
Obsah
Toto je závěrečný díl seriálu o jedinečných hodnotách v aplikaci Excel, který ukazuje, jak získat seznam odlišných / jedinečných hodnot ve sloupci pomocí vzorce a jak tento vzorec upravit pro různé datové sady. Dozvíte se také, jak rychle získat seznam odlišných hodnot pomocí pokročilého filtru aplikace Excel a jak získat jedinečné řádky pomocí nástroje Odstranění duplicit.
V několika nedávných článcích jsme se zabývali různými způsoby, jak v Excelu počítat a vyhledávat jedinečné hodnoty. Pokud jste měli možnost tyto návody číst, už víte, jak získat jedinečný nebo odlišný seznam pomocí identifikace, filtrování a kopírování. To je ale trochu zdlouhavý a zdaleka ne jediný způsob, jak v Excelu získat jedinečné hodnoty. Můžete to udělat mnohem rychleji pomocí speciálního vzorce a za chvíliUkážu vám tuto a několik dalších technik.
Tip: Chcete-li rychle získat jedinečné hodnoty v nejnovější verzi aplikace Excel 365, která podporuje dynamická pole, použijte funkci UNIQUE, jak je vysvětleno ve výše uvedeném odkazovaném tutoriálu.
Jak získat jedinečné hodnoty v aplikaci Excel
Aby nedošlo k nedorozumění, dohodněme se nejprve na tom, čemu v aplikaci Excel říkáme jedinečné hodnoty. Jedinečné hodnoty jsou hodnoty, které se v seznamu vyskytují pouze jednou. Například:
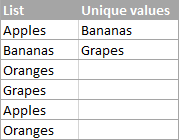
Chcete-li v aplikaci Excel získat seznam jedinečných hodnot, použijte jeden z následujících vzorců.
Pole vzorec pro jedinečné hodnoty (dokončí se stisknutím kláves Ctrl + Shift + Enter ):
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1,$A$2:$A$10) + (COUNTIF($A$2:$A$10, $A$2:$A$10)1), 0)), "")
Pravidelné vzorec pro jedinečné hodnoty (dokončí se stisknutím klávesy Enter):
=IFERROR(INDEX($A$2:$A$10, MATCH(0,INDEX(COUNTIF($B$1:B1, $A$2:$A$10)+(COUNTIF($A$2:$A$10, $A$2:$A$10)1),0,0), 0)), "")
Ve výše uvedených vzorcích jsou použity následující odkazy:
- A2:A10 - seznam zdrojů.
- B1 - horní buňka jedinečného seznamu minus 1. V tomto příkladu začínáme jedinečný seznam v buňce B2, a proto do vzorce dosadíme B1 (B2-1=B1). Pokud váš jedinečný seznam začíná například v buňce C3, pak změňte $B$1:B1 na $C$2:C2.
Poznámka: Protože vzorec odkazuje na buňku nad první buňkou jedinečného seznamu, což je obvykle záhlaví sloupce (v tomto příkladu B1), ujistěte se, že záhlaví má jedinečný název, který se nikde jinde ve sloupci nevyskytuje.
V tomto příkladu získáváme jedinečné názvy ze sloupce A (přesněji z rozsahu A2:A20) a následující snímek obrazovky ukazuje vzorec pole v akci:
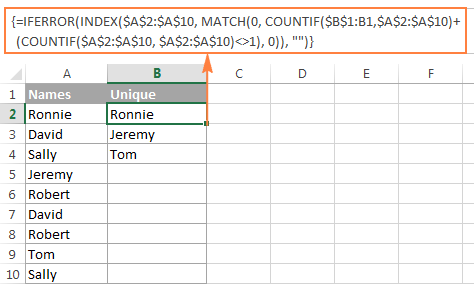
Podrobné vysvětlení logiky vzorce je uvedeno v samostatné části a zde se dozvíte, jak vzorec použít k získání jedinečných hodnot v listech aplikace Excel:
- Upravte jeden ze vzorců podle své sady dat.
- Zadejte vzorec do první buňky jedinečného seznamu (v tomto příkladu B2).
- Pokud používáte vzorec pole, stiskněte klávesy Ctrl + Shift + Enter . Pokud jste se rozhodli pro běžný vzorec, stiskněte jako obvykle klávesu Enter.
