
မာတိကာ
အောက်ပါစာကြောင်းများတွင်၊ သင်သည် ပထမအမှာစာနံပါတ်ကို ဖျက်လိုသည်ဆိုပါစို့။ ထိုဂဏန်းများအားလုံးသည် hash သင်္ကေတ (#) ဖြင့် စတင်ပြီး ဂဏန်း 5 လုံးတိတိ ပါဝင်ပါသည်။ ထို့ကြောင့်၊ ဤ regex ကို အသုံးပြု၍ ၎င်းတို့ကို ကျွန်ုပ်တို့ ခွဲခြားနိုင်သည်-
Pattern : #\d{5}\b
စကားလုံး နယ်နိမိတ် \b သည် ကိုက်ညီသော စာကြောင်းခွဲတစ်ခု မဖြစ်နိုင်ကြောင်း သတ်မှတ်သည် ။ #10000001 ကဲ့သို့သော ပိုကြီးသောစာကြောင်း၏တစ်စိတ်တစ်ပိုင်း။
ကိုက်ညီမှုအားလုံးကိုဖယ်ရှားရန်၊ instance_num အငြင်းအခုံကို သတ်မှတ်မထားပါ။
=RegExpReplace(A5, "#\d{5}\b", "")
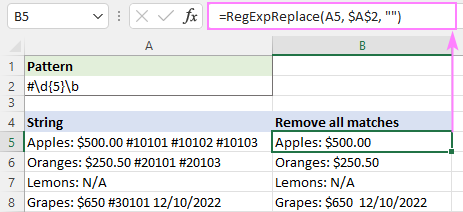
ပထမဖြစ်ပွားမှုကိုသာ ဖျက်ပစ်ရန်၊ ကျွန်ုပ်တို့သည် instance_num အငြင်းအခုံကို 1:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex အချို့သော ဇာတ်ကောင်များကို ဖယ်ရှားရန်
စာကြောင်းတစ်ခုမှ အချို့သော ဇာတ်ကောင်များကို ဖယ်ရှားရန်၊ မလိုအပ်သော စာလုံးအားလုံးကို ချရေးပြီး ဒေါင်လိုက်ဘားဖြင့် ခွဲရုံသာဖြစ်သည်။VBA RegExp ကန့်သတ်ချက်များ ကင်းစင်သော syntax နှင့် ဒုတိယအချက်မှာ၊ နောက်ကွယ်တွင် ကျွန်ုပ်တို့မှ ကုဒ်ပေါင်းစည်းမှုကို လုပ်ဆောင်သောကြောင့် သင့်အလုပ်စာအုပ်များတွင် မည်သည့် VBA ကုဒ်ကိုမျှ ထည့်သွင်းရန် မလိုအပ်ပါ။
သင့်အလုပ်၏ တစ်စိတ်တစ်ပိုင်းသည် ပုံမှန်အသုံးအနှုန်းကို တည်ဆောက်ရန်နှင့်၊ ၎င်းကို လုပ်ဆောင်ချက်အတွက် ဆောင်ရွက်ပေးပါ :) လက်တွေ့နမူနာတစ်ခုတွင် ၎င်းကို မည်သို့လုပ်ဆောင်ရမည်ကို ကျွန်ုပ်ပြပါရစေ။
regex ကို အသုံးပြု၍ ကွင်းစကွင်းပိတ်နှင့် ကွင်းအတွင်းမှ စာသားများကို ဖယ်ရှားနည်း
ရှည်လျားသော စာသားစာကြောင်းများတွင် အရေးမကြီးသော အချက်အလက်၊ [ကွင်းကွင်းများ] နှင့် (ကွင်းကွင်း) တွင် မကြာခဏ ဝိုင်းရံထားသည်။ အခြားဒေတာအားလုံးကို ထိန်းသိမ်းထားသည့် မသက်ဆိုင်သောအသေးစိတ်အချက်အလက်များကို သင်မည်သို့ဖယ်ရှားမည်နည်း။
တကယ်တော့၊ ကျွန်ုပ်တို့သည် html တဂ်များကို ဖျက်ရန်အတွက် အလားတူ regex တစ်ခုကို တည်ဆောက်ထားပြီးဖြစ်သည်၊ ဆိုလိုသည်မှာ angle brackets အတွင်းရှိ စာသားများဖြစ်သည်။ သေချာသည်မှာ၊ တူညီသောနည်းလမ်းများသည် စတုရန်းနှင့် အဝိုင်းကွင်းကွင်းများအတွက်လည်း အလုပ်ဖြစ်ပါမည်။
Pattern : (\.*?\))
တစ်စုံတစ်ဦးသည် ၎င်း၏ toolbox ကို ပုံမှန်အသုံးအနှုန်းများဖြင့် ဖြည့်စွမ်းပေးနိုင်ပါက Excel မည်မျှ အစွမ်းထက်မည်ဟု သင်တွေးဖူးပါသလား။ ကျွန်ုပ်တို့သည် စဉ်းစားရုံသာမက လုပ်ဆောင်ခဲ့သည် :) ယခု၊ သင်သည် ဤအံ့သြဖွယ်ကောင်းသော RegEx လုပ်ဆောင်ချက်ကို သင့်ကိုယ်ပိုင်အလုပ်စာအုပ်များတွင် ထည့်သွင်းပြီး ပုံစံတစ်ခုနှင့်ကိုက်ညီသည့် စာကြောင်းခွဲများကို အချိန်တိုအတွင်း ဖယ်ရှားနိုင်သည်!
