
Სარჩევი
ეს არის Excel-ის უნიკალური მნიშვნელობების სერიის ბოლო ნაწილი, რომელიც გვიჩვენებს, თუ როგორ უნდა მიიღოთ მკაფიო / უნიკალური მნიშვნელობების სია სვეტში ფორმულის გამოყენებით და როგორ შეცვალოთ ეს ფორმულა სხვადასხვა მონაცემთა ნაკრებისთვის. თქვენ ასევე შეიტყობთ, თუ როგორ სწრაფად მიიღოთ მკაფიო სია Excel-ის გაფართოებული ფილტრის გამოყენებით და როგორ ამოიღოთ უნიკალური რიგები Duplicate Remover-ით.
რამდენიმე ბოლო სტატიაში განვიხილეთ სხვადასხვა მეთოდები დათვლასა და პოვნაში. უნიკალური მნიშვნელობები Excel-ში. თუ გქონდათ ამ გაკვეთილების წაკითხვის შესაძლებლობა, თქვენ უკვე იცით, როგორ მიიღოთ უნიკალური ან განსხვავებული სია იდენტიფიკაციის, გაფილტვრისა და კოპირების გზით. მაგრამ ეს ცოტა გრძელი და არა ერთადერთი გზაა Excel-ში უნიკალური მნიშვნელობების ამოსაღებად. ამის გაკეთება შეგიძლიათ ბევრად უფრო სწრაფად სპეციალური ფორმულის გამოყენებით და ცოტა ხანში გაჩვენებთ ამ და კიდევ რამდენიმე ტექნიკას.
რჩევა. იმისათვის, რომ სწრაფად მიიღოთ უნიკალური მნიშვნელობები Excel 365-ის უახლეს ვერსიაში, რომელიც მხარს უჭერს დინამიურ მასივებს, გამოიყენეთ UNIQUE ფუნქცია, როგორც ეს აღწერილია ზემოთ დაკავშირებულ სახელმძღვანელოში.
როგორ მივიღოთ უნიკალური მნიშვნელობები Excel-ში
დაბნეულობის თავიდან ასაცილებლად, პირველ რიგში, მოდით შევთანხმდეთ იმაზე, რასაც ჩვენ ვუწოდებთ უნიკალურ მნიშვნელობებს Excel-ში. უნიკალური მნიშვნელობები არის მნიშვნელობები, რომლებიც არსებობს სიაში მხოლოდ ერთხელ. მაგალითად:
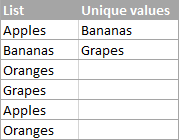
ექსელში უნიკალური მნიშვნელობების სიის ამოსაღებად გამოიყენეთ შემდეგი ფორმულებიდან ერთ-ერთი.
Array უნიკალური მნიშვნელობები ფორმულა (სრულდება Ctrl + Shift + Enter დაჭერითამოიღეთ უნიკალური რიგები, აირჩიეთ კოპირება სხვა ადგილას და შემდეგ მიუთითეთ, სად გსურთ მათი კოპირება - აქტიური ფურცელი (აირჩიეთ მორგებული მდებარეობა ვარიანტი და მიუთითეთ დანიშნულების ზედა უჯრედი დიაპაზონი), ახალი სამუშაო ფურცელი ან ახალი სამუშაო წიგნი.
ამ მაგალითში, მოდით ავირჩიოთ ახალი ფურცელი:
მოგეწონათ Excel-ში უნიკალური მნიშვნელობების ან სტრიქონების სიის მისაღებად ეს სწრაფი და მარტივი გზა? თუ ასეა, გირჩევთ ჩამოტვირთოთ შეფასების ვერსია ქვემოთ და სცადოთ. Duplicate Remover, ისევე როგორც ყველა სხვა დროის დაზოგვის ხელსაწყოები, რომლებიც გვაქვს, შედის Ultimate Suite-ში Excel-ისთვის.
