
Tabloya naverokê
Di rêzikên jêrîn de, bihesibînin ku hûn dixwazin hejmara rêza yekem jêbikin. Hemî jimarên weha bi nîşana hash (#) dest pê dikin û tam 5 reqem hene. Ji ber vê yekê, em dikarin wan bi karanîna vê regexê nas bikin:
Pattern : #\d{5}\b
Peyva boundary \b diyar dike ku binerêzek lihevhatî nabe. beşek ji rêzikek mezintir wek #10000001.
Ji bo rakirina hemî hevberdanê, argumana numala_num nayê diyarkirin:
=RegExpReplace(A5, "#\d{5}\b", "")
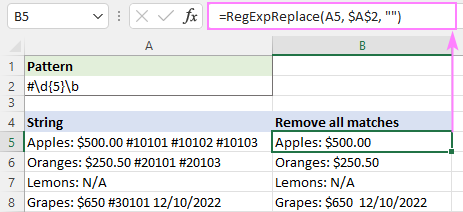
Ji bo ku tenê bûyera yekem ji holê rakin, me argumana numala_num danî 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex ji bo rakirina hin tîpan
Ji bo ku hin tîpan ji rêzekê derxînin, tenê hemî tîpên nexwestî binivîsin û wan bi barek vertîkal ji hev veqetînin.hevoksaziya bê sînorkirinên VBA RegExp, û ya duyemîn, ne hewce ye ku kodek VBA di pirtûkên xwe de têxe nav pirtûkên xwe de ji ber ku hemî yekbûna kodê ji hêla me ve li paşiya paşerojê tê kirin.
Beşê karê we ev e ku hûn vegotinek birêkûpêk ava bikin û wê ji fonksiyonê re xizmet bike :) Bihêle ez li ser mînakek pratîkî nîşanî we bidim ka meriv çawa wiya dike.
Meriv çawa bi karanîna regex nivîsa di nav bend û parantezê de jê dike
Di rêzikên nivîsa dirêj de, agahdariya kêm girîng gelek caran di nav [kelek] û (parantezê) de tê girtin. Meriv çawa van hûrguliyên negirêdayî ku hemî daneyên din diparêze radike?
Bi rastî, me jixwe ji bo jêbirina etîketên html-ê, ango nivîsa di nav kemberên goşeyê de, regeksek wusa çêkiriye. Eşkere ye ku heman rêbaz dê ji bo kelepên çargoşe û dor jî bixebitin.
Şablon : (\(.*?\))
Ma we qet fikirî ku Excel dê çiqas bi hêz be ger kesek karibe qutiya amûra xwe bi vegotinên birêkûpêk dewlemend bike? Me ne tenê fikirî, lê li ser xebitî :) Û naha, hûn dikarin vê fonksiyona RegEx-a hêja li pirtûkên xwe yên xebatê zêde bikin û di demek zû de binerdeyên ku bi şêwazê lihevhatî ne ji holê rakin!
Hefteya çûyî, me nihêrî ka meriv çawa îfadeyên birêkûpêk bikar tîne da ku rêzikên di Excel de biguhezîne. Ji bo vê, me fonksiyonek Regex Replace ya xwerû çêkir. Wekî ku derket holê, fonksiyon ji karanîna xweya bingehîn derbas dibe û ne tenê dikare rêzan biguhezîne lê di heman demê de wan jî rake. Çawa dibe ku bibe? Di warê Excel de, rakirina nirxek ne tiştek din e ji bilî şûna wê bi rêzek vala, tiştek ku fonksiyona meya Regex jê re pir baş e!
Fonksiyon VBA RegExp ji bo rakirina binerdeyên li Excel
Wekî ku em hemî dizanin, îfadeyên birêkûpêk di Excel de ji hêla xwerû ve nayê piştgirî kirin. Ji bo çalakkirina wan, hûn hewce ne ku fonksiyona xweya bikarhêner-ê diyarkirî biafirînin. Mizgîn ev e ku fonksiyonek wusa jixwe hatî nivîsandin, ceribandin û ji bo karanîna amade ye. Tiştê ku divê hûn bikin ev e ku hûn vê kodê kopî bikin, wê di edîtorê VBA-ya xwe de bixin û paşê pelê xwe wekî pirtûka xebatê ya çalak-makro (.xlsm) hilînin.