ပြီးခဲ့သောအပတ်က ကျွန်ုပ်တို့ကြည့်ရှုခဲ့သည်။ Excel ရှိ စာကြောင်းများကို အစားထိုးရန် ပုံမှန်အသုံးအနှုန်းများကို အသုံးပြုနည်း။ ယင်းအတွက်၊ ကျွန်ုပ်တို့သည် စိတ်ကြိုက် Regex Replace လုပ်ဆောင်ချက်ကို ဖန်တီးခဲ့သည်။ ထွက်လာသည့်အတိုင်း၊ လုပ်ဆောင်ချက်သည် ၎င်း၏အဓိကအသုံးပြုမှုထက်ကျော်လွန်သွားပြီး ကြိုးများကို အစားထိုးရုံသာမက ၎င်းတို့ကိုလည်း ဖယ်ရှားနိုင်သည်။ အဲဒါ ဘယ်လိုဖြစ်နိုင်မလဲ။ Excel ၏ စည်းကမ်းချက်များအရ၊ တန်ဖိုးတစ်ခုကို ဖယ်ရှားခြင်းမှာ ၎င်းကို ဗလာစာကြောင်းတစ်ခုဖြင့် အစားထိုးခြင်းမှတပါး အခြားမဟုတ်ပါ၊ ကျွန်ုပ်တို့၏ Regex လုပ်ဆောင်ချက်သည် အလွန်ကောင်းမွန်သော အရာတစ်ခုဖြစ်သည်။
Excel ရှိ စာကြောင်းခွဲများကိုဖယ်ရှားရန် VBA RegExp လုပ်ဆောင်ချက်
ကျွန်ုပ်တို့အားလုံးသိသည့်အတိုင်း၊ ပုံမှန်အသုံးအနှုန်းများကို ပုံသေအားဖြင့် Excel တွင် ပံ့ပိုးမထားပါ။ ၎င်းတို့ကို ဖွင့်ရန်၊ သင့်ကိုယ်ပိုင် အသုံးပြုသူသတ်မှတ်ထားသော လုပ်ဆောင်ချက်ကို ဖန်တီးရန် လိုအပ်သည်။ သတင်းကောင်းမှာ ထိုသို့သောလုပ်ဆောင်ချက်ကို ရေးသားထားပြီး၊ စမ်းသပ်ပြီး အသုံးပြုရန် အသင့်ဖြစ်နေပြီဖြစ်သည်။ သင်လုပ်ရမှာက ဒီကုဒ်ကို မိတ္တူကူးပြီး၊ သင့် VBA တည်းဖြတ်မှုမှာ ကူးထည့်ပါ၊ ထို့နောက် သင့်ဖိုင်ကို macro-enabled workbook (.xlsm) အဖြစ် သိမ်းဆည်းပါ။
လုပ်ဆောင်ချက် ပါရှိပါတယ်။ အောက်ပါအထားအသို-
RegExpReplace(စာသား၊ ပုံစံ၊ အစားထိုး၊ [instance_num]၊ [match_case])ပထမ အကြောင်းပြချက် သုံးခု လိုအပ်သည်၊ နောက်ဆုံး နှစ်ခုသည် စိတ်ကြိုက်ရွေးချယ်နိုင်သည်။
နေရာ-
- Text - ရှာဖွေရန် စာသားစာတန်းအပိတ်ကွင်းပိတ်တစ်ခုကို ရှာမတွေ့မချင်း ဖြစ်နိုင်သည်။
သင်ရွေးချယ်သည့်ပုံစံအတိုင်း ရလဒ်သည် လုံးဝတူညီမည်ဖြစ်သည်။
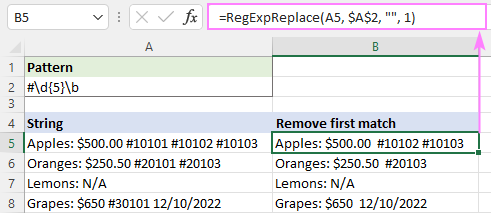
ဥပမာ၊ A5 ရှိ စာကြောင်းတစ်ခုမှ html တဂ်များအားလုံးကို ဖယ်ရှားပြီး စာသားချန်ထားရန်၊ ဖော်မြူလာမှာ-
=RegExpReplace(A5, "]*>", "")
သို့မဟုတ် ဖန်သားပြင်တွင် ပြထားသည့်အတိုင်း ပျင်းရိသည့်ပမာဏကို သင်သုံးနိုင်သည်-
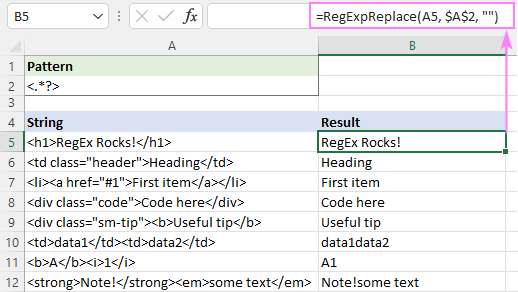