ხელმისაწვდომი ჩამოტვირთვები
იპოვეთ უნიკალური მნიშვნელობები Excel-ში - სამუშაო წიგნის ნიმუში (ფაილი .xlsx)
Ultimate Suite - შეფასების ვერსია (ფაილი .exe)
): =IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1,$A$2:$A$10) + (COUNTIF($A$2:$A$10, $A$2:$A$10)1), 0)), "")
რეგულარული უნიკალური მნიშვნელობების ფორმულა (სრულდება Enter დაჭერით):
=IFERROR(INDEX($A$2:$A$10, MATCH(0,INDEX(COUNTIF($B$1:B1, $A$2:$A$10)+(COUNTIF($A$2:$A$10, $A$2:$A$10)1),0,0), 0)), "")
ზემოთ ფორმულებში, გამოიყენება შემდეგი მითითებები:
- A2:A10 - წყაროს სია.
- B1 - უნიკალური სიის ზედა უჯრედი მინუს 1. ამ მაგალითში ვიწყებთ უნიკალურ სიას. B2-ში და, შესაბამისად, ვაწვდით B1 ფორმულას (B2-1=B1). თუ თქვენი უნიკალური სია იწყება, ვთქვათ, C3 უჯრედში, მაშინ შეცვალეთ $B$1:B1 $C$2:C2-ით.
შენიშვნა. იმის გამო, რომ ფორმულა მიუთითებს უჯრედს უნიკალური სიის პირველი უჯრედის ზემოთ, რომელიც ჩვეულებრივ არის სვეტის სათაური (ამ მაგალითში B1), დარწმუნდით, რომ თქვენს სათაურს აქვს უნიკალური სახელი, რომელიც არ ჩანს სვეტში სხვაგან.
ამ მაგალითში, ჩვენ ვიღებთ უნიკალურ სახელებს A სვეტიდან (უფრო ზუსტად A2:A20 დიაპაზონიდან) და შემდეგი ეკრანის სურათი აჩვენებს მასივის ფორმულას მოქმედებაში:
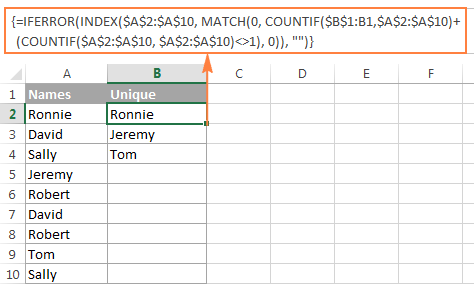
ფორმულის ლოგიკის დეტალური ახსნა მოცემულია ცალკე განყოფილებაში და აი, როგორ გამოვიყენოთ ფორმულა Excel-ის სამუშაო ფურცლებში უნიკალური მნიშვნელობების ამოსაღებად:
- შეასწორეთ ერთ-ერთი ფორმულა თქვენი მონაცემთა ნაკრების მიხედვით.
- შეიყვანეთ ფორმულა უნიკალური სიის პირველ უჯრედში (ამ მაგალითში B2).
- თუ მასივის ფორმულას იყენებთ, დააჭირეთ Ctrl + Shift + Enter . თუ თქვენ აირჩიეთ ჩვეულებრივი ფორმულა, ჩვეულებისამებრ, დააჭირეთ Enter კლავიშს.
- დააკოპირეთ ფორმულა იმდენად, რამდენადაც საჭიროა, შევსების სახელურის გადმოწევით. ვინაიდან ორივეუნიკალური მნიშვნელობების ფორმულები არის ჩასმული IFERROR ფუნქციაში, შეგიძლიათ დააკოპიროთ ფორმულა თქვენი ცხრილის ბოლომდე და ის არ გადაიტვირთებს თქვენს მონაცემებს შეცდომით, მიუხედავად იმისა, თუ რამდენი უნიკალური მნიშვნელობები იქნა ამოღებული.
როგორ მივიღოთ განსხვავებული მნიშვნელობები Excel-ში (უნიკალური + 1-ლი დუბლიკატი)
როგორც თქვენ უკვე მიხვდით ამ განყოფილების სათაურიდან, განსხვავებული მნიშვნელობები Excel-ში ყველა განსხვავებულია მნიშვნელობები სიაში, ანუ უნიკალური მნიშვნელობები და დუბლიკატი მნიშვნელობების პირველი შემთხვევები. მაგალითად:
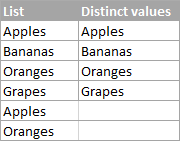
Excel-ში განსხვავებული სიის მისაღებად გამოიყენეთ შემდეგი ფორმულები.
