
Sisukord
Kas olete kunagi mõelnud, kui võimas oleks Excel, kui keegi saaks selle tööriistakasti rikastada regulaaravaldiste abil? Me mitte ainult ei mõelnud, vaid töötasime selle kallal :) Ja nüüd saate lisada selle imelise RegEx-funktsiooni oma töövihikutesse ja pühkida mustrile vastavad alajaotused hetkega välja!
Eelmisel nädalal vaatlesime, kuidas kasutada regulaaravaldisi stringide asendamiseks Excelis. Selleks lõime kohandatud Regex Replace funktsiooni. Nagu selgus, läheb see funktsioon oma esmasest kasutusest kaugemale ja suudab mitte ainult stringid asendada, vaid ka eemaldada neid. Kuidas see võimalik on? Exceli mõistes ei ole väärtuse eemaldamine midagi muud kui selle asendamine tühja stringiga, mida meie Regex funktsioon onväga hea!
VBA RegExp funktsioon alamsõnade eemaldamiseks Excelis
Nagu me kõik teame, ei toeta Excel vaikimisi regulaarseid väljendeid. Nende võimaldamiseks peate looma oma kasutajapoolse funktsiooni. Hea uudis on see, et selline funktsioon on juba kirjutatud, testitud ja valmis kasutamiseks. Teil tuleb vaid kopeerida see kood, kleepida see oma VBA redaktorisse ja seejärel salvestada oma fail kui makrotoimingutega töövihik (.xlsm).
Funktsioonil on järgmine süntaks:
RegExpReplace(text, pattern, replacement, [instance_num], [match_case])Esimesed kolm argumenti on kohustuslikud, kaks viimast on vabatahtlikud.
Kus:
- Tekst - tekstirida, mida otsida.
- Muster - regulaaravaldis, mida otsida.
- Asendus - tekst, millega asendada. Et eemaldage alajaotused mis vastab mustrile, kasutage tühi string ("") asendamiseks.
- Instance_num (valikuline) - asendatav instants. Kui see jäetakse välja, asendatakse kõik leitud vasted (vaikimisi).
- Match_case (valikuline) - bool'i väärtus, mis näitab, kas teksti suur- ja väiketähtedega sobitamine või nende ignoreerimine. Suur- ja väiketähtedega sobitamise puhul kasutage TRUE (vaikimisi); suur- ja väiketähtedega mittearvestamise puhul - FALSE.
Lisateavet leiate funktsioonist RegExpReplace.
Vihje. Lihtsamatel juhtudel saate Exceli valemitega lahtritest eemaldada konkreetseid sümboleid või sõnu. Kuid regulaaravaldised pakuvad selleks palju rohkem võimalusi.
Kuidas eemaldada stringid regulaaravaldiste abil - näited
Nagu eespool mainitud, tuleb mustrile vastavate tekstiosade eemaldamiseks asendada need tühja stringiga. Seega võtab üldine valem sellise kuju:
RegExpReplace(text, pattern, "", [instance_num], [match_case])Allpool toodud näited näitavad selle põhikontseptsiooni erinevaid rakendusi.
Eemaldage kõik vasted või konkreetne vaste
Funktsioon RegExpReplace on mõeldud kõigi antud regexile vastavate alamsõnade leidmiseks. Seda, milliseid esinemisi eemaldada, kontrollib 4. valikuline argument nimega instance_num .
Vaikimisi on "kõik vasted" - kui instance_num argument on välja jäetud, eemaldatakse kõik leitud vasted. Konkreetse vaste kustutamiseks määrake instantsi number.
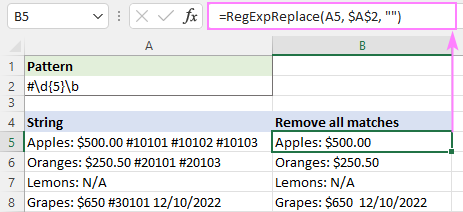
Oletame, et allpool esitatud stringidest tahetakse kustutada esimene järjekorranumber. Kõik sellised numbrid algavad hash-märgiga (#) ja sisaldavad täpselt 5 numbrit. Seega saame neid selle regexi abil tuvastada:
Muster : #\d{5}\b
Sõnapiir \b määrab, et vastav alamjada ei saa olla osa suuremast stringist, näiteks #10000001.
