
Tabloya naverokê
Di çend gotarên vê dawiyê de, me li awayên cihêreng nihêrî ku meriv tîpan ji rêzikên di Excel de derxîne. Îro, em ê dozek din a karanîna lêkolînê bikin - meriv çawa her tiştî berî an piştî karakterek taybetî jêbirin.
Tişta berî, paşî an di navbera 2 tîpan de bi Find & Replace
Ji bo manîpulasyonên daneyan di gelek hucreyan de, Find and Replace amûrek rast e. Ji bo rakirina beşek ji rêzek ku li pêş an li dû karakterek taybetî ye, ev gavan in:
- Hemû şaneyên ku hûn dixwazin nivîsê jêbikin hilbijêrin.
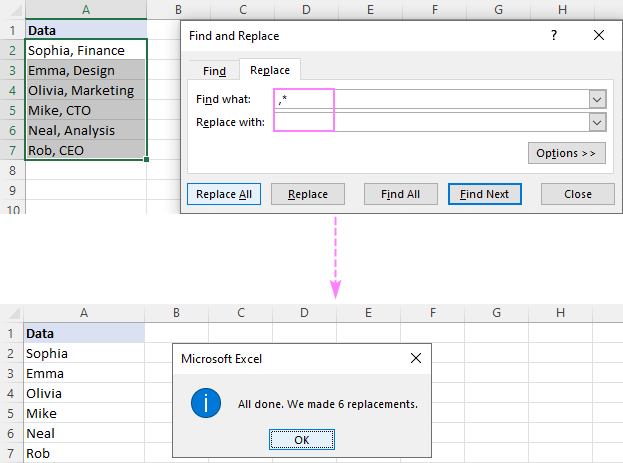
- Ctrl + H bişkînin ji bo vekirina diyaloga Bibîne û Biguherîne .
- Di qutika Çi Bibîne de, yek ji hevbendiyên jêrîn têkevin:
- Ji bo rakirina nivîsê berî karaktereke danî , karaktera bi stêrkê (*char) tê binivîsin.
- Ji bo rakirina nivîsê piştî karaktereke diyar , karaktera li pey stêrkê binivîsin (char *).
- Ji bo jêbirina binerxeke di navbera du tîpan de, stêrkeke ku bi 2 tîpan hatiye dorpêçkirin (char*char) binivîse. Li şûna bi qutiya vala.
- Bikirtînin Hemûyan Biguherînin .
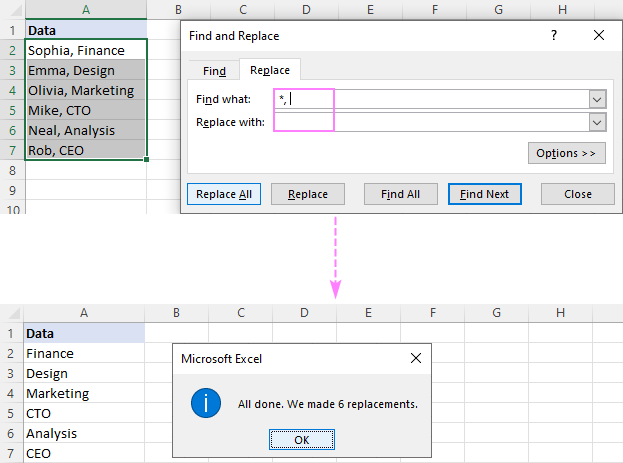
Mînakî, ji bo rakirina her tiştê ku piştî komê bi xwe jî têkelê, têxin bin nîrê û nîşana stêrkê (,*) di qutika Çi bibînin de, û hûn ê encama jêrîn bistînin:
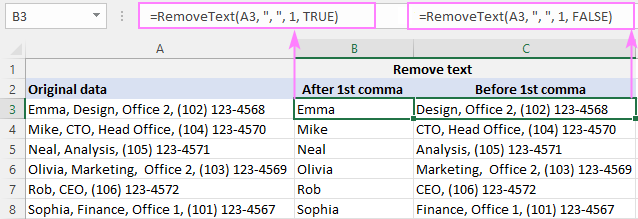
Ji bo jêbirina binerxek berî komê , stêrkê binivîsin, comma,Di A2-ê de her tişt piştî kommaya 1emîn, formula di B2 de ev e:
=RemoveText(A3, ", ", 1, TRUE)
Ji bo jêbirina her tiştê beriya koma 1mîn a A2, formula di C2 de ev e:
=RemoveText(A3, ", ", 1, FALSE)
Ji ber ku fonksiyona meya xwerû ji bo veqetankerê strek qebûl dike , em di argumana 2yemîn de kommayek û valahiyek (", ") danîne da ku ji tengasiya qutkirina cîhên sereke paşde xilas bibin.