Fonksiyon xwedî hevoksaziya jêrîn:
RegExpReplace(text, nimûne, veguherandin, [numûn_num], [match_case])Sê argumanên pêşîn hewce ne, du yên dawîn vebijarkî ne.
Li ku:
- Text - rêzika nivîsê ya lêgerînêmimkun e heya ku ew bendek girtinê bibîne.
Hûn kîjan nimûneyê hilbijêrin, dê encam bi tevahî yek be.
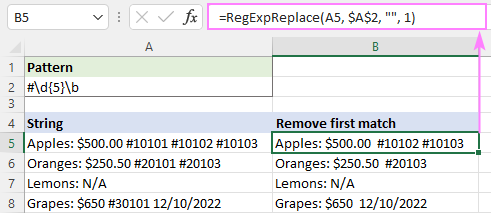
Mînakî, ji bo rakirina hemî tagên html ji rêzek di A5 de û hiştina nivîsê, formula ev e:
=RegExpReplace(A5, "]*>", "")
An jî hûn dikarin pîvana lazy wekî ku di dîmenê de tê xuyang kirin bikar bînin:
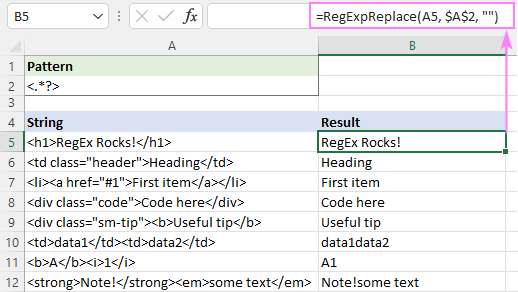
Ev çareserî ji bo bêkêmasî dixebite nivîsa yekane (rêzên 5 - 9). Ji bo gelek nivîsan (rêzên 10 - 12), encam gumanbar in - nivîsên ji tagên cûda di yek de têne yek kirin. Ev rast e an na? Ez ditirsim, ew ne tiştek e ku meriv bi hêsanî biryar bide - hemî bi têgihîştina we ya encama xwestinê ve girêdayî ye. Mînakî, di B11 de, encama "A1" tête hêvî kirin; dema di B10 de, dibe ku hûn bixwazin "data1" û "data2" bi valahiyek ji hev bên veqetandin.
Ji bo rakirina tagên html û veqetandina nivîsên mayî bi valahî, hûn dikarin bi vî rengî bimeşin:
30>
=RegExpReplace(A5, "]*>", " ")
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ")
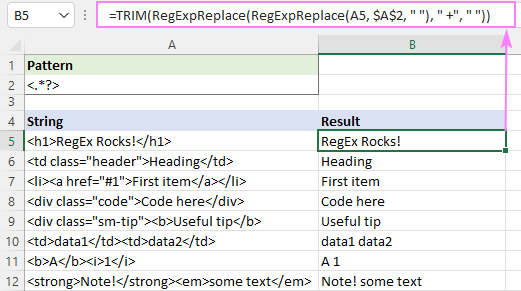
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
Encam dê bi vî rengî xuya bike:
Ablebits Regex Remove Tool
Heke we şansek hebû ku hûn Suite Ultimate ji bo Excel-ê bikar bînin, belkî we jixwe Amûrên Regex-ê yên nû ku bi serbestberdana vê dawîyê re hatine destnîşan kirin keşf kirine. Bedewiya van fonksiyonên Regex-ê yên bingehîn .NET ev e ku ew, pêşî, piştgirîya îfadeya birêkûpêk-tevger dikin.vebijarka Rake , û Rake bitikîne.
Ji bo ku encaman wek formul, ne nirx, bi dest bixin, qutika Wek formulê têxe hilbijêrin.
