
Obsah
Sloučení duplicitních řádků ve vašich tabulkách se může proměnit v jeden z nejsložitějších úkolů. Podívejme se, s čím vám mohou pomoci vzorce Google, a seznamte se s jedním chytrým doplňkem, který vše udělá za vás.
Funkce pro kombinování buněk se stejnou hodnotou v Tabulkách Google
Snad jste si nemysleli, že by v tabulkách Google Sheets chyběly funkce pro tento druh úloh? ;) Zde jsou vzorce, které budete potřebovat ke konsolidaci řádků a odstranění duplicitních buněk v tabulkách.
CONCATENATE - funkce a operátor pro spojování záznamů v Tabulkách Google
První věc, která mě napadne, když přemýšlím nejen o odstranění duplicit, ale i o spojení duplicitních řádků, je funkce CONCATENATE a ampersand (&) - speciální operátor spojování.
Předpokládejme, že máte seznam filmů ke zhlédnutí a chcete je seskupit podle žánrů:
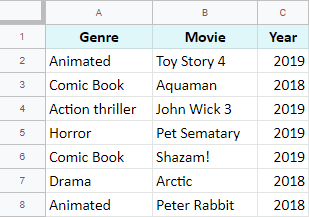
- Buňky v Tabulkách Google lze slučovat pouze s mezerami mezi hodnotami:
=CONCATENATE(B2," ",C2," ",B8," ",C8)=B2&" "&C2&" "&B8&" "&C8".
- Nebo použijte mezery s jakýmikoli jinými značkami ke spojení duplicitních řádků dohromady:
=CONCATENATE(A3,": ",B3," (",C3,"), ",B6," (",C6,") ")=A3&": "&B3&" ("&C3&"), "&B6&" ("&C6&") "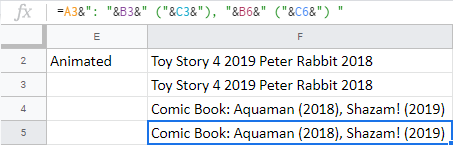
Po sloučení řádků se můžete zbavit vzorců a ponechat pouze text podle příkladu v tomto návodu: Převod vzorců na hodnoty v tabulkách Google.
Jakkoli se tento způsob může zdát jednoduchý, není samozřejmě zdaleka ideální. Vyžaduje, abyste znali přesné pozice duplicit, a jste to vy, kdo by na ně měl vzorec upozornit. Tento způsob tedy může fungovat pro malé soubory dat, ale co dělat, když se zvětší?
Sloučení buněk, ale zachování dat pomocí UNIQUE + JOIN
Tento tandem vzorců za vás vyhledá duplicity v tabulkách Google (a sloučí buňky s jedinečnými záznamy). Stále jste však ve vedení vy a musíte vzorcům ukázat, kde mají hledat. Podívejme se, jak to funguje na stejném seznamu k nahlédnutí.
- Pro kontrolu žánrů ve sloupci A používám v tabulce E2 v aplikaci Google Sheets funkci UNIQUE:
=UNIQUE(A2:A)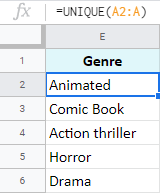
Vzorec vrátí seznam všech žánrů bez ohledu na to, zda se v původním seznamu opakují nebo neopakují. Jinými slovy, odstraní duplicity ze sloupce A.
Tip: UNIQUE rozlišuje velká a malá písmena, takže se ujistěte, že stejné záznamy mají stejná velikost písmen. Tento návod vám pomůže to rychle hromadně udělat.
Tip: Pokud do sloupce A přidáte další hodnoty, vzorec automaticky rozšíří seznam o jedinečné záznamy.
- Poté sestavím další vzorec pomocí funkce JOIN v tabulkách Google:
=JOIN(", ",FILTER(B:B,A:A=E2))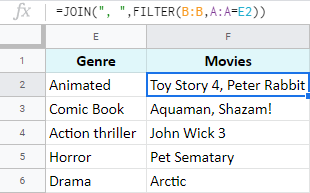
Jak fungují prvky tohoto vzorce?
- FILTER prohledá sloupec A a vyhledá všechny výskyty hodnoty v E2. Jakmile je najde, vytáhne odpovídající záznamy ze sloupce B.
- JOIN tyto hodnoty spojí do jedné buňky s čárkou.
