
목차
최근 몇 개의 기사에서는 Excel에서 문자열에서 문자를 제거하는 다양한 방법을 살펴보았습니다. 오늘은 특정 문자 앞이나 뒤의 모든 것을 삭제하는 사용 사례를 하나 더 살펴보겠습니다.
Find & 바꾸기
여러 셀에서 데이터를 조작하려면 찾기 및 바꾸기가 올바른 도구입니다. 특정 문자 앞이나 뒤의 문자열 부분을 제거하려면 다음 단계를 수행하십시오.
- 텍스트를 삭제할 모든 셀을 선택합니다.
- Ctrl + H를 누릅니다. 찾기 및 바꾸기 대화 상자를 엽니다.
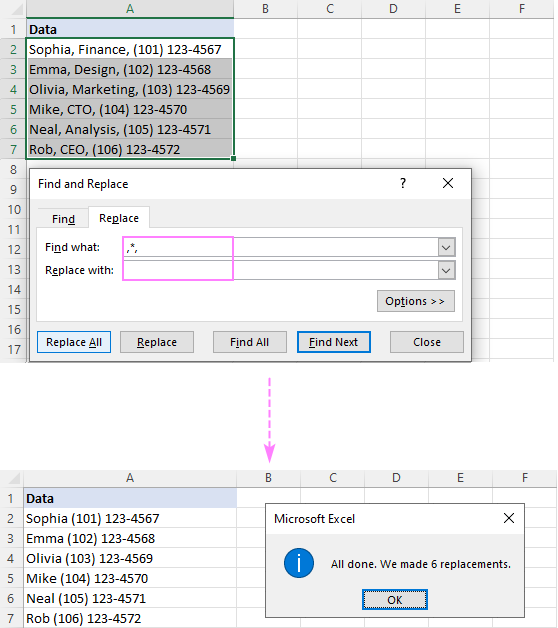
- 찾을 내용 상자에 다음 조합 중 하나를 입력합니다.
- 텍스트 제거 특정 문자 앞에 별표(*char)가 붙은 문자를 입력하십시오.
- 특정 문자 뒤의 텍스트를 제거하려면 뒤에 별표(char)가 붙은 문자를 입력하십시오. *).
- 하위 문자열 두 문자 사이 를 삭제하려면 별표를 두 문자로 묶습니다(char*char).
- 그대로 둡니다. 바꾸기 상자가 비어 있습니다.
- 모두 바꾸기 를 클릭합니다.
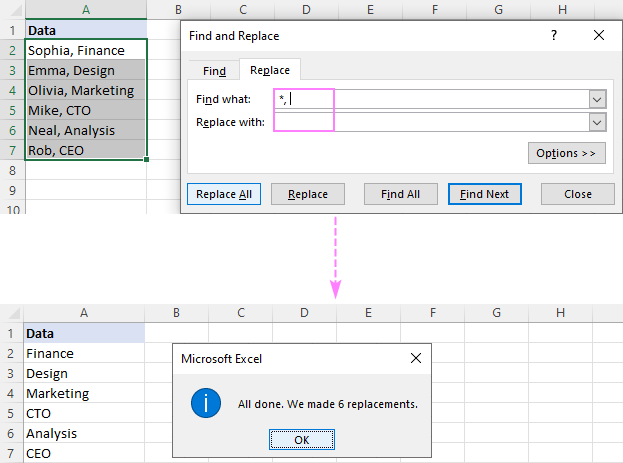
예를 들어 을 제거하려면 쉼표 자체를 포함하여 쉼표 뒤의 모든 항목을 찾을 내용 상자에 쉼표와 별표 기호(,*)를 넣으면 다음과 같은 결과가 나타납니다.
