
فہرست کا خانہ
نیچے دیے گئے تاروں میں، فرض کریں کہ آپ پہلے آرڈر نمبر کو حذف کرنا چاہتے ہیں۔ ایسے تمام نمبر ہیش سائن (#) سے شروع ہوتے ہیں اور بالکل 5 ہندسوں پر مشتمل ہوتے ہیں۔ لہذا، ہم اس regex کا استعمال کرتے ہوئے ان کی شناخت کر سکتے ہیں:
پیٹرن : #\d{5}\b
لفظ باؤنڈری \b یہ بتاتا ہے کہ ایک مماثل ذیلی اسٹرنگ نہیں ہوسکتی ہے۔ ایک بڑی سٹرنگ کا حصہ جیسے #10000001۔
تمام میچوں کو ہٹانے کے لیے، instance_num دلیل کی وضاحت نہیں کی گئی ہے:
=RegExpReplace(A5, "#\d{5}\b", "")
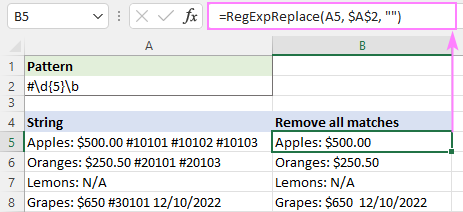
صرف پہلی موجودگی کو ختم کرنے کے لیے، ہم نے instance_num دلیل کو 1 پر سیٹ کیا:
=RegExpReplace(A5, "#\d{5}\b", "", 1)
Regex مخصوص حروف کو ہٹانے کے لیے
کچھ حروف کو تار سے ہٹانے کے لیے، بس تمام ناپسندیدہ حروف کو لکھیں اور انہیں عمودی بار سے الگ کریںVBA RegExp کی حدود سے پاک نحو، اور دوسرا، اپنی ورک بک میں کسی بھی VBA کوڈ کو داخل کرنے کی ضرورت نہیں ہے کیونکہ تمام کوڈ انٹیگریشن ہم بیک اینڈ پر کرتے ہیں۔
آپ کے کام کا حصہ ایک ریگولر ایکسپریشن بنانا ہے اور اسے فنکشن میں پیش کریں :) آئیے میں آپ کو عملی مثال کے طور پر دکھاتا ہوں۔
ریجیکس کا استعمال کرتے ہوئے بریکٹ اور قوسین میں متن کو کیسے ہٹایا جائے
لمبی ٹیکسٹ اسٹرنگ میں، کم اہم معلومات اکثر [بریکٹ] اور (قوسین) میں بند ہوتا ہے۔ دیگر تمام ڈیٹا کو مدنظر رکھتے ہوئے آپ ان غیر متعلقہ تفصیلات کو کیسے ہٹاتے ہیں؟
درحقیقت، ہم نے پہلے ہی HTML ٹیگز کو حذف کرنے کے لیے ایک ایسا ہی ریجیکس بنایا ہے، یعنی زاویہ بریکٹ کے اندر متن۔ ظاہر ہے، یہی طریقے مربع اور گول بریکٹ کے لیے بھی کام کریں گے۔
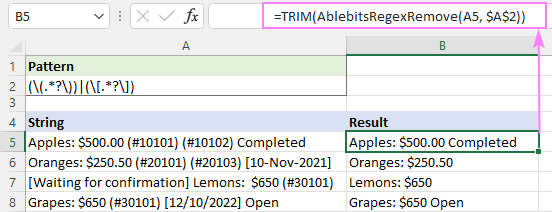
پیٹرن : (\(.*?\))
1 ہم نے نہ صرف سوچا ہے بلکہ اس پر کام کیا ہے :) اور اب، آپ اس شاندار RegEx فنکشن کو اپنی ورک بک میں شامل کر سکتے ہیں اور بغیر کسی وقت کے پیٹرن سے مماثل ذیلی سٹرنگز کو مٹا سکتے ہیں!