Zkopírujte vzorec dolů a zobrazí se vám všechny tituly seřazené podle žánru.
Poznámka: V případě, že potřebujete i roky, budete muset vzorec vytvořit v sousedním sloupci, protože JOIN pracuje vždy s jedním sloupcem:
=JOIN(", ",FILTER(C:C,A:A=E2))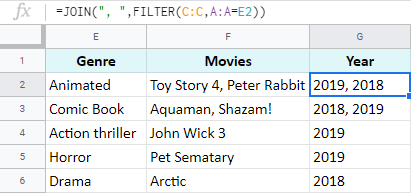
Tato možnost tedy vybavuje Tabulky Google několika funkcemi, které na základě duplicit sloučí více řádků do jednoho. A děje se to automaticky. Tedy, téměř. Dokonalé řešení si hodlám nechat až na samotný konec článku. Ale klidně na něj skočte hned ;)
Funkce QUERY pro odstranění duplicitních řádků v Tabulkách Google
Existuje ještě jedna funkce, která pomáhá pracovat s obrovskými tabulkami - QUERY. Zpočátku se může zdát trochu složitá, ale jakmile se ji naučíte používat, stane se vaším věrným společníkem v tabulkách.
Zde je samotná funkce QUERY:
=QUERY(data, query, [headers])Jak to funguje:
- data (povinné) - rozsah zdrojové tabulky.
- dotaz (povinné) - sada příkazů pro určení podmínek pro získání konkrétních údajů.
Tip. Úplný seznam všech příkazů najdete zde.
- záhlaví (nepovinné) - počet řádků záhlaví ve zdrojové tabulce.
Zjednodušeně řečeno, dotaz v tabulkách Google vrátí některé sady hodnot na základě zadaných podmínek.
Příklad 1
Chci si pořídit pouze komiksové filmy, které jsem ještě neshlédl:
=QUERY(A1:C, "select * where A="Comic Book"")
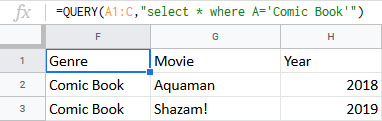
Vzorec zpracuje celou moji zdrojovou tabulku (A1:C) a vrátí všechny sloupce (select *) pro komiksové filmy (kde A="Komiks").
Tip. Záměrně neuvádím poslední řádek tabulky (A1:C) - aby vzorec zůstal flexibilní a v případě přidání dalších řádků do tabulky vracel nové záznamy.
Jak vidíte, funguje podobně jako filtr. V praxi však mohou být vaše data mnohem větší - s čísly, která možná budete muset vypočítat.
Tip: Podívejte se na další způsoby vyhledávání duplicit v tabulce v tabulkách Google Sheets v tomto článku.
Příklad 2
Předpokládejme, že dělám malý průzkum a sleduji víkendové tržby nejnovějších filmů v kinech:
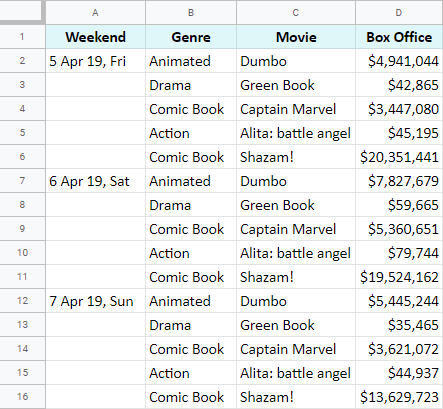
K odstranění duplicit a spočítání celkové částky vydělaných peněz za každý film za všechny víkendy používám QUERY v tabulkách Google. Také je seřazuji podle žánrů:
=QUERY(B1:D, "select B,C, SUM(D) group by B,C")
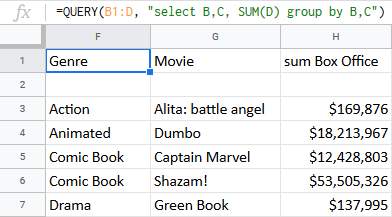
Poznámka: Pro skupina podle je třeba vyjmenovat všechny sloupce po příkazu vybrat , jinak vzorec nebude fungovat.
