
विषयसूची
हाल के कुछ लेखों में, हमने एक्सेल में स्ट्रिंग्स से वर्णों को हटाने के विभिन्न तरीकों पर ध्यान दिया है। आज, हम एक और उपयोग मामले की जांच करेंगे - किसी विशिष्ट वर्ण से पहले या बाद में सब कुछ कैसे हटाएं।
Find & बदलें
एक से अधिक सेल में डेटा हेरफेर के लिए, ढूँढें और बदलें सही टूल है। किसी विशिष्ट वर्ण से पहले या बाद में स्ट्रिंग के भाग को निकालने के लिए, ये करने के चरण हैं:
- उन सभी कक्षों का चयन करें जहां आप पाठ को हटाना चाहते हैं।
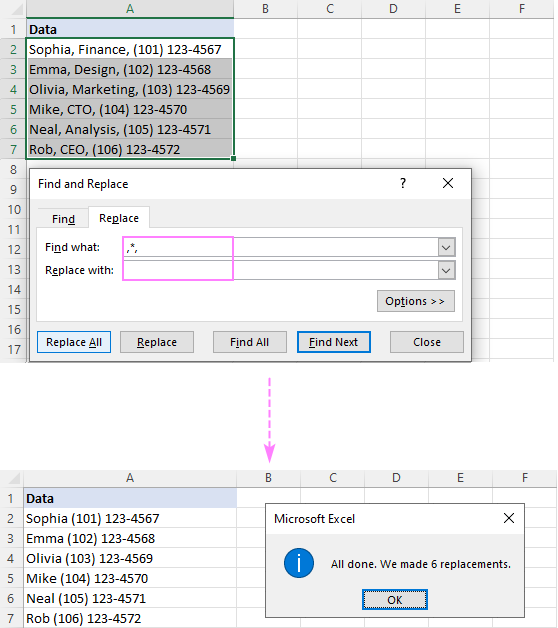
- Ctrl + H दबाएं खोजें और बदलें डायलॉग बॉक्स खोलने के लिए।> दिए गए वर्ण से पहले , तारक चिह्न (*char) से पहले वर्ण टाइप करें। *).
- किसी सबस्ट्रिंग दो अक्षरों के बीच को हटाने के लिए, 2 वर्णों (char*char) से घिरा एक तारांकन चिह्न टाइप करें।
- छोड़ दें रिप्लेस रिप्लेस बॉक्स खाली।
- क्लिक करें रिप्लेस ऑल ।
उदाहरण के लिए, को हटाने के लिए अल्पविराम के बाद सब कुछ स्वयं अल्पविराम सहित, क्या खोजें बॉक्स में एक अल्पविराम और एक तारांकन चिह्न (,*) लगाएं, और आपको निम्नलिखित परिणाम मिलेंगे:
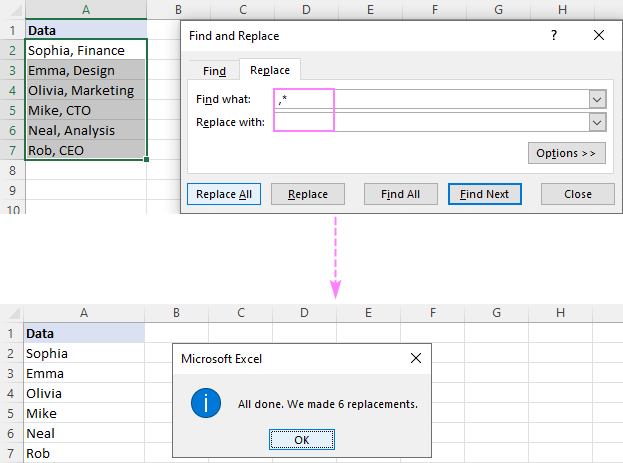
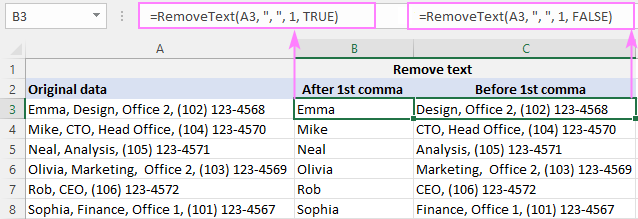
किसी सबस्ट्रिंग को हटाने के लिए अल्पविराम से पहले , एक तारांकन चिह्न टाइप करें, एक अल्पविराम,A2 में पहले अल्पविराम के बाद सब कुछ, B2 में सूत्र है:
=RemoveText(A3, ", ", 1, TRUE)
A2 में पहले अल्पविराम से पहले सब कुछ हटाने के लिए, C2 में सूत्र है:
=RemoveText(A3, ", ", 1, FALSE)
चूंकि हमारा कस्टम फ़ंक्शन सीमांकक के लिए एक स्ट्रिंग स्वीकार करता है, हम दूसरे तर्क में एक अल्पविराम और एक स्थान (", ") डालते हैं ताकि बाद में प्रमुख स्थानों को ट्रिम करने की परेशानी से बचा जा सके।