Fonksiyonek meya xwerû bi xweşikî dixebite, ne wusa? Lê heke hûn difikirin ku ew çareseriyek berfireh e, we hîn mînaka din nedîtiye :)
Tiştê berî, paşî an di navbera karakteran de jêbikin
Ji bo ku hûn hê bêtir vebijarkan ji bo rakirina karakterên kesane an nivîsa ji çend şaneyan, li gorî hev an pozîsyonê, Suite Ultimate me li qutiya amûrê Excel-ê zêde bikin.
Li vir, em ê ji nêz ve li taybetmendiya Rakirin li gorî Position ya ku li ser ye binêre. 9>Ablebits Data tab > Text kom > Rake .
Li jêr, em ê her du senaryoyên herî berbelav.
Tiştê berî an piştî hin nivîsê rakin
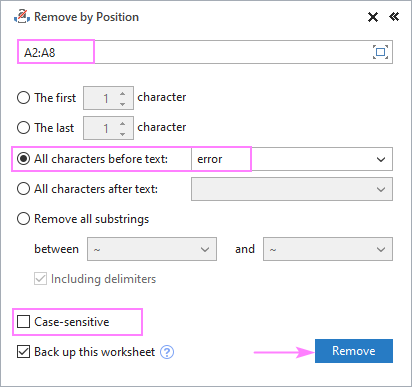
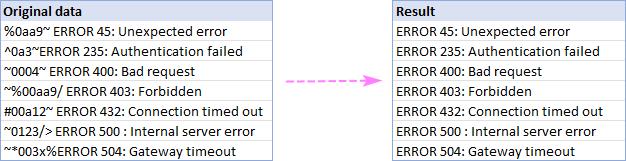
Bihesibînin ku hemî rêzikên çavkaniya we hin peyv an nivîsek hevpar dihewîne û hûn dixwazin her tiştê berî an piştî wê nivîsê jêbikin. Ji bo ku ew pêk were, daneya çavkaniya xwe hilbijêrin, amûra Rakirin bi Position bixebitînin û wê wekî ku li jêr tê xuyang kirin mîheng bikin:
- Hemû karakterên berî nivîsê hilbijêrin an jî Hemû tîpên piştî nivîsê vebijarkek û di qutîka pêş de nivîsa sereke (an karakter) binivîsin.ji bo wê.
- Li gor ka divê tîpên mezin û biçûk wek tîpên cuda bên nirxandin an jî wek heman tîpan bên nirxandin, qutiya hesas-qezenc bişopînin an rakin.
- Lêxin Rake .
