
সুচিপত্র
সাম্প্রতিক কয়েকটি নিবন্ধে, আমরা এক্সেলের স্ট্রিং থেকে অক্ষরগুলি সরানোর বিভিন্ন উপায় দেখেছি। আজ, আমরা আরও একটি ব্যবহারের ক্ষেত্রে তদন্ত করব - কীভাবে একটি নির্দিষ্ট অক্ষরের আগে বা পরে সবকিছু মুছে ফেলতে হয়।
Find & Replace
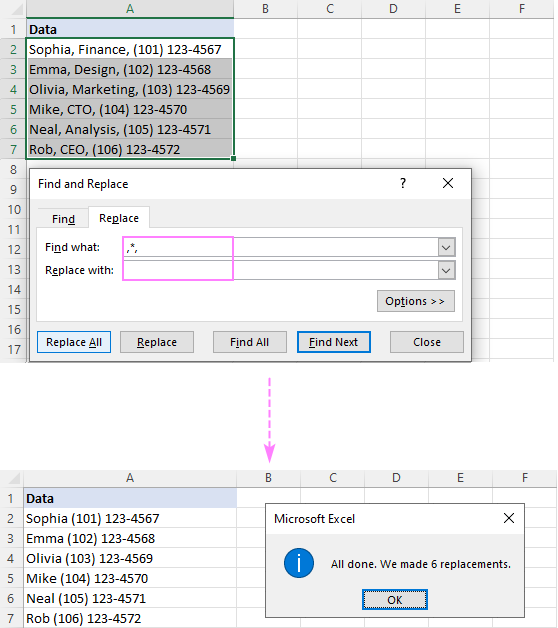
একাধিক কক্ষে ডেটা ম্যানিপুলেশনের জন্য, Find এবং Replace হল সঠিক টুল। একটি নির্দিষ্ট অক্ষরের পূর্বে বা অনুসরণ করা একটি স্ট্রিংয়ের অংশ মুছে ফেলার জন্য, এইগুলি সম্পাদন করার পদক্ষেপগুলি হল:
- যে সমস্ত ঘর আপনি পাঠ্য মুছতে চান সেগুলি নির্বাচন করুন৷
- Ctrl + H টিপুন খুঁজুন এবং প্রতিস্থাপন করুন ডায়ালগ খুলতে।
- কী খুঁজুন বক্সে, নিম্নলিখিত সমন্বয়গুলির মধ্যে একটি লিখুন:
- পাঠ্য নির্মূল করতে প্রদত্ত অক্ষরের আগে , একটি তারকাচিহ্নের পূর্বে অক্ষরটি টাইপ করুন (*char)।
- টেক্সট অপসারণ করতে একটি নির্দিষ্ট অক্ষরের পরে , একটি তারকাচিহ্ন (char) এর পরে অক্ষরটি টাইপ করুন *)।
- একটি সাবস্ট্রিং মুছে ফেলতে দুটি অক্ষরের মধ্যে , 2টি অক্ষর দ্বারা বেষ্টিত একটি তারকাচিহ্ন টাইপ করুন (char*char)।
- টি ছেড়ে দিন। প্রতিস্থাপন করুন বক্স খালি দিয়ে।
- ক্লিক করুন সব প্রতিস্থাপন করুন ।
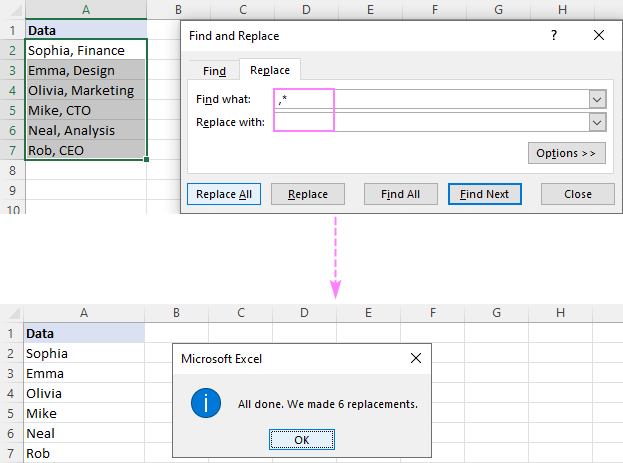
উদাহরণস্বরূপ, অপসারণ করতে একটি কমা পরে সবকিছু কমা সহ, একটি কমা এবং একটি তারকাচিহ্ন চিহ্ন (,*) কি খুঁজুন বক্সে রাখুন এবং আপনি নিম্নলিখিত ফলাফল পাবেন:
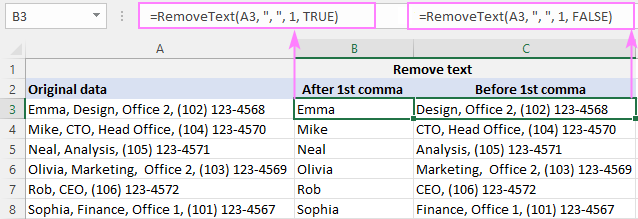
একটি সাবস্ট্রিং মুছতে কমার আগে , একটি তারকাচিহ্ন টাইপ করুন, একটি কমা,A2-তে 1ম কমার পরে সবকিছু, B2-এর সূত্র হল:
=RemoveText(A3, ", ", 1, TRUE)
A2-তে 1ম কমার আগে সবকিছু মুছে ফেলার জন্য, C2-এর সূত্র হল:
=RemoveText(A3, ", ", 1, FALSE)
যেহেতু আমাদের কাস্টম ফাংশন ডিলিমিটারের জন্য একটি স্ট্রিং গ্রহণ করে , আমরা ২য় আর্গুমেন্টে একটি কমা এবং একটি স্পেস (", ") রাখি যাতে পরবর্তীতে লিডিং স্পেস ট্রিম করার ঝামেলা এড়ানো যায়।