- Přetažením úchytu výplně vzorec zkopírujte dolů, kam až bude potřeba. Protože oba vzorce pro jedinečné hodnoty jsou zapouzdřeny ve funkci IFERROR, můžete vzorec zkopírovat až na konec tabulky a nebude zahlcovat data žádnými chybami bez ohledu na to, jak málo jedinečných hodnot bylo extrahováno.
Jak získat odlišné hodnoty v aplikaci Excel (jedinečné + 1. duplicitní výskyt)
Jak jste již možná vytušili z nadpisu této části, odlišné hodnoty v Excelu jsou všechny různé hodnoty v seznamu, tj. jedinečné hodnoty a první případy duplicitních hodnot. Např:
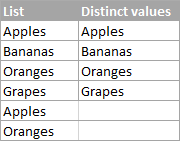
Chcete-li v aplikaci Excel získat odlišný seznam, použijte následující vzorce.
Pole odlišný vzorec (vyžaduje stisknutí kláves Ctrl + Shift + Enter ):
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10), 0)), "")
Pravidelné odlišný vzorec:
=IFERROR(INDEX($A$2:$A$10, MATCH(0, INDEX(COUNTIF($B$1:B1, $A$2:$A$10), 0, 0), 0)), "")
Kde:
- A2:A10 je seznam zdrojů.
- B1 je buňka nad první buňkou odlišného seznamu. V tomto příkladu začíná odlišný seznam v buňce B2 (je to první buňka, do které zadáváte vzorec), takže odkazujete na B1.
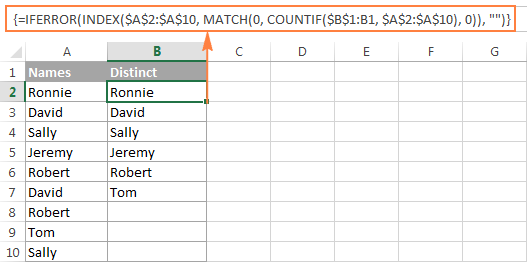
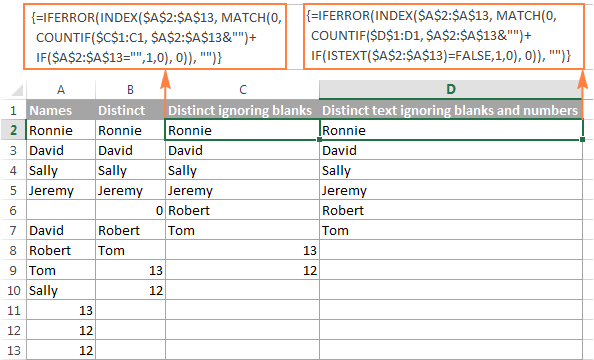
Výpis různých hodnot ve sloupci bez ohledu na prázdné buňky
Pokud váš zdrojový seznam obsahuje prázdné buňky, výrazný vzorec, který jsme právě probrali, by vracel nulu pro každý prázdný řádek, což by mohl být problém. Chcete-li to napravit, vzorec ještě trochu vylepšete:
Vzorec pole pro extrakci odlišné hodnoty bez prázdných míst :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF($A$2:$A$10="",1,0), 0)), "")
Získání seznamu různých textových hodnot bez čísel a mezer
Podobným způsobem můžete získat seznam různých hodnot. s výjimkou prázdných buněk a buněk s čísly :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF(ISTEXT($A$2:$A$10)=FALSE,1,0), 0)), "")
Pro rychlou připomínku, ve výše uvedených vzorcích je A2:A10 zdrojový seznam a B1 je buňka hned nad první buňkou odlišného seznamu.