Di vê nimûneyê de, em hemî tîpên berî peyva "çewtî" ya di hucreyên A2:A8:
Nivîsa di navbera du tîpan de rakin
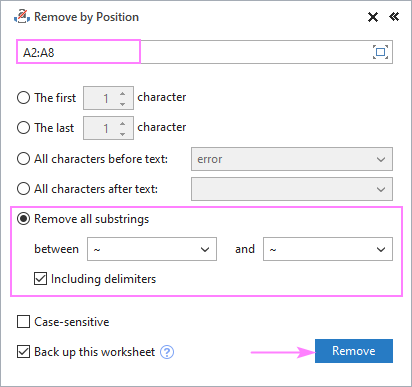
Di rewşek ku agahdariya negirêdayî di navbera 2 tîpan de be, li vir çawa ye. tu dikarî zû jê bibî:
- Hilbijêre Hemû binerdên jêbirin û du tîpan di qutikên jêrîn de binivîsin.
- Heke divê tîpên "navber" jî bên rakirin. , qutîka Têveqetandinên veqetandinê kontrol bikin.
- Bikirtînin Rake .
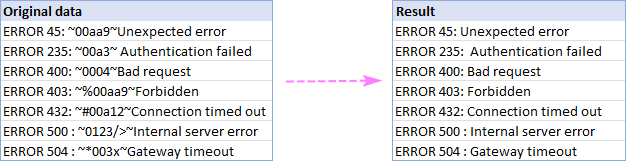
Wekî mînakek, em her tiştî di navbera du tîpên tilde (~) de jê dikin û di encamê de rêzikên bêkêmasî yên paqijkirî distînin:
Ji bo ceribandina taybetmendiyên din ên bikêr ên ku di vê pir-fonksîyonê de hene amûrek, ez ji we re teşwîq dikim ku hûn e-yek dakêşin guhertoya nirxandinê di dawiya vê postê de. Spas ji bo xwendinê û hêvî dikim ku hefteya pêş me we li ser bloga xwe bibînim!
Daxistinên berdest
Karekterên pêşîn an yên dawîn rakin - mînak (pelê .xlsm)
Suite Ultimate - guhertoya ceribandinê (pelê .exe)
û valahiyek (*, ) di çarçoveya Çi bibînede.Ji kerema xwe bala xwe bidin ku em ne tenê girseyek, lê koma û valahiyek diguherînin da ku pêşî lê neyê girtin. cihên di encama. Ger daneyên we bi qertafên bê valahî ji hev bên veqetandin, wê demê stêrkek li dû wê (*,) bi kar bînin.
Ji bo jêbirina nivîsê di navbera du koman de , stêrkeke ku bi qertaf (,*,) hatiye dorpêçkirin bi kar bîne.
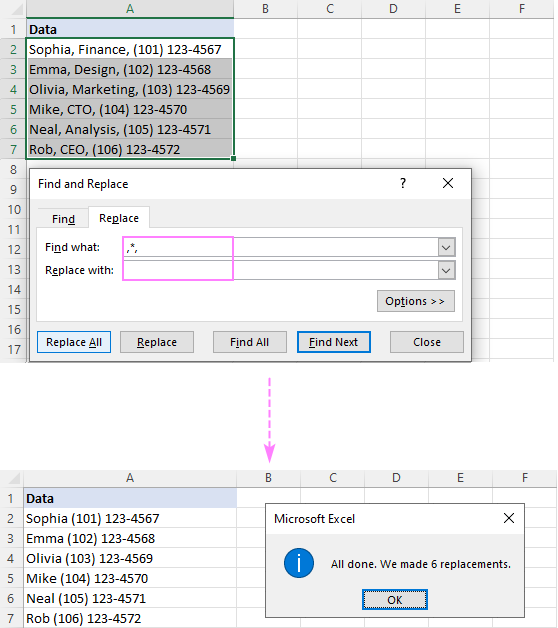
Şîret. Heger tu dixwazî nav û jimareyên têlefonê bi komoyê ji hev veqetînin, wê gavê di qada Li şûna de girseyek (,) binivîsin.