گزشتہ ہفتے، ہم نے دیکھا ایکسل میں سٹرنگز کو تبدیل کرنے کے لیے ریگولر ایکسپریشنز کا استعمال کیسے کریں۔ اس کے لیے، ہم نے اپنی مرضی کے مطابق ریجیکس ریپلیس فنکشن بنایا ہے۔ جیسا کہ یہ نکلا، فنکشن اپنے بنیادی استعمال سے باہر ہے اور نہ صرف تاروں کو تبدیل کر سکتا ہے بلکہ انہیں ہٹا بھی سکتا ہے۔ یہ کیسے ہو سکتا ہے؟ ایکسل کے لحاظ سے، کسی قدر کو ہٹانا اور کچھ نہیں بلکہ اسے خالی سٹرنگ سے تبدیل کرنا ہے، جس میں ہمارا Regex فنکشن بہت اچھا ہے!
VBA RegExp فنکشن ایکسل میں سب اسٹرنگز کو ہٹانے کے لیے
جیسا کہ ہم سب جانتے ہیں، ایکسل میں بطور ڈیفالٹ ریگولر ایکسپریشنز تعاون یافتہ نہیں ہیں۔ ان کو فعال کرنے کے لیے، آپ کو اپنا صارف کی وضاحت کردہ فنکشن بنانے کی ضرورت ہے۔ اچھی خبر یہ ہے کہ اس طرح کا فنکشن پہلے ہی لکھا، تجربہ کیا اور استعمال کے لیے تیار ہے۔ آپ کو بس اس کوڈ کو کاپی کرنا ہے، اسے اپنے VBA ایڈیٹر میں چسپاں کرنا ہے، اور پھر اپنی فائل کو میکرو-انبلڈ ورک بک (.xlsm) کے طور پر محفوظ کرنا ہے۔
فنکشن میں مندرجہ ذیل نحو:
RegExpReplace(text, pattern, replacement, [instance_num], [match_case])پہلے تین دلائل درکار ہیں، آخری دو اختیاری ہیں۔
کہاں:
- ٹیکسٹ - تلاش کرنے کے لیے ٹیکسٹ سٹرنگاس وقت تک ممکن ہے جب تک کہ اسے ایک اختتامی بریکٹ نہ ملے۔
آپ جو بھی پیٹرن منتخب کریں گے، نتیجہ بالکل ایک جیسا ہوگا۔
مثال کے طور پر، A5 میں کسی سٹرنگ سے تمام html ٹیگز کو ہٹانا اور متن چھوڑنا، فارمولا ہے:
=RegExpReplace(A5, "]*>", "")
یا آپ سست کوانٹیفائر استعمال کرسکتے ہیں جیسا کہ اسکرین شاٹ میں دکھایا گیا ہے:
29>
یہ حل اس کے لیے بالکل کام کرتا ہے ایک متن (قطاریں 5 - 9)۔ متعدد متن کے لیے (قطاریں 10 - 12)، نتائج قابل اعتراض ہیں - مختلف ٹیگز کے متن کو ایک میں ضم کر دیا گیا ہے۔ کیا یہ صحیح ہے یا نہیں؟ میں ڈرتا ہوں، یہ کوئی ایسی چیز نہیں ہے جس کا فیصلہ آسانی سے کیا جا سکے - یہ سب آپ کے مطلوبہ نتائج کی سمجھ پر منحصر ہے۔ مثال کے طور پر، B11 میں، نتیجہ "A1" متوقع ہے۔ جبکہ B10 میں، آپ چاہتے ہیں کہ "data1" اور "data2" کو اسپیس کے ساتھ الگ کیا جائے۔