Následující snímek obrazovky ukazuje výsledek obou vzorců:
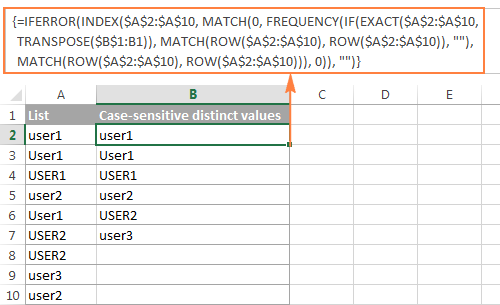
Jak v aplikaci Excel extrahovat odlišné hodnoty rozlišující malá a velká písmena
Při práci s daty, u kterých se rozlišují malá a velká písmena, jako jsou hesla, uživatelská jména nebo názvy souborů, můžete potřebovat získat seznam odlišných hodnot, u kterých se rozlišují velká a malá písmena. K tomu použijte následující vzorec pole, kde A2:A10 je zdrojový seznam a B1 je buňka nad první buňkou odlišného seznamu:
Vzorec pole pro získání odlišných hodnot rozlišujících velká a malá písmena (vyžaduje stisknutí kláves Ctrl + Shift + Enter )
=IFERROR(INDEX($A$2:$A$10, MATCH(0, FREQUENCY(IF(EXACT($A$2:$A$10,TRANSPOSE($B$1:B1)), MATCH(ROW($A$2:$A$10), ROW($A$2:$A$10)), ""), MATCH(ROW($A$2:$A$10), ROW($A$2:$A$10))), 0)), "")
Jak funguje vzorec unique / distinct
Tato část je určena především těm zvídavým a přemýšlivým uživatelům aplikace Excel, kteří chtějí nejen znát vzorec, ale také plně porozumět jeho zádrhelům.
Je samozřejmé, že vzorce pro získání jedinečných a odlišných hodnot v aplikaci Excel nejsou triviální ani jednoduché. Při bližším pohledu si však můžete všimnout, že všechny vzorce jsou založeny na stejném přístupu - použití INDEX/MATCH v kombinaci s funkcí COUNTIF, případně COUNTIF + IF.
Pro naši podrobnou analýzu použijeme vzorec pole, který extrahuje seznam různých hodnot, protože všechny ostatní vzorce probírané v tomto tutoriálu jsou vylepšeními nebo variacemi tohoto základního vzorce:
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10), 0)), "")
Pro začátek si odmysleme zřejmou funkci IFERROR, která se používá s jediným účelem, a to eliminovat chyby #N/A, když počet buněk, do kterých jste zkopírovali vzorec, přesahuje počet různých hodnot ve zdrojovém seznamu.
A nyní si rozebereme hlavní část našeho odlišného vzorce:
- COUNTIF(rozsah, kritéria) vrátí počet buněk v rozsahu, které splňují zadanou podmínku.
V tomto příkladu COUNTIF($B$1:B1, $A$2:$A$10) vrací pole 1 a 0 podle toho, zda se některá z hodnot zdrojového seznamu ($A$2:$A$10) vyskytuje někde v rozlišovacím seznamu ($B$1:B1). Pokud je hodnota nalezena, vzorec vrací 1, jinak - 0.
Konkrétně v buňce B2 se z COUNTIF($B$1:B1, $A$2:$A$10) stane:
COUNTIF("Distinct", {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"})a návraty:
{0;0;0;0;0;0;0;0;0}protože žádná z položek zdrojového seznamu ( kritéria ) se objevuje v rozsah kde funkce hledá shodu. V tomto případě, rozsah ($B$1:B1) se skládá z jediné položky - "Distinct".
MATCH(lookup_value, lookup_array, [match_type])vrací relativní pozici vyhledávací hodnoty v poli.
V tomto příkladu je hodnota lookup_value 0, a proto:
MATCH(0,COUNTIF($B$1:B1, $A$2:$A$10), 0)
se změní na:
MATCH(0, { 0 ;0;0;0;0;0;0;0;0},0)
a vrací
protože naše funkce MATCH získá první hodnotu, která se přesně rovná vyhledávací hodnotě (jak si pamatujete, vyhledávací hodnota je 0).
V tomto příkladu INDEX($A$2:$A$10, 1)
se stává:
INDEX({"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}, 1)
a vrátí "Ronnie".
Při kopírování vzorce dolů do sloupce se rozšíří odlišný seznam ($B$1:B1), protože odkaz na druhou buňku (B1) je relativní odkaz, který se mění podle relativní polohy buňky, v níž se vzorec pohybuje.
Po zkopírování do buňky B3 se tedy COUNTIF($B$1: B1 , $A$2:$A$10) se změní na COUNTIF($B$1: B2 , $A$2:$A$10) a stává se:
COUNTIF({"Distinct"; "Ronnie"}, {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}), 0)), "")
a návraty:
{1;0;0;0;0;0;0;0;0}
protože v rozsahu $B$1:B2 se nachází jeden "Ronnie".
