
Kazalo
V učbeniku se osredotočamo na to, kako v Excelu opraviti naključno vzorčenje brez ponovitev. Našli boste rešitve za Excel 365, Excel 2021, Excel 2019 in prejšnje različice.
Pred časom smo opisali nekaj različnih načinov naključne izbire v Excelu. Večina teh rešitev temelji na funkcijah RAND in RANDBETWEEN, ki lahko ustvarita podvojene številke. Posledično lahko naključni vzorec vsebuje ponavljajoče se vrednosti. Če potrebujete naključno izbiro brez podvojitev, uporabite pristope, opisane v tem vodniku.
Excelov naključni izbor s seznama brez dvojnikov
Deluje samo v programih Excel 365 in Excel 2021, ki podpirajo dinamična polja.
Za naključno izbiro s seznama, ki se ne ponavlja, uporabite to splošno formulo:
INDEX(SORTBY( podatki , RANDARRAY(VRSTICE( podatki ))), SEQUENCE( n ))Kje: n je želena velikost izbora.
Če želite na primer s seznama A2:A10 dobiti 5 edinstvenih naključnih imen, uporabite naslednjo formulo:
=INDEX(SORTBY(A2:A10, RANDARRAY(ROWS(A2:A10))), SEQUENCE(5))
Zaradi priročnosti lahko velikost vzorca vnesete v vnaprej določeno celico, na primer C2, in funkciji SEQUENCE posredujete sklic na celico:
=INDEX(SORTBY(A2:A10, RANDARRAY(ROWS(A2:A10))), SEQUENCE(C2))
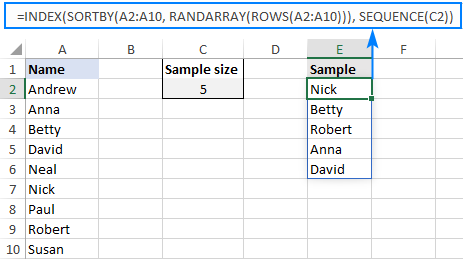
Kako deluje ta formula:
Tu je razlaga logike formule na visoki ravni: funkcija RANDARRAY ustvari polje naključnih števil, SORTBY razvrsti izvirne vrednosti po teh številkah, INDEX pa pridobi toliko vrednosti, kot jih določa SEQUENCE.
Podrobna razčlenitev je navedena v nadaljevanju:
Funkcija ROWS prešteje, koliko vrstic vsebuje podatkovni niz, in to število posreduje funkciji RANDARRAY, da lahko ustvari enako število naključnih decimalk:
RANDARRAY(VRSTICE(A2:C10))
Funkcija SORTBY to polje naključnih decimalk uporabi kot polje "razvrstitev po". Tako se vaši prvotni podatki naključno premešajo.
Iz naključno razvrščenih podatkov izluščite vzorec določene velikosti. V ta namen funkciji INDEX posredujete premešano polje in zahtevate, da se pridobi prvi N vrednosti s pomočjo funkcije SEQUENCE, ki ustvari zaporedje številk od 1 do N Ker so prvotni podatki že razvrščeni v naključnem vrstnem redu, nam je vseeno, katera mesta bomo pridobili, pomembna je le količina.
Izberite naključne vrstice v Excelu brez podvojitev
Deluje samo v programih Excel 365 in Excel 2021, ki podpirajo dinamična polja.
Če želite izbrati naključne vrstice brez ponovitev, sestavite formulo na ta način:
INDEX(SORTBY( podatki , RANDARRAY(VRSTICE( podatki ))), SEQUENCE( n ), {1,2,...})Kje: n je velikost vzorca, {1,2,...} pa so številke stolpcev, ki jih je treba izluščiti.