HTML ٹیگز کو ہٹانے اور باقی متن کو خالی جگہوں کے ساتھ الگ کرنے کے لیے، آپ اس طرح آگے بڑھ سکتے ہیں:
- ٹیگز کو خالی جگہوں سے بدلیں " "، خالی تاروں سے نہیں:
=RegExpReplace(A5, "]*>", " ") - متعدد اسپیسز کو ایک ہی اسپیس کریکٹر میں کم کریں:
=RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " ") - پچھلی اور پچھلی جگہوں کو تراشیں:
=TRIM(RegExpReplace(RegExpReplace(A5, "]*>", " "), " +", " "))
نتیجہ کچھ اس طرح نظر آئے گا:
32>
Ablebits Regex Remove Tool
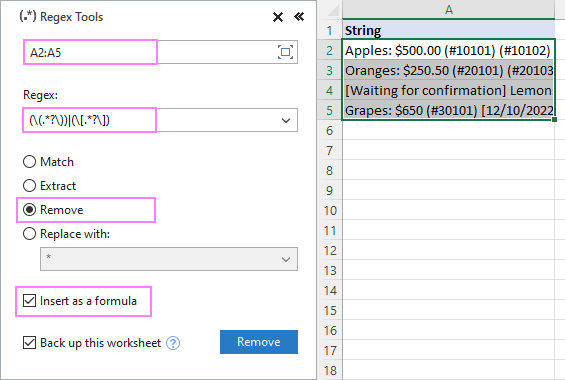
0 ان .NET پر مبنی Regex فنکشنز کی خوبصورتی یہ ہے کہ یہ سب سے پہلے مکمل خصوصیات والے ریگولر اظہار کی حمایت کرتے ہیں۔ ہٹائیںاختیار، اور دبائیں ہٹائیں۔نتائج کو فارمولوں کے طور پر حاصل کرنے کے لیے، اقدار کے نہیں، ایک فارمولے کے طور پر داخل کریں چیک باکس کو منتخب کریں۔
A2:A5 میں سٹرنگز سے بریکٹ کے اندر موجود متن کو ہٹانے کے لیے، ہم ترتیبات کو ترتیب دیتے ہیں۔ حسب ذیل:
نتیجتاً، AblebitsRegexRemove فنکشن آپ کے اصل ڈیٹا کے آگے ایک نئے کالم میں داخل کیا جاتا ہے۔
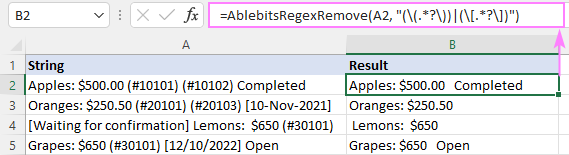
فنکشن کو معیاری فنکشن داخل کریں ڈائیلاگ باکس کے ذریعے براہ راست سیل میں بھی داخل کیا جاسکتا ہے، جہاں اسے AblebitsUDFs کے تحت درجہ بندی کیا گیا ہے۔<3
جیسا کہ AblebitsRegexRemove کو متن کو ہٹانے کے لیے ڈیزائن کیا گیا ہے، اس کے لیے صرف دو دلائل کی ضرورت ہے - سورس سٹرنگ اور ریجیکس۔ دونوں پیرامیٹرز کو براہ راست فارمولے میں بیان کیا جاسکتا ہے یا سیل حوالوں کی شکل میں فراہم کیا جاسکتا ہے۔ اگر ضرورت ہو تو، اس حسب ضرورت فنکشن کو کسی بھی مقامی کے ساتھ استعمال کیا جا سکتا ہے۔
مثال کے طور پر، نتیجے میں آنے والے تاروں میں اضافی خالی جگہوں کو تراشنے کے لیے، آپ TRIM فنکشن کو ریپر کے طور پر استعمال کر سکتے ہیں:
=TRIM(AblebitsRegexRemove(A5, $A$2))
ریگولر ایکسپریشنز کا استعمال کرتے ہوئے ایکسل میں سٹرنگز کو ہٹانے کا طریقہ یہ ہے۔ میں پڑھنے کے لیے آپ کا شکریہ ادا کرتا ہوں اور اگلے ہفتے آپ کو ہمارے بلاگ پر دیکھنے کا منتظر ہوں!