हमारा कस्टम फंक्शन खूबसूरती से काम करता है, है ना? लेकिन अगर आपको लगता है कि यह व्यापक समाधान है, तो आपने अभी तक अगला उदाहरण नहीं देखा है :)
वर्णों के पहले, बाद में या उनके बीच सब कुछ हटाएं
व्यक्तिगत वर्णों को हटाने के लिए और भी अधिक विकल्प प्राप्त करने के लिए या मिलान या स्थिति के आधार पर कई सेल से टेक्स्ट, हमारे अल्टीमेट सूट को अपने एक्सेल टूलबॉक्स में जोड़ें। 9>एबलबिट्स डेटा टैब > टेक्स्ट समूह > निकालें ।
नीचे, हम दोनों को कवर करेंगे सबसे आम परिदृश्य।
कुछ टेक्स्ट से पहले या बाद में सब कुछ हटा दें
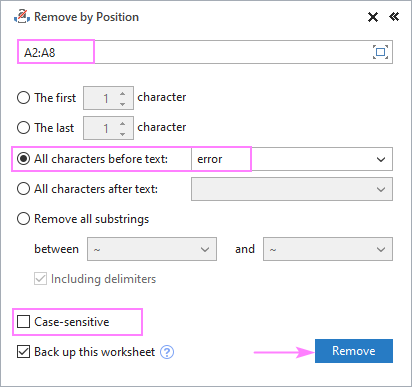
मान लें कि आपके सभी स्रोत स्ट्रिंग में कुछ सामान्य शब्द या टेक्स्ट हैं और आप उस टेक्स्ट से पहले या बाद में सब कुछ हटाना चाहते हैं। इसे पूरा करने के लिए, अपने स्रोत डेटा का चयन करें, स्थिति के अनुसार निकालें टूल चलाएँ, और इसे नीचे दिखाए अनुसार कॉन्फ़िगर करें:
- टेक्स्ट से पहले के सभी वर्ण<10 चुनें> या टेक्स्ट के बाद के सभी अक्षर विकल्प और अगले बॉक्स में मुख्य टेक्स्ट (या कैरेक्टर) टाइप करेंइसके लिए।
- इस पर निर्भर करते हुए कि अपरकेस और लोअरकेस अक्षरों को अलग-अलग या समान वर्णों के रूप में माना जाना चाहिए, केस-संवेदी बॉक्स को चेक या अनचेक करें।
- हिट निकालें ।
इस उदाहरण में, हम कक्ष A2:A8:
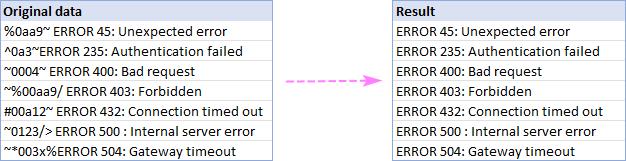
दो अक्षरों के बीच के पाठ को हटा दें
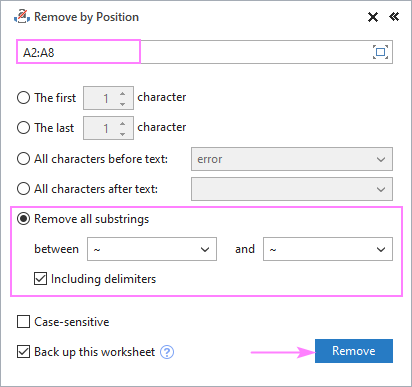
ऐसी स्थिति में जब अप्रासंगिक जानकारी 2 विशिष्ट वर्णों के बीच हो, यहां बताया गया है कि कैसे आप इसे जल्दी से हटा सकते हैं:
- चुनें सभी सबस्ट्रिंग हटाएं और नीचे दिए गए बॉक्स में दो वर्ण टाइप करें।
- यदि "बीच" वर्णों को भी हटा दिया जाना चाहिए , सहित सीमांकक बॉक्स को चेक करें।
- निकालें क्लिक करें।
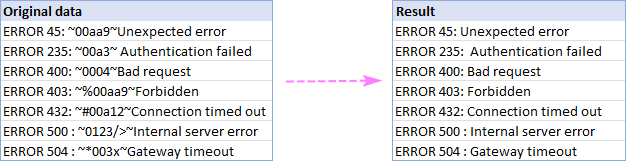
