
सामग्री सारणी
अलीकडच्या काही लेखांमध्ये, आम्ही एक्सेलमधील स्ट्रिंगमधून अक्षरे काढून टाकण्याचे वेगवेगळे मार्ग पाहिले आहेत. आज, आम्ही आणखी एका वापर प्रकरणाची चौकशी करू - विशिष्ट वर्णापूर्वी किंवा नंतर सर्वकाही कसे हटवायचे.
Find & Replace
एकाधिक सेलमधील डेटा हाताळणीसाठी, Find आणि Replace हे योग्य साधन आहे. स्ट्रिंगचा काही भाग काढून टाकण्यासाठी विशिष्ट वर्णाच्या आधी किंवा अनुसरण करण्यासाठी, या पायऱ्या आहेत:
- तुम्हाला जिथे मजकूर हटवायचा आहे ते सर्व सेल निवडा.
- Ctrl + H दाबा शोधा आणि बदला संवाद उघडण्यासाठी.
- काय शोधा बॉक्समध्ये, खालीलपैकी एक संयोजन प्रविष्ट करा:
- मजकूर काढून टाकण्यासाठी दिलेल्या वर्णापूर्वी , तारकापुढील वर्ण टाईप करा (*char).
- मजकूर काढण्यासाठी विशिष्ट वर्णानंतर , तारा (*char) नंतर वर्ण टाइप करा *).
- सबस्ट्रिंग दोन वर्णांमधील हटवण्यासाठी, 2 वर्णांनी वेढलेले तारांकन टाइप करा (char*char).
- त्याला सोडा. बदला बॉक्स रिकामा.
- सर्व बदला क्लिक करा.
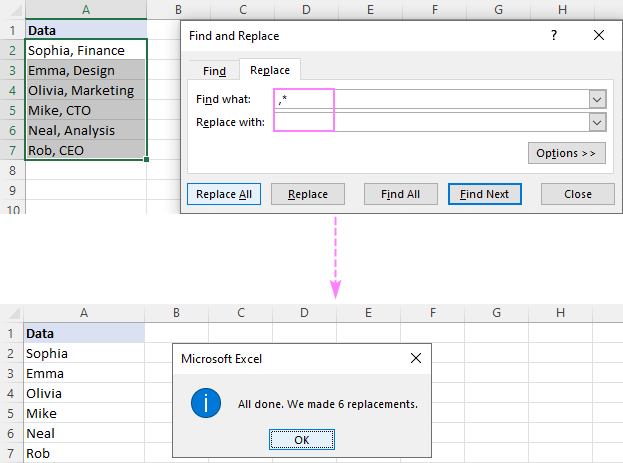
उदाहरणार्थ, काढण्यासाठी स्वल्पविरामानंतर सर्व काही स्वल्पविरामासह, स्वल्पविराम आणि तारांकित चिन्ह (,*) काय शोधा बॉक्समध्ये ठेवा आणि तुम्हाला पुढील परिणाम मिळेल:
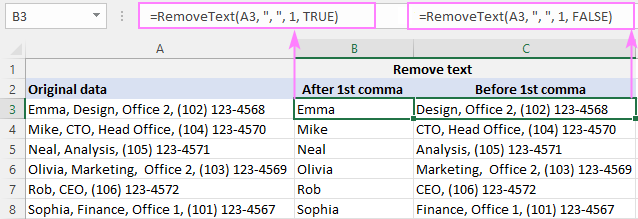
सबस्ट्रिंग हटवण्यासाठी स्वल्पविरामाच्या आधी , तारांकन टाइप करा, स्वल्पविराम,A2 मधील पहिल्या स्वल्पविरामानंतर सर्व काही, B2 मधील सूत्र आहे:
=RemoveText(A3, ", ", 1, TRUE)
A2 मधील पहिल्या स्वल्पविरामाच्या आधी सर्वकाही हटवण्यासाठी, C2 मधील सूत्र आहे:
=RemoveText(A3, ", ", 1, FALSE)
आमचे कस्टम फंक्शन डिलिमिटरसाठी स्ट्रिंग स्वीकारत असल्याने, नंतर लीडिंग स्पेस ट्रिम करण्याचा त्रास टाळण्यासाठी आम्ही दुसऱ्या वितर्कमध्ये स्वल्पविराम आणि स्पेस (", ") ठेवतो.