دستیاب ڈاؤن لوڈز
ریجیکس کا استعمال کرتے ہوئے تاروں کو ہٹا دیں - مثالیں (.xlsm فائل)
Ultimate Suite - آزمائشی ورژن (.exe فائل)
میں۔مزید معلومات کے لیے، براہ کرم RegExpReplace فنکشن دیکھیں۔
ٹپ۔ سادہ معاملات میں، آپ Excel فارمولوں کے ساتھ سیلز سے مخصوص حروف یا الفاظ کو ہٹا سکتے ہیں۔ لیکن ریگولر ایکسپریشنز اس کے لیے بہت زیادہ آپشن فراہم کرتے ہیں۔
ریگولر ایکسپریشنز کا استعمال کرتے ہوئے تاروں کو کیسے ہٹایا جائے - مثالیں
جیسا کہ اوپر بتایا گیا ہے، کسی پیٹرن سے مماثل متن کے حصوں کو ہٹانے کے لیے، آپ کو انہیں تبدیل کرنا ہوگا۔ ایک خالی تار کے ساتھ۔ لہذا، ایک عام فارمولا یہ شکل اختیار کرتا ہے:
RegExpReplace(text, pattern, "", [instance_num], [match_case])ذیل کی مثالیں اس بنیادی تصور کے مختلف نفاذ کو ظاہر کرتی ہیں۔
ہٹائیں تمام مماثلتیں یا مخصوص مماثلت
RegExpReplace فنکشن کو دیے گئے regex سے مماثل تمام ذیلی اسٹرنگز تلاش کرنے کے لیے ڈیزائن کیا گیا ہے۔ کون سے واقعات کو ہٹانا ہے 4th اختیاری دلیل کے ذریعے کنٹرول کیا جاتا ہے، جس کا نام instance_num ہے۔
پہلے سے طے شدہ "تمام مماثلتیں" ہے - جب instance_num کنکٹنیشن آپریٹر (&) اور ٹیکسٹ فنکشنز جیسے RIGHT, MID اور LEFT۔
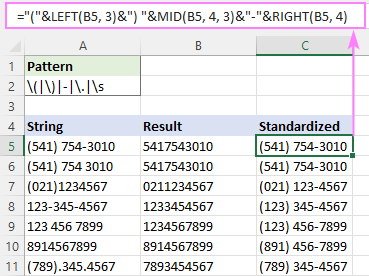
مثال کے طور پر، تمام فون نمبرز کو (123) 456-7890 فارمیٹ میں لکھنے کے لیے، فارمولا یہ ہے:
="("&LEFT(B5, 3)&") "&MID(B5, 4, 3)&"-"&RIGHT(B5, 4)
جہاں B5 RegExpReplace فنکشن کا آؤٹ پٹ ہے۔
ریجیکس کا استعمال کرتے ہوئے خصوصی حروف کو ہٹائیں
ہمارے ایک ٹیوٹوریل میں، ہم نے دیکھا کہ ان بلٹ اور کسٹم فنکشنز کا استعمال کرتے ہوئے ایکسل میں ناپسندیدہ حروف کو کیسے ہٹایا جائے۔ باقاعدہ اظہار چیزوں کو بہت آسان بنا دیتا ہے! حذف کرنے کے لیے تمام حروف کو درج کرنے کے بجائے، صرف ان کی وضاحت کریں جنہیں آپ رکھنا چاہتے ہیں :)
پیٹرن منفی کریکٹر کلاسز پر مبنی ہے - ایک کیرٹ کریکٹر کلاس کے اندر رکھا جاتا ہے [^ ] بریکٹ میں نہیں کسی ایک حرف سے مماثل ہونا۔ + کوانٹیفائر اسے لگاتار حروف کو ایک مماثلت کے طور پر شمار کرنے پر مجبور کرتا ہے، تاکہ ہر ایک کریکٹر کے بجائے ایک مماثل ذیلی اسٹرنگ کے لیے متبادل کیا جائے۔
اپنی ضروریات پر منحصر ہے، درج ذیل ریجیکس میں سے ایک کا انتخاب کریں۔