ဤဖြေရှင်းချက်သည် ကောင်းမွန်စွာအလုပ်လုပ်ပါသည်။ စာသားတစ်ခုတည်း (အတန်း ၅ - ၉)။ စာသားအများအပြား (အတန်း 10 မှ 12) အတွက် ရလဒ်များသည် မေးခွန်းထုတ်စရာဖြစ်သည် - မတူညီသော tag များမှ စာသားများကို တစ်ခုတည်းအဖြစ် ပေါင်းစပ်ထားသည်။ ဒါက မှန်သလား မမှန်ဘူးလား။ ငါကြောက်တယ်၊ အဲဒါက လွယ်လွယ်ကူကူ ဆုံးဖြတ်လို့ရတဲ့ အရာမဟုတ်ဘူး - အားလုံးလိုချင်တဲ့ ရလဒ်ကို မင်းနားလည်မှုပေါ်မှာ မူတည်တယ်။ ဥပမာအားဖြင့်၊ B11 တွင် ရလဒ် "A1" ကို မျှော်လင့်ထားသည်။ B10 တွင်ရှိနေစဉ်၊ သင်သည် "data1" နှင့် "data2" ကို နေရာလွတ်တစ်ခုဖြင့် ခွဲထားလိုပေမည်။
html တဂ်များကို ဖယ်ရှားပြီး ကျန်စာသားများကို နေရာလွတ်များဖြင့် ခွဲရန်၊ သင်သည် ဤနည်းဖြင့် ဆက်လက်လုပ်ဆောင်နိုင်သည်-
- တဂ်များကို နေရာလွတ် " "၊ အလွတ်စာကြောင်းများမဟုတ်ဘဲ အစားထိုးပါ-
=RegExpReplace(A5, "]*>", " ") - နေရာလွတ်များစွာကို စာလုံးတစ်လုံးတည်းသို့ နေရာလွတ်များစွာ လျှော့ချပါ-
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - ရှေ့ဆောင်နှင့် နောက်လိုက်နေရာများကို ဖြတ်တောက်ပါ-
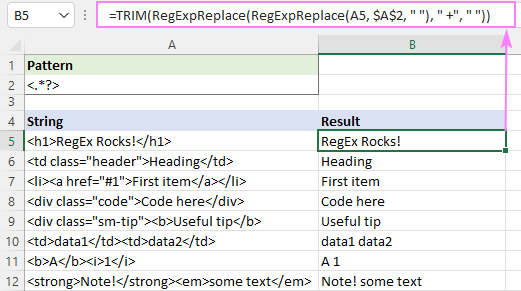
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
ရလဒ်သည် ဤကဲ့သို့ဖြစ်မည်-
Ablebits Regex Remove Tool
ကျွန်ုပ်တို့၏ Excel အတွက် Ultimate Suite ကို သင်အသုံးပြုခွင့်ရခဲ့ပါက၊ မကြာသေးမီကထွက်ရှိထားသော Regex Tools အသစ်ကို သင်ရှာဖွေတွေ့ရှိပြီးဖြစ်နိုင်ပါသည်။ ဤ .NET အခြေပြု Regex လုပ်ဆောင်ချက်များ၏ လှပမှုသည် ပထမဦးစွာ ၎င်းတို့သည် အင်္ဂါရပ်ပြည့် ပုံမှန်ဖော်ပြမှုကို ပံ့ပိုးပေးသောကြောင့်ဖြစ်သည်။ Remove option ကို နှိပ်ပြီး Remove ကိုနှိပ်ပါ။
ရလဒ်များကို ဖော်မြူလာအဖြစ်၊ တန်ဖိုးများမဟုတ်ဘဲ၊ ဖော်မြူလာအဖြစ် ထည့်သွင်းပါ အမှတ်ခြစ်အကွက်ကို ရွေးပါ။
A2:A5 ရှိ စာကြောင်းများမှ ကွင်းပိတ်များအတွင်း စာသားများကို ဖယ်ရှားရန်၊ ဆက်တင်များကို ကျွန်ုပ်တို့ စီစဉ်သတ်မှတ်ပေးပါသည်။ အောက်ပါအတိုင်းဖြစ်သည်-
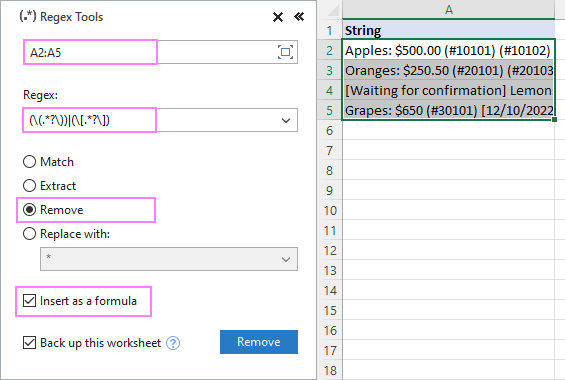
ရလဒ်အနေဖြင့်၊ AblebitsRegexRemove လုပ်ဆောင်ချက်ကို သင့်မူရင်းဒေတာဘေးရှိ ကော်လံအသစ်တွင် ထည့်သွင်းပါသည်။
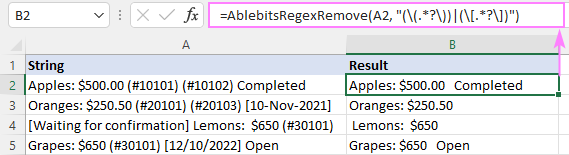
လုပ်ဆောင်ချက်ကို AblebitsUDFs အောက်တွင် အမျိုးအစားခွဲခြားထားသည့် စံ လုပ်ဆောင်ချက်ထည့်သွင်းခြင်း ဒိုင်ယာလော့အကွက်မှတစ်ဆင့် ဆဲလ်တစ်ခုအတွင်းသို့လည်း တိုက်ရိုက်ထည့်သွင်းနိုင်သည်။
AblebitsRegexRemove သည် စာသားကို ဖယ်ရှားရန် ဒီဇိုင်းထုတ်ထားသောကြောင့် ၎င်းသည် အကြောင်းပြချက်နှစ်ခုသာ လိုအပ်သည် - အရင်းအမြစ်စာကြောင်းနှင့် regex။ ဘောင်နှစ်ခုလုံးကို ဖော်မြူလာတစ်ခုတွင် တိုက်ရိုက်သတ်မှတ်နိုင်သည် သို့မဟုတ် ဆဲလ်ကိုးကားမှုပုံစံဖြင့် ပံ့ပိုးပေးနိုင်သည်။ လိုအပ်ပါက၊ ဤစိတ်ကြိုက်လုပ်ဆောင်ချက်ကို မည်သည့် မူရင်းအမျိုးအစားများနှင့်မဆို တွဲသုံးနိုင်သည်။
