
Obsah
V několika posledních článcích jsme se zabývali různými způsoby odstraňování znaků z řetězců v aplikaci Excel. Dnes prozkoumáme ještě jeden případ použití - jak odstranit vše před nebo za určitým znakem.
Odstranění textu před, za nebo mezi 2 znaky pomocí funkce Najít & Nahradit
Pro manipulaci s daty ve více buňkách je vhodným nástrojem funkce Najít a nahradit. Chcete-li odstranit část řetězce předcházejícího určitému znaku nebo následujícího za ním, proveďte tyto kroky:
- Vyberte všechny buňky, ve kterých chcete odstranit text.
- Stisknutím klávesové zkratky Ctrl + H otevřete Najít a nahradit dialog.
- V Zjistěte, co zadejte jednu z následujících kombinací:
- Odstranění textu před daným znakem , zadejte znak, kterému předchází hvězdička (*znak).
- Odstranění textu podle určitého znaku , zadejte znak následovaný hvězdičkou (char*).
- Odstranění podřetězce mezi dvěma postavami , zadejte hvězdičku obklopenou 2 znaky (char*char).
- Opusťte Vyměňte stránky s prázdné pole.
- Klikněte na Vyměňte všechny .
Chcete-li například odstranit vše za čárkou včetně samotné čárky, vložte čárku a znak hvězdičky (,*) do pole Zjistěte, co a dostanete následující výsledek:
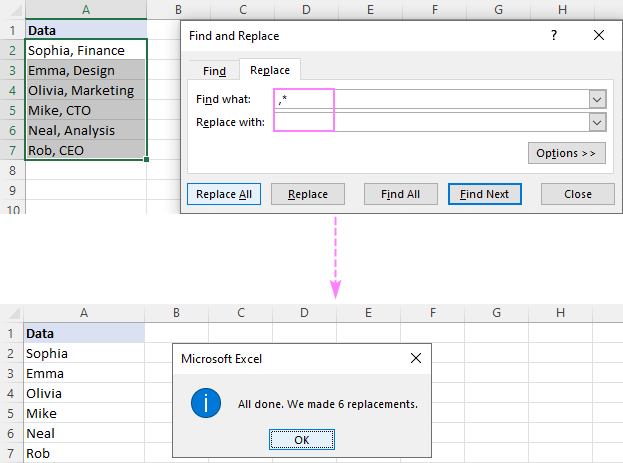
Odstranění podřetězce před čárkou , napište do pole hvězdičku, čárku a mezeru (*, ). Zjistěte, co box.
Všimněte si prosím, že nenahrazujeme pouze čárku, ale také čárka a mezera aby se ve výsledcích neobjevily úvodní mezery. Pokud jsou data oddělena čárkami bez mezer, použijte hvězdičku následovanou čárkou (*,).
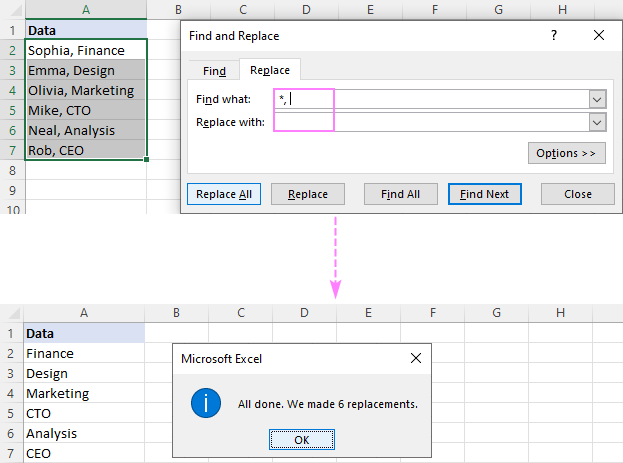
Odstranění textu mezi dvěma čárkami , použijte hvězdičku obklopenou čárkami (,*,).