Ji bo ku metna di nav kevokan de ji rêzikên di A2:A5 de jê bibe, em mîhengan pêk tînin. bi vî rengî:
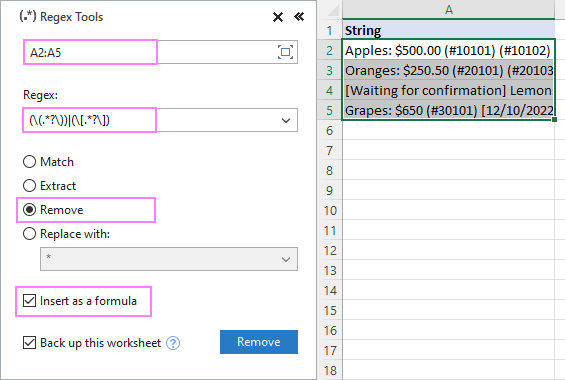
Di encamê de fonksiyona AblebitsRegexRemove di stûnek nû de li kêleka daneya weya resen tê danîn.
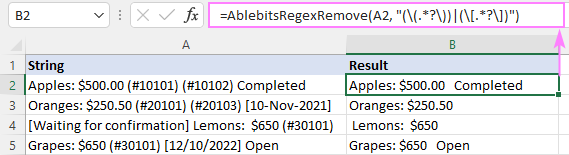
Fonksiyon di heman demê de rasterast di nav şaneyek de dikare bi riya qutiya diyalogê ya standard Fonksiyon Têxe , ku li wir di binê AblebitsUDFs de tê categorîzekirin, were danîn.
Ji ber ku AblebitsRegexRemove ji bo rakirina nivîsê hatiye sêwirandin, tenê du argumanan hewce dike - rêzika çavkaniyê û regex. Her du parameter dikarin rasterast di formulak de bêne diyar kirin an jî di forma referansên hucreyê de bêne peyda kirin. Ger hewce be, ev fonksiyona xwerû dikare bi hemî yên xwemalî re bi hev re were bikar anîn.
Mînakî, ji bo qutkirina cîhên zêde di rêzikên encam de, hûn dikarin fonksiyona TRIM-ê wekî pêçek bikar bînin:
=TRIM(AblebitsRegexRemove(A5, $A$2))
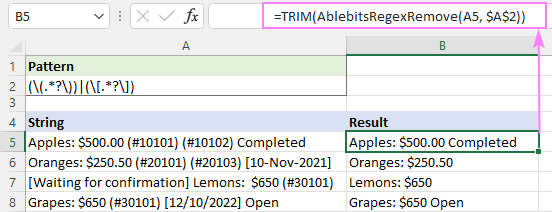
Bi vî rengî meriv di Excel-ê de rêzikên bi karanîna birêkûpêk jêbirin. Ez spasiya te dikim ji bo xwendinê û hêvî dikim ku hefteya bê te li ser bloga me bibînim!
Daxistinên berdest
Rakirina rêzan bi karanîna regex - mînakan (pelê .xlsm)
Ultimate Suite - Guhertoya ceribandinê (pelê .exe)
in.Ji bo bêtir agahdarî, ji kerema xwe li fonksiyona RegExpReplace binêre.
Tip. Di rewşên hêsan de, hûn dikarin bi formulên Excel tîpan an peyvan ji hucreyan derxînin. Lê biwêjên rêkûpêk ji bo vê yekê gelek vebijarkên din peyda dikin.
Çawa meriv bi karanîna biwêjên rêkûpêk rêzan jê dike - mînak
Wek ku li jor hatî behs kirin, ji bo rakirina beşên nivîsê yên ku bi şêwazê lihevhatî ne, divê hûn wan biguhezînin. bi têlek vala. Ji ber vê yekê, formulek gelemperî vî rengî digire:
RegExpReplace(text, nimûne, "", [numûn_num], [match_case])Mînakên jêrîn pêkanînên cihêreng ên vê têgeha bingehîn nîşan didin.
Rake hemî hevberdan an hevhevhatina taybetî
Fonksiyon RegExpReplace ji bo dîtina hemî binerxên ku bi regeksek diyarkirî re têkildar in, hatî sêwirandin. Kîjan rûdanên ku werin rakirin ji hêla argumana bijartî ya 4emîn ve têne kontrol kirin, bi navê numûn_num .
Pêşveçûn "hemû lihevhatin" e - dema ku numûn_numûna operatora hevgirtinê (&) û fonksiyonên nivîsê yên wekî RIGHT, MID û LEFT.