Parçeyek nivîsê bi karanîna Flash Fill rakin
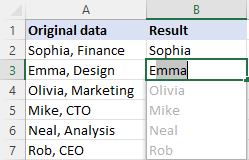
Di guhertoyên nûjen ên Excel (2013 û paşê de), rêyek din a hêsan heye ku meriv nivîsa ku li pêş an li dû karakterek taybetî ye ji holê rabike - taybetmendiya Flash Fill. Li vir çawa dixebite:
- Di şaneya li kêleka şaneya yekem a bi daneyên xwe de, encama çaverêkirî binivîsin û Enter bikirtînin.
- Di şaneya din de nirxek guncav binivîsînin. Dema ku Excel nimûneyê di nirxên ku hûn dinivîsin de hîs bike, ew ê pêşdîtinek ji bo şaneyên mayî yên li gorî heman şêwazê nîşan bide.
- Bişkojka Enter lêxin da ku pêşniyarê qebûl bikin.
Qediya!
Bi karanîna formulan nivîsê rakin
Di Microsoft Excel de, gelek manîpulasyonên daneyê yên ku bi karanîna taybetmendiyên hundurîn têne kirin jî dikarin bi formulek bêne kirin. Berevajî rêbazên berê, formula di daneyên orîjînal de ti guhertinan nakin û bêtir kontrolê didin weencaman.
Çawa meriv her tiştî piştî karakterek taybetî jê dike
Ji bo jêbirina nivîsê piştî karakterek taybetî, formula giştî ev e:
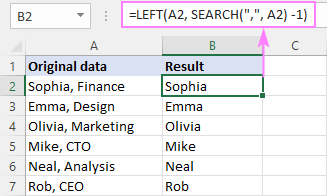
ÇEP( hucre , LÊGERÎN (" char ", hucre ) -1)Li vir, em fonksiyona SEARCH bikar tînin da ku pozîsyona karakterê bistînin û wê derbasî fonksiyona LEFT bikin, ji ber vê yekê ew derdixe. hejmara têkildar a tîpan ji destpêka rêzê. Karakterêk ji jimareya ku ji hêla SEARCH ve hatî vegerandin tê jêbirin da ku veqetandek ji encaman derxe.
Mînakî, ji bo rakirina beşek ji rêzek li dû komê, hûn formula jêrîn di B2-ê de têkevin û wê di nav B7-ê de kaş bikin. :
=LEFT(A2, SEARCH(",", A2) -1)
Çawa meriv her tiştî berî karakterek taybetî jê dike
Ji bo jêbirina beşek ji rêzika nivîsê berî karakterek diyarkirî, Formula giştî ev e:
RIGHT( hucre , LEN( hucre ) - SEARCH(" char ", hucre ))Li vir, em dîsa bi alîkariya SEARCH-ê pozîsyona karaktera armanc dihejmêrin, wê ji dirêjahiya rêza tevahî ya ku ji hêla LEN ve hatî vegerandin jê dikin, û cûdahiyê derbasî fonksiyona RIGHT dikin, ji ber vê yekê ew gelek tîpan ji dawiya tîpê derdixe. string.
Mînakî, ji bo rakirina nivîsê li ber komê, formula ev e:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
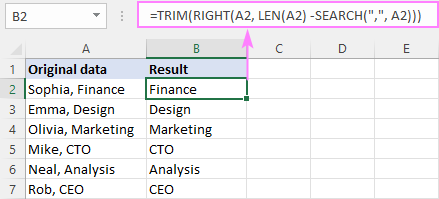
Di rewşa me de, li dû kommayê tîpek vala tê. Ji bo ku em di encaman de cîhên pêşeng dûr bixin, em formula bingehîn di fonksiyona TRIM de dipêçin:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
Nîşe:
- Herduji mînakên jorîn texmîn dikin ku di rêzika orîjînal de tenê yek nimûne veqetandinê heye. Ger gelek bûyer hebin, dê nivîs berî/piştî mînala yekem were jêbirin.