আমাদের কাস্টম ফাংশন সুন্দরভাবে কাজ করে, তাই না? কিন্তু আপনি যদি মনে করেন এটি ব্যাপক সমাধান, আপনি এখনও পরবর্তী উদাহরণটি দেখেননি :)
অক্ষরের আগে, পরে বা অক্ষরের মধ্যে সবকিছু মুছুন
স্বতন্ত্র অক্ষরগুলি সরানোর জন্য আরও বেশি বিকল্প পেতে বা একাধিক কক্ষ থেকে পাঠ্য, মিল বা অবস্থান অনুসারে, আপনার এক্সেল টুলবক্সে আমাদের আলটিমেট স্যুট যোগ করুন।
এখানে, আমরা অবস্থান অনুসারে সরান বৈশিষ্ট্যটি ঘনিষ্ঠভাবে দেখব যা Ablebits Data ট্যাব > টেক্সট গ্রুপ > সরান ।
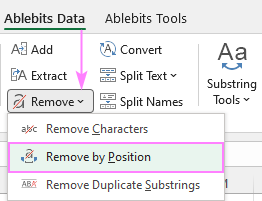
নীচে, আমরা দুটি কভার করব সবচেয়ে সাধারণ পরিস্থিতি।
নির্দিষ্ট পাঠ্যের আগে বা পরে সবকিছু সরান
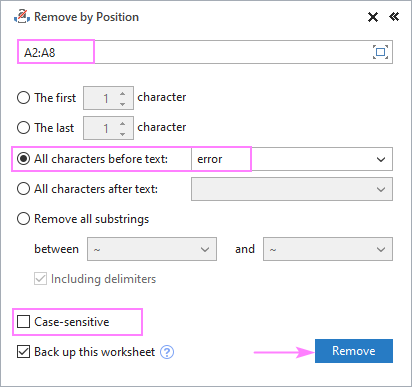
ধরুন আপনার সমস্ত উৎস স্ট্রিং-এ কিছু সাধারণ শব্দ বা পাঠ্য রয়েছে এবং আপনি সেই পাঠ্যের আগে বা পরে সবকিছু মুছে ফেলতে চান। এটি সম্পন্ন করার জন্য, আপনার উত্স ডেটা নির্বাচন করুন, অবস্থান অনুসারে সরান টুলটি চালান এবং নীচে দেখানো মত এটি কনফিগার করুন:
- টেক্সটের আগে সমস্ত অক্ষর নির্বাচন করুন অথবা টেক্সটের পরে সমস্ত অক্ষর বিকল্পটি এবং পরবর্তী বক্সে কী পাঠ্য (বা অক্ষর) টাইপ করুনএটিতে৷
- বড় হাতের অক্ষর এবং ছোট হাতের অক্ষরগুলিকে আলাদা বা একই অক্ষর হিসাবে বিবেচনা করা উচিত কিনা তার উপর নির্ভর করে, কেস-সংবেদনশীল বক্সটি চেক বা আনচেক করুন৷
- <9 টিপুন>মুছে ফেলুন ।
এই উদাহরণে, আমরা A2:A8:
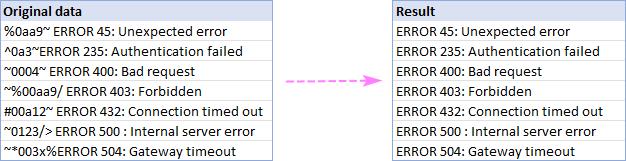
দুটি অক্ষরের মধ্যবর্তী টেক্সট মুছে ফেলুন
অপ্রাসঙ্গিক তথ্য যখন 2টি নির্দিষ্ট অক্ষরের মধ্যে থাকে, তখন এখানে কীভাবে আপনি দ্রুত এটি মুছে ফেলতে পারেন:
- পছন্দ করুন সমস্ত সাবস্ট্রিংগুলি সরান এবং নীচের বাক্সে দুটি অক্ষর টাইপ করুন৷
- যদি "মাঝখানে" অক্ষরগুলিও সরানো উচিত , ডিলিমিটার সহ বক্সে চেক করুন।
- সরান ক্লিক করুন।
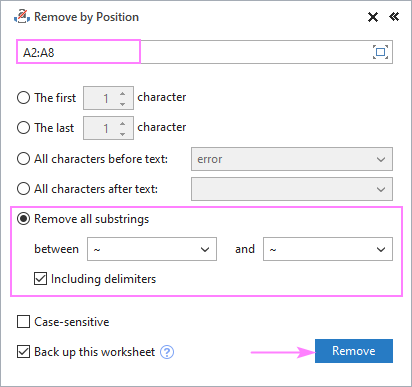
এভাবে একটি উদাহরণ, আমরা দুটি টিল্ড অক্ষর (~) এর মধ্যে সবকিছু মুছে ফেলি এবং ফলাফল হিসাবে পুরোপুরি পরিষ্কার স্ট্রিংগুলি পাই:
এই মাল্টি-ফাংশনালের সাথে অন্তর্ভুক্ত অন্যান্য দরকারী বৈশিষ্ট্যগুলি চেষ্টা করার জন্য টুল, আমি আপনাকে একটি ই ডাউনলোড করতে উত্সাহিত করি এই পোস্টের শেষে মূল্যায়ন সংস্করণ। পড়ার জন্য আপনাকে ধন্যবাদ এবং আশা করি আগামী সপ্তাহে আমাদের ব্লগে দেখা হবে!
উপলব্ধ ডাউনলোড
প্রথম বা শেষ অক্ষরগুলি সরান - উদাহরণ (.xlsm ফাইল)
আলটিমেট স্যুট - ট্রায়াল সংস্করণ (.exe ফাইল)
এবং কি খুঁজে বের করুনবক্সে একটি স্পেস (*, )৷দয়া করে লক্ষ্য করুন যে আমরা শুধুমাত্র একটি কমা নয় বরং একটি কমা এবং একটি স্থান প্রতিস্থাপন করছি লিডিং প্রতিরোধ করতে ফলাফলে শূন্যস্থান। যদি আপনার ডেটা স্পেস ছাড়াই কমা দ্বারা পৃথক করা হয়, তাহলে একটি কমা (*,) দ্বারা অনুসরণ করে একটি তারকাচিহ্ন ব্যবহার করুন।
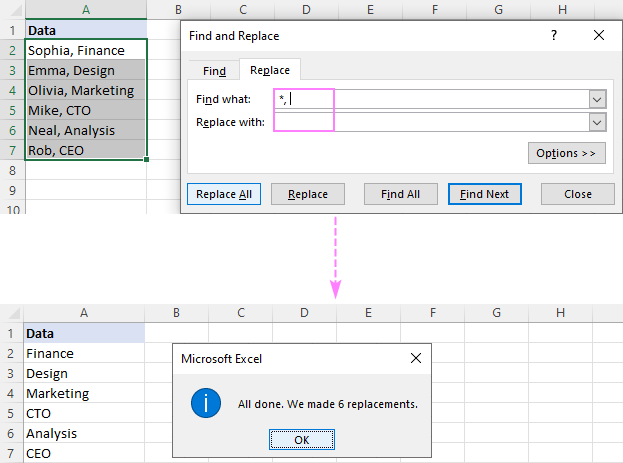
টেক্সট মুছে ফেলতে দুটি কমার মধ্যে , কমা (,*,) দ্বারা বেষ্টিত একটি তারকাচিহ্ন ব্যবহার করুন।
টিপ। আপনি যদি নাম এবং ফোন নম্বরগুলিকে কমা দ্বারা আলাদা করতে চান, তাহলে প্রতিস্থাপন ক্ষেত্রে একটি কমা (,) টাইপ করুন।
ফ্ল্যাশ ফিল ব্যবহার করে পাঠ্যের কিছু অংশ সরান
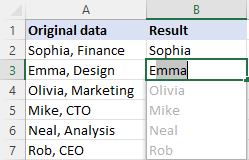
এক্সেলের আধুনিক সংস্করণে (2013 এবং পরবর্তী), একটি নির্দিষ্ট অক্ষরের আগে বা অনুসরণ করা পাঠ্য মুছে ফেলার আরও একটি সহজ উপায় রয়েছে - ফ্ল্যাশ ফিল বৈশিষ্ট্য। এটি কীভাবে কাজ করে তা এখানে:
- আপনার ডেটা সহ প্রথম ঘরের পাশের একটি ঘরে, প্রত্যাশিত ফলাফল টাইপ করুন এবং এন্টার টিপুন।
- পরবর্তী ঘরে একটি উপযুক্ত মান টাইপ করা শুরু করুন। একবার Excel আপনার প্রবেশ করা মানগুলির প্যাটার্নটি অনুভব করলে, এটি একই প্যাটার্ন অনুসরণ করে অবশিষ্ট কক্ষগুলির জন্য একটি পূর্বরূপ প্রদর্শন করবে৷
- পরামর্শটি গ্রহণ করতে এন্টার কী টিপুন৷
সম্পন্ন!
সূত্র ব্যবহার করে পাঠ্য সরান
মাইক্রোসফট এক্সেলে, ইনবিল্ট বৈশিষ্ট্যগুলি ব্যবহার করে সঞ্চালিত অনেক ডেটা ম্যানিপুলেশনগুলিও একটি সূত্র দিয়ে সম্পন্ন করা যেতে পারে। পূর্ববর্তী পদ্ধতিগুলির বিপরীতে, সূত্রগুলি মূল ডেটাতে কোনও পরিবর্তন করে না এবং আপনাকে আরও নিয়ন্ত্রণ দেয়ফলাফল।