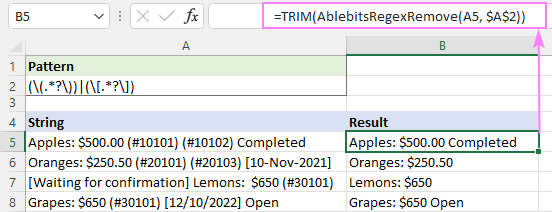
ဥပမာ၊ ရလာသောစာကြောင်းများတွင် အပိုနေရာများကို ချုံ့ရန်၊ သင်သည် TRIM လုပ်ဆောင်ချက်ကို wrapper အဖြစ် အသုံးပြုနိုင်သည်-
=TRIM(AblebitsRegexRemove(A5, $A$2))
၎င်းသည် ပုံမှန်အသုံးအနှုန်းများကို အသုံးပြု၍ Excel ရှိ စာကြောင်းများကို ဖယ်ရှားနည်းဖြစ်သည်။ ကျွန်ုပ်တို့၏ဘလော့ဂ်တွင် ဖတ်ရှုပြီး နောက်အပတ်တွင် သင့်ကိုတွေ့ရန် မျှော်လင့်သည့်အတွက် ကျေးဇူးတင်ပါသည်။
ရရှိနိုင်သောဒေါင်းလုဒ်များ
regex ကိုအသုံးပြု၍ စာကြောင်းများကို ဖယ်ရှားပါ - ဥပမာများ (.xlsm ဖိုင်)
Ultimate Suite - အစမ်းဗားရှင်း (.exe ဖိုင်)
ထဲတွင်။ပိုမိုသိရှိလိုပါက၊ RegExpReplace လုပ်ဆောင်ချက်ကို ကြည့်ပါ။
အကြံပြုချက်။ ရိုးရှင်းသောကိစ္စများတွင်၊ Excel ဖော်မြူလာများဖြင့် ဆဲလ်များမှ သီးခြားစာလုံး သို့မဟုတ် စကားလုံးများကို ဖယ်ရှားနိုင်သည်။ သို့သော် ပုံမှန်အသုံးအနှုန်းများသည် ၎င်းအတွက် ရွေးချယ်စရာများစွာကို ပေးစွမ်းပါသည်။
ပုံမှန်အသုံးအနှုန်းများကို အသုံးပြု၍ စာကြောင်းများကို ဖယ်ရှားနည်း - ဥပမာ
အထက်တွင်ဖော်ပြခဲ့သည့်အတိုင်း ပုံစံတစ်ခုနှင့်ကိုက်ညီသော စာသားအစိတ်အပိုင်းများကို ဖယ်ရှားရန်၊ ၎င်းတို့ကို အစားထိုးရမည်ဖြစ်ပါသည်။ ကြိုးအလွတ်တစ်ခုနှင့်။ ထို့ကြောင့်၊ ယေဘုယျဖော်မြူလာတစ်ခုသည် ဤပုံသဏ္ဍာန်ကို ယူဆောင်သည်-
RegExpReplace(စာသား၊ ပုံစံ၊ "", [instance_num], [match_case])အောက်ပါဥပမာများသည် ဤအခြေခံသဘောတရား၏ အကောင်အထည်ဖော်ဆောင်ရွက်မှုအမျိုးမျိုးကို ပြသသည်။
ဖယ်ရှားပါ။ ကိုက်ညီမှုအားလုံး သို့မဟုတ် တိကျသောကိုက်ညီမှု
RegExpReplace လုပ်ဆောင်ချက်သည် ပေးထားသော regex နှင့် ကိုက်ညီသော စာကြောင်းများအားလုံးကို ရှာဖွေရန် ဒီဇိုင်းထုတ်ထားသည်။ ဖယ်ရှားရန် မည်သည့်ဖြစ်ပျက်မှုများကို instance_num ဟုအမည်ပေးထားသည့် 4th ရွေးချယ်နိုင်သော အကြောင်းပြချက်ဖြင့် ထိန်းချုပ်ထားသည်။
ပုံသေမှာ "အားလုံးတူညီသည်" - instance_num ဖြစ်သောအခါ၊ဆက်စပ်အော်ပရေတာ (&) နှင့် ညာဘက်၊ အလယ်နှင့် လက်ဝဲကဲ့သို့သော စာသားလုပ်ဆောင်ချက်များ။
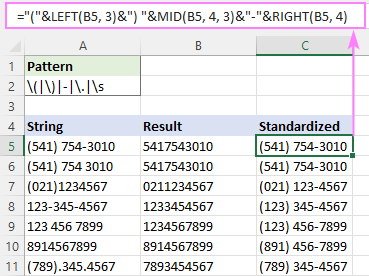
ဥပမာ၊ (123) 456-7890 ဖော်မတ်တွင် ဖုန်းနံပါတ်အားလုံးကိုရေးရန်၊ ဖော်မြူလာမှာ-
