
Tartalomjegyzék
Az elmúlt néhány cikkben különböző módokat vizsgáltunk arra, hogyan lehet karaktereket eltávolítani az Excelben a karakterláncokból. Ma egy újabb felhasználási esetet vizsgálunk meg - hogyan lehet mindent törölni egy adott karakter előtt vagy után.
Szöveg törlése 2 karakter előtt, után vagy között a Find & Replace funkcióval
Több cellában végzett adatmanipulációkhoz a Keresés és csere a megfelelő eszköz. Ha egy karakterlánc egy adott karaktert megelőző vagy követő részét szeretné eltávolítani, a következő lépéseket kell végrehajtania:
- Jelölje ki az összes olyan cellát, ahol törölni szeretné a szöveget.
- Nyomja meg a Ctrl + H billentyűkombinációt a Keresés és csere párbeszéd.
- A Találd meg, mit mezőben adja meg a következő kombinációk egyikét:
- A szöveg kiküszöbölése egy adott karakter előtt , írja be a karaktert, amelyet egy csillag (*char) előz meg.
- Szöveg eltávolítása egy bizonyos karakter után , írja be a karaktert, amelyet egy csillag követ (char*).
- Részlánc törlése két karakter között , írjon be egy csillagot 2 karakterrel körülvéve (char*char).
- Hagyja a Cserélje ki a címet. a címen doboz üres.
- Kattintson a címre. Cserélje ki az összes .
Például, a következők eltávolításához minden vessző után beleértve magát a vesszőt is, tegyen egy vesszőt és egy csillagot (,*) a Találd meg, mit mezőt, és a következő eredményt kapja:
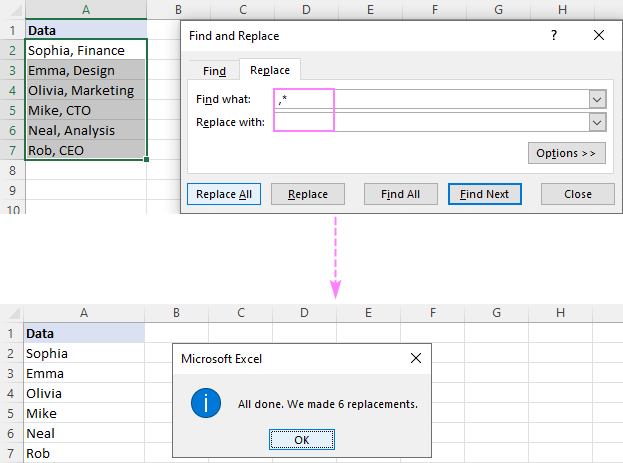
Részlánc törlése vessző előtt , írjon be egy csillagot, egy vesszőt és egy szóközt (*, ) a Találd meg, mit doboz.
Kérjük, vegye figyelembe, hogy nem csak egy vesszőt, hanem a vessző és szóköz Ha az adatokat vesszőkkel, szóközök nélkül választja el, akkor használjon csillagot, amelyet vessző követ (*,).
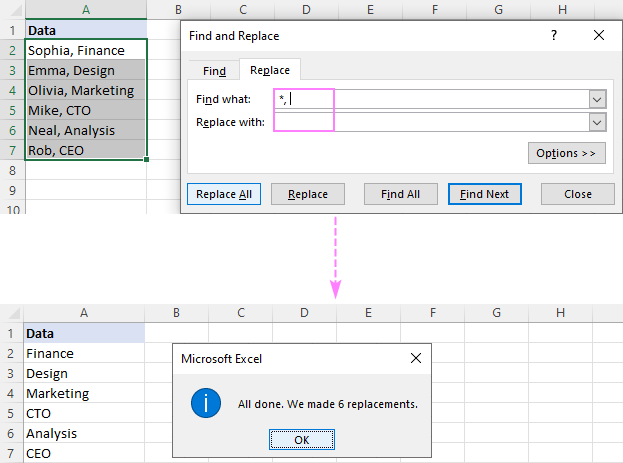
Szöveg törlése két vessző között , használjon csillagot vesszőkkel körülvéve (,*,).