Pokud chci místo toho řadit záznamy podle filmu, mohu jednoduše změnit pořadí sloupců u položky skupina podle :
=QUERY(B1:D, "select B,C, SUM(D) group by C,B")
Příklad 3
Předpokládejme, že úspěšně provozujete knihkupectví a evidujete všechny knihy, které jsou na skladě ve všech vašich pobočkách. Seznam dosahuje stovek knih:
- Kvůli humbuku kolem série o Harrym Potterovi se rozhodnete zkontrolovat, kolik knih od J. K. Rowlingové vám ještě zbývá:
=QUERY('Kopie Skladem'!A1:D, "select A,B,C,D where A="Rowling"")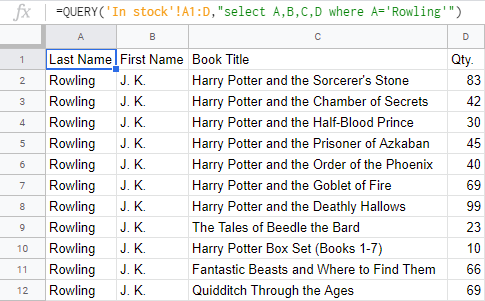
- Rozhodnete se jít ještě dál a ponechat si pouze sérii o Harrym Potterovi a ostatní příběhy vynechat:
=QUERY('Skladem'!A1:D, "select A,B,C,D where (A='Rowling' and C contains 'Harry Potter')")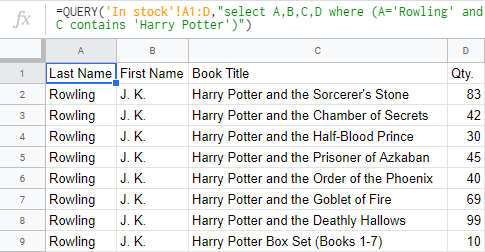
- Pomocí funkce QUERY v tabulkách Google můžete všechny tyto knihy také spočítat:
=QUERY('Skladem'!A1:D, "select A,B, sum(D) where (A='Rowling' and C contains 'Harry Potter') group by A,B")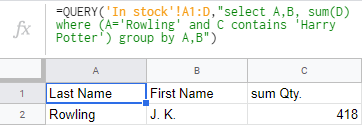
Myslím, že zatím máte představu o tom, jak funkce QUERY "odstraňuje duplicity" v tabulkách Google. I když je to možnost dostupná všem, pro mě je to spíše oklikou ke spojení duplicitních řádků.
Tip: QUERY je tak výkonný, že dokáže sloučit nejen duplikáty v rámci listu - dokáže porovnat & amp; sloučit celé tabulky dohromady.
Navíc dokud se nenaučíte dotazy, které používá, a pravidla jejich použití, nebude vám funkce příliš nápomocná.
Nejrychlejší způsob kombinování duplicitních řádků
Když už přestanete doufat, že najdete jednoduché řešení, jak spojit více řádků na základě duplicit, náš doplněk pro tabulky Google vám skvěle pomůže :)
Sloučit duplicitní řádky prohledá sloupec s opakujícími se záznamy, sloučí odpovídající buňky z jiných sloupců, oddělí tyto záznamy pomocí oddělovačů a sloučí čísla. To vše najednou a během několika kliknutí myší!
Pamatujete si na můj seznam knih v obchodě s několika stovkami řádků? Podívejme se, jak si s ním nástroj poradí.
