
目次
これは、Excelの固有値シリーズの最終パートで、数式を使用して列の固有値/ユニーク値のリストを取得する方法と、異なるデータセット用に数式を調整する方法を示します。 また、Excelの高度なフィルタを使用して迅速に固有値を取得する方法、およびDuplicate Removerで固有行を抽出する方法を学びます。
最近の記事で、Excelでユニークな値を数え、見つけるためのさまざまな方法について説明しました。 これらのチュートリアルを読む機会があれば、識別、フィルタリング、コピーによってユニークまたは明確なリストを取得する方法をすでに知っています。 しかし、これは少し長く、はるかにExcelでユニーク値を抽出する唯一の方法ではありません。 特別な式を使用して、より速くそれを行うことができ、一瞬でこのほかにもいくつかのテクニックを紹介します。
ヒント:動的配列に対応した最新版のExcel 365で一意な値を素早く取得するには、上記リンク先のチュートリアルで説明されているようにUNIQUE関数を使用します。
エクセルで一意な値を取得する方法
混乱を避けるために、まず最初に、Excelでユニークな値を何と呼ぶかについて合意しておこう。 ユニークな価値観 は,リスト中に一度だけ存在する値である.
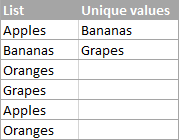
Excelで一意の値のリストを抽出するには、次のいずれかの数式を使用します。
アレイ ユニークバリューの計算式(Ctrl + Shift + Enterキーで完了)
=iferror(index($a$2:$a$10, match(0, countif($b$1:b1,$a$2:$a$10) + (countif($a$2:$a$10, $a$2:$a$10)1)), 0)), """)
レギュラー unique values 式(Enter キーで完了)。
=iferror(index($a$2:$a$10, match(0,index(countif($b$1:b1, $a$2:$a$10)+(countif($a$2:$a$10, $a$2:$a$10)1),0,0), 0)), """)
上記の式において、以下の参考文献を使用する。
- A2:A10 - ソースリストです。
- B1 - ユニークリストの先頭セルから 1 を引いた値。 この例では、ユニークリストを B2 で開始しているので、数式に B1 を指定しています (B2-1=B1) 。 ユニークリストがたとえばセル C3 で始まる場合は、$B$1:B1 を $C$2:C2 に変更します。
注:この数式は、固有リストの最初のセル(通常は列ヘッダー(この例では B1))の上のセルを参照するため、ヘッダーに列の他のどこにも表示されない固有名を付けるようにしてください。
この例では、A列(正確にはA2:A20の範囲)から固有名を抽出しており、以下のスクリーンショットは、配列式が実際に動作している様子を示しています。
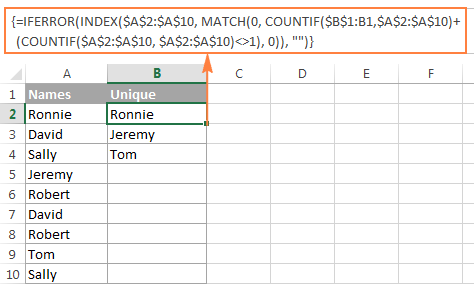
数式のロジックの詳細な説明は別項で行い、ここではExcelのワークシートでユニークな値を抽出するための数式を使用する方法を説明します。
- データセットに応じて、計算式の一つを微調整します。
- ユニークリストの最初のセル(この例ではB2)に数式を入力します。
- 配列式を使う場合は、Ctrl + Shift + Enter キーを押します。 通常の式を選んだ場合は、通常通り Enter キーを押します。
- この数式は、フィルハンドルをドラッグして必要なだけ下にコピーします。 一意な値の数式は両方とも IFERROR 関数でカプセル化されているので、表の最後まで数式をコピーしても、一意な値がどれだけ抽出されていなくても、エラーでデータが散らかることはありません。
Excelでdistinctな値を取得する方法(ユニーク+重複1件目)
この項の見出しから既にお察しの通りです。 明瞭な値 は、リスト内の異なる値、つまりユニークな値と重複する値の最初のインスタンスです。 例えば、次のようなものです。
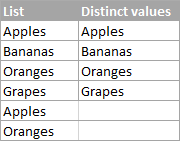
Excelで明確なリストを得るには、以下の数式を使用します。