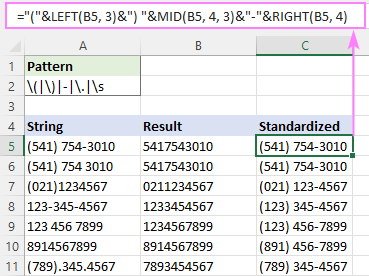
Mînakî, ji bo nivîsandina hemî hejmarên têlefonê di forma (123) 456-7890 de, formula ev e:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
Cîhê ku B5 derencama fonksiyona RegExpReplace ye.
Bi karekterên taybet regex rakin
Di yek ji dersên me de, me nihêrî ka meriv çawa karakterên nedilxwaz li Excel-ê bi karanîna fonksiyonên xwerû û xwerû jêbirin. Gotinên birêkûpêk tiştan pir hêsantir dike! Li şûna ku hûn hemî tîpan binivîsin ku hûn jêbikin, tenê yên ku hûn dixwazin bihêlin diyar bikin :)
Nimûne li ser derfên karakterên negatîfkirî ye - xelekek di hundurê çînek karakteran de tê danîn [^ ] ji bo ku her karakterek yekane NE di nav kevanan de li hev bikin. Pîvana + wê neçar dike ku tîpên li pey hev wek hevhevokekê bihesibîne, ji ber vê yekê ji bo her karakterek ferdî şûna wê ji bo binerêzek lihevhatî were kirin.
Li gorî hewcedariyên we, yek ji regezên jêrîn hilbijêrin.
Ji bo rakirina tîpên ne-hejmarî , ango hemû tîpan ji xeynî tîp û jimareyan:
Nablo : [^0-9a-zA-Z] +
Ji bo paqijkirina hemû tîpan ji bilî tîpan , hejmaran û valahiyan :
Şablon : [^0-9a-zA-Z ]+
Ji bo jêbirina hemû tîpan ji xeynî tîpan , hejmaran û binxetê , hûn dikarin \ bi kar bînin W ku ji bo her karakterek ku NE karaktera alfan-hejmarî ye an jî radiwestebinxetê:
Şablon : \W+
Heke hûn dixwazin hinek tîpên din bihêlin , wek mînak. Nîşanên xalbendiyê, wan bixin hundirê kevanan.
Mînakî, ji bilî herf, jimar, xal, komma, an valahiyê her karakterekî din jêbirin, regeksa jêrîn bikar bînin:
Nimûne : [^0-9a-zA-Z\., ]+
Ev bi serketî hemû tîpên taybet ji holê radike, lê cîhê spî yê zêde dimîne.
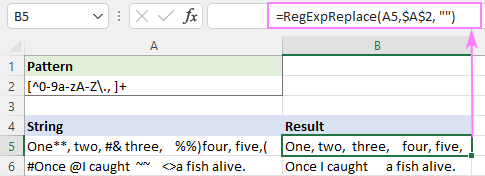
Ji bo rastkirina vê yekê, hûn dikarin fonksiyona jorîn di nav yekî din de hêlîn bikin ku çend ciyan bi karakterek cîhê yekane veguhezîne.
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
An jî tenê fonksiyona xwemalî ya TRIM bi heman bandorê bikar bînin :
=TRIM(RegExpReplace(A5, $A$2, ""))
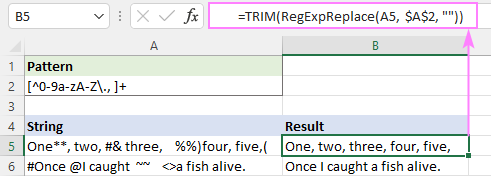
Regex ji bo rakirina tîpên nehejmar
Ji bo jêbirina hemû tîpên nehejmarî ji rêzekê, hûn dikarin bikar bînin. ev formula dirêj an yek ji regezên pir hêsan ên ku li jêr hatine rêz kirin.
Her karakterek ku NE reqem e bi hev re bidin hev:
Pattern : \D+
Karakterên ne-hejmarî bi karanîna çînên negatîf qut bikin:
Şablon : [^0-9]+
Şablon : [^\d] +
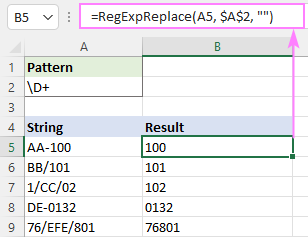
Şîret. Ger mebesta we ev e ku hûn nivîsê jê bikin û hejmarên mayî biherikînin hucreyên cihê, an jî wan hemîyan li yek hucreyek ku bi veqetandek diyarkirî veqetandî bi cîh bikin, wê hingê fonksiyona RegExpExtract bikar bînin wekî ku di Meriv çawa bi karanîna birêkûpêk jimareyan ji rêzê veqetîne bikar bînin.