Kõikide vastete eemaldamiseks on instance_num argument ei ole määratletud:
=RegExpReplace(A5, "#\d{5}\b", "")
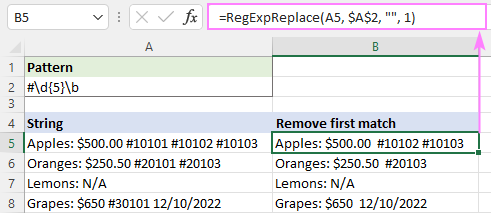
Ainult esimese esinemise likvideerimiseks määrame me instance_num argument 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex teatud tähemärkide eemaldamiseks
Teatud tähemärkide eemaldamiseks stringist kirjutage lihtsalt kõik soovimatud tähemärgid üles ja eraldage need vertikaalse ribaga.
Näiteks eri formaatides kirjutatud telefoninumbrite standardiseerimiseks vabaneme kõigepealt konkreetsetest märkidest, nagu sulgudes, sidekriipsudes, punktidest ja tühikutest.
Muster : \(
=RegExpReplace(A5, "\(
Selle operatsiooni tulemuseks on 10-kohaline number nagu "1234567890".
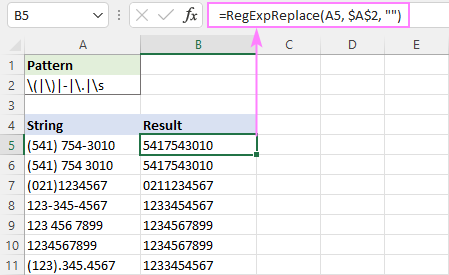
Mugavuse huvides võite sisestada regexi eraldi lahtrisse ja viidata sellele lahtrisse, kasutades absoluutset viidet, näiteks $A$2:
=RegExpReplace(A5, $A$2, "")
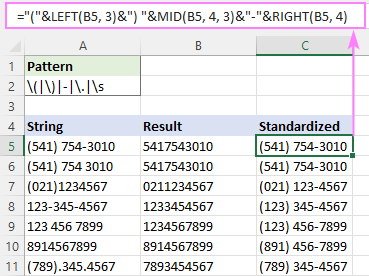
Ja siis saate vormindamist standardiseerida nii, nagu soovite, kasutades liitmisoperaatorit (&) ja tekstifunktsioone, nagu RIGHT, MID ja LEFT.
Näiteks, et kirjutada kõik telefoninumbrid formaadis (123) 456-7890, on valem järgmine:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Kus B5 on funktsiooni RegExpReplace väljund.
Erimärkide eemaldamine regexi abil
Ühes meie õpetuses vaatlesime, kuidas eemaldada soovimatuid sümboleid Excelis, kasutades sisseehitatud ja kohandatud funktsioone. Regulaaravaldised teevad asja palju lihtsamaks! Selle asemel, et loetleda kõik kustutatavad sümbolid, määrake lihtsalt need, mida soovite säilitada :)
Muster põhineb eiratud tähemärkide klassid - karet pannakse tähemärkide klassi [^ ] sisse, et sobitada mis tahes üksikmärk, mis EI ole sulgudes. Kvantifikaator + sunnib seda käsitlema järjestikuseid märke ühe vastena, nii et asendamine toimub pigem sobiva alamjada kui iga üksiku tähemärgi puhul.
Sõltuvalt teie vajadustest valige üks järgmistest regexidest.