غیر حرفی حروف کو ہٹانے کے لیے، یعنی حروف اور ہندسوں کے علاوہ تمام حروف:
پیٹرن : [^0-9a-zA-Z] +
تمام حروف کو صاف کرنے کے لیے حروف کے علاوہ ، ہندسوں اور اسپیسز :
پیٹرن : [^0-9a-zA-Z ]+
تمام حروف کو حذف کرنے کے لیے ماسوائے حروف ، ہندسوں اور انڈر سکور ، آپ استعمال کر سکتے ہیں \ W جس کا مطلب کسی ایسے کردار کا ہے جو حروفِ عددی حرف نہیں ہے یاانڈر سکور:
پیٹرن : \W+
اگر آپ کچھ دوسرے حروف کو رکھنا چاہتے ہیں ، جیسے اوقاف کے نشانات، انہیں بریکٹ کے اندر رکھیں۔
مثال کے طور پر، کسی حرف، ہندسے، پیریڈ، کوما، یا اسپیس کے علاوہ کسی بھی حرف کو ہٹانے کے لیے، درج ذیل ریجیکس کا استعمال کریں:
پیٹرن : [^0-9a-zA-Z\., ]+
یہ کامیابی کے ساتھ تمام خاص حروف کو ختم کر دیتا ہے، لیکن اضافی خالی جگہ باقی رہتی ہے۔
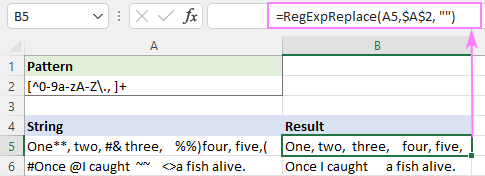
اسے ٹھیک کرنے کے لیے، آپ مندرجہ بالا فنکشن کو ایک دوسرے میں گھونسلا کر سکتے ہیں جو متعدد خالی جگہوں کو ایک ہی اسپیس کریکٹر سے بدل دیتا ہے۔
=RegExpReplace(RegExpReplace(A5,$A$2,""), " +", " ")
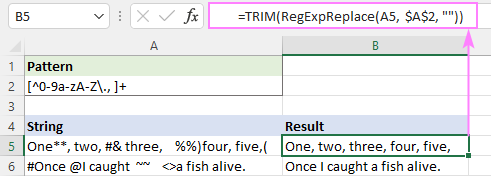
یا صرف اسی اثر کے ساتھ مقامی TRIM فنکشن کا استعمال کریں۔ :
=TRIM(RegExpReplace(A5, $A$2, ""))
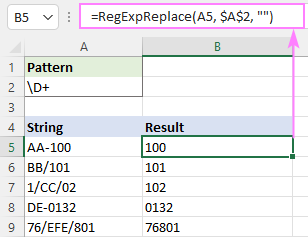
غیر عددی حروف کو ہٹانے کے لیے Regex
اسٹرنگ سے تمام غیر عددی حروف کو حذف کرنے کے لیے، آپ استعمال کر سکتے ہیں۔ یا تو یہ لمبا فارمولہ یا نیچے دیے گئے بہت ہی آسان ریجیکسز میں سے ایک۔
کسی بھی ایسے حروف سے ملائیں جو ہندسہ نہ ہو:
پیٹرن : \D+
منفی کلاسز کا استعمال کرتے ہوئے غیر عددی حروف کی پٹی:
پیٹرن : [^0-9]+
پیٹرن : [^\d] +
ٹپ۔ اگر آپ کا مقصد متن کو ہٹانا اور بقیہ نمبروں کو الگ سیل میں پھیلانا ہے یا ان سب کو ایک مخصوص ڈیلیمیٹر کے ساتھ الگ کرکے ایک سیل میں رکھنا ہے، تو RegExpExtract فنکشن کا استعمال کریں جیسا کہ ریگولر ایکسپریشنز کا استعمال کرتے ہوئے سٹرنگ سے نمبرز کو کیسے نکالا جائے میں بتایا گیا ہے۔
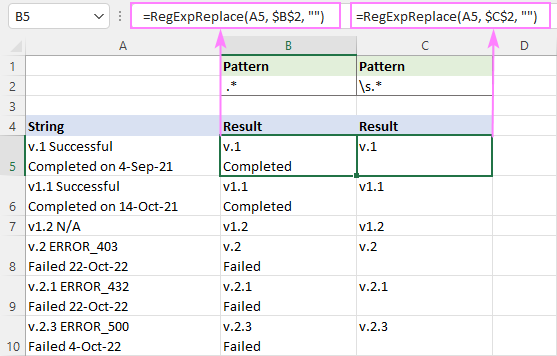
اسپیس کے بعد ہر چیز کو ہٹانے کے لیے ریجیکس
اسپیس کے بعد ہر چیز کو مٹانے کے لیے، یا تو اسپیس ( ) یاپہلی جگہ تلاش کرنے کے لیے وائٹ اسپیس (\s) کریکٹر اور .* اس کے بعد کے کسی بھی حروف سے ملنے کے لیے۔