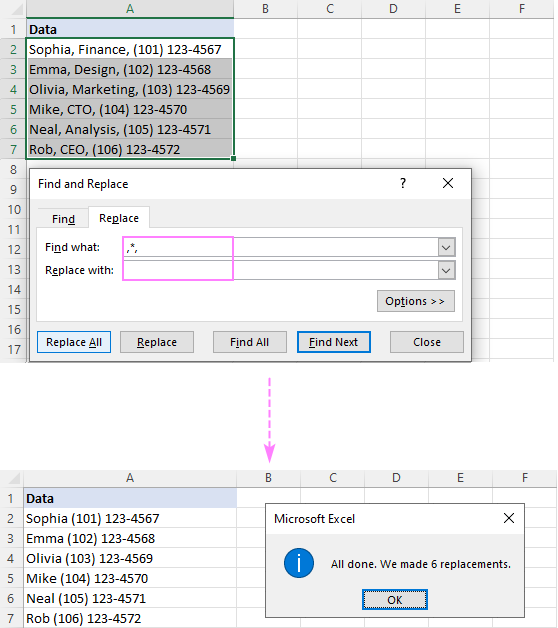
Tip: Pokud chcete jména a telefonní čísla oddělit čárkou, napište čárku (,) do pole pro zadání jména. Nahradit pole.
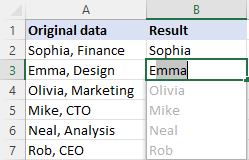
Odstranění části textu pomocí funkce Flash Fill
V moderních verzích aplikace Excel (2013 a novějších) existuje ještě jeden snadný způsob, jak vymazat text, který předchází nebo následuje po určitém znaku - funkce Bleskové vyplnění. Zde je popsán její postup:
- Do buňky vedle první buňky s daty napište očekávaný výsledek a stiskněte klávesu Enter .
- Začněte psát vhodnou hodnotu do další buňky. Jakmile Excel zjistí vzor zadávaných hodnot, zobrazí náhled zbývajících buněk podle stejného vzoru.
- Stisknutím klávesy Enter návrh přijmete.
Hotovo!
Odstranění textu pomocí vzorců
V aplikaci Microsoft Excel lze mnoho manipulací s daty prováděných pomocí vestavěných funkcí provést také pomocí vzorce. Na rozdíl od předchozích metod vzorce neprovádějí žádné změny původních dat a poskytují větší kontrolu nad výsledky.
Jak odstranit vše za určitým znakem
Obecný vzorec pro odstranění textu za určitým znakem je:
LEVÝ( buňka , HLEDAT(" znak ", buňka ) -1)Zde pomocí funkce SEARCH zjistíme pozici znaku a předáme ji funkci LEFT, takže ta vyčlení příslušný počet znaků ze začátku řetězce. Od čísla vráceného funkcí SEARCH se odečte jeden znak, aby se z výsledků vyloučil oddělovač.
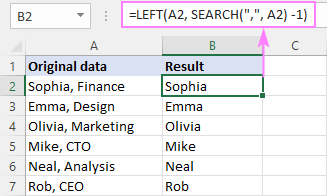
Chcete-li například odstranit část řetězce za čárkou, zadejte následující vzorec do pole B2 a přetáhněte jej dolů přes pole B7:
=LEFT(A2, SEARCH(",", A2) -1)
Jak odstranit vše před určitým znakem
Chcete-li odstranit část textového řetězce před určitým znakem, použijete obecný vzorec:
PRAVDA( buňka , LEN( buňka ) - HLEDAT(" znak ", buňka ))Zde opět pomocí funkce SEARCH vypočítáme pozici cílového znaku, odečteme ji od celkové délky řetězce vrácené funkcí LEN a rozdíl předáme funkci RIGHT, která vytáhne z konce řetězce právě tolik znaků.