アレイ のような明確な計算式(Ctrl + Shift + Enter キーが必要)。
=iferror(index($a$2:$a$10, match(0, countif($b$1:b1, $a$2:$a$10), 0)), "")
レギュラー を明確にした式。
=iferror(index($a$2:$a$10, match(0, index(countif($b$1:b1, $a$2:$a$10), 0, 0), 0)), "")
どこで
- A2:A10はソースリストです。
- B1は、個別リストの最初のセルより上のセルです。 この例では、個別リストはセルB2(数式を入力した最初のセルです)から始まるので、B1を参照します。
空白セルを無視して列内の明確な値を抽出する
ソースリストに空白のセルがある場合、先ほど説明したdistinctの式は空の行ごとに0を返すので、問題があるかもしれません。 これを解決するために、式をもう少し改良します。
抽出するための配列式 空白を除く明確な値 :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF($A$2:$A$10="",1,0), 0)), """)
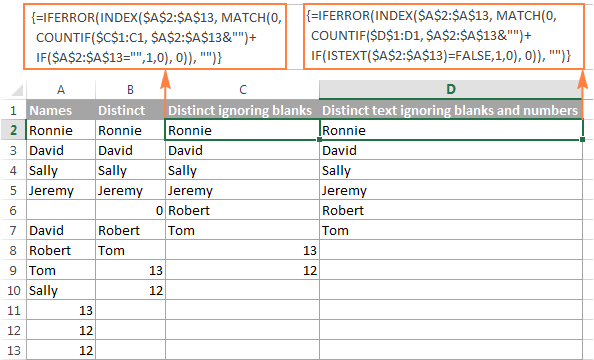
数字や空白を無視した、個別のテキスト値のリストを取得する。
同様の方法で、異なる値のリストを取得することができます。 空のセルと数字のあるセルを除く :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF(ISTEXT($A$2:$A$10)=FALSE,1,0)), 0), "")
簡単なメモとして、上記の数式では、A2:A10 がソースリストで、B1 は異なるリストの最初のセルのすぐ上のセルです。
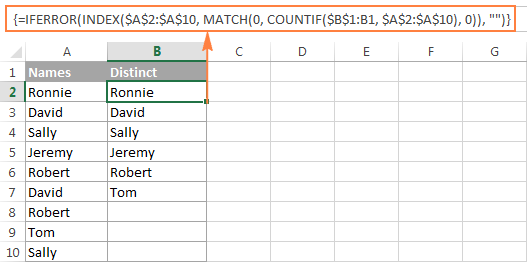
次のスクリーンショットは、両方の計算式の結果を示しています。
Excelで大文字と小文字を区別して値を抽出する方法
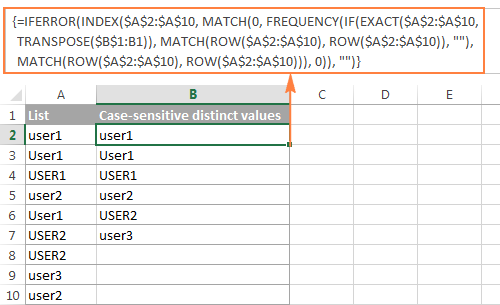
パスワード、ユーザー名、ファイル名など大文字小文字を区別するデータを扱う場合、大文字小文字を区別する値のリストを取得する必要があります。 この場合、次の配列式を使用します。A2:A10 はソースリスト、B1 は区別リストの最初のセルより上のセルです。
大文字と小文字を区別した値を取得するための配列式(Ctrl + Shift + Enter キーが必要です)
=iferror(index($a$2:$a$10, match(0, frequency(if(exact($a$2:$a$10,transpose($b$1:b1)), match(row($a$2:$a$10), row($a$2:$a$10)), ""), match(row($a$2:$a$10), row($a$2:$a$10))), 0"))
ユニーク/ディスティンクティブ・フォーミュラのしくみ
このセクションは、数式を知るだけでなく、そのコツを完全に理解したい、好奇心旺盛で思慮深いExcelユーザーのために特に書かれています。
Excelで一意な値や異なる値を抽出する数式は、言うまでもなく簡単ではありません。 しかし、よく見ると、すべての数式は、INDEX/MATCHとCOUNTIF、またはCOUNTIF + IF関数を組み合わせて使用するという、同じアプローチに基づいていることに気づくかもしれません。
このチュートリアルで説明する他のすべての式は、この基本的な式を改良または変形したものなので、詳細な分析には、異なる値のリストを抽出する配列式を使用しましょう。
=iferror(index($a$2:$a$10, match(0, countif($b$1:b1, $a$2:$a$10), 0)), "")
IFERROR関数は、数式をコピーしたセルの数がソースリストの異なる値の数を超えたときに#N/Aエラーを排除するために使用されるものです。
そして、次に、私たちの明確な公式の核となる部分を分解してみましょう。
- COUNTIF(range, criteria) 較正関数は、指定された条件を満たす、範囲内のセルの数を返します。
