
Სარჩევი
ბოლო რამდენიმე სტატიაში ჩვენ განვიხილეთ Excel-ში სტრიქონებიდან სიმბოლოების ამოღების სხვადასხვა გზა. დღეს ჩვენ გამოვიკვლევთ გამოყენების კიდევ ერთ შემთხვევას - როგორ წაშალოთ ყველაფერი კონკრეტულ სიმბოლომდე ან მის შემდეგ.
წაშალეთ ტექსტი 2 სიმბოლომდე ან შორის Find & Replace
მრავალ უჯრედში მონაცემთა მანიპულირებისთვის, Find and Replace არის სწორი ინსტრუმენტი. სტრიქონის ნაწილის ამოსაღებად, რომელიც წინ უსწრებს ან მისდევს კონკრეტულ სიმბოლოს, შემდეგი ნაბიჯები უნდა შესრულდეს:
- აირჩიეთ ყველა უჯრედი, სადაც გსურთ წაშალოთ ტექსტი.
- დააჭირეთ Ctrl + H ძებნა და ჩანაცვლება დიალოგის გასახსნელად.
- იპოვე რა ველში შეიყვანეთ ერთ-ერთი შემდეგი კომბინაცია:
- ტექსტის აღმოსაფხვრელად მოცემული სიმბოლოს წინ , აკრიფეთ სიმბოლო, რომელსაც წინ უძღვის ვარსკვლავი (*char).
- ტექსტის წასაშლელად გარკვეული სიმბოლოს შემდეგ , აკრიფეთ სიმბოლო, რასაც მოჰყვება ვარსკვლავი (char *).
- ქვესტრიქონის წასაშლელად ორ სიმბოლოს შორის , აკრიფეთ ვარსკვლავი, რომელიც გარშემორტყმულია 2 სიმბოლოთი (char*char).
- დატოვეთ ჩანაცვლება ცარიელი ველით.
- დააწკაპუნეთ ყველას ჩანაცვლება .
მაგალითად, წასაშლელად ყველაფერი მძიმის შემდეგ , მძიმის ჩათვლით, ჩადეთ მძიმით და ვარსკვლავით (,*) ველში იპოვეთ რა და მიიღებთ შემდეგ შედეგს:
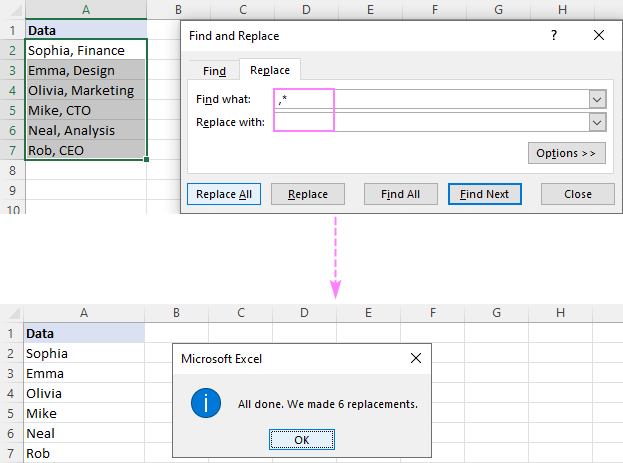
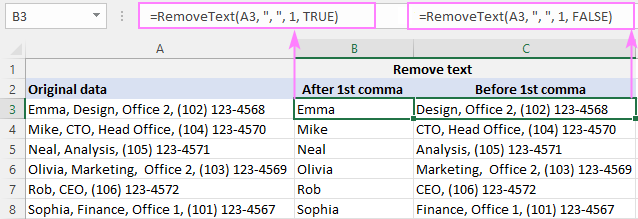
ქვესტრიქონის წასაშლელად მძიმით , აკრიფეთ ვარსკვლავი, მძიმით,ყველაფერი A2-ში 1-ლი მძიმის შემდეგ, B2-ში ფორმულა არის:
=RemoveText(A3, ", ", 1, TRUE)
A2-ში პირველ მძიმამდე ყველაფრის წასაშლელად, C2-ის ფორმულა არის:
=RemoveText(A3, ", ", 1, FALSE)
რადგან ჩვენი მორგებული ფუნქცია იღებს სტრიქონს დელიმიტერისთვის , მე-2 არგუმენტში ვდებთ მძიმით და ინტერვალს (", "), რათა არ შეგვეძლოს შემდგომი წამყვანი ადგილების ამოჭრა.