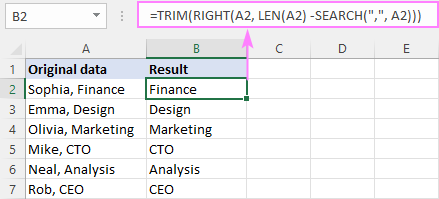
Například pro odstranění textu před čárkou je vzorec následující:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
V našem případě za čárkou následuje znak mezery. Abychom se vyhnuli úvodním mezerám ve výsledcích, obalíme základní vzorec funkcí TRIM:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
Poznámky:
- Oba výše uvedené příklady předpokládají, že existuje pouze jeden případ oddělovače v původním řetězci. Pokud se vyskytuje vícekrát, text bude odstraněn před/za oddělovačem. první instance .
- Funkce HLEDAT je nerozlišuje velká a malá písmena , což znamená, že nerozlišuje mezi malými a velkými písmeny. Pokud je konkrétním znakem písmeno a chcete rozlišit velikost písmen, použijte příkaz rozlišování velkých a malých písmen Funkce FIND místo funkce SEARCH.
Jak odstranit text po N-tém výskytu znaku
V situaci, kdy zdrojový řetězec obsahuje více výskytů oddělovače, můžete mít potřebu odstranit text za určitým výskytem. K tomu použijte následující vzorec:
LEVÝ( buňka , FIND("#", SUBSTITUTE( buňka , " znak ", "#", n )) -1)Kde: n je výskyt znaku, za kterým se má text odstranit.
Vnitřní logika tohoto vzorce vyžaduje použití nějakého znaku, který se nikde ve zdrojových datech nevyskytuje, v našem případě symbolu hash (#). Pokud se tento znak ve vašem souboru dat vyskytuje, použijte místo znaku "#" něco jiného.
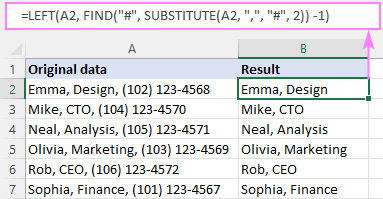
Například pro odstranění všeho za 2. čárkou v A2 (a samotné čárky) je vzorec následující:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
Jak tento vzorec funguje:
Klíčovou částí vzorce je funkce FIND, která vypočítá pozici n-tého oddělovače (v našem případě čárky). Zde je uveden postup:
Pomocí příkazu SUBSTITUTE nahradíme 2. čárku v A2 symbolem hash (nebo jiným znakem, který se v datech nevyskytuje):
SUBSTITUTE(A2, ",", "#", 2)
Výsledný řetězec přejde do 2. argumentu příkazu FIND, takže najde pozici znaku "#" v tomto řetězci:
FIND("#", "Emma, Design# (102) 123-4568")
FIND nám říká, že "#" je 13. znak v řetězci. Chcete-li zjistit počet znaků, které mu předcházejí, stačí odečíst 1 a výsledkem bude 12:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
Toto číslo se přenáší přímo na num_chars argumentu LEFT, aby vytáhl prvních 12 znaků z A2:
=LEFT(A2, 12)
A je to!
Jak odstranit text před N-tým výskytem znaku
Obecný vzorec pro odstranění podřetězce před určitým znakem je:
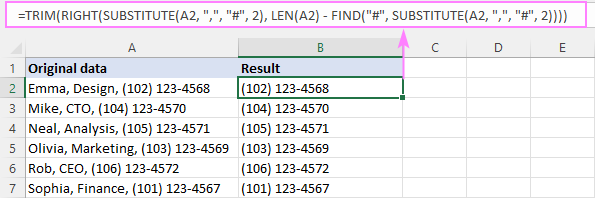
RIGHT(SUBSTITUTE( buňka , " znak ", "#", n ), LEN( buňka ) - FIND("#", SUBSTITUTE( buňka , " znak ", "#", n )) -1)Například pro odstranění textu před 2. čárkou v A2 je vzorec následující:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2) -1)
Pro odstranění úvodní mezery opět použijeme funkci TRIM jako obal:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
Jak tento vzorec funguje:
Souhrnně řečeno, zjistíme, kolik znaků je za n-tým oddělovačem, a zprava extrahujeme podřetězec odpovídající délky. Níže je rozpis vzorce:
Nejprve nahradíme 2. čárku v A2 symbolem hash:
SUBSTITUTE(A2, ",", "#", 2)
Výsledný řetězec přejde do text argument PRÁVA:
RIGHT("Emma, Design# (102) 123-4568", ...