この例では、COUNTIF($B$1:B1, $A$2:$A$10) は、ソースリスト ($A$2:$A$10) の値のいずれかが区別リスト ($B$1:B1) のどこかにあるかどうかに基づいて 1 と 0 の配列を返します。 値が見つかった場合、式は 1、それ以外の場合は - 0 を返します。
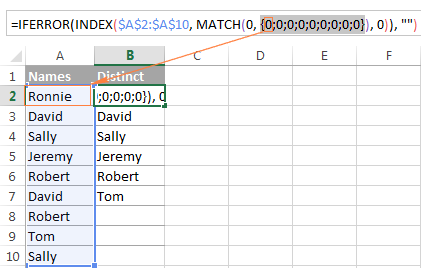
特にセルB2では、COUNTIF($B$1:B1, $A$2:$A$10)となる。
COUNTIF("Distinct", {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally" }.)と返します。
{0;0;0;0;0;0;0;0;0}というのも、ソースリストのどの項目も( クライテリア )が表示されます。 レンジ この場合,関数は一致するものを探します. レンジ ($B$1:B1)は、"Distinct "という1つの項目で構成されています。
MATCH(lookup_value、lookup_array、[match_type])は、配列中のルックアップ値の相対位置を返します。
この例では、lookup_valueは0であり、その結果。
match(0,countif($b$1:b1, $a$2:$a$10), 0)
に変わります。
MATCH(0, {) 0 ;0;0;0;0;0;0;0;0},0)
を返します。
なぜなら、MATCH関数は、ルックアップ値と正確に等しい最初の値を取得するからです(覚えているように、ルックアップ値は0です)。
この例では、INDEX($A$2:$A$10, 1)となります。
になります。
INDEX({"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}, 1)
と入力し、"Ronnie "と返す。
数式が列の下にコピーされると、2 番目のセル参照 (B1) が数式が移動するセルの相対位置に応じて変化する相対参照であるため、区別リスト ($B$1:B1) が拡張されるのです。
そこで、セルB3にコピーされると、COUNTIF($B$1: B1 , $A$2:$A$10) が、COUNTIF($B$1.) に変更されました。 B2 , $A$2:$A$10)となる。
COUNTIF({"Distinct"; "Ronnie"}, {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}), 0)), """).
と返します。
{1;0;0;0;0;0;0;0;0}
なぜなら、範囲 $B$1:B2 に "Ronnie" が1つ見つかったからです。
そして、MATCH(0,{1; 0 ;0;0;0;0;0;0},0) が2を返すのは、2が配列中の最初の0の相対位置だからです。
そして最後に。 index($a$2:$a$10, 2) は2行目の値、つまり "David "を返します。
ヒント:数式のロジックをよりよく理解するために、数式バーで数式のさまざまな部分を選択し、F9キーを押すと、選択した部分がどのように評価されるかを確認することができます。
もし、まだ計算式がわからない場合は、次のチュートリアルでINDEX/MATCHの連携について詳しく説明しています:INDEX & MATCH as a better alternative to Excel VLOOKUP.
すでに述べたように、このチュートリアルで説明する他の数式も同じロジックに基づいており、ほんの少し修正を加えています。
ユニークバリュー式 - ソースリストに2回以上表示されるすべての項目をユニークリストから除外するCOUNTIF関数がもう1つ含まれています。 countif($a$2:$a$10, $a$2:$a$10)1 .
空白を無視する識別値の式 - ここでは、空白のセルが識別リストに追加されないようにするIF関数を追加します。 IF($A$2:$A$13="",1,0) .
数値を無視したテキスト値の判別式 - 値がテキストかどうかをチェックするにはISTEXT関数を、空白セルを含む他のすべての値の種類を却下するにはIF関数を使用します。 if(istext($a$2:$a$13)=false,1,0)とする。 .