आमचे सानुकूल कार्य सुंदरपणे कार्य करते, नाही का? परंतु जर तुम्हाला वाटत असेल की हा सर्वसमावेशक उपाय आहे, तर तुम्ही अद्याप पुढील उदाहरण पाहिले नाही :)
अक्षरांच्या आधी, नंतर किंवा वर्णांमधील सर्वकाही हटवा
वैयक्तिक वर्ण काढून टाकण्यासाठी आणखी पर्याय मिळविण्यासाठी किंवा एकाहून अधिक सेलमधील मजकूर, जुळणी किंवा स्थितीनुसार, आमचा अल्टिमेट सूट तुमच्या एक्सेल टूलबॉक्समध्ये जोडा.
येथे, आम्ही स्थितीनुसार काढा वैशिष्ट्याकडे जवळून पाहू. 9>Ablebits Data टॅब > मजकूर गट > काढून टाका .
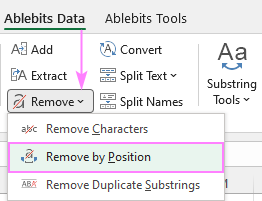
खाली, आम्ही दोन कव्हर करू सर्वात सामान्य परिस्थिती.
विशिष्ट मजकूराच्या आधी किंवा नंतर सर्वकाही काढून टाका
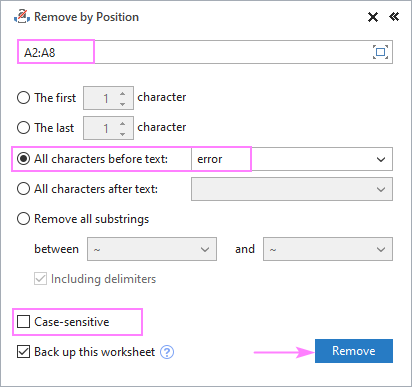
समजा तुमच्या सर्व स्त्रोत स्ट्रिंगमध्ये काही सामान्य शब्द किंवा मजकूर आहे आणि तुम्हाला त्या मजकुरापूर्वी किंवा नंतर सर्वकाही हटवायचे आहे. ते पूर्ण करण्यासाठी, तुमचा स्त्रोत डेटा निवडा, स्थितीनुसार काढा टूल चालवा आणि खाली दर्शविल्याप्रमाणे कॉन्फिगर करा:
- मजकूराच्या आधीचे सर्व वर्ण निवडा किंवा मजकूरानंतरचे सर्व वर्ण पर्याय आणि पुढील बॉक्समध्ये मुख्य मजकूर (किंवा वर्ण) टाइप करात्यावर.
- अपरकेस आणि लोअरकेस अक्षरे भिन्न किंवा समान वर्ण मानली जावीत यावर अवलंबून, केस-सेन्सिटिव्ह बॉक्स चेक किंवा अनचेक करा.
- <9 दाबा>काढून टाका .
या उदाहरणात, आम्ही सेल A2:A8:
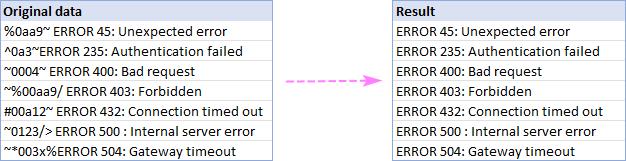
दोन वर्णांमधील मजकूर काढा
असंबद्ध माहिती 2 विशिष्ट वर्णांमध्ये असेल अशा परिस्थितीत, ते कसे आहे ते येथे आहे तुम्ही ते त्वरीत हटवू शकता:
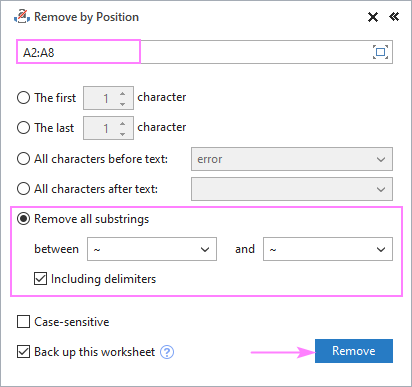
- सर्व सबस्ट्रिंग काढा निवडा आणि खालील बॉक्समध्ये दोन वर्ण टाइप करा.