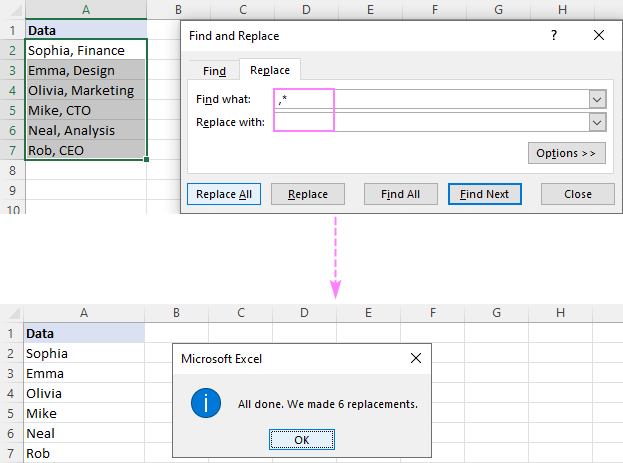
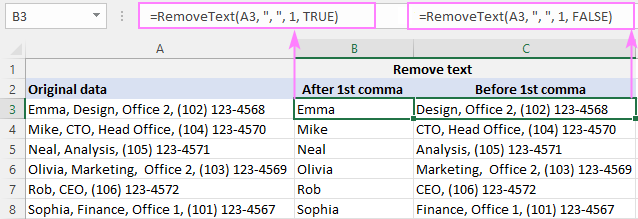
콤마 앞의 하위 문자열 을 삭제하려면 별표를 입력하십시오. 쉼표,A2에서 첫 번째 쉼표 뒤의 모든 것, B2의 수식:
=RemoveText(A3, ", ", 1, TRUE)
A2에서 첫 번째 쉼표 앞의 모든 것을 삭제하려면 C2의 수식:
=RemoveText(A3, ", ", 1, FALSE)
우리의 사용자 정의 함수는 구분 기호 에 대해 문자열을 허용하므로 나중에 선행 공백을 자르는 수고를 덜기 위해 두 번째 인수에 쉼표와 공백(", ")을 넣습니다.
저희 맞춤 기능이 정말 잘 작동하죠? 그러나 이것이 포괄적인 솔루션이라고 생각한다면 아직 다음 예를 보지 못한 것입니다 :)
문자 앞, 뒤 또는 사이의 모든 항목 삭제
개별 문자 또는 여러 셀의 텍스트를 일치 또는 위치별로 Excel 도구 상자에 추가하세요.
여기서 위치별 제거 기능에 대해 자세히 살펴보겠습니다. 9>Ablebits 데이터 탭 > 텍스트 그룹 > 제거 .
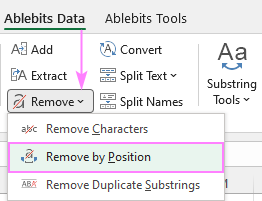
아래에서 두 가지를 다룰 것입니다. 가장 일반적인 시나리오입니다.
특정 텍스트 앞이나 뒤의 모든 항목 제거
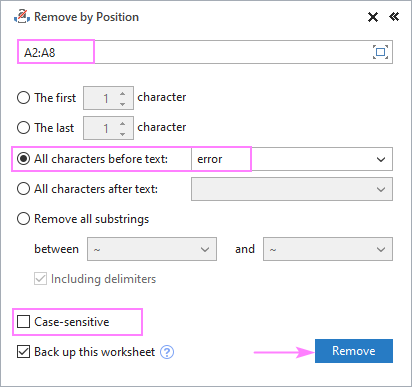
모든 소스 문자열에 일반적인 단어나 텍스트가 포함되어 있고 해당 텍스트 앞이나 뒤의 모든 항목을 삭제하려고 한다고 가정합니다. 이를 수행하려면 소스 데이터를 선택하고 위치별 제거 도구를 실행하고 아래와 같이 구성합니다.
- 텍스트 앞의 모든 문자<10 선택> 또는 텍스트 뒤의 모든 문자 옵션을 선택하고 다음 상자에 핵심 텍스트(또는 문자)를 입력합니다.
- 대소문자를 다르게 취급해야 하는지 같은 문자로 취급해야 하는지에 따라 대소문자 구분 상자를 선택하거나 선택 취소합니다.
- <9를 누르세요>Remove .