Array განსხვავებული ფორმულა (საჭიროებს Ctrl-ის დაჭერას + Shift + Enter ):
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10), 0)), "")
რეგულარული განსხვავებული ფორმულა:
=IFERROR(INDEX($A$2:$A$10, MATCH(0, INDEX(COUNTIF($B$1:B1, $A$2:$A$10), 0, 0), 0)), "")
სად:
- A2:A10 არის წყაროს სია.
- B1 არის უჯრედი განსხვავებული სიის პირველი უჯრედის ზემოთ. ამ მაგალითში, განსხვავებული სია იწყება უჯრედში B2 (ეს არის პირველი უჯრედი, სადაც შეიყვანთ ფორმულას), ასე რომ თქვენ მიუთითებთ B1-ში.
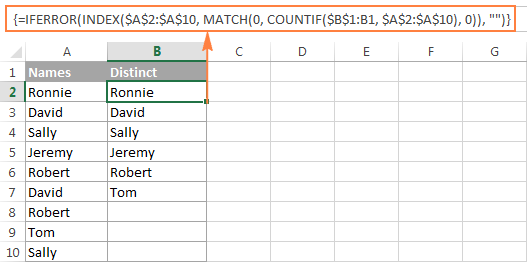
სხვადასხვა მნიშვნელობების ამოღება სვეტი, რომელიც იგნორირებას უკეთებს ცარიელ უჯრედებს
თუ თქვენი წყაროს სია შეიცავს ცარიელ უჯრედებს, ჩვენ მიერ განხილული განსხვავებული ფორმულა დააბრუნებს ნულს თითოეული ცარიელი მწკრივისთვის, რაც შეიძლება იყოს პრობლემა. ამის გამოსასწორებლად, ცოტათი გააუმჯობესეთ ფორმულა:
მასივის ფორმულა ამოსაღებად განსხვავებული მნიშვნელობების გამოკლებით :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF($A$2:$A$10="",1,0), 0)), "")
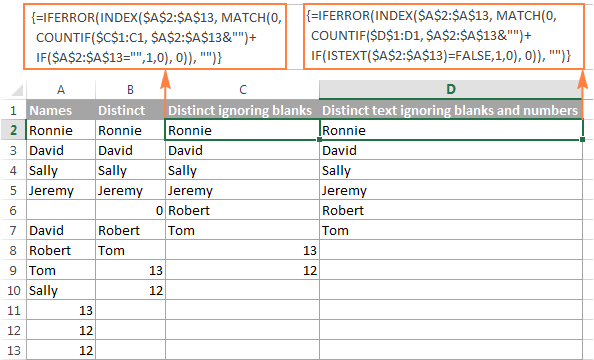
მიიღეთ განსხვავებული სიის ტექსტის მნიშვნელობები რიცხვების იგნორირება დაბლანკები
მსგავსი წესით, შეგიძლიათ მიიღოთ განსხვავებული მნიშვნელობების სია ცარიელი უჯრედების და ნომრების გამოკლებით :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF(ISTEXT($A$2:$A$10)=FALSE,1,0), 0)), "")
სწრაფად შეგახსენებთ, ზემოთ მოცემულ ფორმულებში A2:A10 არის წყაროს სია, ხოლო B1 არის უჯრედი მკაფიო სიის პირველი უჯრედის ზემოთ.