A pak MATCH(0,{1; 0 ;0;0;0;0;0;0;0;0},0) vrací 2, protože 2 je relativní pozice první 0 v poli.
A konečně, INDEX($A$2:$A$10, 2) vrátí hodnotu z 2. řádku, což je "David".
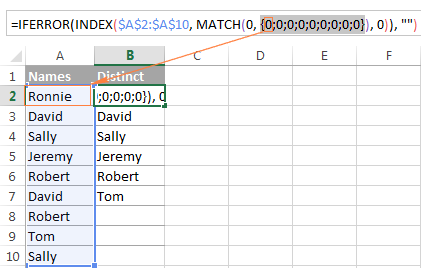
Tip: Pro lepší pochopení logiky vzorce můžete na panelu vzorců vybrat různé části vzorce a stisknutím klávesy F9 zobrazit, co vybraná část vyhodnocuje:
Pokud máte stále potíže s pochopením vzorce, můžete se podívat na následující výukový program, kde je podrobně vysvětleno, jak funguje spojení INDEX/MATCH: INDEX & MATCH jako lepší alternativa k Excel VLOOKUP.
Jak již bylo zmíněno, ostatní vzorce probírané v tomto tutoriálu jsou založeny na stejné logice, pouze s několika úpravami:
Vzorec pro jedinečné hodnoty - obsahuje ještě jednu funkci COUNTIF, která z jedinečného seznamu vyloučí všechny položky, které se ve zdrojovém seznamu vyskytují více než jednou: COUNTIF($A$2:$A$10, $A$2:$A$10)1 .
Vzorec pro rozlišování hodnot ignorující prázdné buňky - zde přidáte funkci IF, která zabrání přidání prázdných buněk do seznamu rozlišovaných hodnot: IF($A$2:$A$13="",1,0) .
Vzorec pro rozlišování textových hodnot ignoruje čísla - pomocí funkce ISTEXT zkontrolujete, zda je hodnota textová, a pomocí funkce IF zamítnete všechny ostatní typy hodnot, včetně prázdných buněk: IF(ISTEXT($A$2:$A$13)=FALSE,1,0) .
Výběr odlišných hodnot ze sloupce pomocí pokročilého filtru aplikace Excel
Pokud nechcete ztrácet čas luštěním tajuplných zákrut vzorců pro zřetelné hodnoty, můžete rychle získat seznam zřetelných hodnot pomocí pokročilého filtru. Podrobný postup je uveden níže.
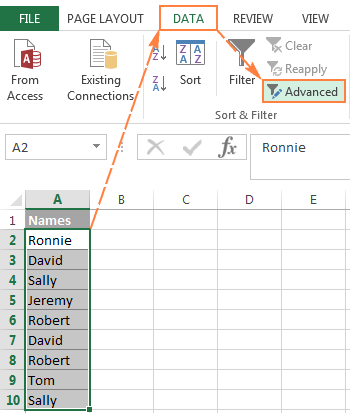
- Vyberte sloupec dat, ze kterého chcete extrahovat odlišné hodnoty.
- Přepněte na Data karta> Třídit a filtrovat a klikněte na Pokročilé tlačítko:
- Podívejte se na stránky . Kopírování do jiného umístění přepínač.
- V Rozsah seznamu zkontrolujte, zda je rozsah zdroje zobrazen správně.
- V Kopírovat do rámečku , zadejte nejvyšší buňku cílového rozsahu. Mějte na paměti, že filtrovaná data můžete zkopírovat pouze do buňky. aktivní list .
- Vyberte Pouze jedinečné záznamy
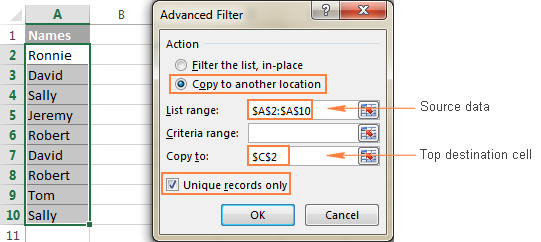
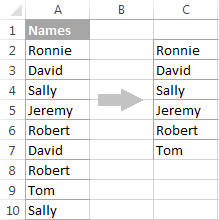
Věnujte prosím pozornost tomu, že ačkoli je možnost rozšířeného filtru pojmenována " Pouze jedinečné záznamy ", extrahuje odlišné hodnoty , tj. jedinečné hodnoty a 1. výskyt duplicitních hodnot.