이 예에서는 A2:A8:
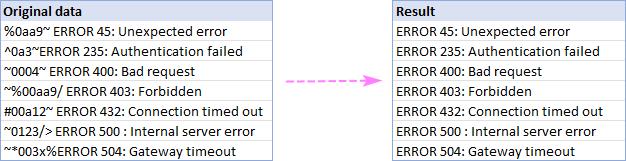
두 문자 사이의 텍스트 제거
관련 없는 정보가 두 특정 문자 사이에 있는 상황에서 방법은 다음과 같습니다. 빠르게 삭제할 수 있습니다:
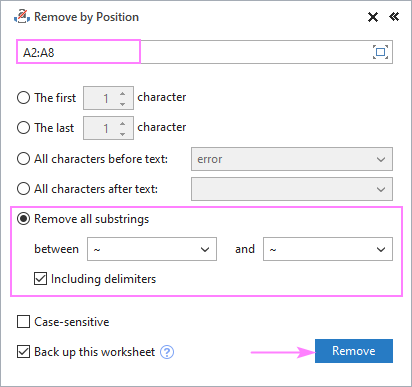
- 모든 하위 문자열 제거 를 선택하고 아래 상자에 두 문자를 입력합니다.
- "사이" 문자도 제거해야 하는 경우 , 구분 기호 포함 상자를 선택합니다.
- 제거 를 클릭합니다.
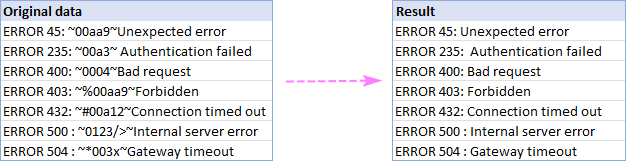
다음과 같이 예를 들어 두 물결표 문자(~) 사이의 모든 항목을 삭제하고 결과로 완벽하게 정리된 문자열을 얻습니다.
이 다기능 도구, 나는 당신이 전자를 다운로드하는 것이 좋습니다 이 게시물의 끝에서 평가 버전. 읽어 주셔서 감사합니다. 다음 주 블로그에서 뵙기를 바랍니다!
사용 가능한 다운로드
처음 또는 마지막 문자 제거 - 예(.xlsm 파일)
Ultimate Suite - 평가판(.exe 파일)
및 찾을 내용상자에 공백(*, )이 있습니다.단순 쉼표가 아니라 쉼표와 공백 도 교체하여 선행을 방지합니다. 결과에 공백이 있습니다. 데이터가 공백 없이 쉼표로 구분된 경우 별표 다음에 쉼표(*,)를 사용합니다.
두 쉼표 사이 텍스트를 삭제하려면 , 쉼표(,*,)로 묶인 별표를 사용합니다.
팁. 이름과 전화번호를 쉼표로 구분하려면 바꾸기 필드에 쉼표(,)를 입력하십시오.
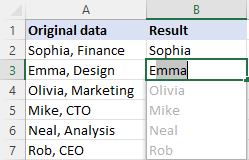
빠른 채우기를 사용하여 텍스트 일부 제거
최신 버전의 Excel(2013 이상)에는 특정 문자 앞이나 뒤에 오는 텍스트를 제거하는 또 하나의 쉬운 방법인 빠른 채우기 기능이 있습니다. 작동 방식은 다음과 같습니다.
- 데이터가 있는 첫 번째 셀 옆의 셀에 예상 결과를 입력하고 Enter 키를 누릅니다.
- 다음 셀에 적절한 값을 입력하기 시작합니다. Excel에서 입력하는 값의 패턴을 감지하면 동일한 패턴을 따르는 나머지 셀의 미리보기를 표시합니다.
- 제안을 수락하려면 Enter 키를 누르세요.
완료!
수식을 사용하여 텍스트 제거
Microsoft Excel에서 내장 기능을 사용하여 수행되는 많은 데이터 조작은 수식으로도 수행할 수 있습니다. 이전 방법과 달리 수식은 원본 데이터를 변경하지 않으며 더 많은 제어 기능을 제공합니다.결과.
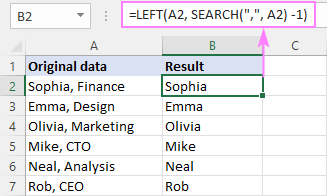
특정 문자 뒤의 모든 항목을 제거하는 방법
특정 문자 뒤의 텍스트를 삭제하는 일반 수식은 다음과 같습니다.