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
B5 သည် RegExpReplace လုပ်ဆောင်ချက်၏ ထွက်လာသည့်နေရာဖြစ်သည်။
regex ကို အသုံးပြု၍ အထူးဇာတ်ကောင်များကို ဖယ်ရှားပါ
ကျွန်ုပ်တို့၏ သင်ခန်းစာများထဲမှ တစ်ခုတွင်၊ inbuilt နှင့် custom functions များကို အသုံးပြု၍ Excel တွင် မလိုလားအပ်သော အက္ခရာများကို ဖယ်ရှားနည်းကို ကြည့်ရှုခဲ့ပါသည်။ ပုံမှန်အသုံးအနှုန်းများသည်အရာများကိုပိုမိုလွယ်ကူစေသည်။ ဖျက်ရန် စာလုံးအားလုံးကို စာရင်းပြုစုမည့်အစား သင်သိမ်းဆည်းလိုသော စာလုံးများကိုသာ သတ်မှတ်ပါ :)
ပုံစံသည် negated character classes အပေါ် အခြေခံသည် - caret တစ်ခုကို character class တစ်ခုအတွင်း ထည့်ထားသည် [^ ] ကွင်းပိတ်များတွင်မဟုတ်သော စာလုံးတစ်လုံးချင်းနှင့် ကိုက်ညီရန်။ + quantifier သည် ၎င်းအား ဆက်တိုက်ဇာတ်ကောင်များကို တူညီမှုတစ်ခုအဖြစ် မှတ်ယူရန် တွန်းအားပေးသည်၊ ထို့ကြောင့် ဇာတ်ကောင်တစ်ခုစီအတွက်မဟုတ်ဘဲ ကိုက်ညီသောစာကြောင်းခွဲတစ်ခုအတွက် အစားထိုးမှုကို လုပ်ဆောင်ပါသည်။
သင့်လိုအပ်ချက်ပေါ်မူတည်၍ အောက်ပါ regexe များထဲမှ တစ်ခုကို ရွေးချယ်ပါ။
အက္ခရာ အက္ခရာမဟုတ်သော အက္ခရာများကို ဖယ်ရှားရန်၊ ဆိုလိုသည်မှာ စာလုံးများနှင့် ဂဏန်းများမှလွဲ၍ အက္ခရာအားလုံးကို ဖယ်ရှားရန်-
Pattern - [^0-9a-zA-Z] +
စာလုံးများ အက္ခရာများမှလွဲ၍ ၊ ဂဏန်းများ နှင့် spaces :
Pattern - [^0-9a-zA-Z ]+
အက္ခရာများ အက္ခရာများမှလွဲ၍ ၊ ဂဏန်းများ နှင့် underscore ကို သင်သုံးနိုင်သည် W သည် အက္ခရာဂဏန်းမဟုတ်သော အက္ခရာ သို့မဟုတ် အက္ခရာတစ်ခုခုအတွက် ကိုယ်စားပြုသည်။underscore-
Pattern : \W+
သင် အခြားဇာတ်ကောင်အချို့ကို သိမ်းဆည်းလိုပါက ၊ ဥပမာ။ သတ်ပုံအမှတ်အသားများကို ကွင်းစကွင်းပိတ်အတွင်း ထည့်ပါ။
ဥပမာ၊ အက္ခရာ၊ ဂဏန်း၊ ကာလ၊ ကော်မာ သို့မဟုတ် နေရာလွတ်မှလွဲ၍ အခြားအက္ခရာများကို ဖယ်ထုတ်ရန် အောက်ပါ regex ကို အသုံးပြုပါ-
Pattern - [^0-9a-zA-Z\., ]+
၎င်းသည် အထူးဇာတ်ကောင်အားလုံးကို အောင်မြင်စွာ ဖယ်ရှားနိုင်သော်လည်း အပိုအဖြူကွက်ကျန်ရှိနေပါသည်။
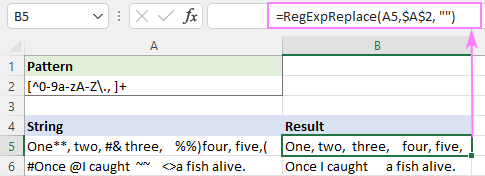
၎င်းကိုပြင်ဆင်ရန်၊ သင်သည် အထက်ဖော်ပြပါလုပ်ဆောင်ချက်ကို နေရာလွတ်တစ်ခုတည်းဖြင့် စာလုံးတစ်လုံးတည်းဖြင့် နေရာအများအပြားကို အစားထိုးသည့် အခြားတစ်ခုတွင် အစုအဝေးပြုလုပ်နိုင်ပါသည်။
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