Tip: Vzhledem k tomu, že nástroj je součástí Power Tools, nainstalujte si jej nejprve a přejděte přímo na stránku Sloučit & amp; Kombinovat skupina:
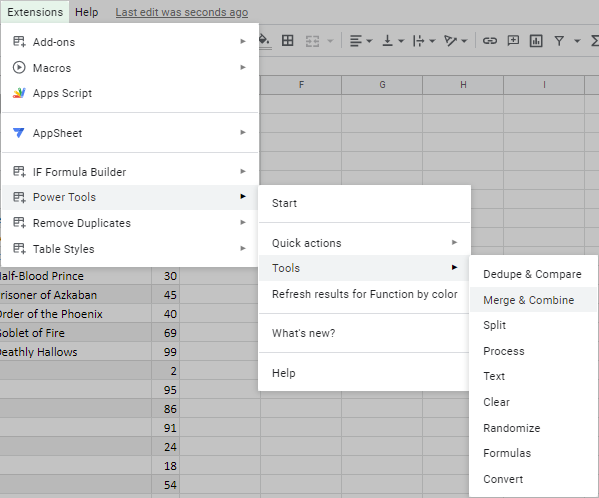
Poté klikněte na ikonu doplňku a otevřete jej:
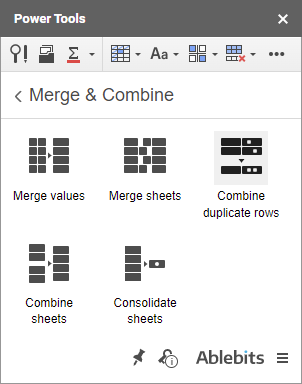