जैसा एक उदाहरण, हम दो टिल्ड वर्णों (~) के बीच सब कुछ हटा देते हैं, और परिणाम के रूप में पूरी तरह से साफ किए गए तार प्राप्त करते हैं:
इस बहु-कार्यात्मक के साथ शामिल अन्य उपयोगी सुविधाओं को आज़माने के लिए उपकरण, मैं आपको एक ई डाउनलोड करने के लिए प्रोत्साहित करता हूं इस पोस्ट के अंत में मूल्यांकन संस्करण। पढ़ने के लिए धन्यवाद और अगले सप्ताह हमारे ब्लॉग पर आपसे मिलने की आशा है!
डाउनलोड उपलब्ध हैं
पहले या अंतिम वर्ण हटाएं - उदाहरण (.xlsm फ़ाइल)
अल्टीमेट सुइट - परीक्षण संस्करण (.exe फ़ाइल)
और ढूंढेंबॉक्स में एक स्पेस (*, ) है। परिणामों में रिक्त स्थान। यदि आपका डेटा बिना रिक्त स्थान के अल्पविराम द्वारा अलग किया गया है, तो एक अल्पविराम (*,) के बाद एक तारांकन चिह्न का उपयोग करें। 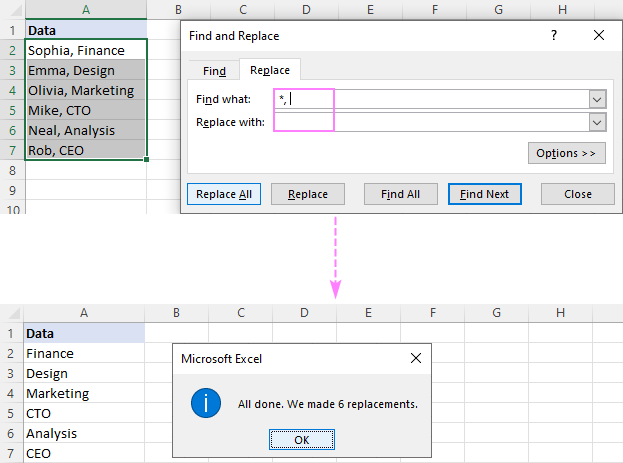
पाठ को हटाने के लिए दो अल्पविरामों के बीच , अल्पविराम (,*,) से घिरे तारक चिह्न का उपयोग करें।
युक्ति। अगर आप चाहते हैं कि नाम और फोन नंबर कॉमा से अलग हों, तो रिप्लेस विथ फील्ड में कॉमा (,) टाइप करें।
फ़्लैश फ़िल का उपयोग करके टेक्स्ट का भाग हटाएं
एक्सेल के आधुनिक संस्करणों (2013 और उसके बाद) में, किसी विशिष्ट वर्ण के पहले या बाद वाले टेक्स्ट को मिटाने का एक और आसान तरीका है - फ़्लैश फ़िल सुविधा। यहां बताया गया है कि यह कैसे काम करता है:
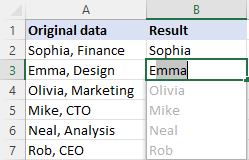
- अपने डेटा वाले पहले सेल के बगल वाले सेल में, अपेक्षित परिणाम टाइप करें और एंटर दबाएं।
- अगले सेल में उचित मान टाइप करना शुरू करें। एक बार जब एक्सेल आपके द्वारा दर्ज किए जा रहे मानों में पैटर्न को महसूस करता है, तो यह उसी पैटर्न का अनुसरण करने वाले शेष सेल के लिए एक पूर्वावलोकन प्रदर्शित करेगा।
- सुझाव को स्वीकार करने के लिए Enter कुंजी दबाएं।
हो गया!