Kot primer izberimo naključne vrstice iz A2:C10 brez podvojenih vnosov na podlagi velikosti vzorca v F1. Ker so naši podatki v treh stolpcih, formuli dodamo to konstanto polja: {1,2,3}
=INDEX(SORTBY(A2:C10, RANDARRAY(ROWS(A2:C10))), SEQUENCE(F1), {1,2,3})
In dobite naslednji rezultat:
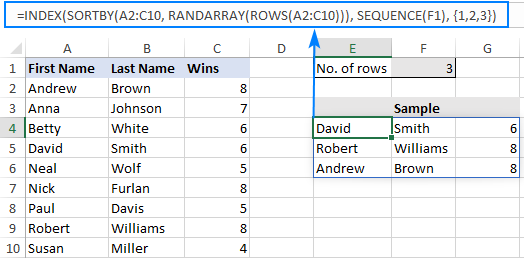
Kako deluje ta formula:
Formula deluje s popolnoma enako logiko kot prejšnja formula. Majhna sprememba, ki pomeni veliko razliko, je, da določite oba vrstica_številka in . številka_stolpca argumentov za funkcijo INDEX: vrstica_številka je zagotovljena s SEQUENCE in številka_stolpca s konstanto polja.
Kako opraviti naključno vzorčenje v programu Excel 2010 - 2019
Ker dinamična polja podpirata le programa Excel za Microsoft 365 in Excel 2021, funkcije dinamičnih polj, uporabljene v prejšnjih primerih, delujejo le v programu Excel 365. Za druge različice boste morali poiskati drugačno rešitev.
Predpostavimo, da želite naključni izbor s seznama v A2:A10. To lahko storite z dvema ločenima formulama:
- Generirajte naključne številke s formulo Rand. V našem primeru jo vnesemo v B2 in nato kopiramo navzdol v B10:
=RAND() - Prvo naključno vrednost pridobite s spodnjo formulo, ki jo vnesite v E2:
=INDEX($A$2:$A$10, RANK.EQ(B2, $B$2:$B$10) + COUNTIF($B$2:B2, B2) - 1) - Zgornjo formulo kopirajte v toliko celic, kolikor naključnih vrednosti želite izbrati. V tem primeru želimo 4 imena, zato formulo kopiramo od E2 do E5.
Končano! Naš naključni vzorec brez dvojnikov je videti takole:
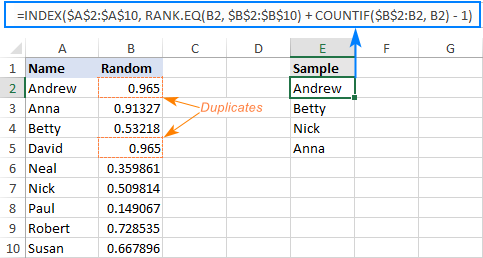
Kako deluje ta formula:
Podobno kot v prvem primeru uporabite funkcijo INDEX za pridobivanje vrednosti iz stolpca A na podlagi naključnih številk vrstic. Razlika je v tem, kako te številke dobite:
Funkcija RAND zapolni območje B2:B10 z naključnimi decimalkami.
Funkcija RANK.EQ izračuna rang naključnega števila v dani vrstici. Na primer, v E2 funkcija RANK.EQ(B2, $B$2:$B$10) razvrsti število v B2 glede na vsa števila v B2:B10. Pri kopiranju v E3 se relativna referenca B2 spremeni v B3 in vrne rang števila v B3 in tako naprej.
Funkcija COUNTIF ugotovi, koliko pojavitev danega števila je v zgornjih celicah. Na primer, v E2 funkcija COUNTIF($B$2:B2, B2) preveri samo eno celico - B2 in vrne 1. V E5 se formula spremeni v COUNTIF($B$2:B5, B5) in vrne 2, ker B5 vsebuje enako vrednost kot B2 (upoštevajte, da je to samo zaradi boljše razlage logike formule; pri majhnem naboru podatkov je možnost, da dobitepodvojena naključna števila so blizu nič).
Kot rezultat, za vse prve pojavitve COUNTIF vrne 1, od katerega odštejete 1, da ohranite prvotno razvrstitev. Za druge pojavitve COUNTIF vrne 2. Z odštevanjem 1 povečate razvrstitev za 1, s čimer preprečite podvajanje razvrstitev.
Na primer, za B2, RANK.EQ vrne 1. Ker je to prvi pojav, tudi COUNTIF vrne 1. RANK.EQ + COUNTIF da 2. In - 1 povrne rang 1.
Zdaj poglejte, kaj se zgodi v primeru 2. pojavitve. Za B5 RANK.EQ prav tako vrne 1, COUNTIF pa 2. Če ju seštejete, dobite 3, od katerega odštejete 1. Kot končni rezultat dobite 2, ki predstavlja rang števila v B5.