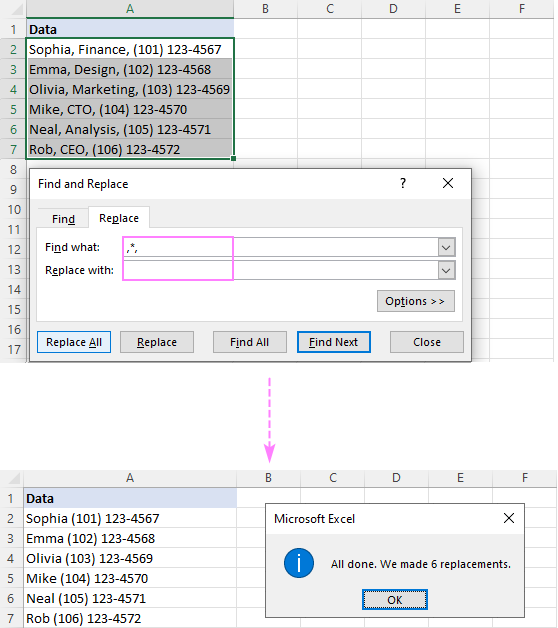
Tipp: Ha a neveket és a telefonszámokat vesszővel szeretné elválasztani, akkor írjon egy vesszőt (,) a Cserélje ki mező.
A szöveg egy részének eltávolítása Flash Fill használatával
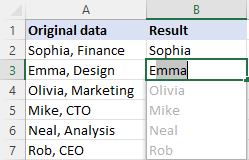
Az Excel modern verzióiban (2013 és újabb) van még egy egyszerű módja annak, hogy egy adott karaktert megelőző vagy követő szöveget kitöröljön - a Flash Fill funkció. Így működik:
- Írja be az adatokat tartalmazó első cella melletti cellába a várt eredményt, és nyomja meg az Enter billentyűt.
- Kezdjen el beírni egy megfelelő értéket a következő cellába. Amint az Excel megérzi a beírt értékek mintázatát, előnézetet jelenít meg a többi celláról, amelyek ugyanezt a mintát követik.
- A javaslat elfogadásához nyomja meg az Enter billentyűt.
Kész!
Szöveg eltávolítása képletek segítségével
A Microsoft Excelben számos, a beépített funkciók használatával végzett adatmanipuláció képlettel is elvégezhető. Az előző módszerekkel ellentétben a képletek nem változtatnak az eredeti adatokon, és nagyobb kontrollt biztosítanak az eredmények felett.
Hogyan lehet eltávolítani mindent egy adott karakter után
Egy adott karakter utáni szöveg törléséhez az általános képlet a következő:
LEFT( sejt , SEARCH(" char ", sejt ) -1)Itt a SEARCH függvénnyel megkapjuk a karakter pozícióját, és átadjuk a LEFT függvénynek, így az kivonja a megfelelő számú karaktert a karakterlánc elejéről. A SEARCH által visszaadott számból egy karaktert kivonunk, hogy a határolójelet kizárjuk az eredményekből.
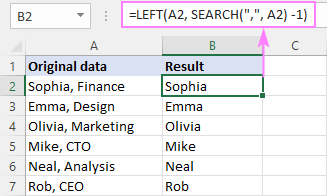
Ha például egy karakterlánc vessző utáni részét szeretné eltávolítani, adja be az alábbi képletet a B2-be, és húzza lefelé a B7-ig:
=LEFT(A2, SEARCH(",", A2) -1)
Hogyan lehet eltávolítani mindent egy adott karakter előtt
A szöveges karakterlánc egy bizonyos karakter előtti részének törléséhez az általános képlet a következő:
RIGHT( sejt , LEN( sejt ) - SEARCH(" char ", sejt ))Itt ismét kiszámítjuk a SEARCH segítségével a célkarakter pozícióját, kivonjuk a LEN által visszaadott teljes stringhosszból, és a különbséget átadjuk a RIGHT függvénynek, így az ennyi karaktert húz ki a string végéből.
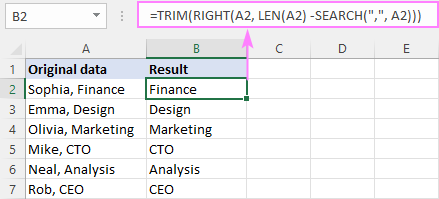
Például a vessző előtti szöveg eltávolításához a képlet a következő:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
A mi esetünkben a vesszőt egy szóköz karakter követi. Hogy elkerüljük a szóközöket az eredményekben, az alapképletet a TRIM függvénybe csomagoljuk:
=TRIM(JOBBRA(A2, LEN(A2) - SEARCH(",", A2)))
Megjegyzések:
- Mindkét fenti példa azt feltételezi, hogy csak egy egy példány Ha többször fordul elő, a szöveg a szöveg előtt/után a karakterláncban lévő elsőfokú eljárás .