შემდეგი სკრინშოტი აჩვენებს ორივე ფორმულის შედეგს:
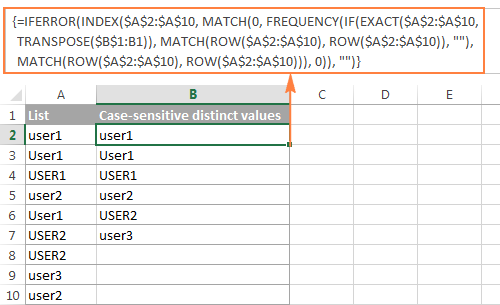
როგორ ამოიღოთ რეგისტრისადმი მგრძნობიარე განსხვავებული მნიშვნელობები Excel-ში
როდესაც მუშაობთ რეგისტრის მგრძნობიარე მონაცემებთან, როგორიცაა პაროლები, მომხმარებლის სახელები ან ფაილების სახელები, შეიძლება დაგჭირდეთ სიის მიღება ქეისისადმი მგრძნობიარე განსხვავებული მნიშვნელობები. ამისათვის გამოიყენეთ მასივის შემდეგი ფორმულა, სადაც A2:A10 არის წყაროს სია, ხოლო B1 არის უჯრედი მკაფიო სიის პირველი უჯრედის ზემოთ:
მასივის ფორმულა, რომ მიიღოთ რეგისტრირებული განსხვავებული მნიშვნელობები (მოითხოვს დაჭერას Ctrl + Shift + Enter )
=IFERROR(INDEX($A$2:$A$10, MATCH(0, FREQUENCY(IF(EXACT($A$2:$A$10,TRANSPOSE($B$1:B1)), MATCH(ROW($A$2:$A$10), ROW($A$2:$A$10)), ""), MATCH(ROW($A$2:$A$10), ROW($A$2:$A$10))), 0)), "")
როგორ მუშაობს უნიკალური / განსხვავებული ფორმულა
ეს განყოფილება დაწერილია სპეციალურად მათთვის, ვინც დაინტერესებულია და Excel-ის მოაზროვნე მომხმარებლები, რომლებსაც არა მხოლოდ უნდათ იცოდნენ ფორმულა, არამედ სრულად ესმით მისი ფრაგმენტები.
რა თქმა უნდა, ფორმულები Excel-ში უნიკალური და განსხვავებული მნიშვნელობების ამოსაღებად არც ტრივიალურია და არც მარტივი. მაგრამ უფრო ახლოს რომ დავაკვირდეთ, შეიძლება შეამჩნიოთ, რომ ყველა ფორმულა ეფუძნება ერთსა და იმავე მიდგომას - INDEX/MATCH-ის გამოყენებით COUNTIF-თან ერთად, ან COUNTIF + IF ფუნქციებს.
ჩვენი სიღრმისეული ანალიზისთვის, მოდით გამოვიყენოთ მასივის ფორმულა რომამოიღებს განსხვავებული მნიშვნელობების ჩამონათვალს, რადგან ამ სახელმძღვანელოში განხილული ყველა სხვა ფორმულა არის ამ ძირითადის გაუმჯობესებები ან ვარიაციები:
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10), 0)), "")
დაწყებისთვის, მოდით გადავიტანოთ მოშორება აშკარა IFERROR ფუნქცია, რომელიც გამოიყენება ერთი მიზნით #N/A შეცდომების აღმოსაფხვრელად, როდესაც უჯრედების რაოდენობა, სადაც დააკოპირეთ ფორმულა, აღემატება წყაროს სიაში განსხვავებული მნიშვნელობების რაოდენობას.
და ახლა, მოდით დავშალოთ ჩვენი განსხვავებული ფორმულის ძირითადი ნაწილი:
- COUNTIF(დიაპაზონი, კრიტერიუმები) აბრუნებს დიაპაზონის უჯრედების რაოდენობას, რომლებიც აკმაყოფილებენ მითითებულ პირობას.
ამ მაგალითში, COUNTIF($B$1:B1, $A$2:$A$10) აბრუნებს 1-ისა და 0-ის მასივს იმის მიხედვით, არის თუ არა წყაროს სიის რომელიმე მნიშვნელობა ($A$2:$A$10) გამოჩნდება სადღაც მკაფიო სიაში ($B$1:B1). თუ მნიშვნელობა იქნა ნაპოვნი, ფორმულა აბრუნებს 1-ს, წინააღმდეგ შემთხვევაში - 0-ს.
კერძოდ, უჯრედში B2, COUNTIF($B$1:B1, $A$2:$A$10) ხდება:
<. 0>COUNTIF("Distinct", {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"})
და აბრუნებს:
{0;0;0;0;0;0;0;0;0}
რადგან წყაროს სიის არცერთი ელემენტი ( კრიტერიუმი ) არ ჩანს დიაპაზონში სადაც ფუნქცია ეძებს შესატყვისს. ამ შემთხვევაში, დიაპაზონი ($B$1:B1) შედგება ერთი ელემენტისგან - "განსხვავებული".