একটি নির্দিষ্ট অক্ষরের পরে সবকিছু কীভাবে সরিয়ে ফেলা যায়
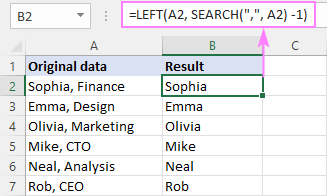
একটি নির্দিষ্ট অক্ষরের পরে পাঠ্য মুছে ফেলার জন্য, জেনেরিক সূত্রটি হল:
বাম( সেল , অনুসন্ধান করুন (" char ", cell ) -1)এখানে, আমরা অক্ষরের অবস্থান পেতে SEARCH ফাংশন ব্যবহার করি এবং এটিকে বাম ফাংশনে পাস করি, তাই এটি নিষ্কাশন করে স্ট্রিং এর শুরু থেকে অক্ষরের অনুরূপ সংখ্যা। ফলাফল থেকে বিভেদক বাদ দিতে SEARCH দ্বারা প্রত্যাবর্তিত সংখ্যা থেকে একটি অক্ষর বিয়োগ করা হয়৷
উদাহরণস্বরূপ, একটি কমা পরে একটি স্ট্রিংয়ের অংশ সরাতে, আপনি B2-এ নীচের সূত্রটি প্রবেশ করান এবং এটিকে B7 এর মাধ্যমে নীচে টেনে আনুন :
=LEFT(A2, SEARCH(",", A2) -1)
কীভাবে একটি নির্দিষ্ট অক্ষরের আগে সবকিছু মুছে ফেলা যায়
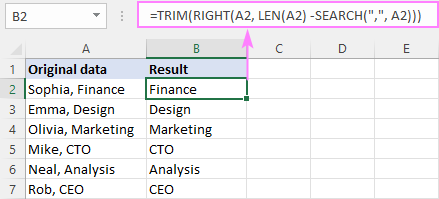
একটি নির্দিষ্ট অক্ষরের আগে একটি পাঠ্য স্ট্রিংয়ের অংশ মুছে ফেলার জন্য, জেনেরিক সূত্র হল:
RIGHT( cell , LEN( cell ) - SEARCH(" char ", cell ))এখানে, আমরা আবার SEARCH এর সাহায্যে টার্গেট ক্যারেক্টারের অবস্থান গণনা করি, LEN দ্বারা প্রত্যাবর্তিত মোট স্ট্রিং দৈর্ঘ্য থেকে এটি বিয়োগ করি, এবং পার্থক্যটিকে RIGHT ফাংশনে পাস করি, যাতে এটি অনেকগুলি অক্ষর টেনে নিয়ে যায় স্ট্রিং।
উদাহরণস্বরূপ, একটি কমার আগে টেক্সট মুছে ফেলার জন্য, সূত্রটি হল:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
আমাদের ক্ষেত্রে, কমা একটি স্পেস অক্ষর দ্বারা অনুসরণ করা হয়। ফলাফলে অগ্রণী স্থানগুলি এড়াতে, আমরা TRIM ফাংশনে মূল সূত্রটি মোড়ানো:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
নোট:
- উভয়উপরের উদাহরণগুলির মধ্যে অনুমান করা হয়েছে যে মূল স্ট্রিংটিতে শুধুমাত্র একটি উদাহরণ রয়েছে। একাধিক ঘটনা ঘটলে, প্রথম উদাহরণ এর আগে/পরে পাঠ্য মুছে ফেলা হবে।