सूत्रों का उपयोग करके पाठ हटाएं
माइक्रोसॉफ्ट एक्सेल में, इनबिल्ट सुविधाओं का उपयोग करके किए गए कई डेटा हेरफेर को एक सूत्र के साथ भी पूरा किया जा सकता है। पिछली विधियों के विपरीत, सूत्र मूल डेटा में कोई परिवर्तन नहीं करते हैं और आपको अधिक नियंत्रण प्रदान करते हैंपरिणाम।
किसी विशिष्ट वर्ण के बाद सब कुछ कैसे हटाएं
किसी विशेष वर्ण के बाद पाठ को हटाने के लिए, सामान्य सूत्र है:
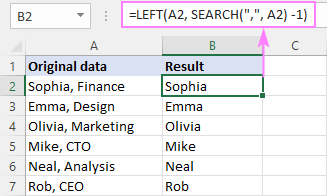
LEFT( सेल , SEARCH (" char ", cell ) -1)यहां, हम वर्ण की स्थिति प्राप्त करने के लिए SEARCH फ़ंक्शन का उपयोग करते हैं और इसे LEFT फ़ंक्शन में पास करते हैं, इसलिए यह निष्कर्ष निकालता है स्ट्रिंग की शुरुआत से वर्णों की संगत संख्या। परिणामों से सीमांकक को बाहर करने के लिए SEARCH द्वारा लौटाई गई संख्या से एक वर्ण घटाया जाता है।
उदाहरण के लिए, अल्पविराम के बाद स्ट्रिंग के भाग को निकालने के लिए, आप B2 में निम्न सूत्र दर्ज करते हैं और इसे B7 से नीचे खींचते हैं :
=LEFT(A2, SEARCH(",", A2) -1)
किसी विशिष्ट वर्ण से पहले सब कुछ कैसे हटाएं
किसी निश्चित वर्ण से पहले पाठ स्ट्रिंग के भाग को हटाने के लिए, सामान्य सूत्र है:
राइट ( सेल , LEN ( सेल ) - SEARCH (" char ", सेल ))यहाँ, हम फिर से SEARCH की मदद से लक्ष्य वर्ण की स्थिति की गणना करते हैं, इसे LEN द्वारा लौटाई गई कुल स्ट्रिंग लंबाई से घटाते हैं, और अंतर को RIGHT फ़ंक्शन में पास करते हैं, इसलिए यह इतने वर्णों को खींचता है string.
उदाहरण के लिए, अल्पविराम से पहले पाठ को हटाने के लिए, सूत्र है:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
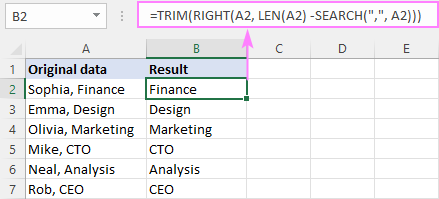
हमारे मामले में, अल्पविराम के बाद एक रिक्ति वर्ण होता है। परिणामों में अग्रणी स्थान से बचने के लिए, हम मूल सूत्र को TRIM फ़ंक्शन में लपेटते हैं:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
टिप्पणियाँ:
- दोनोंऊपर दिए गए उदाहरणों में से मान लिया गया है कि मूल स्ट्रिंग में सीमांकक का केवल एक उदाहरण है। यदि एक से अधिक आवृत्तियाँ हैं, तो पहले उदाहरण से पहले/बाद में टेक्स्ट हटा दिया जाएगा।
- SEARCH फ़ंक्शन केस-संवेदी नहीं है , जिसका अर्थ है कि यह इन दोनों के बीच कोई अंतर नहीं करता है लोअरकेस और अपरकेस वर्ण। यदि आपका विशिष्ट वर्ण एक अक्षर है और आप अक्षर केस को अलग करना चाहते हैं, तो खोज के बजाय केस-संवेदी FIND फ़ंक्शन का उपयोग करें।
Nth घटना के बाद टेक्स्ट को कैसे हटाएं एक चरित्र का
ऐसी स्थिति में जब एक स्रोत स्ट्रिंग में सीमांकक के कई उदाहरण होते हैं, तो आपको एक विशिष्ट उदाहरण के बाद पाठ को हटाने की आवश्यकता हो सकती है। इसके लिए निम्न सूत्र का प्रयोग करें:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "#" , n )) -1)कहाँ n वर्ण की घटना है जिसके बाद पाठ को हटाना है।