- Fonksiyon SEARCH ne hesas bi mezinbûnê ye , yanî ferq nake di navbera tîpên biçûk û mezin. Ger karaktera weya taybetî herfek e û hûn dixwazin qertafa tîpan ji hev cuda bikin, wê hingê li şûna SEARCH fonksiyona FIND bikar bînin.
Meriv çawa piştî bûyera N-emîn nivîsê jê bibe ji karakterekê
Di rewşekê de dema ku rêzika çavkaniyê gelek mînakên veqetandarê dihewîne, dibe ku hewcedariya we hebe ku hûn piştî mînakek taybetî nivîsê jê bikin. Ji bo vê, formula jêrîn bikar bînin:
LEFT( hucre , FIND("#", SUBSTITUTE( hucre , " char ", "#" , n )) -1)Li kuderê n rûdana karakterê ye ku piştî wê tê rakirin.
Mantiqa navxweyî ya vê formulê pêdivî bi karanîna hin karakteran heye. ku li tu derê di daneya çavkaniyê de tune ye, di doza me de sembolek hash (#). Ger ev karakter di berhevoka daneya we de cih bigire, wê hingê li şûna "#" tiştek din bikar bînin.
Mînakî, ji bo rakirina her tiştî piştî koma 2-mîn a A2-yê (û gireva xwe), formula ev e:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
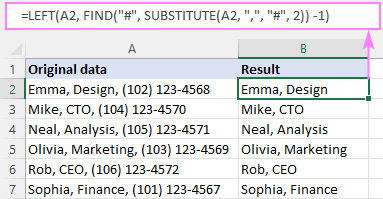
Ev formula çawa dixebite:
Beşê sereke yê formulê fonksiyona FIND e ku hesab dike helwesta nthveqetandek (di halê me de komo). Bi vî awayî ev e:
Em bi alîkariya SUBSTITUTE kommaya 2yemîn di A2 de bi nîşanek hash (an her karakterek din a ku di daneyên we de tune) diguhezînin:
SUBSTITUTE(A2, ",", "#", 2)
Rêja ku di encamê de diçe argumana 2yemîn ya FIND, ji ber vê yekê ew cîhê "#" di wê rêzê de dibîne:
FIND("#", "Emma, Design# (102) 123-4568")
FIND ji me re dibêje ku "#" karaktera 13emîn e. di rêzê de. Ji bo ku hûn hejmara tîpên berî wê bizanibin, tenê 1 jê derxin, û hûn ê di encamê de bibin 12:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
Ev hejmar rasterast diçe argumana num_chars ya LEFT jê dipirse ku 12 tîpên pêşîn ji A2 derxe:
=LEFT(A2, 12)
Ew e!
Meriv çawa nivîsê berî peydabûna N-mîn karakterekê jêbibe
Formula giştî ya rakirina binerêzek li ber karakterek diyar ev e:
RIGHT(SUBSTITUTE( hucre , " char ", "#", n ), LEN( hucre ) - FIND("#", SUBSTITUTE( hucre , " char ", "#", n )) -1)Mînakî, ji bo jêbirina nivîsê li ber kommaya 2yemîn a A2, formula ev e:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
Ji bo ji holê rakirina cîhek pêşeng, em dîsa TRIM bikar tînin. fonksiyona wekî pêçekê dike:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
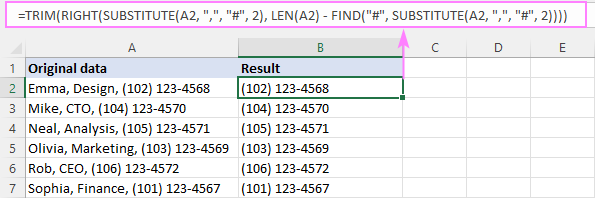
Ev formula çawa dixebite:
Bi kurtî, em fêr dibin çend tîp li dû veqetandeka n-ê ne û ji rastê xêzek bi dirêjahiya têkildar derxe. Li jêr formûla têkçûn e:
Pêşî, em di A2-ê de kommaya 2yemîn bi haş veguherînin.sembol:
SUBSTITUTE(A2, ",", "#", 2)
Rêça ku di encamê de diçe argumana RIGHT ya text :
RIGHT("Emma, Design# (102) 123-4568", …
Piştre, divê em diyar bike ka çend tîpan ji dawiya rêzê derxe. Ji bo vê yekê, em di rêza jorîn de cîhê nîşana hash (ku 13 ye) dibînin:
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
Û wê ji dirêjahiya rêzê ya giştî (ku dibe 28) jê derdixin:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
Cûdahî (15) diçe argumana duyemîn ya RIGHT û ferman dide ku di argumana yekem de 15 tîpên dawî ji rêzê derxe:
RIGHT("Emma, Design# (102) 123-4568", 15)
Derketin binerêzek "(102) 123-4568" e, ku pir nêzîkê encama tê xwestin e, ji bilî cîhek sereke. Ji ber vê yekê, em fonksiyona TRIM-ê bikar tînin da ku jê xilas bibin.