Eemaldada mitte-alfanumbriline tähemärgid, st kõik tähemärgid peale tähtede ja numbrite:
Muster : [^0-9a-zA-Z]+
Kõigi tähemärkide puhastamine välja arvatud kirjad , numbrid ja ruumid :
Muster : [^0-9a-zA-Z ]+
Kõigi tähemärkide kustutamine välja arvatud kirjad , numbrid ja alajaotus , võite kasutada \W, mis tähistab mis tahes märki, mis EI ole tähtnumbriline märk või alajaotus:
Muster : \W+
Kui soovite hoida mõned teised tegelased , nt kirjavahemärgid, pange need sulgudes.
Näiteks, et eemaldada kõik muud märgid peale tähe, numbri, punkti, koma või tühiku, kasutage järgmist regexi:
Muster : [^0-9a-zA-Z\., ]+
See kõrvaldab edukalt kõik erimärgid, kuid alles jäävad täiendavad tühikud.
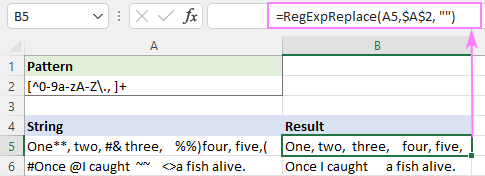
Selle parandamiseks saate ülaltoodud funktsiooni ühendada teise funktsiooniga, mis asendab mitu tühikut ühe tühiku märgiga.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
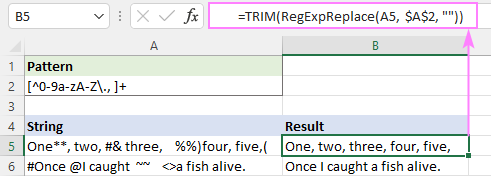
Või kasutage lihtsalt sama efekti saavutamiseks natiivset funktsiooni TRIM:
=TRIM(RegExpReplace(A5, $A$2, ""))
Regex mittenumbriliste märkide eemaldamiseks
Et kustutada stringist kõik mittenumbrilised tähemärgid, võite kasutada kas seda pikka valemit või ühte allpool loetletud väga lihtsatest regexidest.
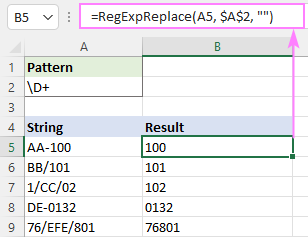
Sobitatakse mis tahes tähemärki, mis EI ole number:
Muster : \D+
Mitte-numbrilised tähemärgid eemaldatakse, kasutades eitavaid klasse:
Muster : [^0-9]+
Muster : [^\d]+
Vihje. Kui teie eesmärk on eemaldada tekst ja valada allesjäänud numbrid eraldi lahtritesse või paigutada need kõik ühte lahtrisse, mis on eraldatud määratud eraldaja abil, siis kasutage funktsiooni RegExpExtract, nagu on selgitatud peatükis Kuidas eraldada numbreid stringist regulaaravaldiste abil.
Regex, et eemaldada kõik pärast tühikut
Et kustutada kõik pärast tühikut, kasutage kas tühikut ( ) või tühikut (\s), et leida esimene tühik ja .*, et sobitada kõik selle järgnevad tähemärgid.
Kui teil on ühe rea stringid, mis sisaldavad ainult tavalisi tühikuid (väärtus 32 7-bitises ASCII süsteemis), ei ole tegelikult oluline, millist allpool toodud regexi te kasutate. Mitme rea stringide puhul on see oluline.
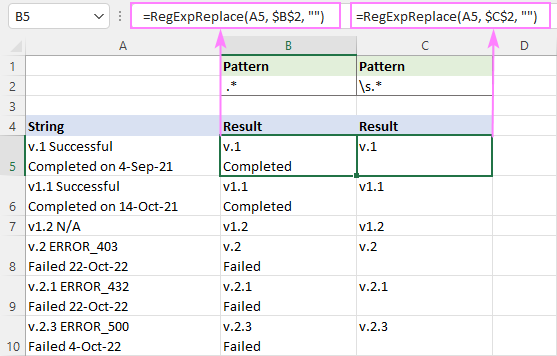
Eemaldada kõik pärast tühikut , kasutage seda regexi:
Muster : " .*"
=RegExpReplace(A5, " .*", "")
See valem eemaldab kõik pärast esimest tühikut, mis on sees iga rida Tulemuste korrektseks kuvamiseks lülitage kindlasti sisse Wrap Text.