- जर "दरम्यान" वर्ण देखील काढून टाकले पाहिजेत , डिलिमिटरसह बॉक्स चेक करा.
- काढा क्लिक करा.
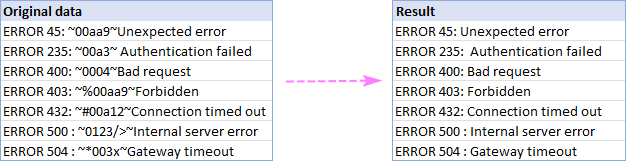
म्हणून एक उदाहरण, आम्ही दोन टिल्ड कॅरेक्टर्स (~) मधील सर्व काही हटवतो आणि परिणाम म्हणून पूर्णपणे साफ केलेल्या स्ट्रिंग्स मिळवतो:
या मल्टी-फंक्शनलमध्ये समाविष्ट असलेल्या इतर उपयुक्त वैशिष्ट्यांचा प्रयत्न करण्यासाठी टूल, मी तुम्हाला ई डाउनलोड करण्यास प्रोत्साहित करतो या पोस्टच्या शेवटी मूल्यांकन आवृत्ती. वाचल्याबद्दल धन्यवाद आणि पुढील आठवड्यात तुम्हाला आमच्या ब्लॉगवर भेटण्याची आशा आहे!
उपलब्ध डाउनलोड
पहिले किंवा शेवटचे वर्ण काढा - उदाहरणे (.xlsm फाइल)
अंतिम सूट - चाचणी आवृत्ती (.exe फाइल)
आणि काय शोधाबॉक्समध्ये एक स्पेस (*, ).कृपया लक्षात घ्या की अग्रगण्य टाळण्यासाठी आम्ही फक्त स्वल्पविराम नाही तर स्वल्पविराम आणि स्पेस बदलत आहोत. निकालांमध्ये मोकळी जागा. तुमचा डेटा रिक्त स्थानांशिवाय स्वल्पविरामाने विभक्त केला असल्यास, स्वल्पविरामाने (*,) नंतर तारका वापरा.
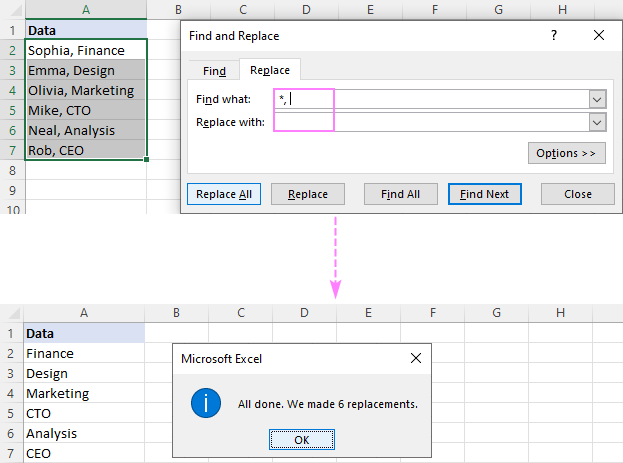
दोन स्वल्पविरामांमधील मजकूर हटवण्यासाठी , स्वल्पविरामांनी वेढलेले तारांकन वापरा (,*,).