اگر آپ کے پاس سنگل لائن سٹرنگز ہیں جن میں صرف عام اسپیس ہیں (7 بٹ ASCII سسٹم میں قدر 32) ، اس سے کوئی فرق نہیں پڑتا ہے کہ آپ ذیل میں سے کون سی ریجیکس استعمال کرتے ہیں۔ ملٹی لائن سٹرنگز کی صورت میں، اس سے فرق پڑتا ہے۔
ہر چیز کو ہٹانے کے لیے اسپیس کریکٹر کے بعد، یہ ریجیکس استعمال کریں:
پیٹرن : " .*"
=RegExpReplace(A5, " .*", "")
یہ فارمولہ ہر سطر میں پہلی جگہ کے بعد کچھ بھی چھین لے گا۔ نتائج کو درست طریقے سے ظاہر کرنے کے لیے، ریپ ٹیکسٹ کو آن کرنا یقینی بنائیں۔
سب کچھ ختم کرنے کے لیے سفید جگہ کے بعد (بشمول اسپیس، ٹیب، کیریج ریٹرن اور نئی لائن)، ریجیکس یہ ہے:
پیٹرن : \s.*
=RegExpReplace(A5, "\s.*", "")
کیونکہ \s کچھ مختلف وائٹ اسپیس اقسام سے مماثل ہے بشمول ایک نئی لائن (\n)، یہ فارمولا سیل میں پہلی جگہ کے بعد ہر چیز کو حذف کر دیتا ہے، چاہے اس میں کتنی ہی لائنیں ہوں۔
مخصوص کے بعد متن کو ہٹانے کے لیے ریجیکس کریکٹر
پچھلی مثال کے طریقوں کا استعمال کرتے ہوئے، آپ کسی بھی کریکٹر کے بعد متن کو مٹا سکتے ہیں جسے آپ بیان کرتے ہیں۔
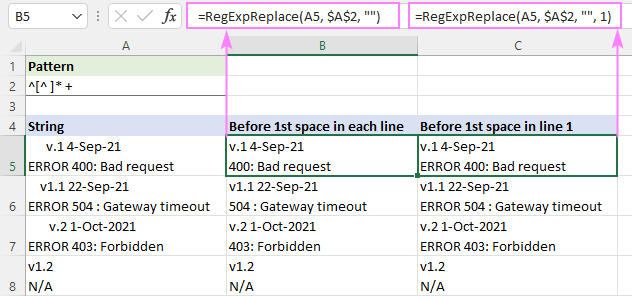
ہر لائن کو الگ سے ہینڈل کرنے کے لیے:
عام پیٹرن : char.*
سنگل لائن سٹرنگز میں، یہ char کے بعد ہر چیز کو ہٹا دے گا۔ ملٹی لائن سٹرنگز میں، ہر لائن پر انفرادی طور پر کارروائی کی جائے گی کیونکہ VBA Regex فلیور میں، ایک پیریڈ (.) کسی بھی کردار سے میل کھاتا ہے سوائے ایک نئےسٹرنگ کی شروعات ^، ہم صفر یا زیادہ غیر اسپیس حروف سے ملتے ہیں [^ ]* جس کے فوراً بعد ایک یا زیادہ خالی جگہیں "+" آتی ہیں۔ نتائج میں ممکنہ معروف خالی جگہوں کو روکنے کے لیے آخری حصہ شامل کیا گیا ہے۔
ہر لائن میں پہلی جگہ سے پہلے متن کو ہٹانے کے لیے، فارمولہ کو پہلے سے طے شدہ "تمام میچز" موڈ میں لکھا جاتا ہے ( instance_num چھوڑ دیا گیا):
=RegExpReplace(A5, "^[^ ]* +", "")
پہلی لائن میں پہلی اسپیس سے پہلے متن کو حذف کرنے کے لیے، اور باقی تمام لائنوں کو برقرار رکھنے کے لیے، instance_num دلیل 1:<پر سیٹ کی گئی ہے۔ 3>
=RegExpReplace(A5, "^[^ ]* +", "", 1)
ریجیکس کریکٹر سے پہلے ہر چیز کو ہٹانے کے لیے
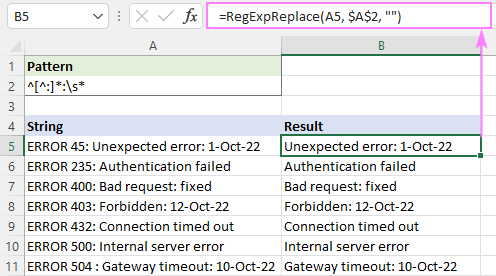
کسی مخصوص کریکٹر سے پہلے تمام ٹیکسٹ کو ہٹانے کا سب سے آسان طریقہ ریجیکس کا استعمال کرنا ہے۔ اس طرح:
عام پیٹرن : ^[^char]*char