- A SEARCH funkció nem nagy- és kisbetű-érzékeny , ami azt jelenti, hogy nem tesz különbséget a kis- és nagybetűs karakterek között. Ha az adott karakter egy betű, és meg akarja különböztetni a betű esetét, akkor használja a case-sensitive FIND funkció a SEARCH helyett.
Hogyan lehet törölni a szöveget egy karakter N-edik előfordulása után?
Abban az esetben, ha a forrás karakterlánc többszörösen tartalmazza az elválasztójelet, szükség lehet arra, hogy egy adott példány után eltávolítsa a szöveget. Ehhez használja a következő képletet:
LEFT( sejt , FIND("#", SUBSTITUTE( sejt , " char ", "#", n )) -1)Hol n az a karakter előfordulása, amely után a szöveget el kell távolítani.
A képlet belső logikája megköveteli, hogy olyan karaktert használjon, amely a forrásadatokban sehol sem szerepel, esetünkben egy hash szimbólumot (#). Ha ez a karakter előfordul az adathalmazban, akkor használjon valami mást a "#" helyett.
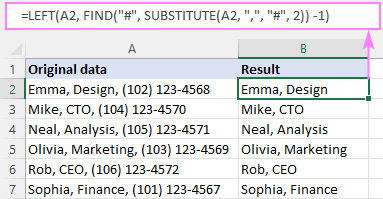
Például, ha az A2-ben a 2. vessző után mindent el akarunk távolítani (és magát a vesszőt is), a képlet a következő:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
Hogyan működik ez a képlet:
A képlet kulcsfontosságú része a FIND függvény, amely kiszámítja az n-edik elválasztójel (esetünkben vessző) pozícióját. Íme, hogyan:
Az A2-ben lévő 2. vesszőt a SUBSTITUTE segítségével egy hash szimbólummal (vagy bármely más, az adatainkban nem létező karakterrel) helyettesítjük:
SUBSTITUTE(A2, ",", "#", 2)
Az így kapott karakterlánc a FIND 2. argumentumába kerül, így a program megtalálja a "#" pozícióját a karakterláncban:
FIND("#", "Emma, Design# (102) 123-4568")
A FIND azt mondja, hogy a "#" a 13. karakter a karakterláncban. Ha tudni akarjuk, hogy hány karakter van előtte, csak vonjunk le 1-et, és 12-t kapunk:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
Ez a szám közvetlenül a num_chars argumentumot, amely arra kéri, hogy az A2 első 12 karakterét húzza ki:
=LEFT(A2, 12)
Ez az!
Hogyan lehet törölni a szöveget egy karakter N-edik előfordulása előtt?
Az általános képlet egy bizonyos karakter előtti részlánc eltávolítására a következő:
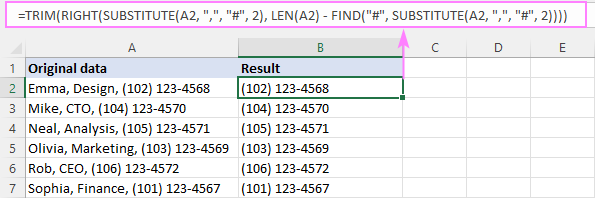
RIGHT(SUBSTITUTE( sejt , " char ", "#", n ), LEN( sejt ) - FIND("#", SUBSTITUTE( sejt , " char ", "#", n )) -1)Például az A2-ben a 2. vessző előtti szöveg eltávolításához a képlet a következő:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2) -1))
A vezető szóköz eltávolításához ismét a TRIM függvényt használjuk:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
Hogyan működik ez a képlet:
Összefoglalva, kiderítjük, hogy hány karakter van az n-edik elválasztójel után, és kivonjuk a megfelelő hosszúságú részláncot jobbról. Az alábbiakban a képlet felbontása következik:
Először is, az A2-ben a 2. vesszőt egy hash szimbólummal helyettesítjük:
SUBSTITUTE(A2, ",", "#", 2)
A kapott karakterlánc a szöveg a RIGHT érve:
RIGHT("Emma, Design# (102) 123-4568", ...