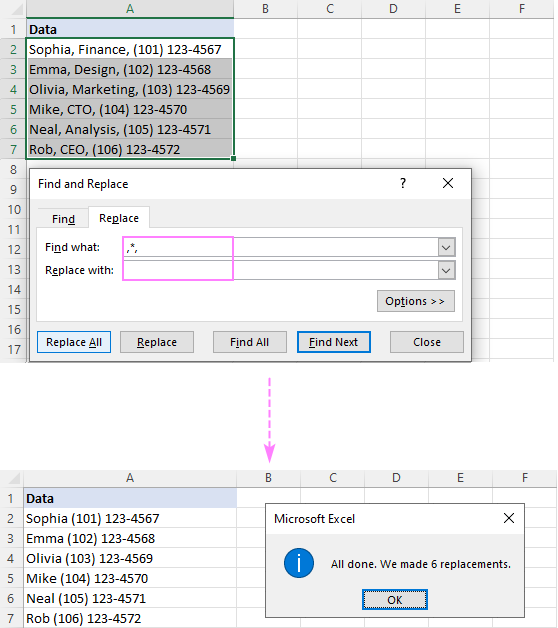
टीप. जर तुम्ही स्वल्पविरामाने वेगळे केलेले नावे आणि फोन नंबर ठेवू इच्छित असाल, तर बदला फील्डमध्ये स्वल्पविराम (,) टाइप करा.
फ्लॅश फिल वापरून मजकूराचा काही भाग काढा
एक्सेलच्या आधुनिक आवृत्त्यांमध्ये (२०१३ आणि नंतर), विशिष्ट वर्णाच्या आधी किंवा फॉलो करणारा मजकूर मिटवण्याचा आणखी एक सोपा मार्ग आहे - फ्लॅश फिल वैशिष्ट्य. ते कसे कार्य करते ते येथे आहे:
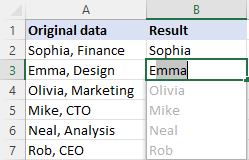
- तुमच्या डेटासह पहिल्या सेलच्या पुढील सेलमध्ये, अपेक्षित परिणाम टाइप करा आणि एंटर दाबा.
- पुढील सेलमध्ये योग्य मूल्य टाइप करणे सुरू करा. एकदा एक्सेलला तुम्ही एंटर करत असलेल्या मूल्यांमध्ये पॅटर्न जाणवला की, तो त्याच पॅटर्नचे अनुसरण करून उर्वरित सेलसाठी पूर्वावलोकन प्रदर्शित करेल.
- सूचना स्वीकारण्यासाठी एंटर की दाबा.
पूर्ण झाले!
सूत्रांचा वापर करून मजकूर काढा
मायक्रोसॉफ्ट एक्सेलमध्ये, इनबिल्ट वैशिष्ट्यांचा वापर करून अनेक डेटा मॅनिप्युलेशन देखील सूत्राने पूर्ण केले जाऊ शकतात. मागील पद्धतींप्रमाणे, सूत्रे मूळ डेटामध्ये कोणतेही बदल करत नाहीत आणि तुम्हाला त्यावर अधिक नियंत्रण देतातपरिणाम.
विशिष्ट वर्णानंतर सर्व काही कसे काढायचे
विशिष्ट वर्णानंतरचा मजकूर हटवण्यासाठी, जेनेरिक सूत्र आहे:
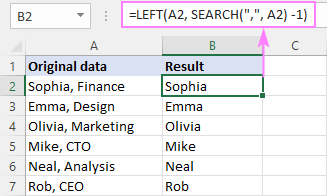
डावीकडे( सेल , शोधा (" char ", cell ) -1)येथे, आम्ही कॅरेक्टरची पोझिशन मिळवण्यासाठी SEARCH फंक्शन वापरतो आणि ते डाव्या फंक्शनमध्ये पास करतो, त्यामुळे ते एक्सट्रॅक्ट होते. स्ट्रिंगच्या प्रारंभापासून वर्णांची संबंधित संख्या. परिणामांमधून परिसीमक वगळण्यासाठी SEARCH द्वारे परत केलेल्या संख्येमधून एक वर्ण वजा केला जातो.