MATCH(lookup_value, lookup_array, [match_type]) აბრუნებს საძიებელი მნიშვნელობის ფარდობით პოზიციას მასივში.ამ მაგალითში lookup_მნიშვნელობა არის 0 და, შესაბამისად:
<. 0> MATCH(0,COUNTIF($B$1:B1, $A$2:$A$10), 0)იქცევა:
MATCH(0, { 0 ;0;0;0;0;0;0;0;0},0)
და ბრუნდება
რადგან ჩვენი MATCHფუნქცია იღებს პირველ მნიშვნელობას, რომელიც ზუსტად უდრის საძიებო მნიშვნელობას (როგორც გახსოვთ, საძიებო მნიშვნელობა არის 0).
ამ მაგალითში, INDEX($A$2:$A$10, 1)
ხდება:
INDEX({"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}, 1)
და აბრუნებს "Ronnie".
0> როდესაც ფორმულა კოპირდება სვეტში, მკაფიო სია ($B$1:B1) ფართოვდება, რადგან მეორე უჯრედის მითითება (B1) არის შედარებითი მითითება, რომელიც იცვლება იმ უჯრედის ფარდობითი პოზიციის მიხედვით, სადაც ფორმულა მოძრაობს.
ასე რომ, როდესაც კოპირდება უჯრედში B3, COUNTIF($B$1: B1 , $A$2:$A$10) იცვლება COUNTIF($B$1: B2 , $A$2:$A$10), და ხდება:
COUNTIF({"Distinct";"Ronnie"}, {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}), 0)), "")
და აბრუნებს:
{1;0;0;0;0;0;0;0;0}
რადგან ერთი "Ronnie" არის ნაპოვნი დიაპაზონი $B$1:B2.
და შემდეგ, MATCH(0,{1; 0 ;0;0;0;0;0;0;0},0) აბრუნებს 2-ს , რადგან 2 არის პირველი 0-ის ფარდობითი პოზიცია მასივში.
და ბოლოს, INDEX($A$2:$A$10, 2) აბრუნებს მნიშვნელობას მე-2 მწკრივიდან, რომელიც არის "David".
რჩევა. ფორმულის ლოგიკის უკეთ გასაგებად, შეგიძლიათ აირჩიოთ ფორმულის სხვადასხვა ნაწილი ფორმულების ზოლში და დააჭიროთ F9, რათა ნახოთ, რას აფასებს არჩეული ნაწილი:
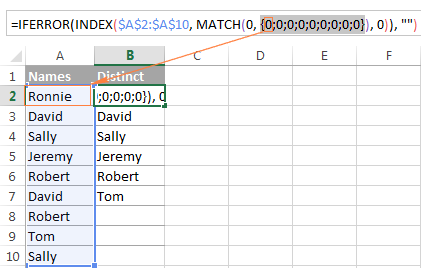
თუ ჯერ კიდევ გაქვთ სირთულეების გამოთვლა ფორმულიდან შეგიძლიათ გაეცნოთ შემდეგ ინსტრუქციას დეტალური ახსნისთვის, თუ როგორ მუშაობს INDEX/MATCH კავშირი: INDEX & amp; მატჩი, როგორც უკეთესიExcel VLOOKUP-ის ალტერნატივა.
როგორც უკვე აღვნიშნეთ, ამ სახელმძღვანელოში განხილული სხვა ფორმულები ეფუძნება იმავე ლოგიკას, მხოლოდ რამდენიმე მოდიფიკაციით:
უნიკალური მნიშვნელობების ფორმულა - შეიცავს კიდევ ერთ COUNTIF ფუნქციას რომელიც გამორიცხავს უნიკალური სიიდან ყველა ელემენტს, რომელიც გამოჩნდება წყაროს სიაში არაერთხელ: COUNTIF($A$2:$A$10, $A$2:$A$10)1 .