Ezután meg kell határoznunk, hogy hány karaktert kell kivenni a karakterlánc végéből. Ehhez megkeressük a hash szimbólum pozícióját a fenti karakterláncban (ami 13):
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
És vonjuk le a teljes karakterlánc hosszából (ami 28):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
A különbség (15) a RIGHT második argumentumába kerül, és arra utasítja, hogy az utolsó 15 karaktert vegye ki az első argumentumban szereplő karakterláncból:
RIGHT("Emma, Design# (102) 123-4568", 15)
A kimenet egy " (102) 123-4568" részlánc, amely nagyon közel áll a kívánt eredményhez, kivéve egy vezető szóközt. Ezért a TRIM függvényt használjuk, hogy megszabaduljunk tőle.
Hogyan lehet eltávolítani a szöveget egy karakter utolsó előfordulása után?
Ha az értékek változó számú elválasztójelekkel vannak elválasztva, akkor érdemes mindent eltávolítani az utolsó elválasztójel után. Ezt a következő képlettel lehet megtenni:
LEFT( sejt , FIND("#", SUBSTITUTE( sejt , " char ", "#", LEN( sejt ) - LEN(HELYETTESÍTŐ( sejt , " char ", "")))) -1)Tegyük fel, hogy az A oszlop különböző információkat tartalmaz az alkalmazottakról, de az utolsó vessző utáni érték mindig egy telefonszám. Az Ön célja, hogy eltávolítsa a telefonszámokat, és megtartsa az összes többi adatot.
A cél eléréséhez az A2 utolsó vesszője utáni szöveget ezzel a képlettel távolíthatja el:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1))
Másolja a képletet az oszlopba, és ezt az eredményt kapja:

Hogyan működik ez a képlet:
A képlet lényege, hogy meghatározzuk az utolsó elválasztójel (vessző) pozícióját a karakterláncban, és balról húzunk egy részláncot az elválasztójelig. Az elválasztójel pozíciójának meghatározása a legtrükkösebb rész, és itt van, hogyan kezeljük ezt:
Először is megállapítjuk, hogy hány vessző van az eredeti karakterláncban. Ehhez minden egyes vesszőt semmivel ("") helyettesítünk, és az így kapott karakterláncot a LEN függvénynek adjuk meg:
LEN(SUBSTITUTE(A2, ",","""))
A2 esetében az eredmény 35, ami az A2-ben szereplő karakterek száma vesszők nélkül.
Vonja ki a fenti számot a teljes karakterlánc hosszából (38 karakter):
LEN(A2) - LEN(SUBSTITUTE(A2, ",","""))
... és 3 lesz, ami az A2-ben lévő vesszők száma (és az utolsó vessző rendbeli száma).
Ezután a FIND és SUBSTITUTE függvények már ismert kombinációját használjuk a karakterlánc utolsó vesszőjének pozíciójának megadására. A példányszámot (esetünkben a 3. vesszőt) a fent említett LEN SUBSTITUTE képlet szolgáltatja:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
Úgy tűnik, hogy a 3. vessző a 23. karakter az A2-ben, ami azt jelenti, hogy 22 karaktert kell kivennünk előtte. Tehát, a fenti képletet mínusz 1 karakterrel a num_chars a LEFT érve:
LEFT(A2, 23-1)
Hogyan lehet eltávolítani a szöveget egy karakter utolsó előfordulása előtt?
Ha egy adott karakter utolsó előfordulása előtt mindent törölni szeretne, az általános képlet a következő:
RIGHT( sejt , LEN( sejt ) - FIND("#", SUBSTITUTE( sejt , " char ", "#", LEN( sejt ) - LEN(HELYETTESÍTŐ( sejt , " char ", "")))))A mintatáblázatunkban az utolsó vessző előtti szöveg törléséhez a képlet a következő formát veszi fel:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",","")))))
Befejezésként a TRIM funkcióba illesztjük, hogy eltüntessük a vezető szóközöket:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",",""))))))
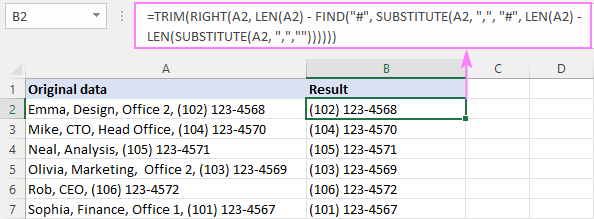
Hogyan működik ez a képlet:
Összefoglalva, az előző példában leírtak szerint megkapjuk az utolsó vessző pozícióját, és kivonjuk a karakterlánc teljes hosszából:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
Eredményként megkapjuk az utolsó vessző utáni karakterek számát, és átadjuk a RIGHT függvénynek, így az ennyi karaktert hoz a karakterlánc végétől.