Dále musíme určit, kolik znaků se má z konce řetězce vyjmout. K tomu zjistíme pozici hash symbolu ve výše uvedeném řetězci (což je 13):
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
A odečtěte ji od celkové délky řetězce (která je 28):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
Rozdíl (15) se přenese do druhého argumentu RIGHT a přikáže mu, aby z řetězce v prvním argumentu vytáhl posledních 15 znaků:
RIGHT("Emma, Design# (102) 123-4568", 15)
Výstupem je podřetězec "(102) 123-4568", který se velmi blíží požadovanému výsledku, až na úvodní mezeru. Proto použijeme funkci TRIM, abychom se jí zbavili.
Jak odstranit text po posledním výskytu znaku
V případě, že jsou hodnoty odděleny různým počtem oddělovačů, můžete chtít odstranit vše za posledním případem tohoto oddělovače. To lze provést pomocí následujícího vzorce:
LEVÝ( buňka , FIND("#", SUBSTITUTE( buňka , " znak ", "#", LEN( buňka ) - LEN(SUBSTITUTE( buňka , " znak ", "")))) -1)Předpokládejme, že sloupec A obsahuje různé informace o zaměstnancích, ale hodnota za poslední čárkou je vždy telefonní číslo. Vaším cílem je odstranit telefonní čísla a zachovat všechny ostatní údaje.
Cíle dosáhnete tak, že text za poslední čárkou v A2 odstraníte pomocí tohoto vzorce:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
Zkopírujte vzorec dolů do sloupce a získáte tento výsledek:

Jak tento vzorec funguje:
Podstata vzorce spočívá v tom, že určíme pozici posledního oddělovače (čárky) v řetězci a vytáhneme podřetězec zleva až k oddělovači. Získání pozice oddělovače je nejsložitější část a zde je uvedeno, jak ji řešíme:
Nejprve zjistíme, kolik je v původním řetězci čárek. Za tímto účelem nahradíme každou čárku ničím ("") a výsledný řetězec předáme funkci LEN:
LEN(SUBSTITUTE(A2, ",",""))
Pro A2 je výsledek 35, což je počet znaků v A2 bez čárek.
Odečtěte výše uvedené číslo od celkové délky řetězce (38 znaků):
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
... a dostanete 3, což je celkový počet čárek v A2 (a také pořadové číslo poslední čárky).
Dále použijeme již známou kombinaci funkcí FIND a SUBSTITUTE, abychom zjistili pozici poslední čárky v řetězci. Číslo instance (v našem případě 3. čárku) dodá výše zmíněný vzorec LEN SUBSTITUTE:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
Ukazuje se, že třetí čárka je 23. znakem v A2, což znamená, že potřebujeme vyjmout 22 znaků, které jí předcházejí. Proto vložíme výše uvedený vzorec minus 1 do pole num_chars argument LEVÁ:
LEFT(A2, 23-1)
Jak odstranit text před posledním výskytem znaku
Chcete-li odstranit vše před posledním výskytem určitého znaku, použijete obecný vzorec:
PRAVDA( buňka , LEN( buňka ) - FIND("#", SUBSTITUTE( buňka , " znak ", "#", LEN( buňka ) - LEN(SUBSTITUTE( buňka , " znak ", "")))))V naší ukázkové tabulce má vzorec pro odstranění textu před poslední čárkou tuto podobu:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
Na závěr jej vložíme do funkce TRIM, abychom odstranili počáteční mezery:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
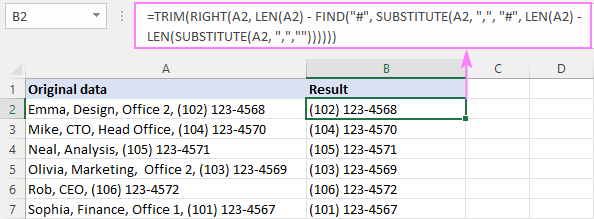
Jak tento vzorec funguje:
Shrneme to tak, že zjistíme pozici poslední čárky, jak bylo vysvětleno v předchozím příkladu, a odečteme ji od celkové délky řetězce:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
Výsledkem je počet znaků za poslední čárkou, který předáme funkci RIGHT, aby přenesla tento počet znaků z konce řetězce.