Kõik maha võtta pärast tühikut (sealhulgas tühik, tabulaator, vagunitagasi ja uus rida), regex on:
Muster : \s.*
=RegExpReplace(A5, "\s.*", "")
Kuna \s vastab mitmetele erinevatele tühikutüüpidele, sealhulgas uus rida (\n), kustutab see valem kõik pärast esimest tühikut lahtris, olenemata sellest, kui palju ridu lahtris on.
Regex teksti eemaldamiseks pärast konkreetset märki
Kasutades eelmises näites toodud meetodeid, saate kustutada teksti pärast mis tahes määratud märki.
Käsitleda iga rida eraldi:
Üldine muster : char.*
Ühe reaga stringides eemaldatakse sellega kõik pärast char Mitmeridade puhul töödeldakse iga rida eraldi, sest VBA Regexi maitses vastab punkt (.) igale tähemärgile, välja arvatud uuele reale.
Kõigi ridade töötlemiseks ühe stringina:
Üldine muster : char(.
Et kustutada kõik, mis järgneb antud märgile, sealhulgas uued read, lisatakse mustrile \n.
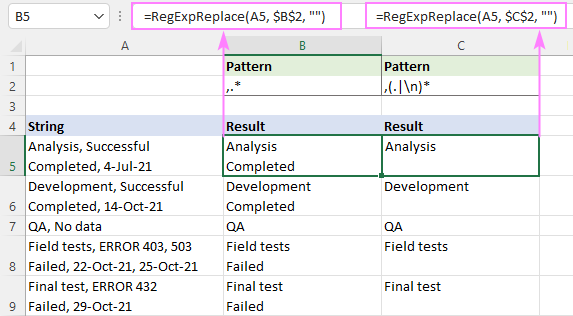
Näiteks, kui soovite eemaldada teksti pärast esimest koma stringi, proovige järgmisi regulaarseid väljendeid:
Muster : ,.*
Muster : ,(.
Allpool oleval ekraanipildil saate vaadata, kuidas tulemused erinevad.
Regex, et eemaldada kõik enne tühikut
Kui töötate pikkade tekstiridadega, võite mõnikord soovida neid lühendada, eemaldades kõikides lahtrites sama teabeosa. Järgnevalt arutame kahte sellist juhtumit.
Eemaldage kõik enne viimast tühikut
Nagu eelmise näite puhul, sõltub regulaaravaldis teie arusaamast "tühiku" kohta.
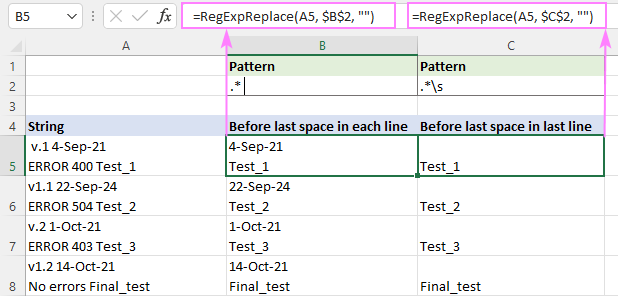
Et sobitada midagi kuni viimane ruum , see regex sobib (jutumärgid on lisatud, et tühik pärast tärni oleks märgatav).
Muster : ".* "
Et sobitada midagi enne viimane tühik (sealhulgas tühik, tabulaator, vagunitagasi ja uus rida), kasutage seda regulaaravaldist.
Muster : .*\s
Erinevus on eriti märgatav mitme rea stringide puhul.