သို့မဟုတ် တူညီသောအကျိုးသက်ရောက်မှုဖြင့် မူရင်း TRIM လုပ်ဆောင်ချက်ကို အသုံးပြုပါ။ :
=TRIM(RegExpReplace(A5, $A$2, ""))
ဂဏန်းမဟုတ်သော အက္ခရာများကို ဖယ်ရှားရန် Regex
စာကြောင်းမှ ဂဏန်းမဟုတ်သော စာလုံးအားလုံးကို ဖျက်ရန်၊ သင်အသုံးပြုနိုင်သည် ဤရှည်လျားသော ဖော်မြူလာ သို့မဟုတ် အောက်တွင်ဖော်ပြထားသော အလွန်ရိုးရှင်းသော regexe များထဲမှ တစ်ခုဖြစ်သည်။
ဂဏန်းမဟုတ်သော မည်သည့်စာလုံးကိုမဆို တွဲကြည့်ပါ-
Pattern : \D+
negated classes ကိုသုံး၍ ဂဏန်းမဟုတ်သော အက္ခရာများကို ဖယ်ထုတ်ပါ-
Pattern : [^0-9]+
Pattern : [^\d] +
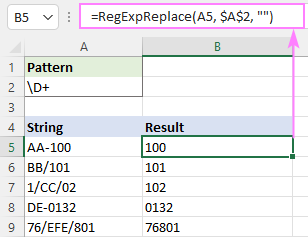
အကြံပြုချက်။ သင့်ရည်မှန်းချက်မှာ စာသားများကို ဖယ်ရှားရန်နှင့် ကျန်နံပါတ်များကို သီးခြားဆဲလ်များထဲသို့ ဖိတ်ချရန် သို့မဟုတ် ၎င်းတို့အားလုံးကို သတ်မှတ်ထားသော ကန့်သတ်ချက်ဖြင့် ခွဲထားသည့် ဆဲလ်တစ်ခုတွင် ထားရှိပါက၊ ပုံမှန်အသုံးအနှုန်းများကို အသုံးပြု၍ စာကြောင်းမှ နံပါတ်များကို ထုတ်ယူနည်းတွင် ရှင်းပြထားသည့်အတိုင်း RegExpExtract လုပ်ဆောင်ချက်ကို အသုံးပြုပါ။
နေရာလွတ်ပြီးနောက် အရာအားလုံးကို ဖယ်ရှားရန် Regex
နေရာလွတ်တစ်ခုပြီးနောက် အရာအားလုံးကို ဖယ်ရှားရန်၊ space ( ) ကိုသုံးပါ သို့မဟုတ်ပထမနေရာကိုရှာရန် whitespace (\s) အက္ခရာနှင့် .* သည် ၎င်းနောက်တွင် မည်သည့်စာလုံးနှင့်မဆို ကိုက်ညီရန်။
သင့်တွင် ပုံမှန်နေရာလွတ်များသာပါဝင်သည့် တစ်ကြောင်းတည်းသောစာကြောင်းများရှိပါက (7-bit ASCII စနစ်တွင် တန်ဖိုး 32) ၊ သင်အသုံးပြုသည့် regexes များထဲမှ မည်သည့်အရာသည် အရေးမကြီးပါ။ မျဉ်းကြောင်းပေါင်းများစွာအတွက်၊ ၎င်းသည် ခြားနားချက်တစ်ခုဖြစ်စေသည်။
အရာအားလုံးကို နေရာလွတ်တစ်ခုပြီးနောက် ၊ ဤ regex ကိုသုံးပါ-
ပုံစံ : " .*"
=RegExpReplace(A5, " .*", "")
ဤဖော်မြူလာသည် စာကြောင်းတစ်ခုစီ ရှိ ပထမနေရာပြီးနောက် မည်သည့်အရာကိုမဆို ဖယ်ရှားပါမည်။ ရလဒ်များကို မှန်ကန်စွာပြသရန်အတွက် Wrap Text ကိုဖွင့်ရန်သေချာပါစေ။
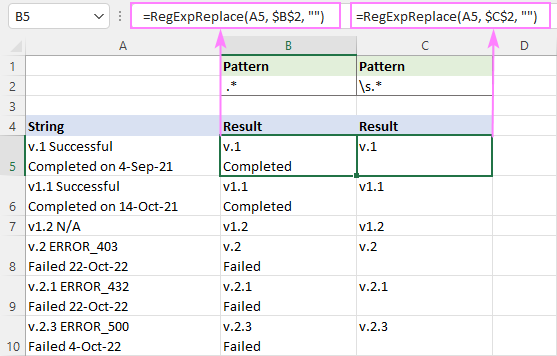
အရာအားလုံးကို နေရာလွတ်တစ်ခုပြီးနောက် (နေရာလွတ်တစ်ခု၊ တက်ဘ်၊ ရထားပြန်ပို့ခြင်းနှင့် စာကြောင်းအသစ်များအပါအဝင်) regex၊ သည်-
Pattern : \s.*
=RegExpReplace(A5, "\s.*", "")