ჩვენი მორგებული ფუნქცია ლამაზად მუშაობს, არა? მაგრამ თუ ფიქრობთ, რომ ეს არის ყოვლისმომცველი გადაწყვეტა, თქვენ ჯერ არ გინახავთ შემდეგი მაგალითი :)
წაშალეთ ყველაფერი ადრე, შემდეგ ან სიმბოლოებს შორის
იმისათვის, რომ მიიღოთ კიდევ უფრო მეტი ვარიანტი ცალკეული სიმბოლოების წასაშლელად ან ტექსტი მრავალი უჯრედიდან, შესატყვისი ან პოზიციის მიხედვით, დაამატეთ ჩვენი Ultimate Suite თქვენს Excel-ის ხელსაწყოთა ყუთში.
აქ, ჩვენ უფრო დეტალურად განვიხილავთ Remove by Position ფუნქციას, რომელიც მდებარეობს 9>Ablebits Data tab > Text ჯგუფი > Remove .
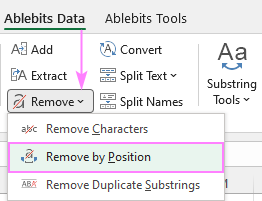
ქვემოთ განვიხილავთ ორს ყველაზე გავრცელებული სცენარი.
წაშალეთ ყველაფერი გარკვეული ტექსტის წინ ან მის შემდეგ
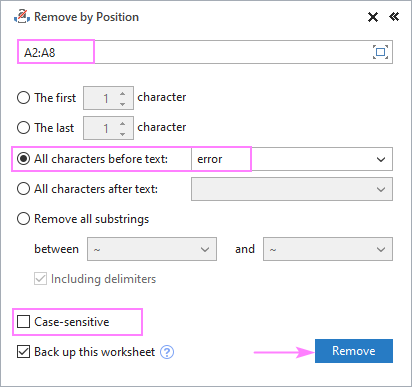
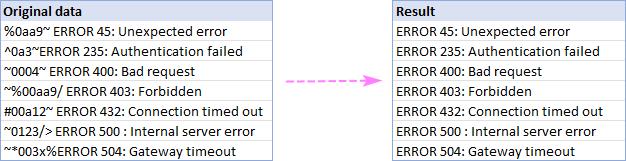
ვთქვათ, რომ თქვენი წყაროს ყველა სტრიქონი შეიცავს ზოგიერთ ჩვეულებრივ სიტყვას ან ტექსტს და გსურთ წაშალოთ ყველაფერი ამ ტექსტის წინ ან მის შემდეგ. ამის შესასრულებლად, აირჩიეთ თქვენი წყაროს მონაცემები, გაუშვით წაშლა პოზიციის მიხედვით ხელსაწყო და დააკონფიგურირეთ ქვემოთ მოცემული სახით:
- აირჩიეთ ყველა სიმბოლო ტექსტამდე ან ყველა სიმბოლო ტექსტის შემდეგ ოფცია და ჩაწერეთ საკვანძო ტექსტი (ან სიმბოლო) შემდეგ ველშიმასზე.
- დამოკიდებულია თუ არა დიდი და პატარა ასოები განიხილება როგორც განსხვავებული ან იგივე სიმბოლოები, მონიშნეთ ან გააუქმეთ ველი Ressenitive .
- დააწკაპუნეთ წაშლა .
ამ მაგალითში ჩვენ ვშლით ყველა სიმბოლოს, რომელიც წინ უსწრებს სიტყვას „შეცდომა“ უჯრედებში A2:A8:
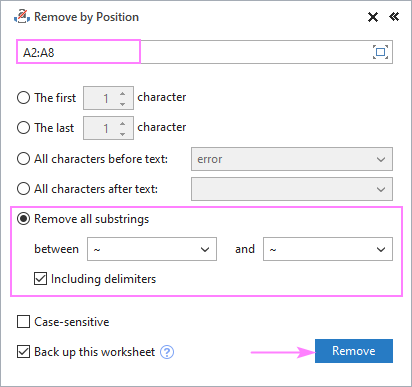
და მიიღეთ ზუსტად ის შედეგი, რასაც ვეძებთ:
წაშალეთ ტექსტი ორ სიმბოლოს შორის
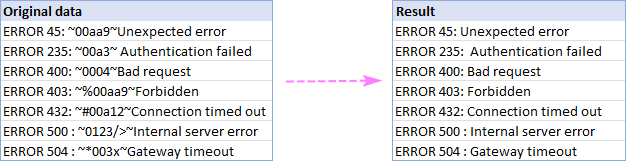
სიტუაციაში, როდესაც შეუსაბამო ინფორმაცია ორ კონკრეტულ სიმბოლოს შორისაა, აი, როგორ შეგიძლიათ სწრაფად წაშალოთ ის:
- აირჩიეთ ამოშალეთ ყველა ქვესტრიქონი და ჩაწერეთ ორი სიმბოლო ქვემოთ მოცემულ ველებში.