განსხვავებული მნიშვნელობების ფორმულა, რომელიც იგნორირებას უკეთებს ბლანკებს - აქ თქვენ ამატებთ IF ფუნქციას, რომელიც ხელს უშლის ცარიელი უჯრედების დამატებას ცალკეულ სიაში: IF($A$2:$A$13="",1,0) .
განსხვავებული ტექსტის მნიშვნელობების ფორმულა, რომელიც იგნორირებას უკეთებს რიცხვებს - იყენებთ ISTEXT ფუნქციას, რათა შეამოწმოთ არის თუ არა მნიშვნელობა ტექსტი, და IF ფუნქციას ყველა სხვა მნიშვნელობის ტიპების გასაუქმებლად, ცარიელი უჯრედების ჩათვლით: IF(ISTEXT($A$2:$A$13)=FALSE,1,0) .
ამოიღეთ მკაფიო მნიშვნელობები სვეტიდან Excel-ის გაფართოებული ფილტრით
თუ არ გსურთ დაკარგოთ დრო განსხვავებული მნიშვნელობების ფორმულების საიდუმლო გადახვევების გარკვევაზე, შეგიძლიათ სწრაფად მიიღოთ განსხვავებული მნიშვნელობების სია, გამოყენებით გაფართოებული ფილტრი. დეტალური ნაბიჯები მიჰყვება ქვემოთ.
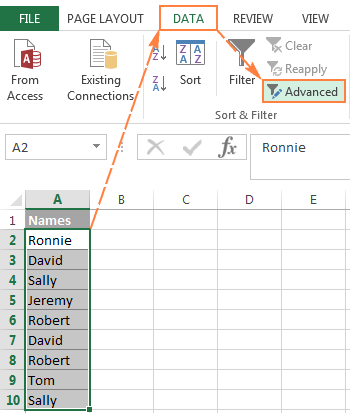
- აირჩიეთ მონაცემთა სვეტი, საიდანაც გსურთ განსხვავებული მნიშვნელობების ამოღება.
- გადართეთ მონაცემები ჩანართზე > დახარისხება & amp; გაფილტრეთ ჯგუფი და დააწკაპუნეთ ღილაკზე Advanced :
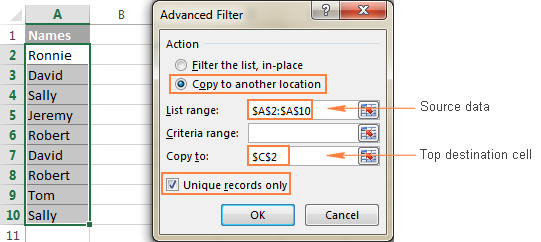
- შეამოწმეთ რადიო ღილაკი კოპირება სხვა ადგილას .
- სიის დიაპაზონი ველში, დარწმუნდით, რომ წყაროს დიაპაზონი სწორად არის ნაჩვენები .
- ში დააკოპირეთ უჯრაში , შეიყვანეთ დანიშნულების დიაპაზონის ზედა უჯრედი. გთხოვთ გაითვალისწინოთ, რომ გაფილტრული მონაცემების კოპირება შეგიძლიათ მხოლოდ აქტიურ ფურცელზე .
- აირჩიეთ მხოლოდ უნიკალური ჩანაწერები
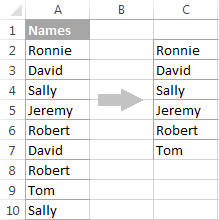
გთხოვთ, მიაქციოთ ყურადღება, რომ მიუხედავად იმისა, რომ გაფართოებული ფილტრის ოფციას ჰქვია „ მხოლოდ უნიკალური ჩანაწერები “, ის ამოიღებს განსხვავებულ მნიშვნელობებს , ანუ უნიკალურ მნიშვნელობებს და დუბლიკატი მნიშვნელობების პირველ შემთხვევებს.