Tühjendage kõik enne esimest tühikut
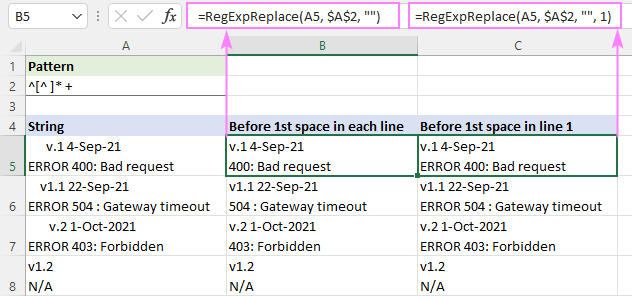
Selleks, et sobitada kõike kuni esimese tühikuni stringis, saate kasutada seda regulaaravaldist:
Muster : ^[^ ]* +
Alates stringi algusest ^ sobitame nulli või rohkem tühikuta tähte [^ ]*, millele järgneb kohe üks või mitu tühikut " +". Viimane osa lisatakse, et vältida võimalikke eesolevaid tühikuid tulemustes.
Et eemaldada tekst enne esimest tühikut igas reas, kirjutatakse valem vaikimisi "kõik vasted" režiimis ( instance_num välja jäetud):
=RegExpReplace(A5, "^[^ ]* +", "")
Teksti kustutamiseks enne esimest tühikut esimeses reas ja kõigi teiste ridade puutumatuks jätmiseks kasutatakse käsku instance_num argumendi väärtuseks on 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex, et eemaldada kõik enne märki
Kõige lihtsam viis eemaldada kogu tekst enne teatud märki on kasutada sellist regexi:
Üldine muster : ^[^char]*char
Inimkeelde tõlgituna ütleb see: "stringi algusest, mis on ankurdatud ^-ga, sobitatakse 0 või rohkem tähemärki, välja arvatud char [^char]* kuni esimese esinemiseni. char .
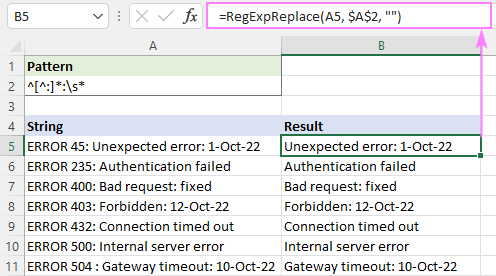
Näiteks, et kustutada kogu tekst enne esimest koolonit, kasutage seda regulaaravaldist:
Muster : ^[^:]*:
Et vältida tulemustes eesolevaid tühikuid, lisage lõppu tühikutähe \s*. See eemaldab kõik enne esimest koolonit ja kärbib kõik tühikud kohe pärast seda:
Muster : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Vihje. Lisaks regulaaravaldistele on Excelil oma vahendid teksti eemaldamiseks positsiooni või vaste järgi. Kuidas seda ülesannet emakeelsete valemitega täita, saate teada, kuidas eemaldada teksti enne või pärast märki Excelis.
Regex, et eemaldada kõik peale
Et kustutada stringist kõik tähemärgid, välja arvatud need, mida soovite säilitada, kasutage eitavaid märgiklasse.
Näiteks, et eemaldada kõik tähed peale väiketähtede ja punktide, on regex:
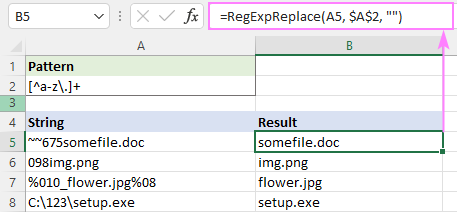
Muster : [^a-z\.]+
Tegelikult võiksime siin ilma kvantifikaatorita + hakkama saada, sest meie funktsioon asendab kõik leitud vasted. Kvantifikaator teeb selle lihtsalt veidi kiiremaks - iga üksiku tähemärgi käsitlemise asemel asendate alamjada.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex html-siltide eemaldamiseks Excelis
Kõigepealt tuleb märkida, et HTML ei ole regulaarkeel, seega ei ole selle analüüs regulaaravaldiste abil parim viis. See tähendab, et regexid võivad kindlasti aidata eemaldada märgiseid lahtritest, et muuta andmestik puhtamaks.
