
Sadržaj
Udžbenik se fokusira na to kako napraviti nasumično uzorkovanje u Excelu bez ponavljanja. Pronaći ćete rješenja za Excel 365, Excel 2021, Excel 2019 i starije verzije.
Prije nekog vremena opisali smo nekoliko različitih načina nasumičnog odabira u Excelu. Većina tih rješenja oslanja se na funkcije RAND i RANDBETWEEN, koje mogu generirati duple brojeve. Posljedično, vaš nasumični uzorak može sadržavati ponavljajuće vrijednosti. Ako trebate nasumični odabir bez duplikata, upotrijebite pristupe opisane u ovom vodiču.
Excel slučajni odabir s popisa bez duplikata
Radi samo u Excel 365 i Excel 2021 koji podržavaju dinamičke nizove.
Da biste napravili nasumični odabir s popisa bez ponavljanja, upotrijebite ovu generičku formulu:
INDEX(SORTBY( data, RANDARRAY(ROWS( data))), SEQUENCE( n))Gdje je n željena veličina odabira.
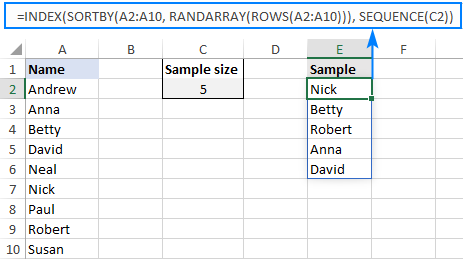
Na primjer, da biste dobili 5 jedinstvenih nasumičnih imena s popisa u A2:A10, evo formule za korištenje:
=INDEX(SORTBY(A2:A10, RANDARRAY(ROWS(A2:A10))), SEQUENCE(5))
Radi praktičnosti, možete unijeti veličinu uzorka u unaprijed definiranu ćeliju, recimo C2, i dostavite referencu ćelije funkciji SEQUENCE:
=INDEX(SORTBY(A2:A10, RANDARRAY(ROWS(A2:A10))), SEQUENCE(C2))
Kako ova formula radi:
Ovdje je objašnjenje logike formule na visokoj razini: funkcija RANDARRAY stvara niz nasumičnih brojeva, SORTBY razvrstava izvorne vrijednosti prema tim brojevima, a INDEX dohvaća onoliko vrijednosti kolikospecificirano SEQUENCE.
Detaljna raščlamba slijedi u nastavku:
Funkcija ROWS broji koliko redaka sadrži vaš skup podataka i prosljeđuje broj funkciji RANDARRAY, tako da može generirati isti broj nasumične decimale:
RANDARRAY(ROWS(A2:C10))
Ovaj niz nasumičnih decimala koristi se kao niz "razvrstaj po" u funkciji SORTBY. Kao rezultat toga, vaši se izvorni podaci nasumično miješaju.
Iz nasumično sortiranih podataka izdvajate uzorak određene veličine. Da biste to učinili, isporučujete izmiješani niz funkciji INDEX i zahtijevate dohvaćanje prvih N vrijednosti uz pomoć funkcije SEQUENCE, koja proizvodi niz brojeva od 1 do N . Budući da su izvorni podaci već poredani nasumičnim redoslijedom, nije nam bitno koje ćemo pozicije dohvatiti, bitna je samo količina.
Odaberite nasumične retke u Excelu bez duplikata
Radi samo u programima Excel 365 i Excel 2021 koji podržavaju dinamičke nizove.
Da biste odabrali nasumične retke bez ponavljanja, izgradite formulu na ovaj način:
INDEX(SORTBY( data, RANDARRAY(ROWS( data))), SEQUENCE( n), {1,2,…})Gdje je n veličina uzorka i {1,2,…} su brojevi stupaca koje treba izdvojiti.