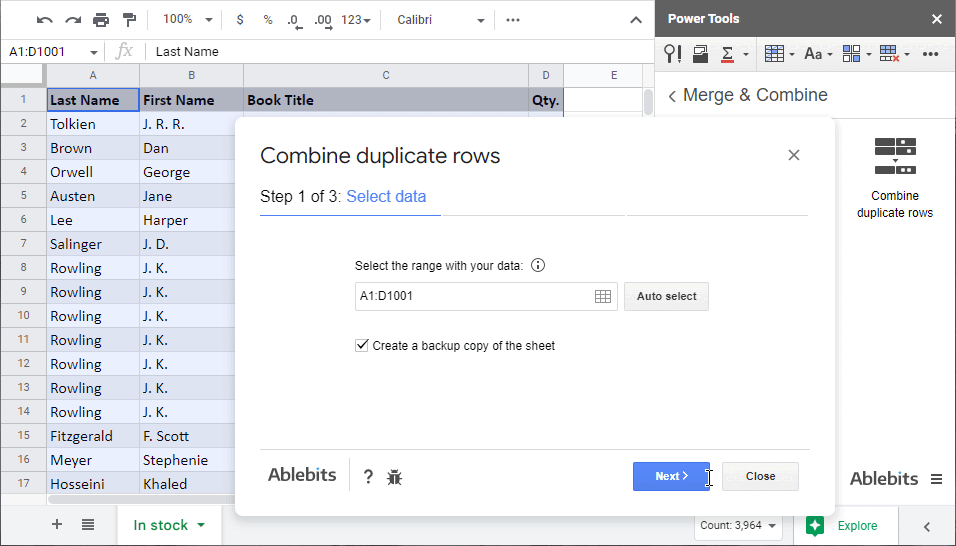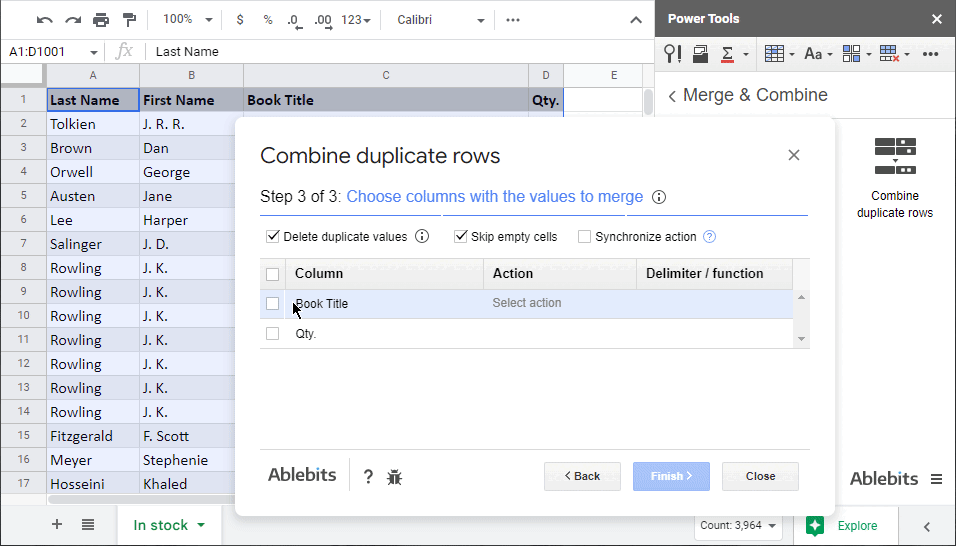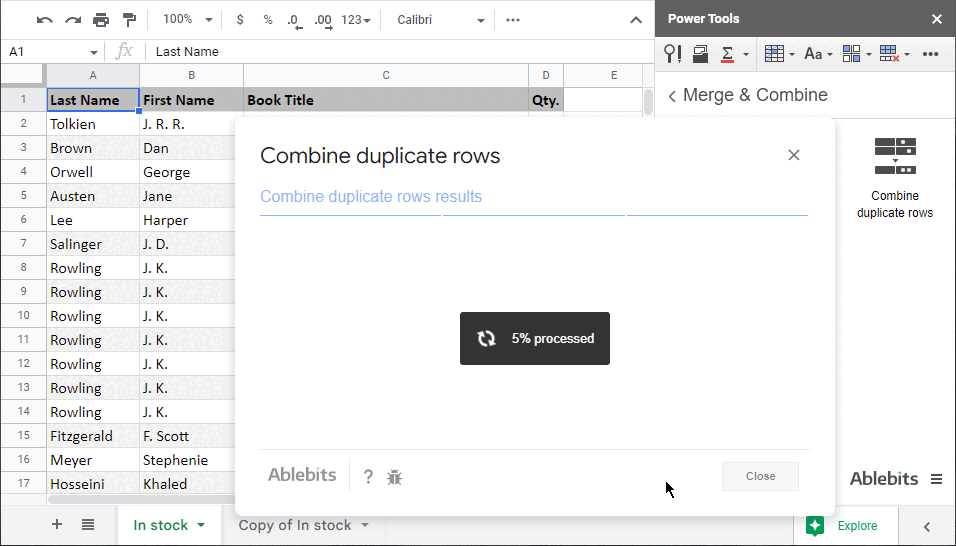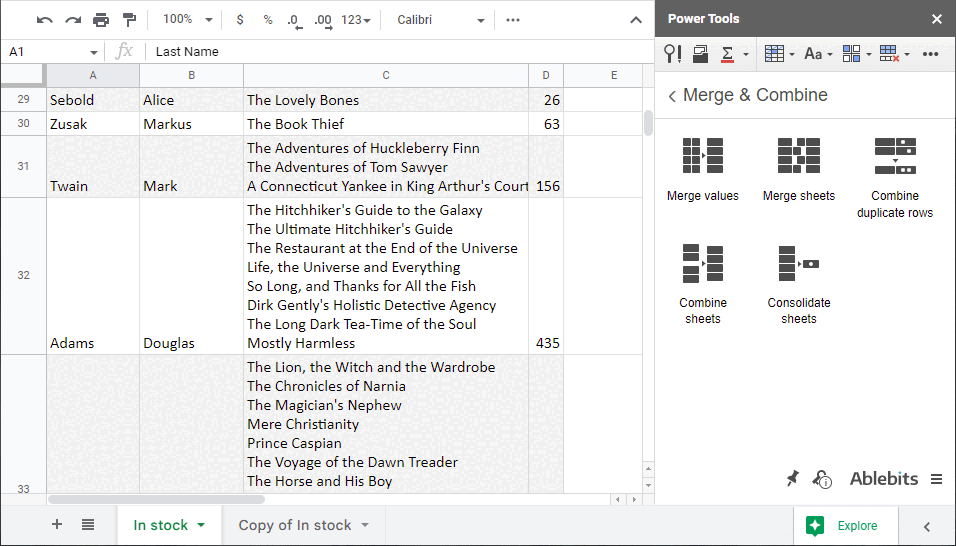
- Po spuštění doplňku vyberte rozsah, ve kterém chcete sloučit duplicitní řádky:
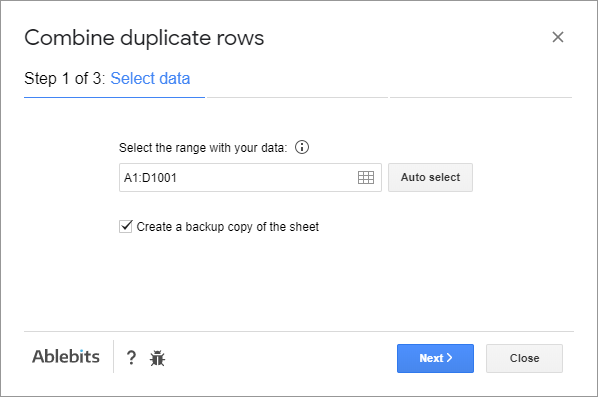
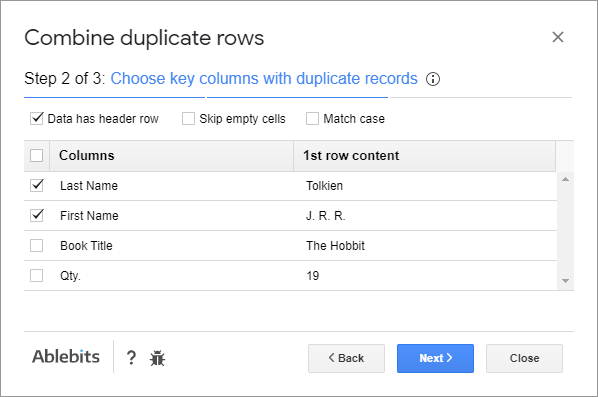