Častni naziv pripada vrstica_številka argumenta funkcije INDEX in izbere vrednost iz ustrezne vrstice (argument številka_stolpca To je razlog, zakaj je tako pomembno, da se izognemo podvojenemu razvrščanju. Če ne bi bilo funkcije COUNTIF, bi funkcija RANK.EQ dala vrednost 1 za B2 in B5, zaradi česar bi INDEX dvakrat vrnil vrednost iz prve vrstice (Andrew).
Kako preprečiti spreminjanje naključnega vzorca programa Excel
Ker so vse naključne funkcije v Excelu, kot so RAND, RANDBETWEEN in RANDARRAY, spremenljive, se preračunajo ob vsaki spremembi na delovnem listu. Zato se bo vaš naključni vzorec nenehno spreminjal. Če želite to preprečiti, uporabite funkcijo Paste Special> Values, da formule nadomestite s statičnimi vrednostmi. V ta namen izvedite naslednje korake:
- Izberite vse celice z vašo formulo (vse formule, ki vsebujejo funkcije RAND, RANDBETWEEN ali RANDARRAY) in pritisnite kombinacijo tipk Ctrl + C, da jih kopirate.
- Z desno tipko miške kliknite izbrano območje in kliknite Posebna prilepitev > Vrednosti Druga možnost je, da pritisnete Shift + F10 in nato V , kar je bližnjica za zgoraj navedeno funkcijo.
Za podrobne korake glejte Kako pretvoriti formule v vrednosti v Excelu.
Naključna izbira programa Excel: vrstice, stolpci ali celice
Deluje v vseh različicah Excel 365 do Excel 2010.
Če imate v Excelu nameščen naš paket Ultimate Suite, lahko naključno vzorčenje namesto s formulo opravite s klikom miške:
- Na Orodja Ablebits kliknite zavihek Naključno > Izberite naključno .
- Izberite območje, iz katerega želite izbrati vzorec.
- V podoknu dodatka naredite naslednje:
- Izberite, ali želite izbrati naključne vrstice, stolpce ali celice.
- Določite velikost vzorca: lahko je v odstotkih ali številu.
- Kliknite na Izberite gumb.
Kot je prikazano na spodnji sliki, je naključni vzorec izbran neposredno v vašem podatkovnem nizu. Če ga želite kam kopirati, pritisnite običajno bližnjico za kopiranje (Ctrl + C) .
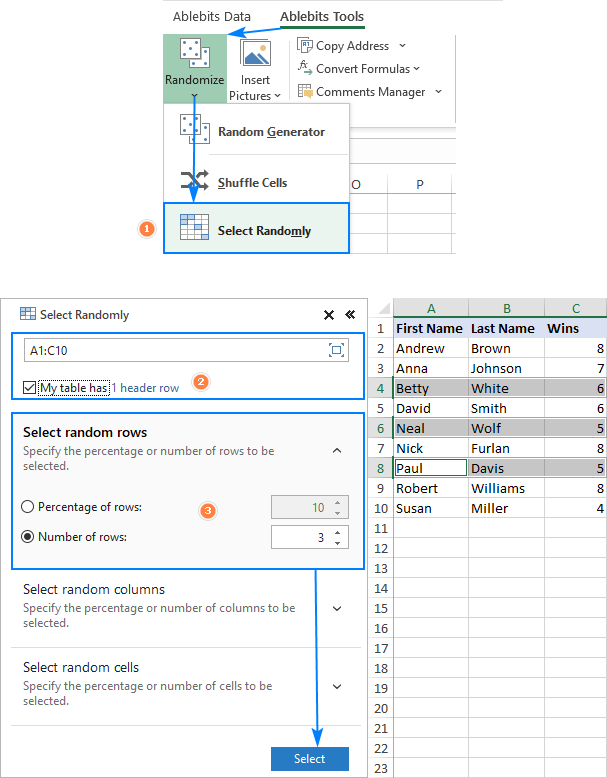
To je način izbire naključnega vzorca v programu Excel brez podvajanja. Zahvaljujem se vam za branje in upam, da se naslednji teden vidimo na našem blogu!
Razpoložljivi prenosi
Naključni vzorec brez dvojnikov - primeri formul (.xlsx datoteka)
Ultimate Suite 14-dnevna popolnoma funkcionalna različica (.exe datoteka)