Arvestades, et html-tähed on alati nurksulgudes , saate neid leida, kasutades ühte järgmistest regexidest.
Negatiivne klass:
Muster : ]*>
Siinkohal sobitame algava nurksulguri, millele järgneb null või rohkem tähemärki, välja arvatud sulgev nurksulgur [^>]*, kuni lähima sulgeva nurksulgurini.
Laisk otsing:
Muster :
Siinkohal sobitame kõike alates esimesest avanevast sulgemisest kuni esimese sulgemisega. Küsimärk sunnib .* sobitama võimalikult vähe märke, kuni ta leiab sulgemisega sulgemise.
Ükskõik, millise mustri te valite, tulemus on absoluutselt sama.
Näiteks, et eemaldada kõik html-tähed stringist A5 ja jätta tekst, on valem järgmine:
=RegExpReplace(A5, "]*>", "")
Või võite kasutada laiskade kvantifikaatorit, nagu on näidatud ekraanipildil:
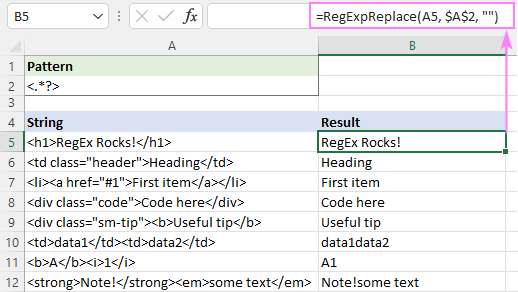
See lahendus töötab suurepäraselt ühe teksti puhul (read 5 - 9). Mitme teksti puhul (read 10 - 12) on tulemus küsitav - eri siltide tekstid liidetakse üheks. Kas see on õige või mitte? Ma kardan, et seda ei saa lihtsalt otsustada - kõik sõltub teie arusaamast soovitud tulemusest. Näiteks B11 puhul oodatakse tulemust "A1"; samas kui B10 puhul võib soovida, et"data1" ja "data2" tuleb eraldada tühikuga.
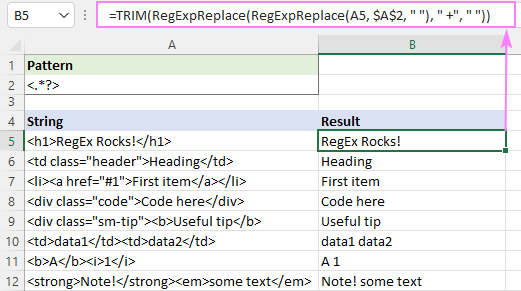
Kui soovite eemaldada html-tähed ja ülejäänud tekstid tühikutega eraldada, võite toimida nii:
- Asendage sildid tühikutega " ", mitte tühjade stringidega:
=RegExpReplace(A5, "]*>", " ") - Vähendage mitu tühikut üheks tühiku märgiks:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - Kärpige juhtivad ja tagumised tühikud:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
Tulemus näeb välja umbes nii:
Ablebits Regexi eemaldamise tööriist
Kui teil on olnud võimalus kasutada meie Ultimate Suite for Excel'i, siis olete tõenäoliselt juba avastanud uued Regex Tools, mis võeti kasutusele hiljutise versiooniga. Nende .NET-põhiste Regex-funktsioonide ilu seisneb selles, et need esiteks toetavad täisfunktsionaalset regulaaravaldiste süntaksit, mis on vaba VBA RegExp piirangutest, ja teiseks ei nõua VBA koodi sisestamist teie töövihikutesse, kuna kogu koodi integreerimine on tehtud.meie poolt tagapool.
Sinu osa tööst on konstrueerida regulaaravaldis ja serveerida see funktsioonile :) Näitan sulle, kuidas seda praktilise näite peal teha.