ამოიღეთ უნიკალური და განსხვავებული რიგები Duplicate-ით. Remover
ამ გაკვეთილის ბოლო ნაწილში, ნება მომეცით გაჩვენოთ ჩვენი საკუთარი გადაწყვეტა Excel-ის ფურცლებში განსხვავებული და უნიკალური მნიშვნელობების მოსაძებნად და ამოსაღებად. ეს გამოსავალი აერთიანებს Excel-ის ფორმულების მრავალფეროვნებას და მოწინავე ფილტრის სიმარტივეს. გარდა ამისა, ის უზრუნველყოფს რამდენიმე უნიკალურ ფუნქციას, როგორიცაა:
- იპოვეთ და ამოიღეთ უნიკალური / განსხვავებული რიგები ერთი ან მეტი სვეტის მნიშვნელობებზე დაყრდნობით.
- იპოვეთ , მონიშნეთ და დააკოპირეთ უნიკალური მნიშვნელობები ნებისმიერ სხვა ადგილას, იმავე ან სხვა სამუშაო წიგნში.
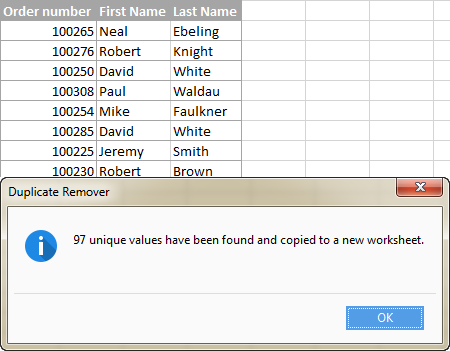
და ახლა, ვნახოთ Duplicate Remover ინსტრუმენტი მოქმედებაში.
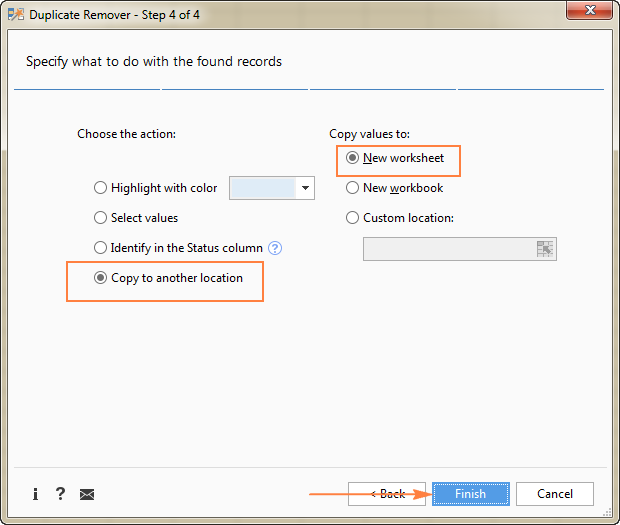
ვვარაუდობთ, რომ თქვენ გაქვთ შემაჯამებელი ცხრილი შექმნილი რამდენიმე სხვა ცხრილის მონაცემების კონსოლიდაციით. ცხადია, რომ შემაჯამებელი ცხრილი შეიცავს უამრავ დუბლიკატ რიგს და თქვენი ამოცანაა ამოიღოთ უნიკალური რიგები, რომლებიც ცხრილში მხოლოდ ერთხელ გამოჩნდება, ან ცალკეული რიგები.უნიკალური და პირველი დუბლიკატი შემთხვევების ჩათვლით. ნებისმიერ შემთხვევაში, Duplicate Remover დანამატით, სამუშაო კეთდება 5 სწრაფი ნაბიჯით.
- აირჩიეთ ნებისმიერი უჯრედი თქვენს წყაროს ცხრილში და დააწკაპუნეთ Duplicate Remover ღილაკზე 1>Ablebits Data ჩანართი, Dedupe ჯგუფში.

Duplicate Remover ოსტატი იმუშავებს და შეარჩევს მთელი მაგიდა. ასე რომ, უბრალოდ დააწკაპუნეთ შემდეგი , რომ გადახვიდეთ შემდეგ ეტაპზე.