အဘယ်ကြောင့်ဆိုသော် \s သည် စာကြောင်းအသစ်<အပါအဝင် မတူညီသော နေရာလွတ်အမျိုးအစားအချို့နှင့် ကိုက်ညီသောကြောင့်၊ 9> (\n)၊ ဤဖော်မြူလာသည် ဆဲလ်တစ်ခုရှိ ပထမနေရာလွတ်ပြီးနောက် အရာအားလုံးကို ဖျက်လိုက်သည်၊ ၎င်းတွင် စာကြောင်းမည်မျှပင်ရှိပါစေ
အတိအကျပြီးနောက် စာသားကို ဖယ်ရှားရန် Regex ဇာတ်ကောင်
ယခင်နမူနာမှ နည်းလမ်းများကို အသုံးပြု၍ သင်သတ်မှတ်ထားသော စာလုံးတစ်ခုပြီးနောက် စာသားကို ဖျက်နိုင်သည်။
စာကြောင်းတစ်ခုစီကို သီးခြားစီကိုင်တွယ်ရန်-
ယေဘုယျပုံစံ : char.*
စာကြောင်းတစ်ကြောင်းတည်းတွင်၊ ၎င်းသည် char ပြီးနောက် အရာအားလုံးကို ဖယ်ရှားပါမည်။ လိုင်းပေါင်းစုံတွင်၊ VBA Regex အရသာတွင်၊ အသစ်တစ်ခုမှလွဲ၍ မည်သည့်ဇာတ်ကောင်နှင့်မဆို ကိုက်ညီသောကြောင့် လိုင်းတစ်ခုစီတွင် လိုင်းတစ်ခုစီကို စီစဥ်ပေးမည်ဖြစ်သည်။^ စာကြောင်းတစ်ခု၏အစ၊ ကျွန်ုပ်တို့သည် သုည သို့မဟုတ် ထို့ထက်ပိုသော နေရာလွတ်မဟုတ်သော စာလုံးများ [^ ]* နှင့် တူညီသော နေရာလွတ်တစ်ခု သို့မဟုတ် တစ်ခုထက်ပိုသော " +" ဖြင့် လိုက်ပါသည်။ ရလဒ်များတွင် ဖြစ်ပေါ်လာနိုင်သော ဦးဆောင်နေရာလွတ်များကို တားဆီးရန် နောက်ဆုံးအပိုင်းကို ပေါင်းထည့်ထားပါသည်။
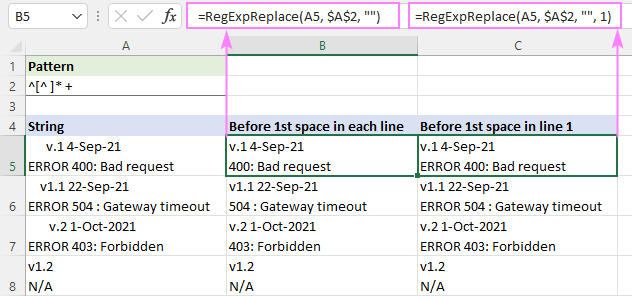
စာကြောင်းတစ်ကြောင်းစီရှိ ပထမနေရာမစမီ စာသားကို ဖယ်ရှားရန်၊ ဖော်မြူလာကို မူရင်း "ကိုက်ညီမှုအားလုံး" မုဒ်တွင် ရေးထားသည် ( instance_num ချန်လှပ်ထားပါသည်):
=RegExpReplace(A5, "^[^ ]* +", "")
ပထမစာကြောင်းရှိ ပထမစာကြောင်းရှေ့တွင် စာသားကိုဖျက်ရန်နှင့် အခြားစာကြောင်းအားလုံးကို နဂိုအတိုင်းထားရန်၊ instance_num အငြင်းအခုံကို 1:
=RegExpReplace(A5, "^[^ ]* +", "", 1)
Regex စာလုံးရှေ့မှအရာအားလုံးကိုဖယ်ရှားရန် Regex
တိကျသောစာလုံးတစ်ခုရှေ့တွင် စာသားအားလုံးကိုဖယ်ရှားရန် အလွယ်ကူဆုံးနည်းလမ်းမှာ regex ကိုအသုံးပြုခြင်းဖြစ်သည် ဤကဲ့သို့သော-
ယေဘုယျပုံစံ : ^[^char]*char
လူသားဘာသာစကားသို့ ဘာသာပြန်ဆိုထားသည်- "^ ဖြင့် ကျောက်ချထားသော ကြိုးတစ်ချောင်း၏အစမှ char [^char]* မှလွဲ၍ 0 သို့မဟုတ် ထို့ထက်ပိုသော အက္ခရာများကို char ၏ ပထမအကြိမ်အထိ ယှဉ်ပါ။
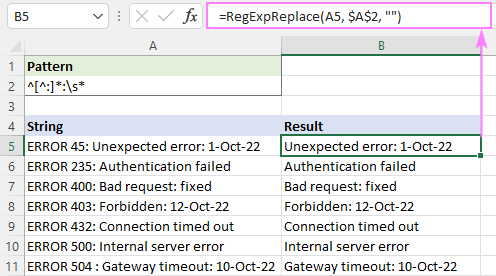
ဥပမာ၊ ပထမကော်လံရှေ့တွင် စာသားအားလုံးကို ဖျက်ရန်၊ ၊ ဤပုံမှန်အသုံးအနှုန်းကိုသုံးပါ-
Pattern : ^[^:]*:
ရလဒ်များတွင် ဦးဆောင်နေရာလွတ်များကို ရှောင်ရှားရန်၊ whitespace စာလုံး \s* ကို ထည့်ပါ။ အဆုံးသတ်၍ ဤအရာအားလုံးကို ဖယ်ရှားပါမည်။ g ပထမ အူမကြီးရှေ့တွင်၊ ၎င်းနောက်တွင် နေရာလွတ်များကို ချုံ့ပါ-