- თუ "შორის" სიმბოლოებიც უნდა მოიხსნას. , მონიშნეთ ველი გადამკვეთების ჩათვლით .
- დააწკაპუნეთ წაშლა .
როგორც მაგალითად, ჩვენ ვშლით ყველაფერს ორ ტილდის სიმბოლოს შორის (~) და შედეგად ვიღებთ სრულყოფილად გაწმენდილ სტრიქონებს:
გამოცადეთ სხვა სასარგებლო ფუნქციები, რომლებიც შედის ამ მრავალფუნქციურ ფუნქციაში ხელსაწყო, გირჩევთ ჩამოტვირთოთ ე შეფასების ვერსია ამ პოსტის ბოლოს. გმადლობთ, რომ კითხულობთ და ვიმედოვნებთ, რომ მომავალ კვირას შეგხვდებით ჩვენს ბლოგზე!
ხელმისაწვდომი ჩამოტვირთვები
წაშალეთ პირველი ან ბოლო სიმბოლოები - მაგალითები (ფაილი .xlsm)
Ultimate Suite - საცდელი ვერსია (.exe ფაილი)
და ინტერვალი (*, ) იპოვე რაველში.გთხოვთ, გაითვალისწინოთ, რომ ჩვენ ვცვლით არა მხოლოდ მძიმით, არამედ მძიმით და ინტერვალს , რათა თავიდან ავიცილოთ წამყვანი ადგილები შედეგებში. თუ თქვენი მონაცემები გამოყოფილია მძიმებით ინტერვალის გარეშე, გამოიყენეთ ვარსკვლავი, რასაც მოჰყვება მძიმით (*,).
ტექსტის წასაშლელად ორ მძიმეს შორის , გამოიყენეთ მძიმით გარშემორტყმული ვარსკვლავი (,*,).
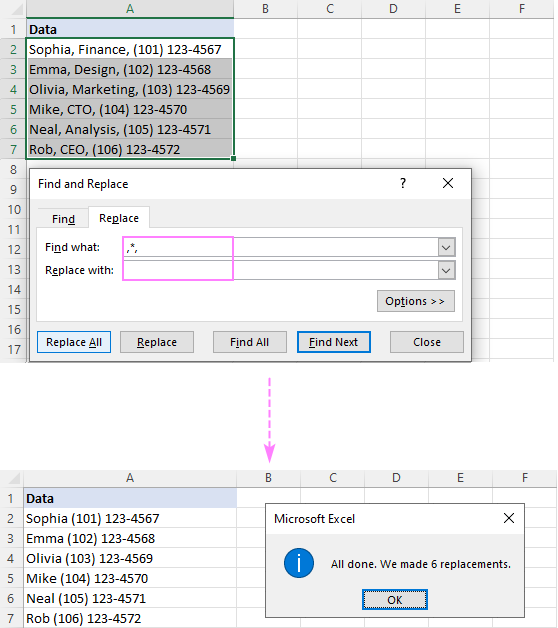
რჩევა. თუ გირჩევნიათ სახელები და ტელეფონის ნომრები მძიმით იყოს გამოყოფილი, მაშინ ჩანაცვლება ველში აკრიფეთ მძიმე (,).