- সার্চ ফাংশনটি কেস-সংবেদনশীল নয় , অর্থাৎ এটির মধ্যে কোন পার্থক্য করে না ছোট হাতের এবং বড় হাতের অক্ষর। যদি আপনার নির্দিষ্ট অক্ষরটি একটি অক্ষর হয় এবং আপনি অক্ষরের ক্ষেত্রে পার্থক্য করতে চান, তাহলে অনুসন্ধানের পরিবর্তে কেস-সংবেদনশীল FIND ফাংশনটি ব্যবহার করুন।
Nth ঘটনার পরে কীভাবে পাঠ্য মুছবেন একটি অক্ষরের
পরিস্থিতিতে যখন একটি উৎস স্ট্রিং-এ ডিলিমিটারের একাধিক দৃষ্টান্ত থাকে, আপনাকে একটি নির্দিষ্ট উদাহরণের পরে পাঠ্য অপসারণ করতে হতে পারে। এর জন্য, নিম্নলিখিত সূত্রটি ব্যবহার করুন:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "#" , n )) -1)যেখানে n অক্ষরের উপস্থিতি যার পরে টেক্সট সরাতে হবে।
এই সূত্রের অভ্যন্তরীণ যুক্তিতে কিছু অক্ষর ব্যবহার করা প্রয়োজন যেটি সোর্স ডেটার কোথাও উপস্থিত নেই, আমাদের ক্ষেত্রে একটি হ্যাশ চিহ্ন (#)। যদি এই অক্ষরটি আপনার ডেটা সেটে দেখা যায়, তাহলে "#" এর পরিবর্তে অন্য কিছু ব্যবহার করুন।
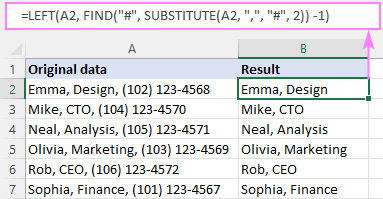
উদাহরণস্বরূপ, A2 তে 2য় কমা (এবং কমা নিজেই) এর পরে সবকিছু মুছে ফেলার জন্য সূত্রটি হল:<1
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
এই সূত্রটি কীভাবে কাজ করে:
সূত্রের মূল অংশ হল FIND ফাংশন যা গণনা করে nম অবস্থানডিলিমিটার (আমাদের ক্ষেত্রে কমা)। এখানে কিভাবে:
আমরা SUBSTITUTE এর সাহায্যে A2-এ ২য় কমাকে হ্যাশ চিহ্ন দিয়ে প্রতিস্থাপন করি (অথবা অন্য কোনো অক্ষর যা আপনার ডেটাতে বিদ্যমান নেই) এর সাহায্যে:
SUBSTITUTE(A2, ",", "#", 2)
ফলে স্ট্রিংটি FIND-এর 2য় আর্গুমেন্টে যায়, তাই এটি সেই স্ট্রিংটিতে "#" এর অবস্থান খুঁজে পায়:
FIND("#", "Emma, Design# (102) 123-4568")
FIND আমাদের বলে যে "#" হল 13 তম অক্ষর। স্ট্রিং মধ্যে এটির পূর্ববর্তী অক্ষরের সংখ্যা জানতে, শুধুমাত্র 1 বিয়োগ করুন, এবং ফলাফল হিসাবে আপনি 12 পাবেন:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
এই সংখ্যাটি সরাসরি সংখ্যা_অক্ষর আর্গুমেন্টে যায় বাম থেকে এটিকে A2 থেকে প্রথম 12টি অক্ষর টেনে আনতে বলছে:
=LEFT(A2, 12)
এটাই!
