
Оглавление
Это заключительная часть серии статей "Уникальные значения Excel", в которой рассказывается о том, как получить список отличительных/уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро получить список отличительных значений с помощью расширенного фильтра Excel и как извлечь уникальные строки с помощью средства удаления дубликатов.
В нескольких недавних статьях мы обсуждали различные методы подсчета и поиска уникальных значений в Excel. Если у вас был шанс прочитать эти руководства, вы уже знаете, как получить уникальный или отличный список путем идентификации, фильтрации и копирования. Но это немного долгий и далеко не единственный способ извлечения уникальных значений в Excel. Вы можете сделать это намного быстрее, используя специальную формулу, и в мгновение окаЯ покажу вам эту и несколько других техник.
Совет. Чтобы быстро получить уникальные значения в последней версии Excel 365, которая поддерживает динамические массивы, используйте функцию UNIQUE, как описано в учебнике по ссылке выше.
Как получить уникальные значения в Excel
Чтобы избежать путаницы, сначала давайте договоримся, что мы называем уникальными значениями в Excel. Уникальные значения это значения, которые существуют в списке только один раз. Например:
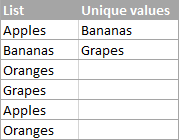
Чтобы извлечь список уникальных значений в Excel, используйте одну из следующих формул.
Массив формула уникальных значений (заполняется нажатием Ctrl + Shift + Enter ):
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1,$A$2:$A$10) + (COUNTIF($A$2:$A$10, $A$2:$A$10)1), 0)), "")
Обычный формула уникальных значений (завершается нажатием клавиши Enter):
=IFERROR(INDEX($A$2:$A$10, MATCH(0,INDEX(COUNTIF($B$1:B1, $A$2:$A$10)+(COUNTIF($A$2:$A$10, $A$2:$A$10)1),0,0), 0)), "")
В приведенных выше формулах используются следующие ссылки:
- A2:A10 - список источников.
- B1 - верхняя ячейка уникального списка минус 1. В данном примере мы начинаем уникальный список с ячейки B2, поэтому в формулу подставляем B1 (B2-1=B1). Если ваш уникальный список начинается, скажем, с ячейки C3, то измените $B$1:B1 на $C$2:C2.
Примечание. Поскольку формула ссылается на ячейку над первой ячейкой уникального списка, которая обычно является заголовком столбца (B1 в данном примере), убедитесь, что ваш заголовок имеет уникальное имя, которое не встречается больше нигде в столбце.
В данном примере мы извлекаем уникальные имена из столбца A (точнее, из диапазона A2:A20), и следующий снимок экрана демонстрирует формулу массива в действии:
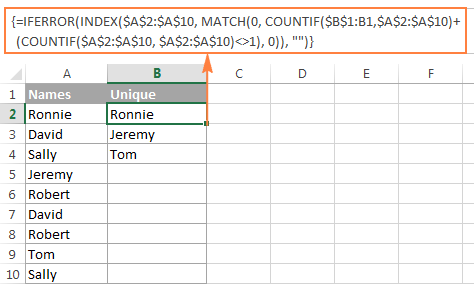
Подробное объяснение логики работы формулы приведено в отдельном разделе, а здесь мы расскажем, как использовать формулу для извлечения уникальных значений в ваших рабочих листах Excel:
- Настройте одну из формул в соответствии с вашим набором данных.
- Введите формулу в первую ячейку уникального списка (B2 в данном примере).
- Если вы используете формулу массива, нажмите Ctrl + Shift + Enter. Если вы выбрали обычную формулу, нажмите клавишу Enter, как обычно.
- Скопируйте формулу вниз на необходимое расстояние, перетащив ручку заполнения. Поскольку обе формулы уникальных значений заключены в функцию IFERROR, вы можете скопировать формулу до конца таблицы, и она не будет загромождать данные ошибками, независимо от того, как мало уникальных значений было извлечено.