انسانی زبان میں ترجمہ کیا گیا، یہ کہتا ہے: "^ کے ذریعے لنگر انداز ہونے والی تار کے آغاز سے 0 یا اس سے زیادہ حروف کو مماثل کریں سوائے char [^char]* کو char کی پہلی موجودگی تک۔
مثال کے طور پر، پہلی بڑی آنت سے پہلے تمام متن کو حذف کرنے کے لیے اس ریگولر ایکسپریشن کا استعمال کریں:
پیٹرن : ^[^:]*:
نتائج میں لیڈنگ اسپیس سے بچنے کے لیے، اس میں وائٹ اسپیس کریکٹر \s* شامل کریں۔ یہ سب کچھ ختم کر دے گا۔ g پہلے بڑی آنت سے پہلے اور اس کے بعد کسی بھی جگہ کو تراشیں:
پیٹرن : ^[^:]*:\s*
=RegExpReplace(A5, "^[^:]*:\s*", "")
ٹپ۔ ریگولر ایکسپریشنز کے علاوہ، Excel کے پاس پوزیشن یا میچ کے لحاظ سے متن کو ہٹانے کے اپنے ذرائع ہیں۔ مقامی فارمولوں کے ساتھ کام کو پورا کرنے کا طریقہ سیکھنے کے لیے،براہ کرم دیکھیں کہ ایکسل میں کسی کردار سے پہلے یا بعد میں متن کو کیسے ہٹایا جائے۔
ریجیکس ہر چیز کو ہٹانے کے لیے سوائے
اسٹرنگ سے تمام حروف کو مٹانے کے لیے جسے آپ رکھنا چاہتے ہیں، منفی کریکٹر کلاسز کا استعمال کریں۔
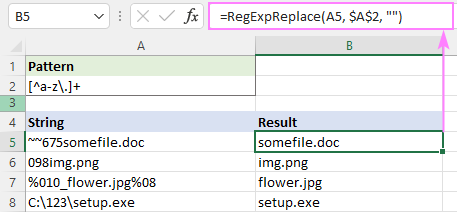
مثال کے طور پر، چھوٹے حروف کے علاوہ تمام حروف کو ہٹانے کے لیے اور نقطوں پر، ریجیکس ہے:
پیٹرن : [^a-z\.]+
درحقیقت، ہم یہاں + کوانٹیفائر کے بغیر کر سکتے ہیں کیونکہ ہمارا فنکشن سب کی جگہ لے لیتا ہے میچز ملے۔ کوانٹیفائر اسے تھوڑا تیز بناتا ہے - ہر ایک کریکٹر کو سنبھالنے کے بجائے، آپ سب اسٹرنگ کو تبدیل کرتے ہیں۔
=RegExpReplace(A5, "[^a-z\.]+", "")
ایکسل میں HTML ٹیگز کو ہٹانے کے لیے ریجیکس
سب سے پہلے، یہ یاد رکھنا چاہیے کہ ایچ ٹی ایم ایل ایک باقاعدہ زبان نہیں ہے، لہذا ریگولر ایکسپریشنز کا استعمال کرتے ہوئے اسے پارس کرنا بہترین طریقہ نہیں ہے۔ اس نے کہا، ریجیکسز یقینی طور پر آپ کے ڈیٹاسیٹ کو صاف ستھرا بنانے کے لیے آپ کے سیلز سے ٹیگز نکالنے میں مدد کر سکتے ہیں۔
یہ دیکھتے ہوئے کہ html ٹیگز ہمیشہ اینگل بریکٹ میں رکھے جاتے ہیں، آپ انہیں درج ذیل ریجیکس میں سے کسی ایک کا استعمال کرتے ہوئے تلاش کر سکتے ہیں۔
0 اختتامی زاویہ بریکٹ [^>]* قریب ترین اختتامی زاویہ بریکٹ تک۔سست تلاش:
پیٹرن :
یہاں، ہم میچ کرتے ہیں پہلے اوپننگ بریکٹ سے پہلے بند ہونے والے بریکٹ تک کچھ بھی۔ سوالیہ نشان .* کو اتنے ہی کم حروف سے ملنے پر مجبور کرتا ہے۔لائن۔
تمام لائنوں کو ایک سٹرنگ کے طور پر پروسیس کرنے کے لیے:
جنرک پیٹرن : char(.