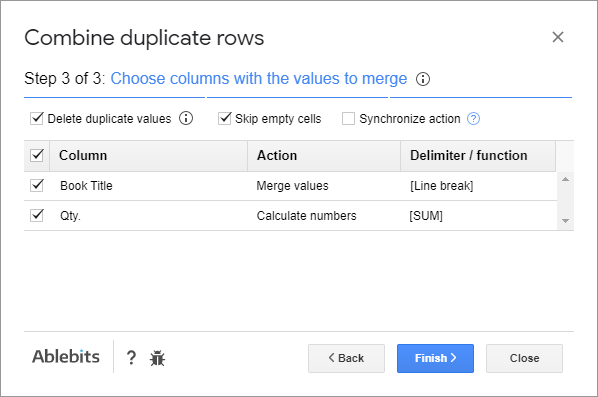
- sloupce s hodnotami, které spojíte dohromady
- způsoby, jak tyto záznamy kombinovat: sloučit nebo vypočítat.
- oddělovač pro sloučení buněk s textem
- funkce pro výpočet čísel
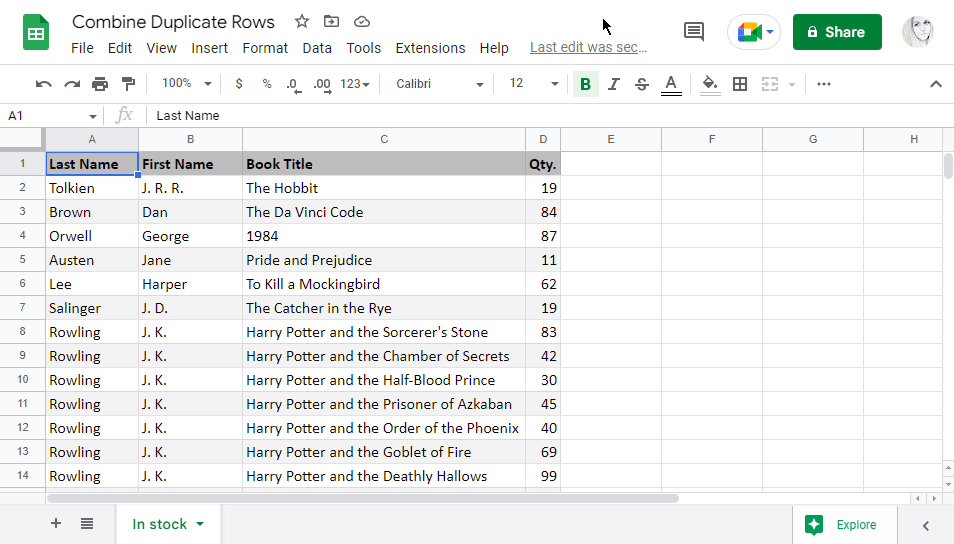