Vlastní funkce pro odstranění textu na obou stranách znaku
Jak jste viděli ve výše uvedených příkladech, můžete pomocí nativních funkcí Excelu v různých kombinacích vyřešit téměř jakýkoli případ použití. Problém je, že si musíte pamatovat hrstku složitých vzorců. Hmm, co kdybychom si napsali vlastní funkci, která by pokryla všechny scénáře? Zní to jako dobrý nápad. Přidejte tedy do svého sešitu následující kód VBA (podrobný postup pro vložení VBA do Excelu je následujícízde):
Function RemoveText(str As String , delimiter As String , occurrence As Integer , is_after As Boolean ) Dim delimiter_num, start_num, delimiter_len As Integer Dim str_result As String delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(delimiter) For i = 1 To occurrence delimiter_num = InStr(start_num, str, delimiter, vbTextCompare) If 0 <delimiter_num Then start_num =delimiter_num + delimiter_len End If Next i If 0 <delimiter_num Then If True = is_after Then str_result = Mid(str, 1, start_num - delimiter_len - 1) Else str_result = Mid(str, start_num) End If End If RemoveText = str_result End FunctionNaše funkce se jmenuje RemoveText a má následující syntaxi:
RemoveText(string, delimiter, occurrence, is_after)Kde:
Řetězec - je původní textový řetězec. Může být reprezentován odkazem na buňku.
Oddělovač - znak před/za, který má být odstraněn.
Výskyt - instance oddělovače.
Is_after - logická hodnota, která určuje, na které straně oddělovače má být text odstraněn. Může to být jeden znak nebo posloupnost znaků.
- TRUE - odstraní vše za oddělovačem (včetně samotného oddělovače).
- FALSE - odstraní vše před oddělovačem (včetně samotného oddělovače).
Po vložení kódu funkce do sešitu můžete z buněk odstraňovat podřetězce pomocí kompaktních a elegantních vzorců.
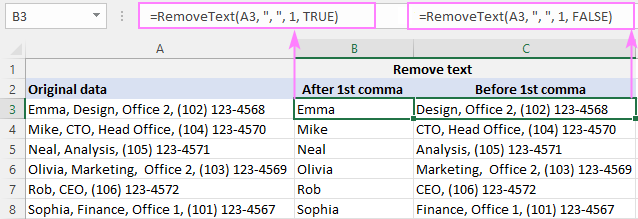
Například pro vymazání všeho za 1. čárkou v A2 je vzorec v B2 následující:
=RemoveText(A3, ", ", 1, TRUE)
Chcete-li odstranit vše před 1. čárkou v A2, vzorec v C2 je:
=RemoveText(A3, ", ", 1, FALSE)
Protože naše vlastní funkce přijímá řetězec pro oddělovač , do druhého argumentu vložíme čárku a mezeru (", "), abychom si ušetřili práci s následným ořezáváním počátečních mezer.
Naše vlastní funkce funguje krásně, že? Ale pokud si myslíte, že je to komplexní řešení, ještě jste neviděli další příklad :)
Odstranění všeho před, za nebo mezi znaky
Chcete-li získat ještě více možností pro odstraňování jednotlivých znaků nebo textu z více buněk podle shody nebo pozice, přidejte si do sady nástrojů Excelu naši sadu Ultimate Suite.
Zde se blíže podíváme na. Odstranění podle pozice funkce umístěná na Data Ablebits karta> Text skupina> Odstranění adresy .