Egyéni funkció a karakter mindkét oldalán lévő szöveg eltávolítására
Amint a fenti példákból láthattuk, szinte bármilyen felhasználási esetet megoldhatunk az Excel natív függvényeinek különböző kombinációkban történő használatával. A probléma az, hogy egy maroknyi trükkös képletet kell megjegyeznünk. Hmm, mi lenne, ha írnánk egy saját függvényt, amely minden forgatókönyvet lefed? Jó ötletnek hangzik. Tehát, adjuk hozzá a következő VBA kódot a munkafüzethez (a VBA Excelbe való beillesztésének részletes lépései a következők.itt):
Function RemoveText(str As String , delimiter As String , occurrence As Integer , is_after As Boolean ) Dim delimiter_num, start_num, delimiter_len As Integer Dim str_result As String delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(delimiter) For i = 1 To occurrence delimiter_num = InStr(start_num, str, delimiter, vbTextCompare) If 0 <delimiter_num Then start_num =delimiter_num + delimiter_len End If Next i If 0 <delimiter_num Then If True = is_after Then str_result = Mid(str, 1, start_num - delimiter_len - 1) Else str_result = Mid(str, start_num) End If End If End If RemoveText = str_result End FunctionA függvényünk neve RemoveText és a következő szintaxissal rendelkezik:
RemoveText(string, delimiter, occurrence, is_after)Hol:
String - az eredeti szöveges karakterlánc. Cellahivatkozással is ábrázolható.
Határolójel - az a karakter, amely előtt/után a szöveget el kell távolítani.
Előfordulás - az elhatároló példánya.
Is_after - egy bóluszi érték, amely megadja, hogy a szöveg melyik oldaláról kell eltávolítani a szöveget. Lehet egyetlen karakter vagy karaktersorozat.
- TRUE - mindent töröl az elválasztójel után (beleértve magát az elválasztójelet is).
- FALSE - mindent töröl az elválasztójel előtt (beleértve magát az elválasztójelet is).
Miután a függvény kódja beillesztésre került a munkafüzetbe, kompakt és elegáns képletekkel távolíthatja el a cellákból a részláncokat.
Például, ha az A2-ben az első vessző után mindent ki akarunk törölni, a B2-ben a következő képletet kell használni:
=RemoveText(A3, ", ", ", 1, TRUE)
Ha az A2-ben az első vessző előtt mindent törölni akarunk, a C2-ben a következő képletet kell használni:
=RemoveText(A3, ", ", ", 1, FALSE)
Mivel az egyéni függvényünk elfogad egy string az elhatárolóhoz , vesszőt és szóközt (", ") teszünk a 2. argumentumba, hogy megkíméljük a vezető szóközök utólagos levágásától.
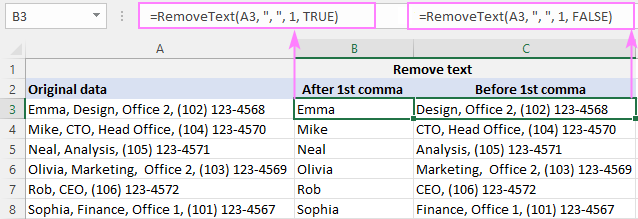
Az egyéni függvényünk gyönyörűen működik, nem igaz? De ha azt hiszed, hogy ez az átfogó megoldás, akkor még nem láttad a következő példát :)
Töröljön mindent a karakterek előtt, után vagy között
Ha még több lehetőséget szeretne kapni az egyes karakterek vagy a szöveg több cellából történő eltávolítására, egyezés vagy pozíció szerint, akkor adja hozzá az Ultimate Suite csomagot az Excel eszköztárához.