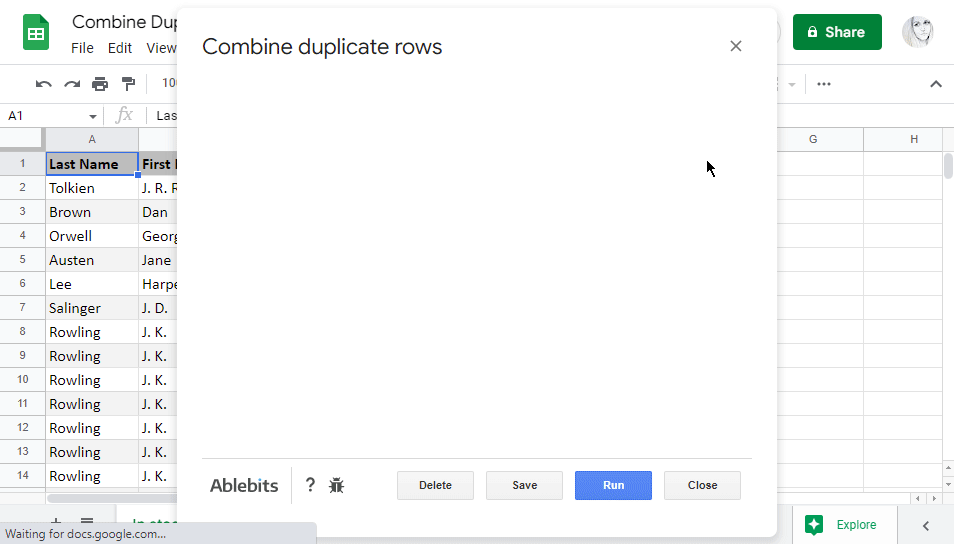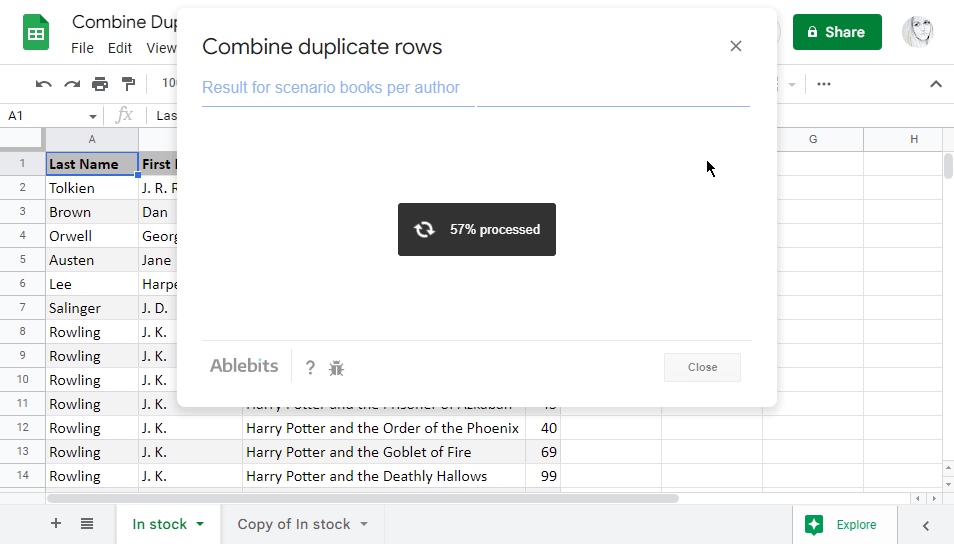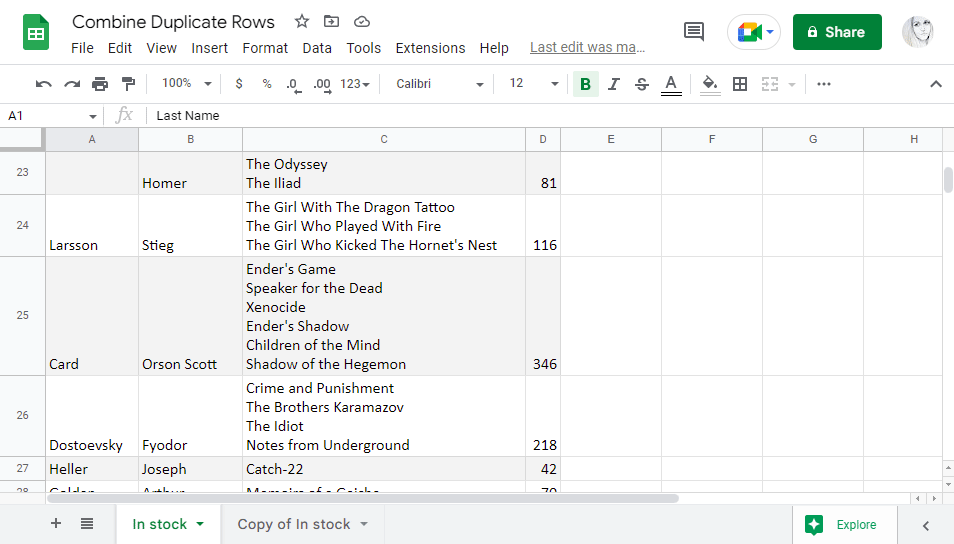
Chtěl bych, aby všechny knihy patřící jednomu autorovi byly přeneseny do jedné buňky a odděleny přerušovacími řádky. Pokud se některé tituly opakují, doplněk je zobrazí pouze jednou.