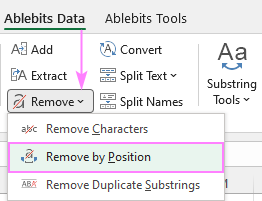
Níže se budeme zabývat dvěma nejčastějšími scénáři.
Odstranění všeho před nebo za určitým textem
Předpokládejme, že všechny vaše zdrojové řetězce obsahují nějaké společné slovo nebo text a vy si přejete odstranit vše před nebo za tímto textem. Chcete-li to provést, vyberte zdrojová data, spusťte příkaz Odstranění podle pozice a nakonfigurujte jej podle následujícího obrázku:
- Vyberte Všechny znaky před textem nebo Všechny znaky za textem a do vedlejšího pole zadejte text klíče (nebo znak).
- V závislosti na tom, zda mají být velká a malá písmena považována za různé nebo stejné znaky, zaškrtněte nebo zrušte zaškrtnutí políčka Rozlišování velkých a malých písmen box.
- Hit Odstranění adresy .
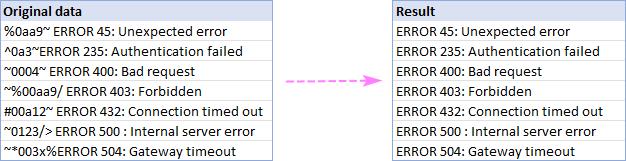
V tomto příkladu odstraníme všechny znaky před slovem "error" v buňkách A2:A8:
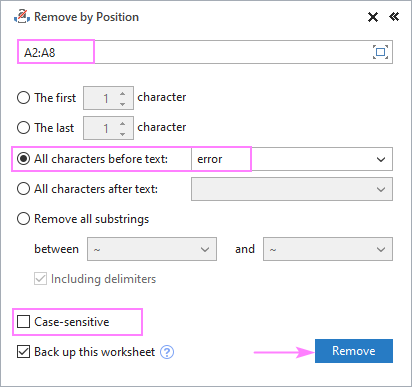
A získat přesně ten výsledek, který hledáme:
Odstranění textu mezi dvěma znaky
V situaci, kdy se mezi dvěma konkrétními znaky nachází irelevantní informace, je možné je rychle odstranit:
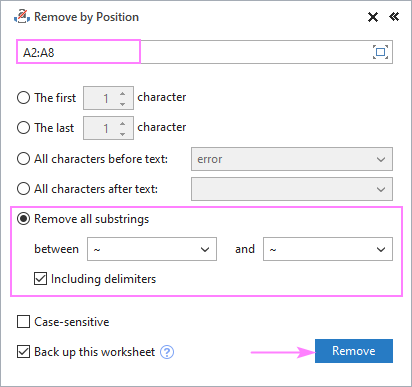
- Vyberte si Odstranění všech podřetězců a zadejte dva znaky do níže uvedených políček.
- Pokud by měly být odstraněny i znaky "mezi", zkontrolujte, zda Včetně oddělovačů box.
- Klikněte na Odstranění stránky .
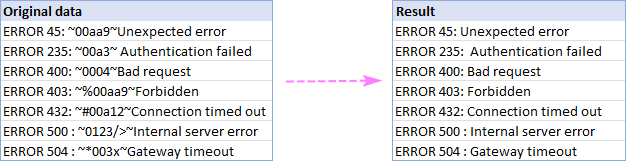
Jako příklad můžeme odstranit vše mezi dvěma znaky tildy (~) a výsledkem je dokonale vyčištěný řetězec:
Chcete-li vyzkoušet další užitečné funkce tohoto multifunkčního nástroje, doporučuji vám stáhnout si zkušební verzi na konci tohoto příspěvku. Děkujeme za přečtení a doufáme, že se uvidíme na našem blogu příští týden!
Dostupné soubory ke stažení
Odstranění prvních nebo posledních znaků - příklady (.xlsm soubor)
Ultimate Suite - zkušební verze (.exe soubor)