Как получить отличные значения в Excel (уникальные + 1-е дублирующие вхождения)
Как вы, возможно, уже догадались из заголовка этого раздела, различные значения в Excel - это все разные значения в списке, т.е. уникальные значения и первые экземпляры дубликатов. Например:
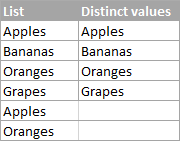
Чтобы получить отчетливый список в Excel, используйте следующие формулы.
Массив отдельную формулу (для этого нужно нажать Ctrl + Shift + Enter ):
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10), 0)), "")
Обычный отдельная формула:
=IFERROR(INDEX($A$2:$A$10, MATCH(0, INDEX(COUNTIF($B$1:B1, $A$2:$A$10), 0, 0), 0)), "")
Где:
- A2:A10 - это список источников.
- B1 - это ячейка над первой ячейкой списка отличий. В этом примере список отличий начинается с ячейки B2 (это первая ячейка, в которую вы вводите формулу), поэтому вы ссылаетесь на B1.
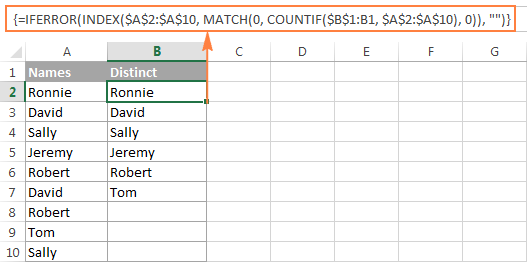
Извлечение отдельных значений в столбце с игнорированием пустых ячеек
Если ваш исходный список содержит пустые ячейки, то формула отличия, которую мы только что рассмотрели, будет возвращать ноль для каждой пустой строки, что может стать проблемой. Чтобы исправить это, улучшите формулу еще немного:
Формула массива для извлечения отдельные значения, исключая пробелы :
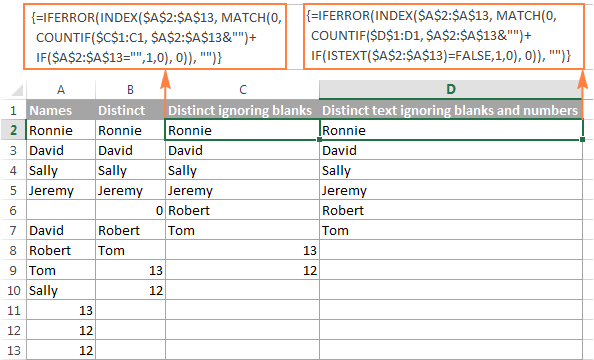
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF($A$2:$A$10="",1,0), 0)), "")
Получение списка отдельных текстовых значений без учета цифр и пробелов
Аналогичным образом можно получить список различных значений исключая пустые ячейки и ячейки с номерами :
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10&"") + IF(ISTEXT($A$2:$A$10)=FALSE,1,0), 0)), "")
Напомним, что в приведенных выше формулах A2:A10 - это исходный список, а B1 - это ячейка прямо над первой ячейкой исходного списка.
На следующем снимке экрана показан результат работы обеих формул:
Как извлечь отличительные значения с учетом регистра в Excel
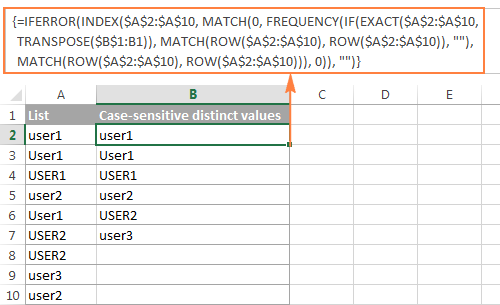
При работе с данными, чувствительными к регистру, такими как пароли, имена пользователей или имена файлов, вам может понадобиться получить список отличительных значений, чувствительных к регистру. Для этого используйте следующую формулу массива, где A2:A10 - исходный список, а B1 - ячейка над первой ячейкой отличительного списка:
Формула массива для получения отличительных значений с учетом регистра (требуется нажать Ctrl + Shift + Enter )
=IFERROR(INDEX($A$2:$A$10, MATCH(0, FREQUENCY(IF(EXACT($A$2:$A$10,TRANSPOSE($B$1:B1)), MATCH(ROW($A$2:$A$10), ROW($A$2:$A$10)), ""), MATCH(ROW($A$2:$A$10), ROW($A$2:$A$10))), 0))), "")
Как работает формула уникальности/отличия
Этот раздел написан специально для тех любознательных и вдумчивых пользователей Excel, которые хотят не только знать формулу, но и полностью понять ее суть.