Excelの高度なフィルタで列から明確な値を抽出する
もし、明瞭な値の公式の難解さを理解するのに時間を費やしたくないなら、高度なフィルターを使うことで明瞭な値のリストを素早く得ることができます。 詳しい手順は以下の通りです。
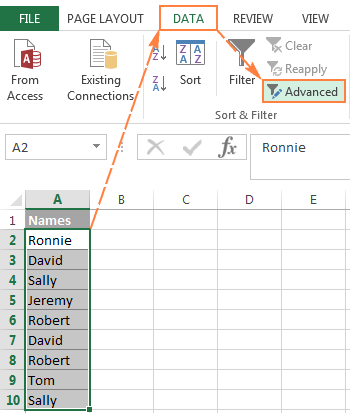
- 異なる値を抽出したいデータの列を選択します。
- に切り替えてください。 データ tab> ソート&フィルター をクリックします。 アドバンスト ボタンをクリックします。
- チェック 別の場所にコピーする ラジオボタン
- での リスト範囲 ボックスで、ソース範囲が正しく表示されることを確認します。
- での ボックスへのコピー にのみコピーできることに注意してください。 アクティブシート .
- を選択します。 一意なレコードのみ
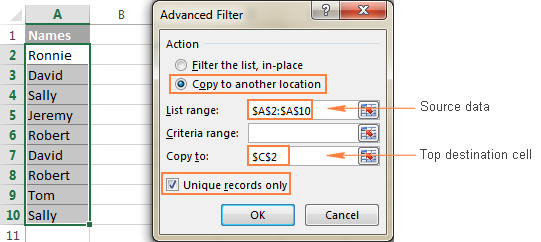
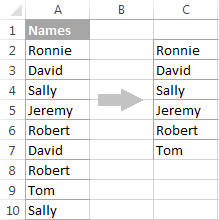
アドバンストフィルターのオプションの名前は""です。 一意なレコードのみ 「を抽出します。 明瞭な値 つまり、一意な値と重複する値の1回目の出現です。
Duplicate Removerでユニークで明確な行を抽出します。
このチュートリアルの最後の部分では、Excelシートで明確でユニークな値を検索して抽出するための独自のソリューションを紹介しましょう。 このソリューションは、Excel数式の多用途性と高度なフィルタの簡便性を組み合わせたものです。 さらに、次のようないくつかの独自の機能も備えています。
- 検索と抽出 一義的/明確な行 は、1つ以上の列の値に基づいています。
- 探す , ハイライト そして コピー 一意な値を、同じワークブック内または異なるワークブック内の他の場所に移動することができます。
それでは、Duplicate Removerツールの動作をご覧ください。
他のテーブルのデータを統合して作成されたサマリーテーブルがあるとします。 そのサマリーテーブルには、明らかに多くの重複した行が含まれており、あなたのタスクは、テーブルに一度だけ現れるユニークな行、またはユニークと最初の重複を含む個別の行を抽出することです。 いずれにせよ、Duplicate Removerアドインを使えば、5ステップで作業を完了することが可能です。