इस सूत्र के आंतरिक तर्क में कुछ वर्ण का उपयोग करने की आवश्यकता होती है जो हमारे मामले में स्रोत डेटा, एक हैश प्रतीक (#) में कहीं भी मौजूद नहीं है। यदि यह वर्ण आपके डेटा सेट में आता है, तो "#" के बजाय कुछ और उपयोग करें।
उदाहरण के लिए, A2 में दूसरे अल्पविराम के बाद सब कुछ हटाने के लिए (और स्वयं अल्पविराम), सूत्र है:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
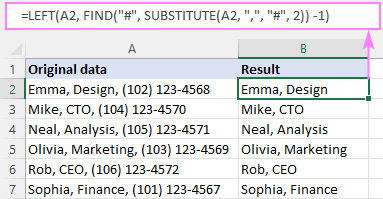
यह सूत्र कैसे काम करता है:
सूत्र का मुख्य भाग FIND फ़ंक्शन है जो गणना करता है nth की स्थितिसीमांकक (हमारे मामले में अल्पविराम)। यहां बताया गया है कि कैसे:
हम A2 में दूसरे अल्पविराम को एक हैश प्रतीक (या कोई अन्य वर्ण जो आपके डेटा में मौजूद नहीं है) के साथ स्थानापन्न की मदद से बदलते हैं:
SUBSTITUTE(A2, ",", "#", 2)
परिणामी स्ट्रिंग FIND के दूसरे तर्क पर जाती है, इसलिए यह उस स्ट्रिंग में "#" की स्थिति का पता लगाती है:
FIND("#", "Emma, Design# (102) 123-4568")
FIND हमें बताता है कि "#" 13वां वर्ण है तार में। इससे पहले वर्णों की संख्या जानने के लिए, केवल 1 घटाएं, और परिणाम के रूप में आपको 12 मिलेगा:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
यह संख्या सीधे num_chars तर्क पर जाती है LEFT इसे A2 से पहले 12 वर्ण निकालने के लिए कह रहा है:
=LEFT(A2, 12)
बस!
किसी वर्ण के Nth आने से पहले टेक्स्ट को कैसे हटाएं
एक निश्चित वर्ण से पहले एक सबस्ट्रिंग को हटाने के लिए सामान्य सूत्र है: ), LEN( सेल ) - FIND("#", स्थानापन्न( सेल , " char ", "#", n )) -1)
उदाहरण के लिए, A2 में दूसरे अल्पविराम से पहले पाठ को हटाने के लिए, सूत्र है:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
एक प्रमुख स्थान को समाप्त करने के लिए, हम फिर से TRIM का उपयोग करते हैं रैपर के रूप में काम करता है:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
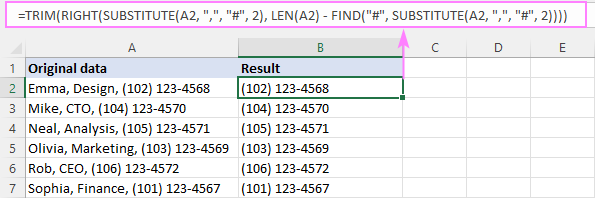
यह फॉर्मूला कैसे काम करता है:
सारांश में, हमें पता चलता है nवें सीमांकक के बाद कितने वर्ण हैं और दाईं ओर से संबंधित लंबाई का सबस्ट्रिंग निकालें। सूत्र नीचे दिया गया है:
सबसे पहले, हम A2 में दूसरे अल्पविराम को हैश से बदलते हैंप्रतीक:
SUBSTITUTE(A2, ",", "#", 2)
परिणामी स्ट्रिंग राइट के पाठ तर्क पर जाता है:
RIGHT("Emma, Design# (102) 123-4568", …
अगला, हमें परिभाषित करें कि स्ट्रिंग के अंत से कितने वर्ण निकालने हैं। इसके लिए, हम उपरोक्त स्ट्रिंग (जो कि 13 है) में हैश प्रतीक की स्थिति पाते हैं:
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
और इसे कुल स्ट्रिंग लंबाई से घटाएं (जो 28 के बराबर है):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
अंतर (15) राइट के दूसरे तर्क में जाता है और इसे पहले तर्क में स्ट्रिंग से अंतिम 15 वर्णों को खींचने का निर्देश देता है:
RIGHT("Emma, Design# (102) 123-4568", 15)
आउटपुट एक सबस्ट्रिंग "(102) 123-4568" है, जो एक प्रमुख स्थान को छोड़कर वांछित परिणाम के बहुत करीब है। इसलिए, हम इससे छुटकारा पाने के लिए TRIM फ़ंक्शन का उपयोग करते हैं।
कैरेक्टर की अंतिम घटना के बाद टेक्स्ट को कैसे हटाएं
यदि आपके मान परिसीमनकों की एक चर संख्या के साथ अलग किए गए हैं, तो आप उस सीमांकक के अंतिम उदाहरण के बाद सब कुछ हटाना चाह सकते हैं। यह निम्न सूत्र के साथ किया जा सकता है:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "#) ", LEN( सेल ) - LEN(SUBSTITUTE( cell , " char ", "")))) -1)मान लें कि कॉलम A कर्मचारियों के बारे में विभिन्न जानकारी शामिल है, लेकिन अंतिम अल्पविराम के बाद का मान हमेशा एक टेलीफोन नंबर होता है। आपका लक्ष्य फ़ोन नंबर निकालना और अन्य सभी विवरण रखना है।
लक्ष्य प्राप्त करने के लिए, आप इसके साथ A2 में अंतिम अल्पविराम के बाद के पाठ को निकाल सकते हैंसूत्र:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
सूत्र को कॉलम के नीचे कॉपी करें, और आपको यह परिणाम मिलेगा:

यह कैसे फ़ॉर्मूला काम करता है:
फ़ॉर्मूला का सार यह है कि हम स्ट्रिंग में अंतिम सीमांकक (कॉमा) की स्थिति निर्धारित करते हैं और एक सबस्ट्रिंग को बाईं ओर से सीमांकक तक खींचते हैं। सीमांकक की स्थिति प्राप्त करना सबसे पेचीदा हिस्सा है, और यहां बताया गया है कि हम इसे कैसे संभालते हैं:
सबसे पहले, हम यह पता लगाते हैं कि मूल स्ट्रिंग में कितने कॉमा हैं। इसके लिए, हम प्रत्येक अल्पविराम को शून्य ("") से प्रतिस्थापित करते हैं और परिणामी स्ट्रिंग को LEN फ़ंक्शन में प्रस्तुत करते हैं:
LEN(SUBSTITUTE(A2, ",",""))
A2 के लिए, परिणाम 35 है, जो वर्णों की संख्या है A2 में कॉमा के बिना।
उपरोक्त संख्या को कुल स्ट्रिंग लंबाई (38 वर्ण) से घटाएं:
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… और आपको 3 मिलेगा, जो कुल संख्या है A2 में अल्पविरामों की संख्या (और अंतिम अल्पविराम की क्रमिक संख्या भी)।
अगला, आप स्ट्रिंग में अंतिम अल्पविराम की स्थिति प्राप्त करने के लिए FIND और स्थानापन्न कार्यों के पहले से ही परिचित संयोजन का उपयोग करते हैं। उदाहरण संख्या (हमारे मामले में तीसरा अल्पविराम) उपर्युक्त LEN स्थानापन्न सूत्र द्वारा आपूर्ति की जाती है:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
ऐसा प्रतीत होता है कि तीसरा अल्पविराम A2 में 23वां वर्ण है, जिसका अर्थ है कि हमें इसकी आवश्यकता है इससे पहले के 22 अक्षर निकालने के लिए। इसलिए, हम उपरोक्त सूत्र माइनस 1 को LEFT के num_chars तर्क में रखते हैं:
LEFT(A2, 23-1)
कैरेक्टर की अंतिम घटना से पहले टेक्स्ट कैसे निकालें
हटाने के लिएएक विशिष्ट चरित्र के अंतिम उदाहरण से पहले सब कुछ, सामान्य सूत्र है:
राइट ( सेल , LEN ( सेल ) - FIND ("#", सबस्टिट्यूट ( सेल , " चार ", "#", एलईएन ( सेल ) - एलईएन (स्थानापन्न ( सेल , " चार ", "")))))हमारी नमूना तालिका में, अंतिम अल्पविराम से पहले पाठ को मिटाने के लिए, सूत्र यह रूप लेता है:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
अंतिम स्पर्श के रूप में, हम लीडिंग स्पेस को खत्म करने के लिए इसे TRIM फंक्शन में नेस्ट करें:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
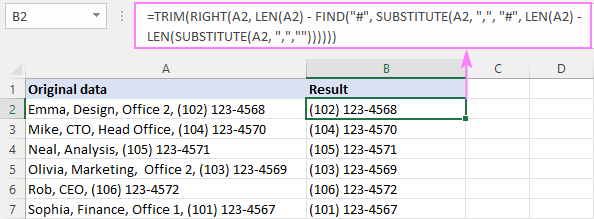
यह फॉर्मूला कैसे काम करता है:
संक्षेप में, हम पिछले उदाहरण में बताए गए अंतिम अल्पविराम की स्थिति प्राप्त करते हैं और इसे स्ट्रिंग की कुल लंबाई से घटाते हैं:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
परिणाम के रूप में, हमें संख्या मिलती है अंतिम अल्पविराम के बाद वर्ण और इसे राइट फ़ंक्शन में पास करें, इसलिए यह स्ट्रिंग के अंत से कई वर्ण लाता है। आपने उपरोक्त उदाहरणों में देखा है, आप एक्सेल के मूल एफ का उपयोग करके लगभग किसी भी उपयोग के मामले को हल कर सकते हैं विभिन्न संयोजनों में क्रियाएं। समस्या यह है कि आपको मुट्ठी भर मुश्किल फॉर्मूलों को याद रखने की जरूरत है। हम्म, क्या होगा यदि हम सभी परिदृश्यों को कवर करने के लिए अपना स्वयं का कार्य लिखें? एक अच्छे विचार की तरह लगता है। इसलिए, अपनी कार्यपुस्तिका में निम्नलिखित VBA कोड जोड़ें (Excel में VBA सम्मिलित करने के लिए विस्तृत चरण यहाँ हैं):बूलियन) मंद delimiter_num, start_num, delimiter_len As Integer Dim str_result As String delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(delimiter) For i = 1 to the event delimiter_num = InStr(start_num, str, delimiter, vbTextCompare) If 0 < delimiter_num फिर start_num = delimiter_num + delimiter_len अंत यदि अगला i यदि 0 < delimiter_num फिर अगर True = is_after तो str_result = Mid(str, 1, start_num - delimiter_len - 1) वरना str_result = Mid(str, start_num) End if End if RemoveText = str_result End Function
हमारे फंक्शन का नाम है RemoveText और इसका सिंटैक्स निम्न है:
रिमूवटेक्स्ट (स्ट्रिंग, सीमांकक, घटना, is_ after)कहां:
स्ट्रिंग - मूल पाठ स्ट्रिंग है। एक सेल संदर्भ द्वारा प्रदर्शित किया जा सकता है।
सीमांकक - चरित्र से पहले / जिसके बाद पाठ को हटाना है।
घटना - का उदाहरण सीमांकक।
Is_after - एक बूलियन मान जो इंगित करता है कि सीमांकक के किस तरफ पाठ को हटाना है। एकल वर्ण या वर्णों का अनुक्रम हो सकता है।
- TRUE - सीमांकक के बाद सब कुछ हटा दें (स्वयं सीमांकक सहित)।
- गलत - सीमांकक से पहले सब कुछ हटा दें (सहित डिलिमिटर स्वयं)।
एक बार फ़ंक्शन का कोड आपकी कार्यपुस्तिका में सम्मिलित हो जाने के बाद, आप कॉम्पैक्ट और सुरुचिपूर्ण सूत्रों का उपयोग करके सेल से सबस्ट्रिंग निकाल सकते हैं।
उदाहरण के लिए, मिटाने के लिए