Extrahujte jedinečné a odlišné řádky pomocí nástroje Duplicate Remover
V závěrečné části tohoto návodu vám ukážu naše vlastní řešení pro vyhledávání a získávání odlišných a jedinečných hodnot v listech aplikace Excel. Toto řešení kombinuje všestrannost vzorců aplikace Excel a jednoduchost pokročilého filtru. Kromě toho poskytuje několik jedinečných funkcí, jako např:
- Vyhledání a extrakce jedinečné / odlišné řádky na základě hodnot v jednom nebo více sloupcích.
- Najít , zvýraznění a kopírovat jedinečné hodnoty do jakéhokoli jiného umístění ve stejném nebo jiném sešitě.
A nyní se podívejme na nástroj Duplicate Remover v akci.
Předpokládejme, že máte souhrnnou tabulku vytvořenou konsolidací dat z několika jiných tabulek. Je zřejmé, že tato souhrnná tabulka obsahuje mnoho duplicitních řádků a vaším úkolem je extrahovat jedinečné řádky, které se v tabulce vyskytují pouze jednou, nebo odlišné řádky včetně jedinečných a 1. duplicitních výskytů. Tak či onak, s doplňkem Duplicate Remover je práce hotová v 5 rychlých krocích.
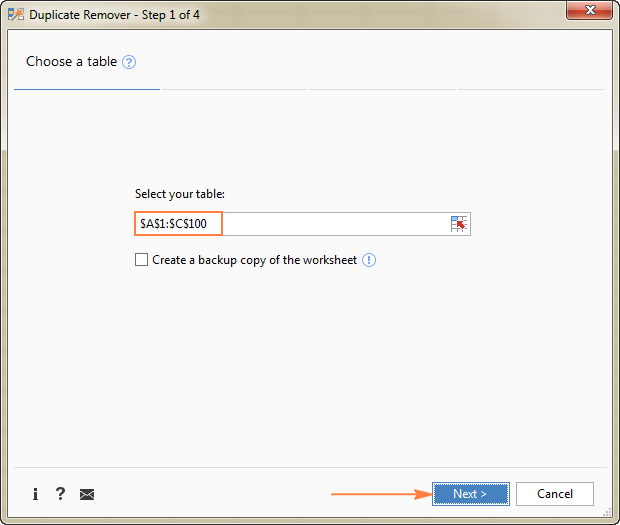
- Vyberte libovolnou buňku ve zdrojové tabulce a klikněte na tlačítko Odstraňovač duplikátů tlačítko na Data Ablebits na kartě Dedupe skupina.

Spustí se průvodce Odstranění duplicit a vybere celou tabulku. Stačí tedy kliknout na tlačítko. Další a přejdete k dalšímu kroku.
- Unikátní
- Unikátní +1. výskyt (odlišný)
V tomto příkladu se snažíme extrahovat jedinečné řádky které se ve zdrojové tabulce objevují pouze jednou, takže vybereme Unikátní možnost:
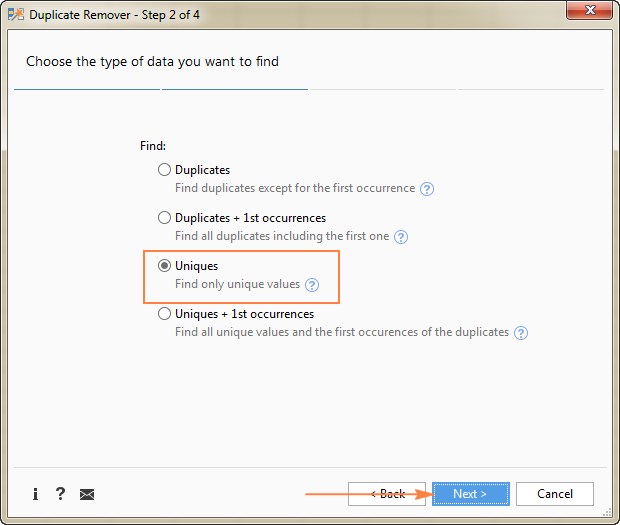
Tip. Jak vidíte na výše uvedeném snímku obrazovky, existují také 2 možnosti pro. duplicitní hodnoty , mějte ji na paměti, pokud budete potřebovat odčítat nějaký jiný pracovní list.