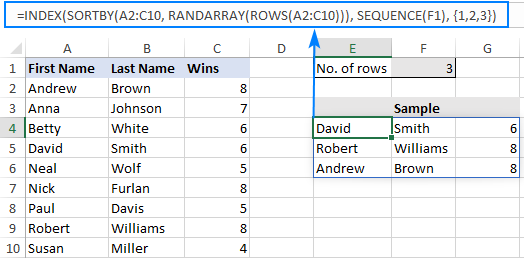
Kao primjer, odaberimo nasumične retke iz A2:C10 bez dvostrukih unosa, na temelju veličine uzorka u F1. Budući da su naši podaci u 3 stupca, ovu konstantu niza unosimo u formulu:{1,2,3}
=INDEX(SORTBY(A2:C10, RANDARRAY(ROWS(A2:C10))), SEQUENCE(F1), {1,2,3})
I dobiti sljedeći rezultat:
Kako ova formula radi:
Formula funkcionira potpuno istom logikom kao i prethodna. Mala promjena koja čini veliku razliku jest to što navodite argumente row_num i column_num za funkciju INDEX: row_num dobivaju SEQUENCE i column_num pomoću konstante polja.
Kako izvršiti nasumično uzorkovanje u programu Excel 2010 - 2019
Budući da samo Excel za Microsoft 365 i Excel 2021 podržavaju dinamička polja, funkcije dinamičkog polja koje se koriste u prethodni primjeri rade samo u programu Excel 365. Za druge verzije, morat ćete pronaći drugačije rješenje.
Pretpostavimo da želite nasumični odabir s popisa u A2:A10. To se može učiniti pomoću 2 zasebne formule:
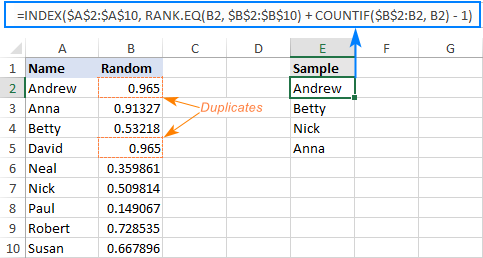
- Generiraj nasumične brojeve pomoću formule Rand. U našem slučaju, unosimo ga u B2, a zatim kopiramo dolje u B10:
=RAND() - Izdvojite prvu slučajnu vrijednost s donjom formulom koju unesete u E2:
=INDEX($A$2:$A$10, RANK.EQ(B2, $B$2:$B$10) + COUNTIF($B$2:B2, B2) - 1) - Kopirajte gornju formulu u onoliko ćelija koliko god nasumičnih vrijednosti želite odabrati. U ovom primjeru želimo 4 imena, pa kopiramo formulu od E2 do E5.
Gotovo! Naš nasumični uzorak bez duplikata izgleda ovako:
Kako funkcionira ova formula:
Kao u prvom primjeru, koristite Funkcija INDEX za dohvaćanje vrijednosti iz stupca A na temelju slučajnog retkabrojevima. Razlika je u tome kako dobivate te brojeve:
Funkcija RAND ispunjava raspon B2:B10 nasumičnim decimalama.
Funkcija RANK.EQ izračunava rang slučajnog broja u danom red. Na primjer, u E2, RANK.EQ(B2, $B$2:$B$10) rangira broj u B2 u odnosu na sve brojeve u B2:B10. Kada se kopira u E3, relativna referenca B2 mijenja se u B3 i vraća rang broja u B3, i tako dalje.
Funkcija COUNTIF pronalazi koliko se pojavljivanja određenog broja nalazi u gornjim ćelijama. Na primjer, u E2, COUNTIF($B$2:B2, B2) provjerava samo jednu ćeliju - samu B2, i vraća 1. U E5, formula se mijenja u COUNTIF($B$2:B5, B5) i vraća 2, jer B5 sadrži istu vrijednost kao B2 (napominjemo da je ovo samo radi boljeg objašnjenja logike formule; na malom skupu podataka šanse za dobivanje duplih nasumičnih brojeva su blizu nule).
Kao rezultat, za sve Prvo pojavljivanje, COUNTIF vraća 1, od kojeg oduzimate 1 kako biste zadržali izvorni poredak. Za 2. pojavljivanja, COUNTIF vraća 2. Oduzimanjem 1 povećavate poredak za 1, čime se sprječavaju dvostruki rangovi.
Na primjer, za B2, RANK.EQ vraća 1. Kako je ovo prvo pojavljivanje, COUNTIF također vraća 1. RANK.EQ + COUNTIF daje 2. I - 1 vraća rang 1.
Sada, pogledajte što se događa u slučaju 2. pojavljivanja. Za B5, RANK.EQ također vraća 1 dok COUNTIF vraća 2. Zbrajanje ovih daje3, od kojeg oduzimate 1. Kao konačni rezultat dobivate 2, što predstavlja rang broja u B5.