Само собой разумеется, что формулы для извлечения уникальных и отличных значений в Excel не являются ни тривиальными, ни простыми. Но присмотревшись, вы можете заметить, что все формулы основаны на одном и том же подходе - использовании INDEX/MATCH в сочетании с функциями COUNTIF, или COUNTIF + IF.
Для нашего углубленного анализа воспользуемся формулой массива, которая извлекает список отдельных значений, поскольку все остальные формулы, обсуждаемые в этом учебнике, являются усовершенствованиями или вариациями этой базовой формулы:
=IFERROR(INDEX($A$2:$A$10, MATCH(0, COUNTIF($B$1:B1, $A$2:$A$10), 0)), "")
Для начала отбросим очевидную функцию IFERROR, которая используется с единственной целью - устранить ошибки #N/A, когда количество ячеек, куда вы скопировали формулу, превышает количество отдельных значений в исходном списке.
А теперь давайте разберем основную часть нашей отличительной формулы:
- COUNTIF(диапазон, критерии) возвращает количество ячеек в диапазоне, удовлетворяющих заданному условию.
В данном примере COUNTIF($B$1:B1, $A$2:$A$10) возвращает массив из 1 и 0 в зависимости от того, встречается ли какое-либо из значений исходного списка ($A$2:$A$10) где-либо в отличительном списке ($B$1:B1). Если значение найдено, формула возвращает 1, иначе - 0.
В частности, в ячейке B2, COUNTIF($B$1:B1, $A$2:$A$10) становится:
COUNTIF("Distinct", { "Ронни"; "Дэвид"; "Салли"; "Джереми"; "Роберт"; "Дэвид"; "Роберт"; "Том"; "Салли"})и возвращается:
{0;0;0;0;0;0;0;0;0}потому что ни один из элементов исходного списка ( критерии ) появляется в ассортимент где функция ищет совпадение. В данном случае, ассортимент ($B$1:B1) состоит из одного элемента - "Distinct".
MATCH(lookup_value, lookup_array, [match_type])возвращает относительную позицию искомого значения в массиве.
В этом примере значение lookup_value равно 0, и, следовательно:
MATCH(0,COUNTIF($B$1:B1, $A$2:$A$10), 0)
превращается в:
MATCH(0, { 0 ;0;0;0;0;0;0;0;0},0)
и возвращается
потому что наша функция MATCH получает первое значение, которое точно равно искомому значению (как вы помните, искомое значение равно 0).
В данном примере INDEX($A$2:$A$10, 1)
становится:
INDEX({ "Ронни"; "Дэвид"; "Салли"; "Джереми"; "Роберт"; "Дэвид"; "Роберт"; "Том"; "Салли"}, 1)
и возвращает "Ронни".
Когда формула копируется вниз по столбцу, список отличий ($B$1:B1) расширяется, потому что ссылка на вторую ячейку (B1) является относительной ссылкой, которая изменяется в зависимости от относительного положения ячейки, в которую перемещается формула.
Таким образом, при копировании в ячейку B3, COUNTIF($B$1: B1 , $A$2:$A$10) меняется на COUNTIF($B$1: B2 , $A$2:$A$10), и становится:
COUNTIF({"Distinct"; "Ronnie"}, {"Ronnie"; "David"; "Sally"; "Jeremy"; "Robert"; "David"; "Robert"; "Tom"; "Sally"}), 0)), "")
и возвращается:
{1;0;0;0;0;0;0;0;0}
потому что в диапазоне $B$1:B2 найден один "Ronnie".