একটি অক্ষরের Nth উপস্থিতির আগে কীভাবে পাঠ্য মুছবেন
একটি নির্দিষ্ট অক্ষরের আগে একটি সাবস্ট্রিং অপসারণের জেনেরিক সূত্র হল:
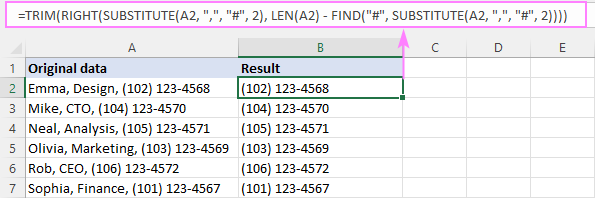
RIGHT(SUBSTITUTE( cell , " char ", "#", n ), LEN( cell ) - FIND("#", SUBSTITUTE( cell , " char ", "#", n )) -1)উদাহরণস্বরূপ, A2-তে ২য় কমার আগে টেক্সট বন্ধ করতে, সূত্রটি হল:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
একটি অগ্রণী স্থান বাদ দিতে, আমরা আবার TRIM ব্যবহার করি একটি মোড়ক হিসাবে কাজ করে:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
এই সূত্রটি কীভাবে কাজ করে:
সংক্ষেপে, আমরা খুঁজে পাই nম ডিলিমিটারের পরে কয়টি অক্ষর আছে এবং ডান থেকে সংশ্লিষ্ট দৈর্ঘ্যের একটি সাবস্ট্রিং বের করুন। নিচে ফর্মুলা ব্রেক ডাউন দেওয়া হল:
প্রথম, আমরা A2-এ ২য় কমা হ্যাশ দিয়ে প্রতিস্থাপন করিচিহ্ন:
SUBSTITUTE(A2, ",", "#", 2)
ফলে স্ট্রিংটি ডানের টেক্সট আর্গুমেন্টে যায়:
RIGHT("Emma, Design# (102) 123-4568", …
এর পরে, আমাদের করতে হবে স্ট্রিংয়ের শেষ থেকে কতগুলি অক্ষর বের করতে হবে তা নির্ধারণ করুন। এর জন্য, আমরা উপরের স্ট্রিং-এ হ্যাশ চিহ্নের অবস্থান খুঁজে পাই (যা 13):
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
এবং মোট স্ট্রিং দৈর্ঘ্য থেকে এটি বিয়োগ করুন (যা 28 এর সমান):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
পার্থক্যটি (15) রাইট-এর দ্বিতীয় আর্গুমেন্টে যায় যা প্রথম আর্গুমেন্টের স্ট্রিং থেকে শেষ 15টি অক্ষর টেনে আনতে নির্দেশ দেয়:
RIGHT("Emma, Design# (102) 123-4568", 15)
আউটপুট হল একটি সাবস্ট্রিং " (102) 123-4568", যা একটি অগ্রণী স্থান ছাড়া পছন্দসই ফলাফলের খুব কাছাকাছি। সুতরাং, আমরা এটি থেকে পরিত্রাণ পেতে TRIM ফাংশন ব্যবহার করি।
কীভাবে একটি অক্ষরের শেষ উপস্থিতির পরে টেক্সট সরাতে হয়
যদি আপনার মানগুলি পরিবর্তনশীল সংখ্যার সীমানা দিয়ে আলাদা করা হয়, আপনি সেই ডিলিমিটারের শেষ উদাহরণের পরে সবকিছু মুছে ফেলতে চাইতে পারে। এটি নিম্নলিখিত সূত্র দিয়ে করা যেতে পারে:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "# ", LEN( cell ) - LEN(SUBSTITUTE( cell , " char ", "")))) -1)ধরুন কলাম A কর্মীদের সম্পর্কে বিভিন্ন তথ্য রয়েছে, কিন্তু শেষ কমা পরে মান সর্বদা একটি টেলিফোন নম্বর। আপনার লক্ষ্য হল ফোন নম্বরগুলি সরানো এবং অন্যান্য সমস্ত বিবরণ রাখা৷