Çawa meriv piştî rûdana dawîn a karakterek nivîsê jê dike
Heke ku nirxên we bi jimareyek veqetandî veqetandî werin veqetandin, hûn dibe ku bixwaze piştî mînaka paşîn a wê veqetandinê her tiştî rake. Ev dikare bi formula jêrîn pêk were:
LEFT( hucre , FIND("#", SUBSTITUTE( hucre , " char ", "# ", LEN( hucre ) - LEN(SUBSTITUTE( hucre , " char ", "")))) -1)Berxwedan stûna A di derbarê karmendan de agahdariya cihêreng dihewîne, lê nirxa piştî koma paşîn her gav jimareyek têlefonê ye. Armanca we ew e ku hûn hejmarên têlefonê rakin û hemî hûrguliyên din bihêlin.
Ji bo ku hûn bigihîjin armancê, hûn dikarin bi vê yekê nivîsa piştî koma paşîn a di A2 de jêbikin.formula:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
Formulê li stûnê kopî bikin, û hûn ê vê encamê bistînin:

Ev çawa formula dixebite:
Gelê formulê ev e ku em di rêzê de pozîsyona veqetînera dawîn (komma) diyar dikin û binerxek ji çepê ber bi veqetandinê ve dikişînin. Girtina pozîsyona veqetandarê beşa herî dijwar e, û li vir çawa em wê bi rê ve dibin:
Pêşî, em fêhm dikin ku di rêzika orîjînal de çend komik hene. Ji bo vê yekê, em li şûna her commayê tiştek ("") diguhezînin û rêzika encam dide fonksiyona LEN-ê:
LEN(SUBSTITUTE(A2, ",",""))
Ji bo A2, encam 35 e, ku hejmara tîpan e. di A2 de bê commas.
Hejmara li jor ji dirêjahiya rêza giştî (38 tîp) derxînin:
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… û hûn ê bibin 3, ku hejmara giştî ye. ji qertafên di A2 de (û her weha jimara rêzî ya koma paşîn).