V tomto příkladu chceme najít jedinečné řádky na základě hodnot ve všech 3 sloupcích ( Objednací číslo , Křestní jméno a Příjmení ), proto vybereme všechny.
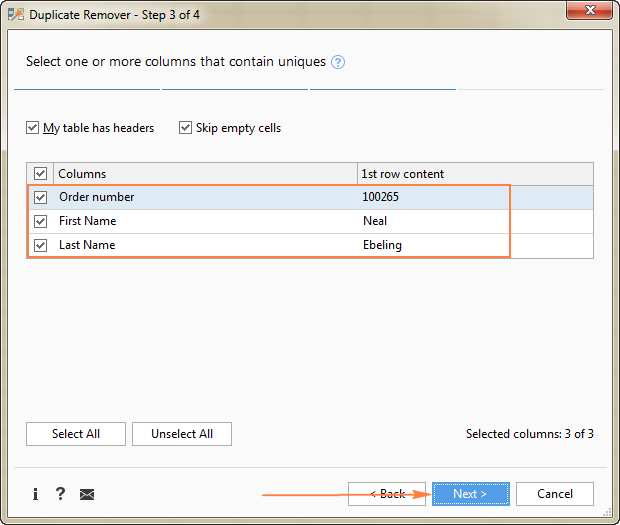
- Zvýraznění jedinečných hodnot
- Výběr jedinečných hodnot
- Identifikace ve stavovém sloupci
- Kopírování do jiného umístění
Protože extrahujeme jedinečné řádky, vyberte Kopírování do jiného umístění a poté určete, kam přesně je chcete zkopírovat - aktivní list (vyberte možnost Vlastní umístění a zadejte horní buňku cílového rozsahu), nový list nebo nový sešit.
V tomto příkladu zvolíme nový list:
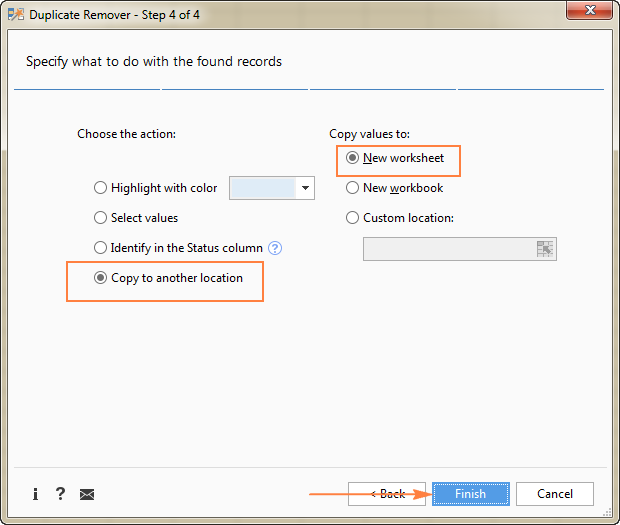
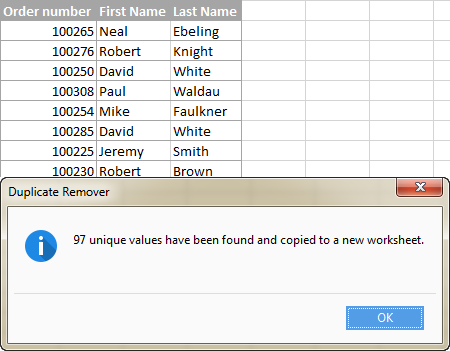
Líbil se vám tento rychlý a jednoduchý způsob, jak získat seznam jedinečných hodnot nebo řádků v aplikaci Excel? Pokud ano, doporučuji vám stáhnout si níže uvedenou zkušební verzi a vyzkoušet ji. Nástroj Duplicate Remover, stejně jako všechny ostatní nástroje pro úsporu času, které máme, jsou součástí sady Ultimate Suite for Excel.
Dostupné soubory ke stažení
Hledání jedinečných hodnot v aplikaci Excel - ukázkový sešit (.xlsx soubor)
Ultimate Suite - zkušební verze (.exe soubor)