Itt közelebbről megnézzük a Eltávolítás pozíció szerint funkció található a Ablebits adatok tab> Szöveg csoport> Távolítsa el a .
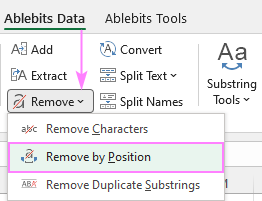
Az alábbiakban a két leggyakoribb forgatókönyvvel foglalkozunk.
Mindent eltávolíthat bizonyos szöveg előtt vagy után
Tegyük fel, hogy az összes forrásszöveged tartalmaz valamilyen közös szót vagy szöveget, és szeretnél törölni mindent, ami a szöveg előtt vagy után van. Ehhez jelöld ki a forrásadataidat, futtasd a Eltávolítás pozíció szerint eszközt, és konfigurálja azt az alábbiak szerint:
- Válassza ki a Minden karakter a szöveg előtt vagy Minden karakter a szöveg után opciót, és írja be a kulcsszöveget (vagy karaktert) a mellette lévő mezőbe.
- Attól függően, hogy a nagy- és kisbetűket különböző vagy azonos karakterként kell-e kezelni, jelölje be vagy vegye ki a jelölést a Nagybetű-érzékeny doboz.
- Hit Távolítsa el a .
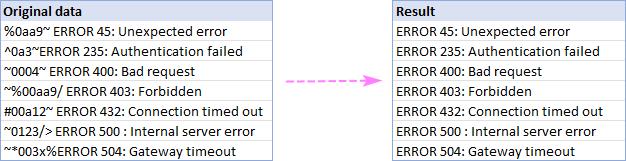
Ebben a példában az A2:A8 cellákban a "hiba" szót megelőző összes karaktert eltávolítjuk:
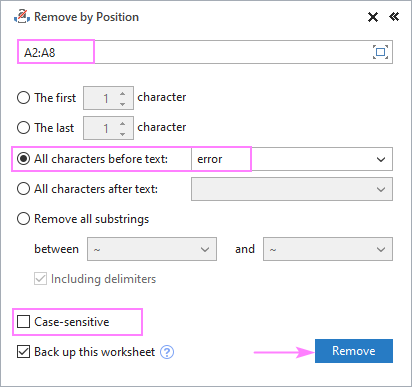
És pontosan azt az eredményt kapjuk, amit keresünk:
Két karakter közötti szöveg eltávolítása
Abban a helyzetben, amikor a nem releváns információ 2 konkrét karakter között van, itt van, hogyan lehet gyorsan törölni:
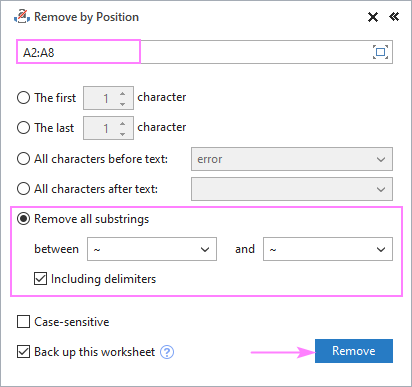
- Válassza ki a címet. Minden részlánc eltávolítása és írjon be két karaktert az alábbi mezőkbe.
- Ha a "between" karaktereket is el kell távolítani, ellenőrizze a Határolójelekkel együtt doboz.
- Kattintson a címre. Távolítsa el a .
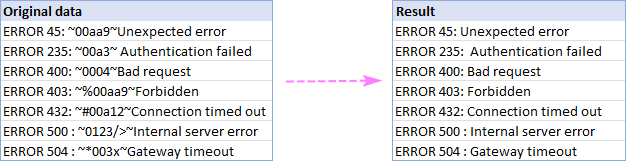
Példaként törölünk mindent két tilde karakter (~) között, és tökéletesen megtisztított karakterláncokat kapunk:
Ha szeretné kipróbálni a multifunkcionális eszköz egyéb hasznos funkcióit, akkor bátorítom, hogy töltse le a tesztverziót a bejegyzés végén. Köszönjük, hogy elolvasta, és reméljük, hogy jövő héten találkozunk a blogunkon!
Elérhető letöltések
Első vagy utolsó karakterek eltávolítása - példák (.xlsm fájl)
Ultimate Suite - próbaverzió (.exe fájl)