Regex ji bo rakirina her tiştî piştî valahiyê
Ji bo rakirina her tiştî piştî valahiyê, valahiya ( ) anKaraktera vala spî (\s) ji bo dîtina cîhê yekem û .* ji bo ku her tîpên li dû wê bigihêje hev.
Heke rêzikên we yên yek-xêz hene ku tenê cîhên normal dihewîne (nirxa 32 di pergala 7-bit ASCII de) , bi rastî ne girîng e ku hûn kîjan ji regezên jêrîn bikar tînin. Di rewşên rêzikên pir-xêz de, ew cûdahiyek çêdike.
Ji bo rakirina her tiştî piştî karakterek valahiyê , vê regexê bikar bînin:
Pattern : " .*"
=RegExpReplace(A5, " .*", "")
Ev formula dê li her rêzê her tiştî piştî valahiya yekem jê bike. Ji bo ku encam rast werin xuyang kirin, ji bîr nekin ku Wrap Text çalak bikin.
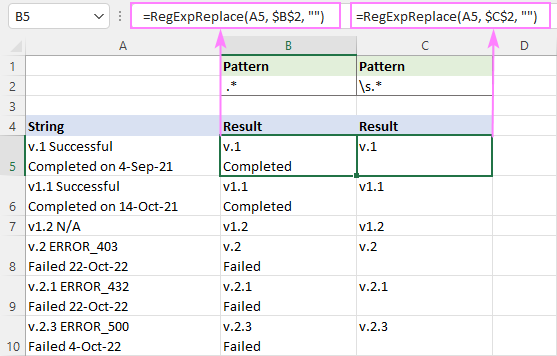
Ji bo rakirina her tiştî piştî valahiyek spî (di nav de cihek, tablo, vegera gerîdeyê û rêzek nû), regex ev e:
Nablo : \s.*
=RegExpReplace(A5, "\s.*", "")
Ji ber ku \s çend cureyên cihê spî di nav de xêzeke nû (\n), ev formula piştî cîhê yekem di şaneyê de, her tiştê ku tê de çend xêz hebin, jê dibire.
Regex ku nivîsê piştî taybetî jê bike. karakter
Bi bikaranîna rêbazên ji mînaka berê, tu dikarî nivîsê piştî her karakterê ku tu diyar bikî ji holê rakî.
Ji bo birêvebirina her rêzê ji hev cuda:
Nimûneya giştî : char.*
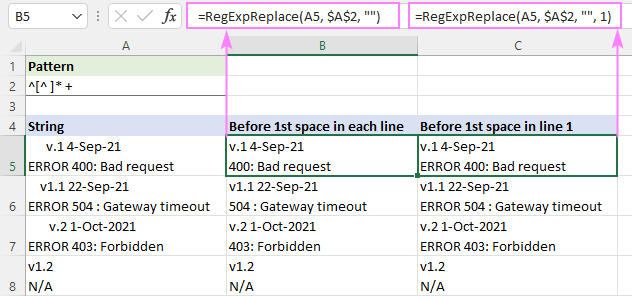
Di rêzikên yek-xêz de, ev ê her tiştî piştî char rake. Di rêzikên pir-xêz de, her rêz dê bi rengek ferdî were hilberandin ji ber ku di tama VBA Regex de, serdemek (.) ji bilî karakterek nû bi her karakterê re li hev dike.destpêka rêzek ^, em sifir an jî zêdetir tîpên ne cihê [^ ]* yên ku tavilê bi yek an jî çend cihan " +" tên dûv hev didin hev. Beşa paşîn tê zêdekirin da ku di encaman de cîhên pêşeng ên potansiyel neyên girtin.