Piştre, hûn hevbendiya jixwe naskirî ya fonksiyonên FIND û SUBSTITUTE bikar tînin da ku pozîsyona koma paşîn a rêzikê bi dest bixin. Nimûneya nimûneyê (di rewşa me de kommaya 3yemîn) ji hêla formula LEN SUBSTITUTE ya jorîn ve hatî destnîşan kirin:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
Xuya ye ku koma 3mîn di A2 de karaktera 23mîn e, yanî em hewce ne ji bo derxistina 22 tîpên berî wê. Ji ber vê yekê, me formula jorîn kêm 1 di argumana num_chars ya LEFT de datîne:
LEFT(A2, 23-1)
Meriv çawa nivîsê berî rûdana dawîn a karakterekê jê dike
Ji bo jêbirinher tişt berî mînaka paşîn a karakterek taybetî, formula giştî ev e:
RIGHT( hucre , LEN( hucre ) - FIND("#", SUBSTITUTE( hucre , " char ", "#", LEN( hucre ) - LEN(SUBSTITUTE( hucre , " char ", "")))))Di tabloya meya nimûneyê de, ji bo ku metna berî kommaya dawîn ji holê rakin, formula vê formê digire:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
Wek destana dawîkirinê, em wê bixin nav fonksiyona TRIM-ê da ku cîhên pêşeng ji holê rakin:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
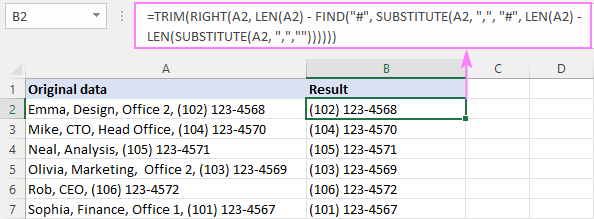
Ev formula çawa dixebite:
Bi kurtî, em pozîsyona koma paşîn a ku di mînaka berê de hate ravekirin distînin û wê ji dirêjahiya rêzê derdixin:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
Di encamê de, em jimara tîpên li dû kommaya paşîn û wê bigihînin fonksiyona RIGHT, ji ber vê yekê ew gelek tîpan ji dawiya rêzê derdixe.
Fonksiyonek kesane ji bo rakirina nivîsê li her du aliyên karakterekê
Wek we di mînakên jorîn de dîtiye, hûn dikarin hema hema her dozek bikar bînin bi karanîna f-ya xweya Excel-ê çareser bikin hevgirtinên di kombînasyona cuda de. Pirsgirêk ev e ku hûn hewce ne ku çend formulên dijwar bi bîr bînin. Hmm, heke em fonksiyona xwe binivîsin da ku hemî senaryoyan veşêrin? Dişibe fikreke baş. Ji ber vê yekê, koda VBA-ya jêrîn li pirtûka xweya xebatê zêde bikin (gavên hûrgulî ji bo têxistina VBA-yê li Excel li vir in):
Fonksiyon RemoveText(str Wek String, veqetandek Wek String, qewimîna Wek Tevjimar, is_piştî WekBoolean ) Dim delimiter_num, start_num, delimiter_len Wek Hejmara Tevahiya Dim str_result Wek String delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(cudakar) Ji bo i = 1 Ji bo rûdana delimiter_num = InStrpare, IfT, < delimiter_num Paşê start_num = delimiter_num + delimiter_len Dawî Ger Paşê i Ger 0 & lt; delimiter_num Dûv re Ger Rast = is_piştî Hingê str_result = Mid(str, 1, start_num - delimiter_len - 1) Wekî din str_result = Mid(str, start_num) Dawî Ger Biqede Heke RemoveText = str_result Fonksiyon DawîFonksiyon me bi navê RakirinText û hevoksaziya wê ya jêrîn heye:
RemoveText(rêzik, veqetandî, rûdan, piştî_ ye)Li ku:
String - rêzika nivîsê ya orîjînal e. Dikare bi referansek şaneyê were temsîl kirin.
Delimiter - karaktera berî/piştî ku nivîsê jê bibe.
Rûbûn - mînaka veqetanker.
Is_after - Nirxeke Boolean a ku nîşan dide ku li kîjan aliyê veqetandinê nivîsê jê bibe. Dikare bibe karakterek yek an rêzek tîpan.
- RAST - her tiştê piştî veqetandinê jêbibe (bi xwe veqetandek jî tê de).
- FALSE - her tiştê berî veqetandinê jêbibe (di nav de xwe veqetîne).
Dema ku koda fonksîyonê têxe pirtûka weya xebatê, hûn dikarin bi formûlên kompakt û xweş ji şaneyan binerxînin.
Mînakî, jêbirin