А затем, MATCH(0,{1; 0 ;0;0;0;0;0;0;0;0;0;0},0) возвращает 2, потому что 2 - это относительная позиция первого 0 в массиве.
И наконец, INDEX($A$2:$A$10, 2) возвращает значение из 2-й строки, которое является "David".
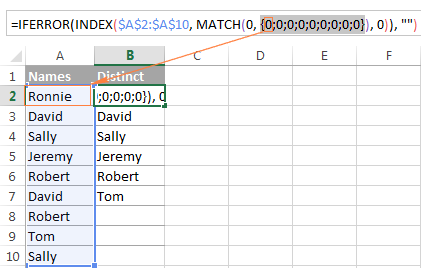
Совет. Чтобы лучше понять логику формулы, можно выделить различные части формулы в строке формул и нажать F9, чтобы увидеть, во что оценивается выбранная часть:
Если вам все еще трудно разобраться с формулой, вы можете ознакомиться со следующим учебным пособием для подробного объяснения того, как работает связь INDEX/MATCH: INDEX & MATCH как лучшая альтернатива Excel VLOOKUP.
Как уже упоминалось, другие формулы, обсуждаемые в этом учебнике, основаны на той же логике, только с некоторыми изменениями:
Формула уникальных значений - содержит еще одну функцию COUNTIF, которая исключает из уникального списка все элементы, которые появляются в исходном списке более одного раза: COUNTIF($A$2:$A$10, $A$2:$A$10)1 .
Формула различающихся значений, игнорирующая пробелы - здесь добавляется функция IF, которая предотвращает добавление пустых ячеек в список различающихся значений: IF($A$2:$A$13="",1,0) .
Формула различения текстовых значений, игнорирующая числа - вы используете функцию ISTEXT для проверки того, является ли значение текстом, и функцию IF для отклонения всех других типов значений, включая пустые ячейки: IF(ISTEXT($A$2:$A$13)=FALSE,1,0) .
Извлечение отдельных значений из столбца с помощью расширенного фильтра Excel
Если вы не хотите тратить время на то, чтобы разбираться в хитросплетениях формул отличительных значений, вы можете быстро получить список отличительных значений с помощью расширенного фильтра. Подробные шаги описаны ниже.
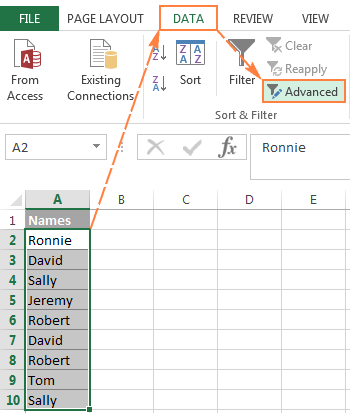
- Выберите столбец данных, из которого вы хотите извлечь отдельные значения.
- Переключитесь на Данные вкладка> Сортировка и фильтр группу, и нажмите кнопку Расширенный кнопка:
- Проверьте Копирование в другое место радиокнопка.
- В Диапазон списка убедитесь, что диапазон источников отображается правильно.
- В Копировать в поле введите самую верхнюю ячейку целевого диапазона. Помните, что скопировать отфильтрованные данные можно только в ячейку активный лист .
- Выберите Только уникальные записи
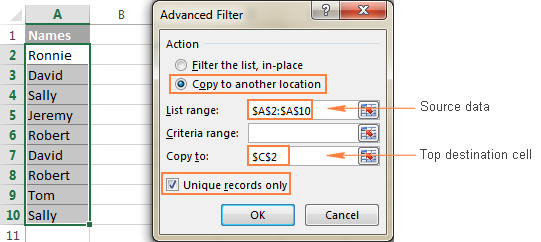
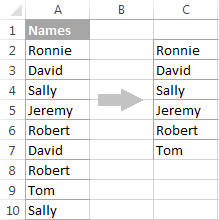
Обратите внимание, что хотя опция расширенного фильтра называется " Только уникальные записи ", он извлекает различные значения т.е. уникальные значения и 1-е вхождение дублирующих значений.