Ji bo rakirina nivîsê berî cîhê yekem di her rêzê de, formula di moda "hemû lihevhatinan" ya xwerû de tê nivîsandin ( numûn_numne jêbirin):
=RegExpReplace(A5, "^[^ ]* +", "")
Ji bo ku nivîsa berî cîhê yekem di rêza yekem de jê bibe, û hemî rêzikên din saxlem bihêlin, argumana numala_num wekî 1 tê danîn:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex ku her tiştî berî karakterê jêke
Rêya herî hêsan ku meriv hemî nivîsê berî karakterek taybetî jê bibe bi karanîna regexek e. bi vî rengî:
Nimûneya giştî : ^[^char]*char
Ji bo zimanê mirovî hatiye wergerandin, dibêje: "ji destpêka têlekî ku ji aliyê ^ , ji bilî char [^char]* ji bilî char [^char]* 0 yan jî zêdetir tîpan bidin hev.
Mînakî, ji bo jêbirina hemû nivîsê berî dubendiya yekem , vê îfadeya rêkûpêk bikar bînin:
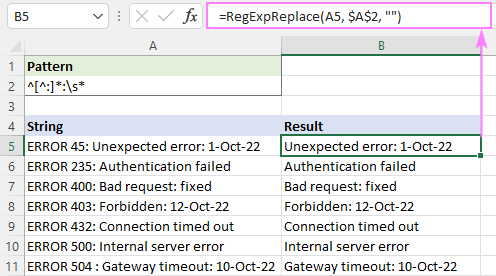
Pattern : ^[^:]*:
Ji bo ku di encaman de cîhên sereke dûr nekevin, karekterek cîhê spî \s* lê zêde bikin Ev ê her tiştî jê bike g berî dubendiya yekem û cihan rast li dû wê bibire:
Nablo : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
Şîret. Ji bilî vegotinên birêkûpêk, Excel rêgezên xwe hene ku nivîsê ji hêla pozîsyonê an hevrêzê ve jêbirin. Ji bo fêrbûna ka meriv çawa bi formulan xwemalî peywirê pêk tîne,Ji kerema xwe binihêrin Meriv çawa nivîsê berî an piştî karakterek di Excel de jê dike.
Regex ji bo rakirina her tiştî ji bilî
Ji bo rakirina hemî tîpan ji rêzê ji bilî yên ku hûn dixwazin bihêlin, çînên karakterên negatîf bikar bînin.
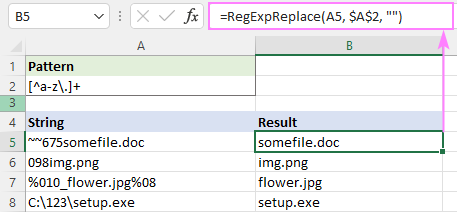
Mînakî, ji bilî tîpên piçûk hemî tîpan jêbirin. û xalan, regex ev e:
Pêşen : [^a-z\.]+
Di rastiyê de, em dikarin li vir bêyî pîvana + bikin ji ber ku fonksiyona me li şûna hemî maç dîtin. Pîvan tenê hinekî bileztir dike - li şûna ku hûn her karakterek kesane bi dest bixin, hûn rêzek binecihê biguhezînin.
=RegExpReplace(A5, "[^a-z\.]+", "")
Regex ji bo rakirina tagên html di Excel de
Destpêkê, divê were zanîn ku HTML ne zimanek birêkûpêk e, ji ber vê yekê parkirina wê bi karanîna bêjeyên birêkûpêk ne awayê çêtirîn e. Ji ber vê yekê, regexes bê guman dikarin alîkariyê bikin ku etîketan ji hucreyên we derxînin da ku databasa we paqijtir bikin.
Ji ber ku etîketên html her gav di nav kevokên goşeyê de têne danîn, hûn dikarin wan bi karanîna yek ji regezên jêrîn bibînin.
Çîna negatîf:
Şablon : ]*>
Li vir, em bendek goşeya vekirinê li hev dikin, li dû wê sifir an jî zêdetir bûyerên her karakterî ji bilî kilama goşeya girtinê [^>]* heta kêşeya girtina goşeya herî nêzîk.
Lêgerîna lazy:
Pattern :
Li vir, em li hev dikin her tişt ji bendika vekirina yekem heya bendika yekem a girtinê. Nîşana pirsê zorê dide .* ku bi qasî çend tîpan li hev bikexêz.
Ji bo ku hemû rêzikan wekî rêzek yekane bişopîne:
Nimûneya giştî : char(.