उदाहरणार्थ, स्वल्पविरामानंतर स्ट्रिंगचा काही भाग काढण्यासाठी, तुम्ही B2 मध्ये खालील सूत्र प्रविष्ट करा आणि B7 द्वारे खाली ड्रॅग करा. :
=LEFT(A2, SEARCH(",", A2) -1)
विशिष्ट वर्णापूर्वी सर्वकाही कसे काढायचे
विशिष्ट वर्णापूर्वी मजकूर स्ट्रिंगचा भाग हटविण्यासाठी, जेनेरिक सूत्र आहे:
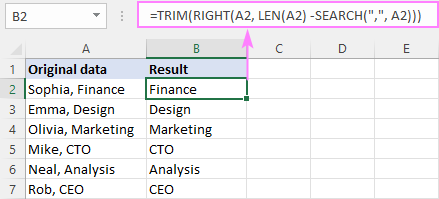
RIGHT( cell , LEN( cell ) - SEARCH(" char ", cell ))येथे, आम्ही पुन्हा SEARCH च्या मदतीने लक्ष्य वर्णाच्या स्थानाची गणना करतो, LEN ने परत केलेल्या एकूण स्ट्रिंग लांबीमधून ते वजा करतो आणि फरक उजव्या फंक्शनमध्ये पास करतो, त्यामुळे ते बर्याच वर्णांना शेवटपर्यंत खेचते. स्ट्रिंग.
उदाहरणार्थ, स्वल्पविरामापूर्वीचा मजकूर काढण्यासाठी, सूत्र आहे:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
आमच्या बाबतीत, स्वल्पविराम नंतर स्पेस वर्ण येतो. निकालांमध्ये अग्रगण्य जागा टाळण्यासाठी, आम्ही TRIM फंक्शनमध्ये कोर फॉर्म्युला गुंडाळतो:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
नोट्स:
- दोन्हीवरील उदाहरणांपैकी असे गृहीत धरले आहे की मूळ स्ट्रिंगमध्ये परिसीमकाचा फक्त एकच प्रसंग आहे. एकाधिक घटना असल्यास, मजकूर प्रथम घटना च्या आधी/नंतर काढला जाईल.
- SEARCH फंक्शन केस-सेन्सेटिव्ह नाही आहे, म्हणजे यात फरक पडत नाही लोअरकेस आणि अपरकेस वर्ण. जर तुमचा विशिष्ट वर्ण एक अक्षर असेल आणि तुम्हाला अक्षर केस वेगळे करायचे असतील, तर SEARCH ऐवजी केस-सेन्सिटिव्ह FIND फंक्शन वापरा.
Nth नंतर मजकूर कसा हटवायचा एका वर्णाचे
स्रोत स्ट्रिंगमध्ये परिसीमकाची अनेक उदाहरणे असतात अशा परिस्थितीत, तुम्हाला विशिष्ट उदाहरणानंतर मजकूर काढण्याची आवश्यकता असू शकते. यासाठी खालील सूत्र वापरा:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "#" , n )) -1)जेथे n ही वर्णाची घटना आहे ज्यानंतर मजकूर काढायचा आहे.
या सूत्राच्या अंतर्गत तर्कासाठी काही वर्ण वापरणे आवश्यक आहे जो स्त्रोत डेटामध्ये कुठेही उपस्थित नाही, आमच्या बाबतीत हॅश चिन्ह (#) आहे. हा वर्ण तुमच्या डेटा सेटमध्ये आढळल्यास, "#" ऐवजी दुसरे काहीतरी वापरा.