LEFT( cell , SEARCH (" char ", cell ) -1)여기서 SEARCH 함수를 사용하여 문자의 위치를 파악하고 LEFT 함수에 전달하므로 추출합니다. 문자열의 시작부터 해당하는 문자 수. SEARCH에서 반환된 숫자에서 한 문자를 빼서 결과에서 구분 기호를 제외합니다.
예를 들어 쉼표 뒤의 문자열 일부를 제거하려면 B2에 아래 수식을 입력하고 B7을 통해 아래로 드래그합니다. :
=LEFT(A2, SEARCH(",", A2) -1)
특정 문자 앞의 모든 항목을 제거하는 방법
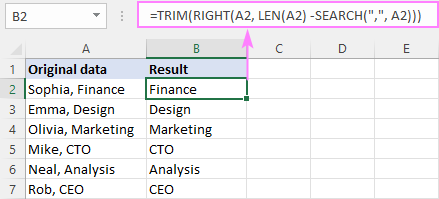
특정 문자 앞의 문자열 일부를 삭제하려면 일반 수식:
RIGHT( cell , LEN( cell ) - SEARCH(" char ", cell ))여기서 SEARCH의 도움으로 대상 문자의 위치를 다시 계산하고 LEN에서 반환한 총 문자열 길이에서 뺀 다음 그 차이를 RIGHT 함수에 전달하여 끝에서 많은 문자를 가져옵니다. string.
예를 들어 쉼표 앞의 텍스트를 제거하려면 공식은 다음과 같습니다.
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
이 경우 쉼표 뒤에 공백 문자가 옵니다. 결과에 선행 공백을 방지하기 위해 핵심 수식을 TRIM 함수로 래핑합니다.
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
참고:
- 둘 다위의 예에서는 원래 문자열에 구분 기호의 하나의 인스턴스 만 있다고 가정합니다. 여러 항목이 있는 경우 첫 번째 인스턴스 앞/뒤에 텍스트가 제거됩니다.
- SEARCH 기능은 대소문자를 구분하지 않습니다 . 소문자와 대문자. 특정 문자가 문자이고 대소문자를 구별하려면 SEARCH 대신 대소문자 구분 FIND 기능을 사용하십시오.
N번째 발생 후 텍스트 삭제 방법 of a character
소스 문자열에 구분 기호의 여러 인스턴스가 포함된 경우 특정 인스턴스 뒤의 텍스트를 제거해야 할 수 있습니다. 이를 위해 다음 수식을 사용합니다.
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "#" , n )) -1)여기서 n 은 텍스트를 제거할 문자 발생입니다.
이 수식의 내부 논리는 일부 문자를 사용해야 합니다. 소스 데이터 어디에도 없는 해시 기호(#)입니다. 이 문자가 데이터 세트에 있으면 "#" 대신 다른 문자를 사용하십시오.
예를 들어 A2에서 두 번째 쉼표(및 쉼표 자체) 뒤의 모든 항목을 제거하려면 공식은 다음과 같습니다.
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
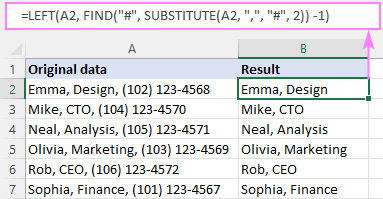
공식 작동 방식:
공식의 핵심 부분은 n 번째 위치구분자(이 경우 쉼표). 방법은 다음과 같습니다.
SUBSTITUTE:
SUBSTITUTE(A2, ",", "#", 2)
FIND("#", "Emma, Design# (102) 123-4568")
FIND는 "#"이 13번째 문자임을 알려줍니다. 문자열에서. 그 앞에 있는 문자의 수를 알려면 1을 빼면 결과가 12가 됩니다.
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
이 숫자는 num_chars 인수로 직접 연결됩니다. A2에서 처음 12자를 가져오도록 요청하는 LEFT:
=LEFT(A2, 12)
그게 다입니다!