Pattern : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
အကြံပြုချက်။ ပုံမှန်အသုံးအနှုန်းများအပြင်၊ Excel တွင် ရာထူး သို့မဟုတ် ကိုက်ညီမှုဖြင့် စာသားကို ဖယ်ရှားရန် ၎င်း၏ကိုယ်ပိုင်နည်းလမ်းရှိသည်။ ဇာတိဖော်မြူလာများဖြင့် အလုပ်ပြီးမြောက်ပုံကို လေ့လာရန်၊Excel တွင် စာလုံးတစ်လုံးရှေ့ သို့မဟုတ် နောက်တွင် စာသားကို ဖယ်ရှားနည်းကို ကျေးဇူးပြု၍ ကြည့်ပါ။
Regex မှလွဲ၍ ကျန်အရာအားလုံးကို ဖယ်ရှားရန်
သင်သိမ်းဆည်းလိုသည့် စာကြောင်းမှလွဲ၍ စာလုံးအားလုံးကို ဖယ်ရှားရန်၊ နှုတ်ဖျက်ထားသော စာလုံးအတန်းများကို သုံးပါ။
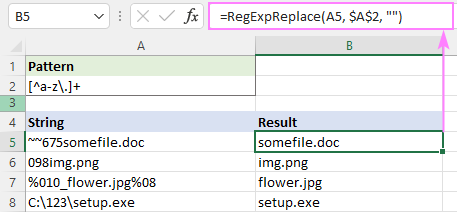
ဥပမာ၊ စာလုံးအသေးမှလွဲ၍ စာလုံးအားလုံးကို ဖယ်ရှားရန်၊ နှင့် အစက်များ၊ regex သည်-
Pattern - [^a-z\.]+
တကယ်တော့၊ ကျွန်ုပ်တို့၏လုပ်ဆောင်ချက်အားလုံးကို အစားထိုးလိုက်သောကြောင့် ဤနေရာတွင် + quantifier မပါဘဲ လုပ်ဆောင်နိုင်ပါသည် တိုက်ဆိုင်မှုတွေ တွေ့တယ်။ quantifier သည် အနည်းငယ်ပိုမြန်စေသည် - စာလုံးတစ်လုံးချင်းစီကို ကိုင်တွယ်မည့်အစား၊ သင်သည် substring တစ်ခုကိုအစားထိုးသည်။
=RegExpReplace(A5, "[^a-z\.]+", "")
Excel တွင် html tag များကိုဖယ်ရှားရန် Regex
ဦးစွာ၊ HTML သည် ပုံမှန်ဘာသာစကားမဟုတ်ကြောင်း သတိပြုသင့်သည်၊ ထို့ကြောင့် ပုံမှန်အသုံးအနှုန်းများကို အသုံးပြု၍ ခွဲခြမ်းစိတ်ဖြာခြင်းသည် အကောင်းဆုံးနည်းလမ်းမဟုတ်ပါ။ ဆိုလိုသည်မှာ၊ regexes သည် သင့်ဒေတာအတွဲများကို ပိုမိုသန့်ရှင်းစေရန်အတွက် သင့်ဆဲလ်များမှ တဂ်များကို ဖယ်ရှားရန် ကူညီပေးနိုင်ပါသည်။
html တဂ်များကို ထောင့်ကွင်းကွက်များအတွင်း အမြဲထည့်သွင်းထားသောကြောင့် ၎င်းတို့ကို အောက်ပါ regexes များထဲမှ တစ်ခုကို အသုံးပြု၍ ရှာဖွေနိုင်ပါသည်။
Negated class-
Pattern : ]*>
ဤတွင်၊ ကျွန်ုပ်တို့သည် အဖွင့်ထောင့်ကွင်းပိတ်တစ်ခုနှင့် ကိုက်ညီပြီး ၎င်းမှလွဲ၍ မည်သည့်ဇာတ်ကောင်၏ သုည သို့မဟုတ် ထို့ထက်ပိုသော ဖြစ်ပေါ်မှုများနောက်တွင်၊ အပိတ်ထောင့်ကွင်းပိတ် [^>]* အနီးဆုံးအပိတ်ထောင့်ကွင်းဆက်အထိ။
ပျင်းရိရှာဖွေမှု-
ပုံစံ -
ဤတွင်၊ ကျွန်ုပ်တို့နှင့် ကိုက်ညီသည် ပထမအဖွင့်ကွင်းမှ ပထမအပိတ်ကွင်းအထိ မည်သည့်အရာမဆို။ မေးခွန်းအမှတ်အသားသည် .* ကဲ့သို့ စာလုံးအနည်းငယ်နှင့် ကိုက်ညီရန် တွန်းအားပေးသည်။စာကြောင်း။
လိုင်းအားလုံးကို စာကြောင်းတစ်ခုတည်းအဖြစ် လုပ်ဆောင်ရန်-
ယေဘုယျပုံစံ : char(။