Извлечение уникальных и отличных строк с помощью Duplicate Remover
В заключительной части этого руководства позвольте мне показать вам наше собственное решение для поиска и извлечения отдельных и уникальных значений в листах Excel. Это решение сочетает в себе универсальность формул Excel и простоту расширенного фильтра. Кроме того, оно предоставляет несколько уникальных возможностей, таких как:
- Найти и извлечь уникальные / отличные строки на основе значений в одном или нескольких столбцах.
- Найти , выделить и копия уникальные значения в любое другое место, в той же или другой рабочей книге.
А теперь давайте посмотрим на инструмент Duplicate Remover в действии.
Предположим, у вас есть сводная таблица, созданная путем консолидации данных из нескольких других таблиц. Очевидно, что эта сводная таблица содержит много дублирующихся строк, и ваша задача - извлечь уникальные строки, которые появляются в таблице только один раз, или отдельные строки, включающие уникальные и 1-е дублирующие вхождения. В любом случае, с помощью надстройки Duplicate Remover работа выполняется за 5 быстрых шагов.
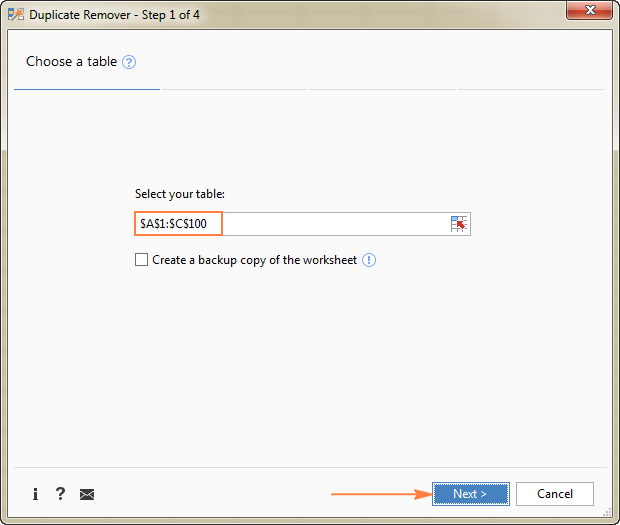
- Выберите любую ячейку в исходной таблице и нажмите кнопку Удаление дубликатов кнопка на Ablebits Data во вкладке Dedupe группа.

Запустится мастер удаления дубликатов, который выделит всю таблицу. Итак, просто нажмите кнопку Следующий чтобы перейти к следующему шагу.
- Уникальный
- Уникальные +1-е вхождения (отличительные)
В данном примере мы стремимся извлечь уникальные строки которые появляются в исходной таблице только один раз, поэтому мы выбираем Уникальный вариант:
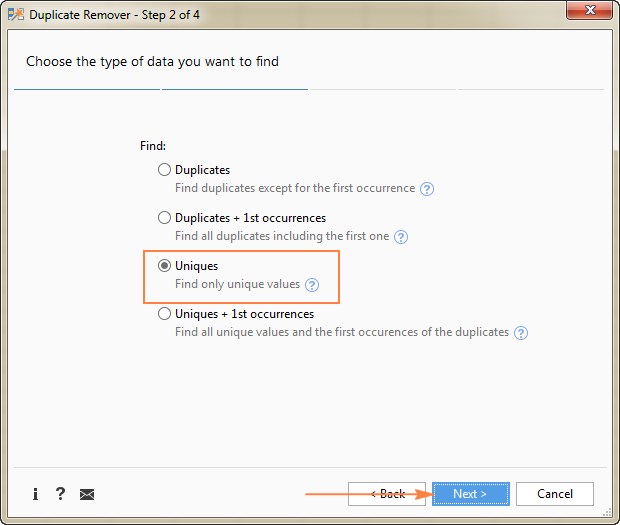
Совет. Как вы можете видеть на скриншоте выше, есть также 2 варианта для дублирование значений Просто имейте это в виду, если вам нужно будет вывести другой рабочий лист.
