који наведете.
Да бисте руковали сваким редом засебно:
Генерички образац : цхар.*
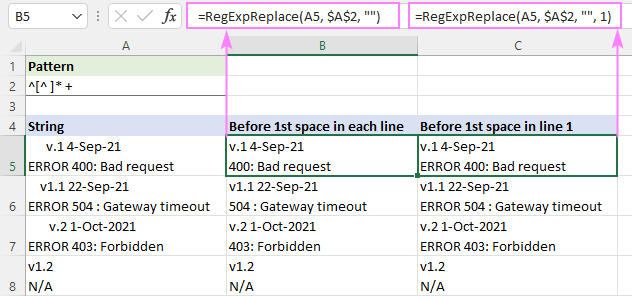
У низовима од једног реда, ово ће уклонити све после цхар . У стринговима са више редова, сваки ред ће бити обрађен појединачно јер у ВБА Регек укусу тачка (.) одговара било ком карактеру осим новогпочетак стринга ^, подударамо нула или више знакова без размака [^ ]* који су одмах праћени једним или више размака " +". Последњи део је додат да би се спречили потенцијални водећи размаци у резултатима.
Да бисте уклонили текст пре првог размака у сваком реду, формула се пише у подразумеваном режиму „сва подударања“ ( број_инстанце изостављено):
=RegExpReplace(A5, "^[^ ]* +", "")
Да бисте избрисали текст пре првог размака у првом реду и оставили све остале редове нетакнутим, аргумент инстанце_нум је подешен на 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Регекс за уклањање свега пре знака
Најлакши начин да уклоните сав текст пре одређеног знака је коришћење редовног израза овако:
Генерички образац : ^[^цхар]*цхар
Преведено на људски језик, каже: „од почетка стринга који је усидрен помоћу ^ , подудара се са 0 или више знакова осим цхар [^цхар]* до првог појављивања цхар .
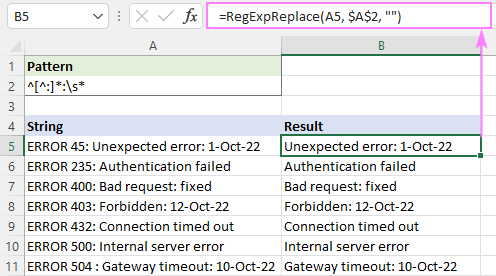
На пример, да избришете сав текст пре првог двотачка , користите овај регуларни израз:
Образац : ^[^:]*:
Да бисте избегли водећи размаци у резултатима, додајте знак размака \с* у крај. Ово ће уклонити све г пре првог двотачка и исеците све размаке одмах после њега:
Образац : ^[^:]*:\с*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Савет. Осим регуларних израза, Екцел има сопствена средства за уклањање текста по позицији или подударању. Да бисте научили како да извршите задатак са изворним формулама,погледајте Како уклонити текст пре или после знака у Екцел-у.
Регек за уклањање свега осим
Да бисте избрисали све знакове из стринга осим оних које желите да задржите, користите негиране класе знакова.
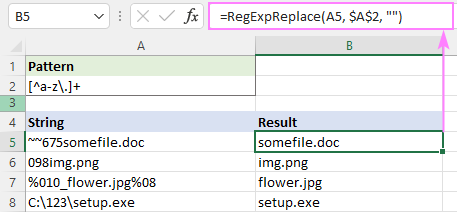
На пример, да бисте уклонили све знакове осим малих слова и тачке, регуларни израз је:
Образац : [^а-з\.]+
У ствари, овде бисмо могли без квантификатора + јер наша функција замењује све пронађена подударања. Квантификатор га само чини мало бржим – уместо да рукујете сваким појединачним карактером, замењујете подниз.
=RegExpReplace(A5, "[^a-z\.]+", "")
Регек за уклањање хтмл ознака у Екцел-у
Прво, треба напоменути да ХТМЛ није регуларан језик, тако да његово рашчлањивање помоћу регуларних израза није најбољи начин. Уз то, регуларни изрази дефинитивно могу помоћи у уклањању ознака из ваших ћелија како би ваш скуп података био чишћи.
С обзиром на то да су хтмл ознаке увек смештене унутар угаоних заграда, можете их пронаћи помоћу једног од следећих регуларних израза.
Негирана класа:
Образац : ]*&гт;
Овде се подударамо са заградом угла отварања, након чега следи нула или више појављивања било ког знака осим затворена угаона заграда [^&гт;]* до најближе угаоне заграде која се затвара.
Лења претрага:
Образац :
Овде се подударамо било шта од прве отварајуће заграде до прве заграде за затварање. Знак питања присиљава .* да одговара што мање знаковалинија.
За обраду свих редова као једног стринга:
Генерички образац : цхар(.