문자가 N번째 발생하기 전에 텍스트를 삭제하는 방법
특정 문자 앞의 하위 문자열을 제거하는 일반 공식은 다음과 같습니다.
RIGHT(SUBSTITUTE( cell, " char", "#", n), LEN( 셀) - FIND("#", SUBSTITUTE( 셀, " 문자", "#", n)) -1)예를 들어 A2에서 두 번째 쉼표 앞의 텍스트를 제거하려면 공식은 다음과 같습니다.
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
앞 공백을 제거하려면 TRIM을 다시 사용합니다. 래퍼로서의 기능:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
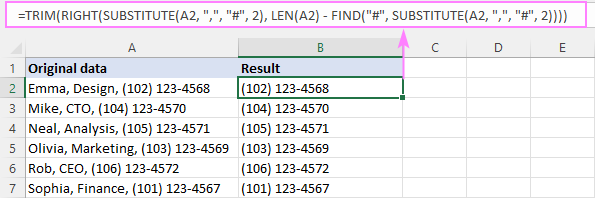
이 공식의 작동 방식:
요약하면 다음과 같습니다. n 번째 구분 기호 뒤에 몇 개의 문자가 있고 오른쪽에서 해당 길이의 하위 문자열을 추출합니다. 다음은 수식 분석입니다.
먼저 A2의 두 번째 쉼표를 해시로 바꿉니다.symbol:
SUBSTITUTE(A2, ",", "#", 2)
결과 문자열은 RIGHT:
RIGHT("Emma, Design# (102) 123-4568", …
의 text 인수로 이동합니다. 문자열 끝에서 추출할 문자 수를 정의합니다. 이를 위해 위의 문자열(13)에서 해시 기호의 위치를 찾습니다.
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
총 문자열 길이(28과 같음)에서 빼기:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
차이점(15)은 RIGHT의 두 번째 인수로 이동하여 첫 번째 인수의 문자열에서 마지막 15자를 가져오도록 지시합니다.
RIGHT("Emma, Design# (102) 123-4568", 15)
출력은 하위 문자열 "(102) 123-4568"이며 선행 공백을 제외하면 원하는 결과에 매우 가깝습니다. 따라서 TRIM 함수를 사용하여 제거합니다.
문자가 마지막으로 발생한 후 텍스트를 제거하는 방법
값이 다양한 수의 구분 기호로 구분되는 경우 해당 구분 기호의 마지막 인스턴스 이후의 모든 항목을 제거할 수 있습니다. 이는 다음 수식으로 수행할 수 있습니다.
LEFT( cell, FIND("#", SUBSTITUTE( cell, " char", "# ", LEN( cell) - LEN(SUBSTITUTE( cell, " char", "")))) -1)열 A를 가정합니다. 직원에 대한 다양한 정보가 포함되어 있지만 마지막 쉼표 뒤의 값은 항상 전화번호입니다. 귀하의 목표는 전화번호를 제거하고 다른 모든 세부 정보를 유지하는 것입니다.
목표를 달성하기 위해 다음을 사용하여 A2의 마지막 쉼표 뒤의 텍스트를 제거할 수 있습니다.수식:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
수식을 열 아래로 복사하면 다음과 같은 결과를 얻을 수 있습니다.

방법 공식 작동:
공식의 요점은 문자열에서 마지막 구분 기호(쉼표)의 위치를 결정하고 하위 문자열을 왼쪽에서 구분 기호까지 가져오는 것입니다. 구분 기호의 위치를 파악하는 것이 가장 까다로운 부분이며 이를 처리하는 방법은 다음과 같습니다.
먼저 원래 문자열에 쉼표가 몇 개인지 알아냅니다. 이를 위해 각 쉼표를 없음("")으로 바꾸고 결과 문자열을 LEN 함수에 제공합니다.
LEN(SUBSTITUTE(A2, ",",""))
A2의 경우 결과는 문자 수인 35입니다. 쉼표 없이 A2에서.
총 문자열 길이(38자)에서 위의 숫자를 빼면:
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… A2의 쉼표 수(및 마지막 쉼표의 서수).