Kuidas eemaldada teksti sulgudes ja sulgudes regexi abil
Pikkades tekstisõnades on vähem oluline teave sageli [sulgudes] ja (sulgudes). Kuidas eemaldada need ebaolulised üksikasjad, säilitades kõik muud andmed?
Tegelikult oleme juba ehitanud sarnase regexi html-tagide, st nurksulgudes oleva teksti kustutamiseks. Ilmselt töötavad samad meetodid ka nurk- ja ümarsulgude puhul.
Muster : (\(.*?\))
Trikk seisneb selles, et laiskade kvantifikaatorite (*?) abil leitakse võimalikult lühike alajaotus. Esimene rühm (\(.*?\)) sobib kõigega alates avanevast sulgemisest kuni esimese sulgemisega. Teine rühm (\[.*?\]) sobib kõigega alates avanevast sulgemisest kuni esimese sulgemisega. Vertikaalne riba
Kui muster on kindlaks määratud, siis "söötame" seda meie Regex Remove funktsioonile. Siin on, kuidas:
- On Ablebits andmed vahekaardil Tekst rühma, klõpsake Regex tööriistad .
Tulemuste saamiseks valemite, mitte väärtustena, valige käsk Sisesta valemina märkeruut.
Selleks, et eemaldada sulgudes olev tekst stringidest A2:A5, seadistame seaded järgmiselt:
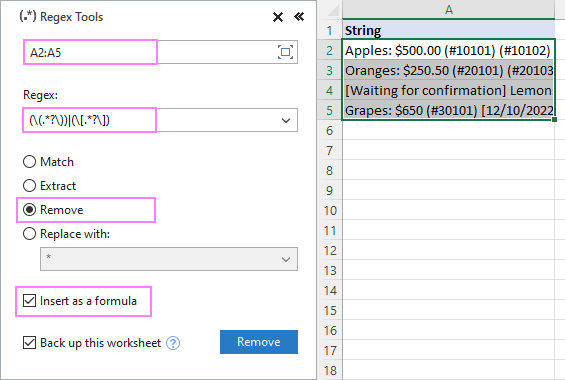
Selle tulemusena on AblebitsRegexRemove funktsioon sisestatakse uude veergu teie algsete andmete kõrvale.
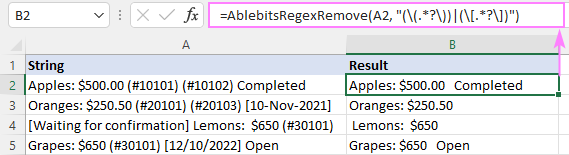
Funktsiooni saab sisestada ka otse lahtrisse standardse Sisestage funktsioon dialoogiaknas, kus see on kategoriseeritud kategooriasse AblebitsUDFs .
Nagu AblebitsRegexRemove on mõeldud teksti eemaldamiseks, see nõuab ainult kahte argumenti - lähtekriipsu ja regexi. Mõlemad parameetrid saab määratleda otse valemis või esitada lahtriviidete kujul. Vajaduse korral saab seda kohandatud funktsiooni kasutada koos mis tahes algupärase funktsiooniga.
Näiteks, et kärpida saadud stringides olevaid tühikuid, saate kasutada funktsiooni TRIM ümbritsevana:
=TRIM(AblebitsRegexRemove(A5, $A$2))
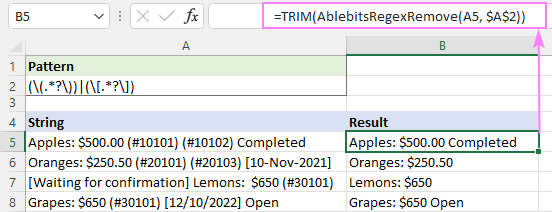
See on, kuidas eemaldada stringid Excelis kasutades regulaarseid väljendeid. Tänan teid lugemise eest ja ootan teid järgmisel nädalal meie blogis!
Saadaolevad allalaadimised
Stringide eemaldamine regexi abil - näited (.xlsm fail)
Ultimate Suite - prooviversioon (.exe fail)