লক্ষ্যটি অর্জন করতে, আপনি এটির সাহায্যে A2 এ শেষ কমাটির পরে পাঠ্য সরাতে পারেনসূত্র:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
কলামের নিচে সূত্রটি অনুলিপি করুন এবং আপনি এই ফলাফলটি পাবেন:

এটি কীভাবে সূত্র কাজ করে:
সূত্রটির সারমর্ম হল যে আমরা স্ট্রিং-এ শেষ ডিলিমিটারের (কমা) অবস্থান নির্ধারণ করি এবং একটি সাবস্ট্রিংকে বাম থেকে ডিলিমিটার পর্যন্ত টেনে আনি। ডিলিমিটারের অবস্থান পাওয়া সবচেয়ে জটিল অংশ, এবং এখানে আমরা কীভাবে এটি পরিচালনা করি:
প্রথম, আমরা আসল স্ট্রিংটিতে কতগুলি কমা আছে তা খুঁজে বের করি। এর জন্য, আমরা প্রতিটি কমাকে কিছুই ("") দিয়ে প্রতিস্থাপন করি এবং ফলস্বরূপ স্ট্রিংটি LEN ফাংশনে পরিবেশন করি:
LEN(SUBSTITUTE(A2, ",",""))
A2-এর জন্য, ফলাফল হল 35, যা অক্ষরের সংখ্যা। A2 এ কমা ছাড়া।
মোট স্ট্রিং দৈর্ঘ্য (38 অক্ষর) থেকে উপরের সংখ্যাটি বিয়োগ করুন:
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… এবং আপনি 3 পাবেন, যা মোট সংখ্যা A2-এ কমা (এবং শেষ কমার ক্রমিক সংখ্যাও)।
এরপর, আপনি স্ট্রিং-এ শেষ কমার অবস্থান পেতে FIND এবং SUBSTITUTE ফাংশনগুলির ইতিমধ্যে পরিচিত সমন্বয় ব্যবহার করুন। ইনস্ট্যান্স নম্বর (আমাদের ক্ষেত্রে 3য় কমা) উপরে উল্লিখিত LEN সাবস্টিটিউট সূত্র দ্বারা সরবরাহ করা হয়েছে:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
এটা দেখা যাচ্ছে যে 3য় কমা হল A2 এর 23 তম অক্ষর, যার অর্থ আমাদের প্রয়োজন এটির আগের 22টি অক্ষর বের করতে। সুতরাং, আমরা উপরের সূত্রটি বিয়োগ 1 টি num_chars LEFT-এর আর্গুমেন্টে রাখি:
LEFT(A2, 23-1)
কীভাবে একটি অক্ষরের শেষ উপস্থিতির আগে টেক্সট সরাতে হয়
মুছে ফেলার জন্যএকটি নির্দিষ্ট অক্ষরের শেষ উদাহরণের আগে সবকিছু, জেনেরিক সূত্র হল:
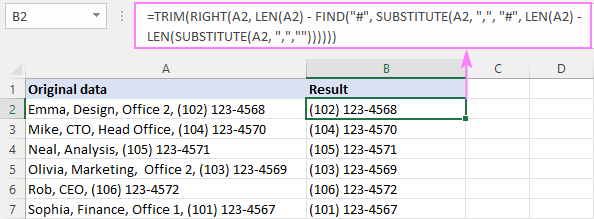
RIGHT( cell , LEN( cell ) - FIND("#", SUBSTITUTE( cell , " char ", "#", LEN( cell ) - LEN(SUBSTITUTE( cell , " char ", "")))))আমাদের নমুনা টেবিলে, শেষ কমার আগে পাঠ্য মুছে ফেলার জন্য, সূত্রটি এই ফর্মটি নেয়:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
একটি সমাপ্তি স্পর্শ হিসাবে, আমরা লিডিং স্পেস বাদ দিতে এটিকে TRIM ফাংশনে নেস্ট করুন:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
এই সূত্রটি কীভাবে কাজ করে:
সংক্ষেপে, আমরা আগের উদাহরণে ব্যাখ্যা করা শেষ কমাটির অবস্থান পাই এবং স্ট্রিংটির মোট দৈর্ঘ্য থেকে এটি বিয়োগ করি:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
এর ফলে, আমরা সংখ্যাটি পাই শেষ কমা পরে অক্ষর এবং এটি RIGHT ফাংশনে পাস করে, তাই এটি স্ট্রিংয়ের শেষ থেকে অনেকগুলি অক্ষর নিয়ে আসে।
একটি অক্ষরের উভয় পাশের পাঠ্য মুছে ফেলার জন্য কাস্টম ফাংশন
যেমন আপনি উপরের উদাহরণগুলিতে দেখেছেন, আপনি এক্সেলের নেটিভ f ব্যবহার করে প্রায় কোনও ব্যবহারের ক্ষেত্রে সমাধান করতে পারেন বিভিন্ন সমন্বয়ে unctions. সমস্যা হল যে আপনাকে মুষ্টিমেয় জটিল সূত্র মনে রাখতে হবে। হুম, যদি আমরা সমস্ত পরিস্থিতি কভার করার জন্য আমাদের নিজস্ব ফাংশন লিখি? একটি ভাল ধারণার মতই শোনাচ্ছে। সুতরাং, আপনার ওয়ার্কবুকে নিম্নলিখিত VBA কোড যোগ করুন (এক্সেলে VBA সন্নিবেশ করার বিস্তারিত পদক্ষেপগুলি এখানে রয়েছে):
ফাংশন রিমোভ টেক্সট(স্ট্রিং হিসাবে স্ট্রিং , ডিলিমিটার হিসাবে স্ট্রিং , পূর্ণসংখ্যা হিসাবে , is_after Asবুলিয়ান ) Dim delimiter_num, start_num, delimiter_len পূর্ণসংখ্যা হিসাবে Dim str_result হিসাবে স্ট্রিং delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(delimiter) i = 1 ঘটানোর জন্য delimiter_num,T_art_num,Text_num,Text_num,Text_num,Text_num,Text. < delimiter_num তারপর start_num = delimiter_num + delimiter_len শেষ হলে পরবর্তী i যদি 0 < delimiter_num তারপর যদি True = is_after তাহলে str_result = Mid(str, 1, start_num - delimiter_len - 1) অন্যথায় str_result = Mid(str, start_num) End If End যদি RemoveText = str_result শেষ ফাংশনআমাদের ফাংশনটির নাম টি এবং এটিতে নিম্নলিখিত সিনট্যাক্স রয়েছে:
RemoveText(string, delimiter,ccence, is_after)কোথায়:
স্ট্রিং - হল আসল টেক্সট স্ট্রিং। একটি সেল রেফারেন্স দ্বারা প্রতিনিধিত্ব করা যেতে পারে।
ডিলিমিটার - টেক্সট মুছে ফেলার আগে/পরে অক্ষর।
ঘটনা - এর উদাহরণ ডিলিমিটার৷
Is_after - একটি বুলিয়ান মান যা নির্দেশ করে যে বিভাজনকারীর কোন দিকে পাঠ্য অপসারণ করতে হবে৷ একটি একক অক্ষর বা অক্ষরগুলির একটি ক্রম হতে পারে৷
- সত্য - বিভাজনের পরে সবকিছু মুছুন (বিভেদক সহ)৷
- মিথ্যা - বিভাজনের আগে সবকিছু মুছুন (সহ ডিলিমিটার নিজেই।
আপনার ওয়ার্কবুকে একবার ফাংশনের কোড ঢোকানো হয়ে গেলে, আপনি কমপ্যাক্ট এবং মার্জিত সূত্র ব্যবহার করে সেল থেকে সাবস্ট্রিংগুলি সরাতে পারেন।
উদাহরণস্বরূপ, মুছে ফেলার জন্য