다음으로 FIND 및 SUBSTITUTE 함수의 익숙한 조합을 사용하여 문자열에서 마지막 쉼표의 위치를 가져옵니다. 인스턴스 번호(이 경우 세 번째 쉼표)는 위에서 언급한 LEN SUBSTITUTE 공식에 의해 제공됩니다.
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
세 번째 쉼표는 A2에서 23번째 문자인 것으로 보입니다. 앞의 22자를 추출합니다. 따라서 위 공식에서 1을 빼서 LEFT의 num_chars 인수에 넣습니다.
LEFT(A2, 23-1)
문자가 마지막으로 발생하기 전에 텍스트를 제거하는 방법
삭제하려면특정 문자의 마지막 인스턴스 앞에 있는 모든 항목의 일반 공식은 다음과 같습니다.
RIGHT( cell, LEN( cell) - FIND("#", SUBSTITUTE( 셀, " 문자", "#", LEN( 셀) - LEN(SUBSTITUTE( 셀, " 문자", "")))))샘플 테이블에서 마지막 쉼표 앞의 텍스트를 제거하기 위해 수식은 다음과 같은 형식을 취합니다.
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
마지막 터치로 TRIM 함수에 중첩하여 선행 공백을 제거합니다.
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
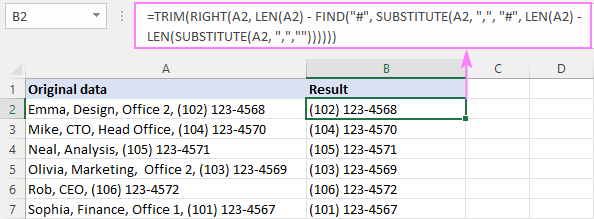
이 공식 작동 방식:
요약하면 이전 예제에서 설명한 대로 마지막 쉼표의 위치를 가져와 문자열의 총 길이에서 뺍니다.
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
결과적으로 마지막 쉼표 뒤의 문자를 RIGHT 함수에 전달하여 문자열 끝에서 해당 문자를 가져옵니다.
문자 양쪽의 텍스트를 제거하는 사용자 정의 함수
다음과 같이 위의 예에서 보았듯이 Excel의 기본 f를 사용하여 거의 모든 사용 사례를 해결할 수 있습니다. 다른 조합의 기능. 문제는 몇 가지 까다로운 공식을 기억해야 한다는 것입니다. 흠, 모든 시나리오를 다루기 위해 자체 함수를 작성하면 어떻게 될까요? 좋은 생각 같아. 따라서 통합 문서에 다음 VBA 코드를 추가합니다(Excel에 VBA를 삽입하는 자세한 단계는 여기 참조).
Function RemoveText(str As String , delimiter As String , 발생 As Integer , is_after AsBoolean ) Dim delimiter_num, start_num, delimiter_len As Integer Dim str_result As String delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(delimiter) For i = 1 To 발생 delimiter_num = InStr(start_num, str, delimiter, vbTextCompare) If 0 < delimiter_num Then start_num = delimiter_num + delimiter_len End If Next i If 0 < delimiter_num Then If True = is_after Then str_result = Mid(str, 1, start_num - delimiter_len - 1) Else str_result = Mid(str, start_num) End If End If RemoveText = str_result End Function함수 이름은 RemoveText 이며 다음과 같은 구문이 있습니다.
RemoveText(문자열, 구분 기호, 발생, is_after)여기서:
문자열 - 원래 텍스트 문자열입니다. 셀 참조로 나타낼 수 있습니다.
구분 기호 - 텍스트를 제거할 앞/뒤의 문자입니다.
발생 - 해당 인스턴스 delimiter.
Is_after - 텍스트를 제거할 구분 기호 쪽을 나타내는 부울 값입니다. 단일 문자 또는 일련의 문자일 수 있습니다.
- TRUE - 구분 기호 뒤의 모든 항목을 삭제합니다(구분 기호 자체 포함).
- FALSE - 구분 기호 앞의 모든 항목 삭제( 구분자 자체).
함수 코드가 통합 문서에 삽입되면 간결하고 우아한 수식을 사용하여 셀에서 하위 문자열을 제거할 수 있습니다.
예를 들어 지우기 위해