उदाहरणार्थ, A2 मधील 2रा स्वल्पविराम (आणि स्वल्पविराम स्वतः) नंतर सर्वकाही काढून टाकण्यासाठी, सूत्र आहे:<1
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
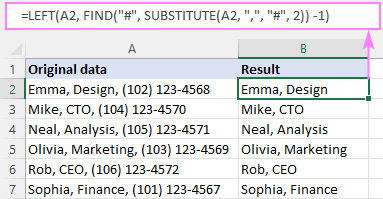
हे सूत्र कसे कार्य करते:
सूत्राचा मुख्य भाग म्हणजे FIND फंक्शन जे गणना करते nth चे स्थानपरिसीमक (आमच्या बाबतीत स्वल्पविराम). हे कसे आहे:
आम्ही SUBSTITUTE च्या मदतीने A2 मधील 2रा स्वल्पविराम हॅश चिन्हाने (किंवा तुमच्या डेटामध्ये अस्तित्वात नसलेला कोणताही वर्ण) बदलतो:
SUBSTITUTE(A2, ",", "#", 2)
परिणामी स्ट्रिंग FIND च्या 2र्या वितर्काकडे जाते, म्हणून ती त्या स्ट्रिंगमध्ये "#" चे स्थान शोधते:
FIND("#", "Emma, Design# (102) 123-4568")
FIND आम्हाला सांगते की "#" 13 वा वर्ण आहे. स्ट्रिंग मध्ये. त्याच्या आधीच्या वर्णांची संख्या जाणून घेण्यासाठी, फक्त 1 वजा करा, आणि तुम्हाला परिणाम म्हणून 12 मिळेल:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
ही संख्या थेट num_chars युक्तिवादावर जाईल डावीकडून A2:
=LEFT(A2, 12)
बसेच पहिले 12 वर्ण काढण्यास सांगितले आहे!
नवी वर्ण येण्यापूर्वी मजकूर कसा हटवायचा
विशिष्ट वर्णापूर्वी सबस्ट्रिंग काढण्याचे जेनेरिक सूत्र आहे:
RIGHT(SUBSTITUTE( cell , " char ", "#", n ), LEN( सेल ) - शोधा("#", SUBSTITUTE( cell , " char ", "#", n )) -1)उदाहरणार्थ, A2 मधील 2रा स्वल्पविराम आधी मजकूर काढून टाकण्यासाठी, सूत्र आहे:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
अग्रणी जागा काढून टाकण्यासाठी, आम्ही पुन्हा TRIM वापरतो रॅपर म्हणून कार्य करा:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
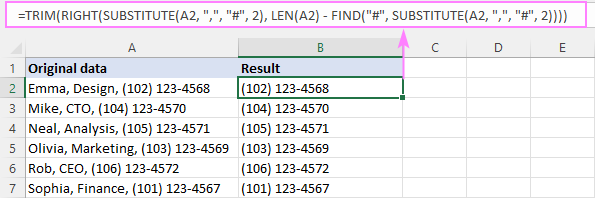
हे सूत्र कसे कार्य करते:
सारांशात, आम्ही शोधू शकतो nव्या परिसीमानंतर किती वर्ण आहेत आणि उजवीकडून संबंधित लांबीची सबस्ट्रिंग काढा. खाली फॉर्म्युला ब्रेक डाउन आहे:
प्रथम, आम्ही A2 मधील 2रा स्वल्पविराम हॅशने बदलतोचिन्ह:
SUBSTITUTE(A2, ",", "#", 2)
परिणामी स्ट्रिंग उजवीकडील टेक्स्ट युक्तिवादाकडे जाते:
RIGHT("Emma, Design# (102) 123-4568", …
पुढे, आपल्याला आवश्यक आहे स्ट्रिंगच्या शेवटी किती वर्ण काढायचे ते परिभाषित करा. यासाठी, आपल्याला वरील स्ट्रिंगमध्ये हॅश चिन्हाची स्थिती आढळते (जे 13 आहे):
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
आणि एकूण स्ट्रिंग लांबीमधून (जे 28 च्या बरोबरीचे आहे):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
फरक (15) पहिल्या युक्तिवादातील स्ट्रिंगमधील शेवटचे 15 वर्ण खेचण्याची सूचना देणारा RIGHT च्या दुसऱ्या वितर्काकडे जातो:
RIGHT("Emma, Design# (102) 123-4568", 15)
आउटपुट हे " (102) 123-4568" सबस्ट्रिंग आहे, जे एक अग्रगण्य स्थान वगळता इच्छित परिणामाच्या अगदी जवळ आहे. त्यामुळे, यापासून मुक्त होण्यासाठी आम्ही TRIM फंक्शन वापरतो.