- ソーステーブル内の任意のセルを選択し、そのセルをクリックします。 デュプリケートリムーバー ボタンをクリックします。 エイブルビットのデータ タブで デデュープ のグループです。

Duplicate Removerウィザードが実行され、テーブル全体が選択されます。 そこで、そのまま 次のページ をクリックして、次のステップに進みます。
- ユニーク
- 一意な+1回目の出現(distinct)
この例では、抽出することを目的としています。 いちげんてき を選択します。 ユニーク オプションを使用します。
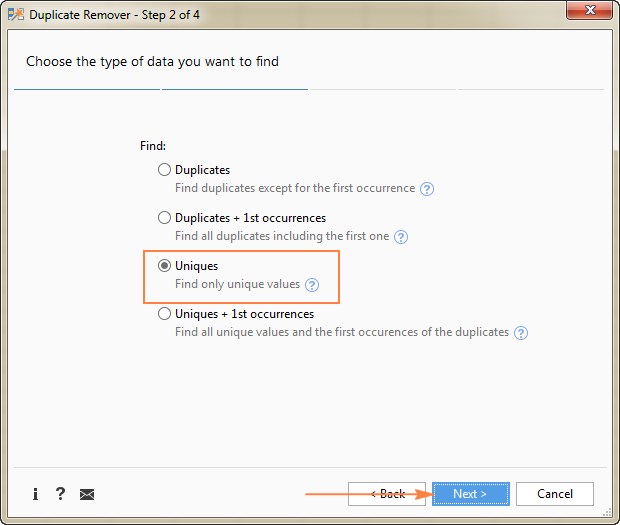
ヒント:上のスクリーンショットにあるように、2つのオプションがあります。 重複値 他のワークシートを控除する必要がある場合、それを心に留めておくだけです。
この例では、3つのカラムすべての値に基づいて一意な行を見つけたい ( 注文番号 , 氏名 と ラストネーム )であるため、すべてを選択する。
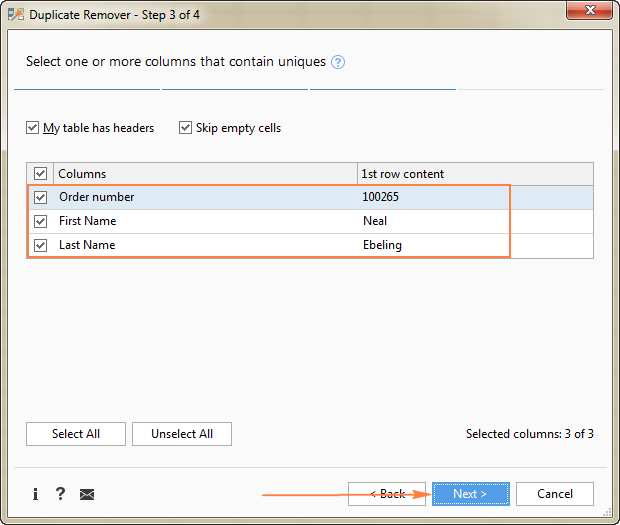
- ユニークな価値を強調する
- ユニークな値を選択する
- ステータス欄で確認する
- 別の場所にコピーする
ユニークな行を抽出するため、select 別の場所にコピーする を選択し、コピーする場所を指定します(アクティブシート)。 カスタムロケーション オプションで、移動先範囲の先頭セルを指定します)、新規ワークシート、新規ワークブックのいずれかを選択します。
この例では、新しいシートを選択しましょう。
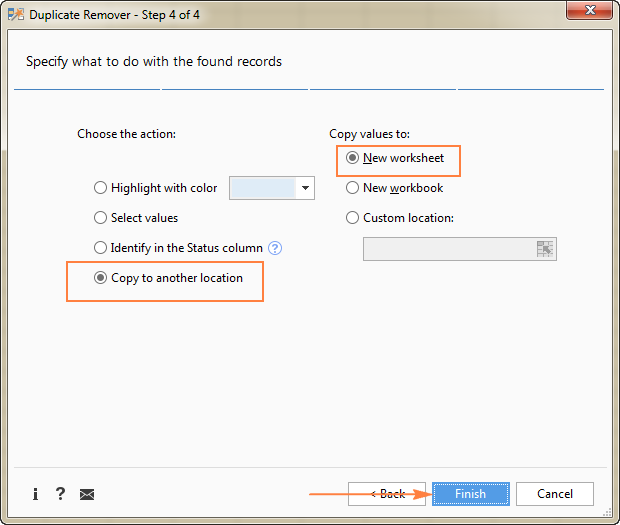
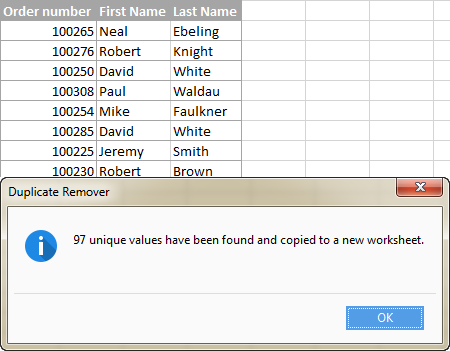
Excelでユニークな値または行のリストを取得するためのこの迅速かつシンプルな方法が気に入りましたか? もしそうなら、以下の評価版をダウンロードして試してみることをお勧めします。 Duplicate Removerだけでなく、私たちが持っている他のすべての時間節約ツールは、Ultimate Suite for Excelに付属しています。
ダウンロード可能なもの
Excelで一意な値を検索する - サンプルワークブック (.xlsx ファイル)
Ultimate Suite - 評価版 (.exeファイル)