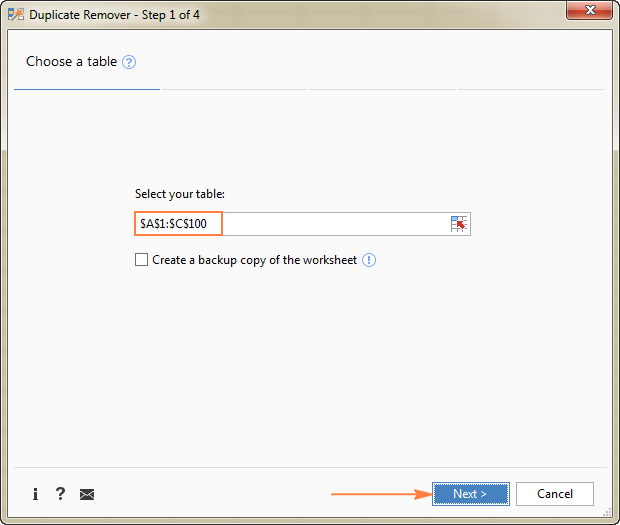
- უნიკალური
- უნიკალური +1-ის შემთხვევები (განსხვავებული)
ამ მაგალითში, ჩვენ მიზნად ისახავს გამოვყოთ უნიკალური რიგები , რომლებიც გამოჩნდება წყაროს ცხრილში მხოლოდ ერთხელ, ამიტომ ვირჩევთ უნიკალურ ვარიანტს:
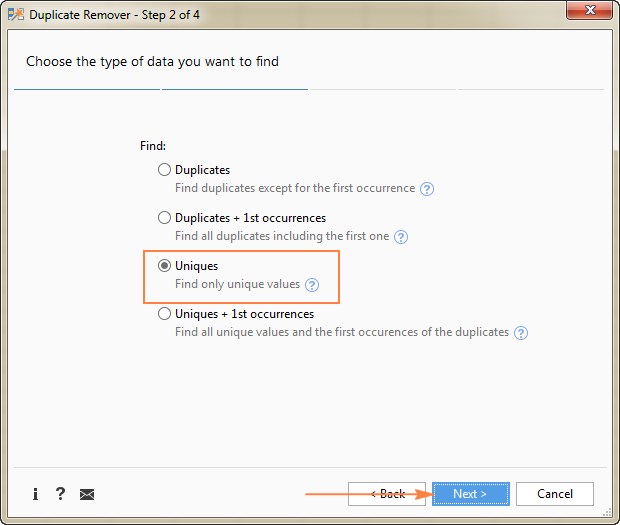
რჩევა. როგორც ზემოთ სკრინშოტში ხედავთ, ასევე არის 2 ვარიანტი დუბლიკატი მნიშვნელობებისთვის , უბრალოდ გაითვალისწინეთ, თუ სხვა სამუშაო ფურცლის წაშლა გჭირდებათ.
ამ მაგალითში ჩვენ გვინდა ვიპოვოთ უნიკალური რიგები მნიშვნელობებზე დაფუძნებული სამივე სვეტში ( შეკვეთის ნომერი , სახელი და გვარი ), შესაბამისად ჩვენ ვირჩევთ ყველა.
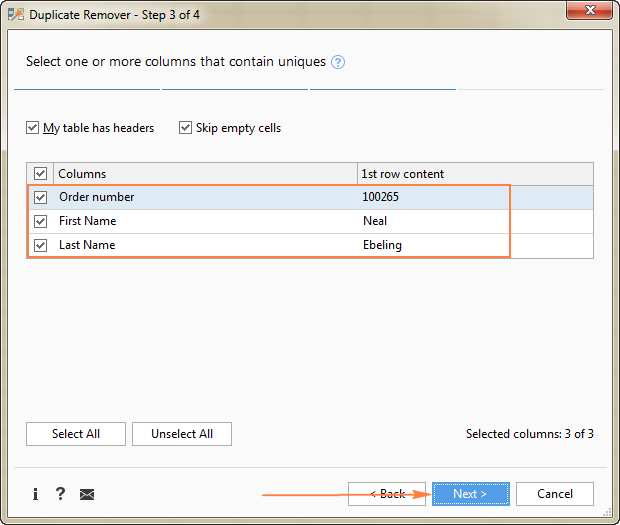
- მონიშნეთ უნიკალური მნიშვნელობები
- აირჩიეთ უნიკალური მნიშვნელობები
- სტატუსის სვეტში იდენტიფიცირება
- კოპირება სხვა მდებარეობაზე
იმიტომ, რომ ჩვენ ვართ