अंतिम वर्णानंतर मजकूर कसा काढायचा
जर तुमची मूल्ये परिसीमकांच्या व्हेरिएबल संख्येने विभक्त केली गेली असतील तर, तुम्ही त्या डिलिमिटरच्या शेवटच्या प्रसंगानंतर सर्वकाही काढून टाकायचे असेल. हे खालील सूत्राने केले जाऊ शकते:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "# ", LEN( cell ) - LEN(SUBSTITUTE( cell , " char ", "")))) -1)समजा स्तंभ A कर्मचार्यांबद्दल विविध माहिती समाविष्ट आहे, परंतु शेवटच्या स्वल्पविरामानंतरचे मूल्य नेहमीच टेलिफोन नंबर असते. तुमचे ध्येय फोन नंबर काढणे आणि इतर सर्व तपशील ठेवणे हे आहे.
ध्येय साध्य करण्यासाठी, तुम्ही यासह A2 मधील शेवटच्या स्वल्पविरामानंतरचा मजकूर काढू शकता.सूत्र:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
स्तंभाच्या खाली सूत्र कॉपी करा आणि तुम्हाला हा परिणाम मिळेल:

हे कसे सूत्र कार्य करते:
सूत्राचा सारांश असा आहे की आपण स्ट्रिंगमधील शेवटच्या परिसीमक (स्वल्पविराम) चे स्थान निर्धारित करतो आणि एक सबस्ट्रिंग डावीकडून डिलिमिटरपर्यंत खेचतो. डिलिमिटरचे स्थान मिळवणे हा सर्वात अवघड भाग आहे आणि आम्ही ते कसे हाताळतो ते येथे आहे:
प्रथम, मूळ स्ट्रिंगमध्ये किती स्वल्पविराम आहेत ते आम्ही शोधतो. यासाठी, आम्ही प्रत्येक स्वल्पविरामाने काहीही ("") बदलतो आणि परिणामी स्ट्रिंग LEN फंक्शनमध्ये देतो:
LEN(SUBSTITUTE(A2, ",",""))
A2 साठी, परिणाम 35 आहे, जो वर्णांची संख्या आहे A2 मध्ये स्वल्पविरामांशिवाय.
वरील संख्या एकूण स्ट्रिंग लांबीमधून वजा करा (38 वर्ण):
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… आणि तुम्हाला 3 मिळेल, जी एकूण संख्या आहे A2 मधील स्वल्पविरामांची (आणि शेवटच्या स्वल्पविरामाची क्रमिक संख्या देखील).
पुढे, स्ट्रिंगमधील शेवटच्या स्वल्पविरामाची स्थिती मिळवण्यासाठी तुम्ही FIND आणि SUBSTITUTE फंक्शन्सचे आधीच परिचित संयोजन वापरता. उदाहरण क्रमांक (आमच्या बाबतीत 3रा स्वल्पविराम) वर नमूद केलेल्या LEN SUBSTITUTE सूत्राद्वारे प्रदान केला जातो:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
असे दिसते की 3रा स्वल्पविराम हा A2 मधील 23वा वर्ण आहे, याचा अर्थ आम्हाला आवश्यक आहे त्याच्या आधीचे 22 वर्ण काढण्यासाठी. म्हणून, आम्ही वरील सूत्र उणे 1 num_chars LEFT च्या युक्तिवादात ठेवले:
LEFT(A2, 23-1)
अंतिम वर्ण येण्यापूर्वी मजकूर कसा काढायचा
हटवण्यासाठीविशिष्ट वर्णाच्या शेवटच्या उदाहरणापूर्वी सर्वकाही, जेनेरिक सूत्र आहे:
RIGHT( cell , LEN( cell ) - FIND("#", SUBSTITUTE( सेल , " char ", "#", LEN( cell ) - LEN(SUBSTITUTE( cell , " char ", "")))))आमच्या नमुना सारणीमध्ये, शेवटच्या स्वल्पविरामापूर्वीचा मजकूर मिटवण्यासाठी, सूत्र हा फॉर्म घेतो:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
अंतिम स्पर्श म्हणून, आम्ही अग्रगण्य जागा काढून टाकण्यासाठी ते TRIM फंक्शनमध्ये नेस्ट करा:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
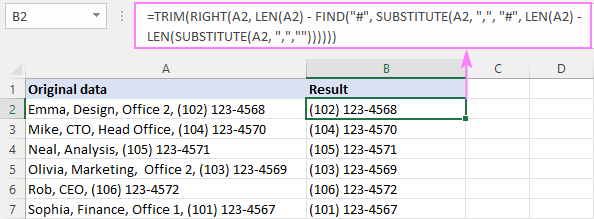
हे सूत्र कसे कार्य करते:
सारांश, मागील उदाहरणात सांगितल्याप्रमाणे आपल्याला शेवटच्या स्वल्पविरामाची स्थिती मिळते आणि स्ट्रिंगच्या एकूण लांबीमधून ती वजा केली जाते:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
परिणामी, आपल्याला संख्या मिळते शेवटच्या स्वल्पविरामानंतरचे वर्ण आणि त्यास RIGHT फंक्शनमध्ये पास करा, त्यामुळे ते स्ट्रिंगच्या शेवटी बरेच वर्ण आणते.
अक्षराच्या दोन्ही बाजूला मजकूर काढण्यासाठी सानुकूल कार्य
म्हणून तुम्ही वरील उदाहरणांमध्ये पाहिले आहे, तुम्ही एक्सेलचे नेटिव्ह f वापरून जवळजवळ कोणत्याही वापराच्या केसचे निराकरण करू शकता विविध संयोजनांमध्ये कार्ये. समस्या अशी आहे की आपल्याला मूठभर अवघड सूत्रे लक्षात ठेवण्याची आवश्यकता आहे. हम्म, सर्व परिस्थिती कव्हर करण्यासाठी आपण स्वतःचे कार्य लिहिल्यास काय? एक चांगली कल्पना वाटते. म्हणून, तुमच्या वर्कबुकमध्ये खालील VBA कोड जोडा (एक्सेलमध्ये VBA घालण्यासाठी तपशीलवार पायऱ्या येथे आहेत):
फंक्शन रिमूव्ह टेक्स्ट(str म्हणून स्ट्रिंग, डिलिमिटर स्ट्रिंग म्हणून, घटना पूर्णांक म्हणून , is_after as .बूलियन ) मंद delimiter_num, start_num, delimiter_len पूर्णांक म्हणून str_result मंद करा < delimiter_num नंतर start_num = delimiter_num + delimiter_len End If Next i If 0 < delimiter_num नंतर True = is_after नंतर str_result = Mid(str, 1, start_num - delimiter_len - 1) Else str_result = Mid(str, start_num) End If End If RemoveText = str_result एंड फंक्शन आमच्या फंक्शनचे नाव आहे टी
कुठे:
स्ट्रिंग - मूळ मजकूर स्ट्रिंग आहे. सेल संदर्भाद्वारे दर्शविले जाऊ शकते.
डिलिमिटर - मजकूर काढण्यासाठी आधी/नंतरचा वर्ण.
घटना - चे उदाहरण परिसीमक.
Is_after - एक बुलियन मूल्य जे परिसीमकाच्या कोणत्या बाजूला मजकूर काढायचा हे सूचित करते. एकल वर्ण किंवा वर्णांचा क्रम असू शकतो.
- सत्य - परिसीमाकानंतर सर्व काही हटवा (विसीमकासह).
- असत्य - परिसीमाकापूर्वी सर्वकाही हटवा (यासह डिलिमिटर स्वतःच).
एकदा फंक्शनचा कोड तुमच्या वर्कबुकमध्ये घातल्यानंतर, तुम्ही कॉम्पॅक्ट आणि शोभिवंत सूत्र वापरून सेलमधून सबस्ट्रिंग काढू शकता.
उदाहरणार्थ, पुसण्यासाठी