Rang ide na argument row_num funkcije INDEX , i odabire vrijednost iz odgovarajućeg retka (argument column_num je izostavljen, pa je zadana vrijednost 1). To je razlog zašto je tako važno izbjeći duplo rangiranje. Da nije bilo funkcije COUNTIF, RANK.EQ bi dao 1 i za B2 i za B5, uzrokujući da INDEX dva puta vrati vrijednost iz prvog retka (Andrew).
Kako spriječiti promjenu slučajnog uzorka programa Excel
Budući da su sve funkcije nasumičnog odabira u Excelu kao što su RAND, RANDBETWEEN i RANDARRAY nepostojane, ponovno se izračunavaju sa svakom promjenom na radnom listu. Kao rezultat toga, vaš slučajni uzorak će se neprestano mijenjati. Kako biste spriječili da se to dogodi, koristite Paste Special > Značajka vrijednosti za zamjenu formula statičkim vrijednostima. Za to izvedite ove korake:
- Odaberite sve ćelije sa svojom formulom (bilo koja formula koja sadrži funkciju RAND, RANDBETWEEN ili RANDARRAY) i pritisnite Ctrl + C da ih kopirate.
- Desnom tipkom miša kliknite odabrani raspon i kliknite Posebno lijepljenje > Vrijednosti . Alternativno, pritisnite Shift + F10, a zatim V , što je prečac za gore navedenu značajku.
Za detaljne korake pogledajte Kako pretvoriti formule u vrijednosti u Excelu.
Excel slučajni odabir: redovi, stupciili ćelije
Radi u svim verzijama Excela 365 do Excela 2010.
Ako imate naš Ultimate Suite instaliran u svom Excelu, tada možete izvršiti nasumično uzorkovanje pomoću klik mišem umjesto formule. Evo kako:
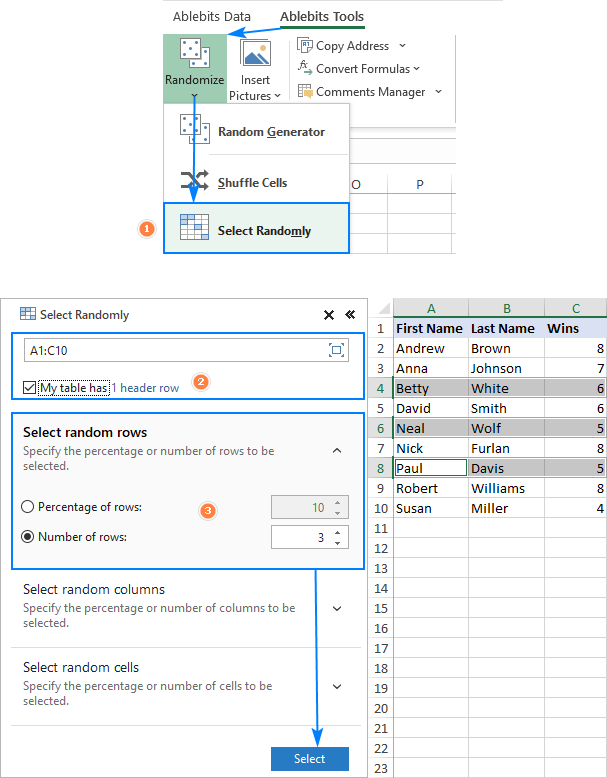
- Na kartici Alatebits Tools kliknite Randomize > Select Randomy .
- Odaberite raspon iz kojeg želite odabrati uzorak.
- U oknu dodatka učinite sljedeće:
- Odaberite želite li odabrati nasumične retke, stupce ili ćelije.
- Definirajte veličinu uzorka: to može biti postotak ili broj.
- Kliknite gumb Odaberi .
To je to! Kao što je prikazano na slici ispod, nasumični uzorak odabire se izravno u vašem skupu podataka. Ako ga želite negdje kopirati, samo pritisnite uobičajeni prečac za kopiranje (Ctrl + C) .
Tako možete odabrati nasumični uzorak u Excelu bez duplikata. Zahvaljujem vam na čitanju i nadam se da se vidimo na našem blogu sljedeći tjedan!
Dostupna preuzimanja
Nasumični uzorak bez duplikata - primjeri formula (.xlsx datoteka)
Ultimate Suite 14-dnevna potpuno funkcionalna verzija (.exe datoteka)