В этом примере мы хотим найти уникальные строки на основе значений во всех 3 столбцах ( Номер заказа , Имя и Фамилия ), поэтому мы выбираем всех.
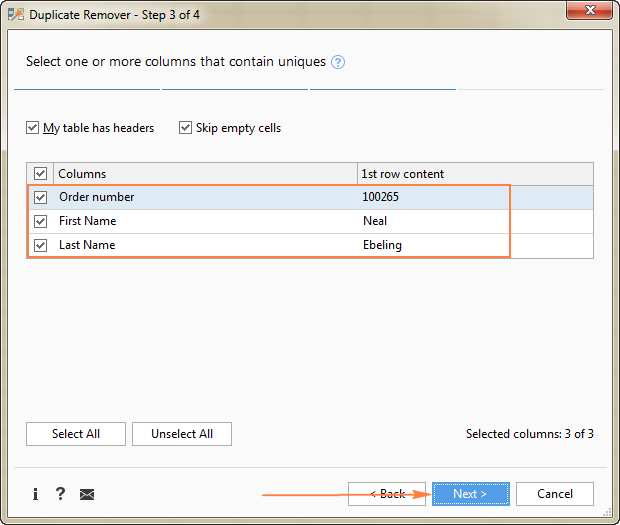
- Выделите уникальные значения
- Выберите уникальные значения
- Определить в колонке состояния
- Копирование в другое место
Поскольку мы извлекаем уникальные строки, выберите Копирование в другое место , а затем укажите, куда именно вы хотите их скопировать - активный лист (выберите Пользовательское местоположение и укажите верхнюю ячейку диапазона назначения), новый рабочий лист или новая рабочая книга.
В этом примере выберем новый лист:
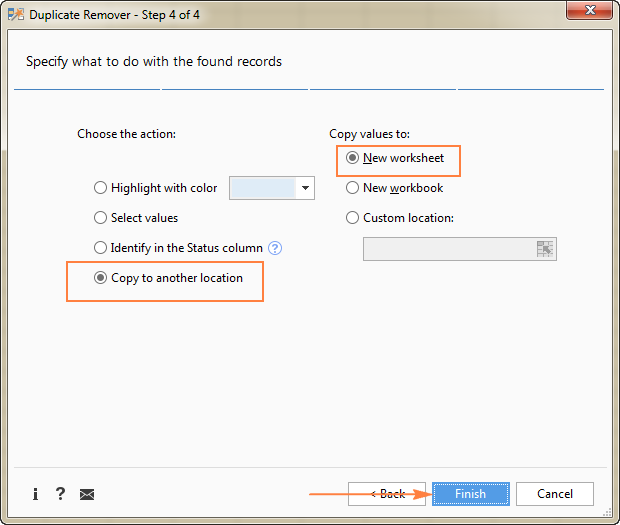
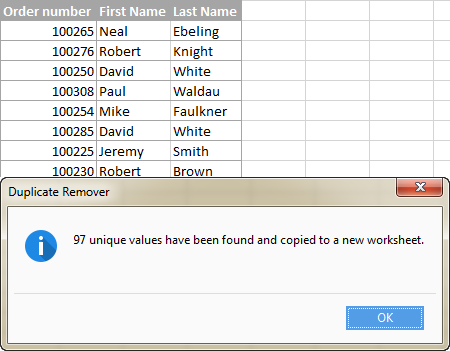
Понравился этот быстрый и простой способ получить список уникальных значений или строк в Excel? Если да, я советую вам скачать ознакомительную версию ниже и попробовать. Duplicate Remover, а также все другие инструменты для экономии времени, которые мы предлагаем, включены в Ultimate Suite for Excel.
Доступные загрузки
Поиск уникальных значений в Excel - образец рабочей книги (файл.xlsx)
Ultimate Suite - ознакомительная версия (файл .exe)