Co se týče množství, nevadí mi, když se sečtou všechny knihy podle autora. Čísla pro duplicitní tituly, pokud nějaké jsou, se sečtou.
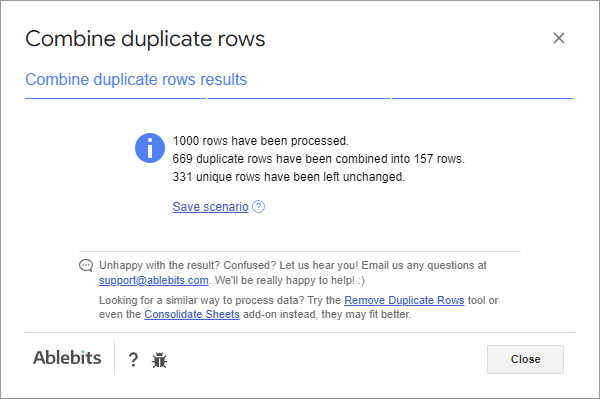
Nástroj sloučil duplicitní řádky v mém seznamu knih. Zde je část toho, jak nyní vypadají moje data:
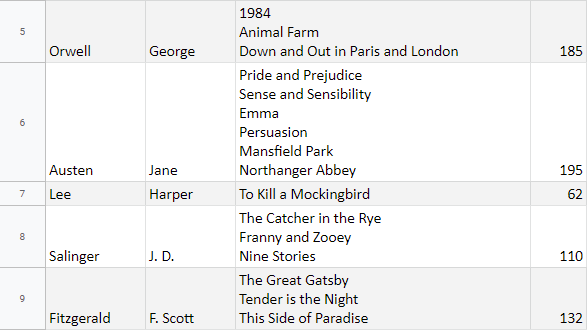
Tip: Případně můžete jeden list rozdělit na více listů, abyste měli samostatnou tabulku se všemi knihami podle autora, nebo zvýraznit duplicitní řádky v tabulkách Google.
Tip. Podívejte se, jak jsem doplněk použil:
Nebo se podívejte na krátké video s představením nástroje:
Použití scénářů k poloautomatickému slučování duplikátů
Další možností, kterou kombinace Duplicitní řádky nabízí, je poloautomatické použití.
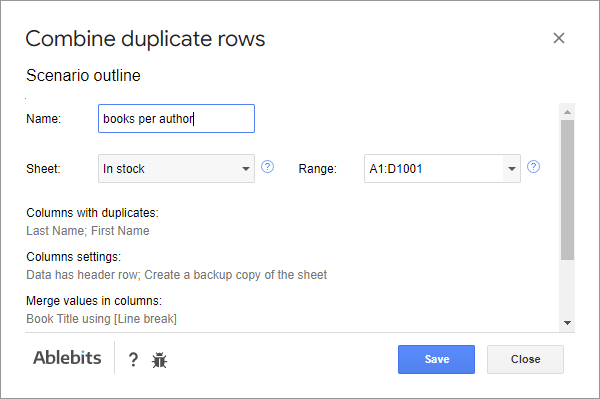
Pokud často procházíte jednotlivými kroky a vybíráte stejné možnosti, můžete je uložit do scénářů. Scénáře vám umožní bez námahy znovu použít stejná nastavení na stejných nebo různých datových sadách.
Scénář je třeba pojmenovat & zadat list a rozsah, který by měl zpracovávat:
Nastavení, která zde uložíte, lze rychle vyvolat z nabídky Tabulky Google. Doplněk začne ihned slučovat duplicitní řádky, čímž vám ušetří trochu času navíc:
Opravdu vám doporučuji, abyste se s nástrojem a jeho možnostmi lépe seznámili, protože Google Sheets je "temný a plný hrůz", jestli víte, co myslím ;)