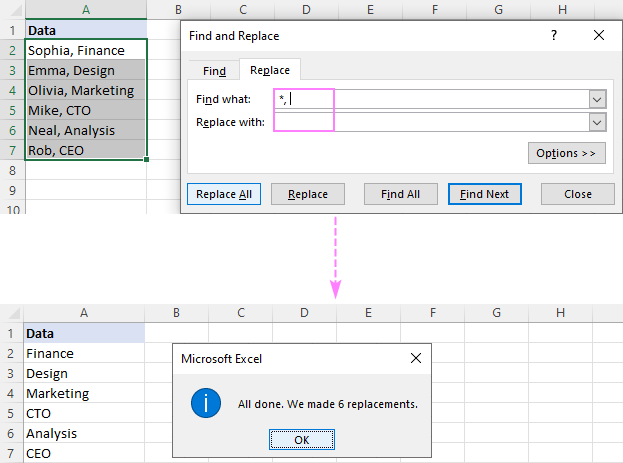
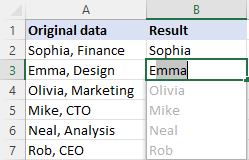
ტექსტის ნაწილის წაშლა Flash Fill-ის გამოყენებით
Excel-ის თანამედროვე ვერსიებში (2013 და შემდეგ), არსებობს კიდევ ერთი მარტივი გზა ტექსტის აღმოსაფხვრელად, რომელიც წინ უსწრებს ან მისდევს კონკრეტულ სიმბოლოს - Flash Fill-ის ფუნქცია. აი, როგორ მუშაობს:
- უჯრედში პირველი უჯრედის გვერდით თქვენი მონაცემებით, აკრიფეთ მოსალოდნელი შედეგი და დააჭირეთ Enter .
- დაიწყეთ შესაბამისი მნიშვნელობის აკრეფა მომდევნო უჯრედში. როგორც კი Excel იგრძნობს შაბლონს თქვენს მიერ შეყვანილ მნიშვნელობებში, ის აჩვენებს გადახედვას დარჩენილი უჯრედებისთვის იმავე ნიმუშის მიხედვით.
- დააჭირეთ Enter კლავიშს წინადადების მისაღებად.
დასრულდა!
ტექსტის წაშლა ფორმულების გამოყენებით
Microsoft Excel-ში, მონაცემთა მრავალი მანიპულაცია, რომელიც შესრულებულია ჩაშენებული ფუნქციების გამოყენებით, ასევე შეიძლება განხორციელდეს ფორმულით. წინა მეთოდებისგან განსხვავებით, ფორმულები არ ცვლიან თავდაპირველ მონაცემებს და გაძლევენ მეტ კონტროლსშედეგები.
როგორ წავშალოთ ყველაფერი კონკრეტული სიმბოლოს შემდეგ
კონკრეტული სიმბოლოს შემდეგ ტექსტის წასაშლელად, ზოგადი ფორმულა არის:
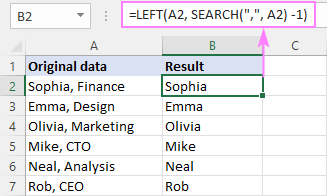
LEFT( cell , SEARCH (" char ", უჯრედი ) -1)აქ, ჩვენ ვიყენებთ SEARCH ფუნქციას, რომ მივიღოთ სიმბოლოს პოზიცია და გადავიტანოთ იგი LEFT ფუნქციაზე, ასე რომ ის ამოიღებს სიმბოლოების შესაბამისი რაოდენობა სტრიქონის დასაწყისიდან. SEARCH-ის მიერ დაბრუნებულ რიცხვს აკლდება ერთი სიმბოლო, რათა გამორიცხოს დელიმიტერი შედეგებიდან.
მაგალითად, მძიმის შემდეგ სტრიქონის ნაწილის ამოსაღებად, შეიყვანეთ ქვემოთ მოცემული ფორმულა B2-ში და გადაიტანეთ იგი ქვემოთ B7-ში. :
=LEFT(A2, SEARCH(",", A2) -1)
როგორ წავშალოთ ყველაფერი კონკრეტულ სიმბოლომდე
წაშალოთ ტექსტის სტრიქონის ნაწილი გარკვეული სიმბოლომდე, ზოგადი ფორმულა არის:
RIGHT( უჯრედი , LEN( უჯრედი ) - SEARCH(" char ", უჯრედი ))აქ ჩვენ კვლავ ვიანგარიშებთ სამიზნე სიმბოლოს პოზიციას SEARCH-ის დახმარებით, გამოვაკლებთ მას LEN-ის მიერ დაბრუნებულ სტრიქონის მთლიან სიგრძეს და სხვაობას გადავცემთ RIGHT ფუნქციას, ასე რომ, ის ამოიყვანს ამდენ სიმბოლოს ბოლოდან. string.
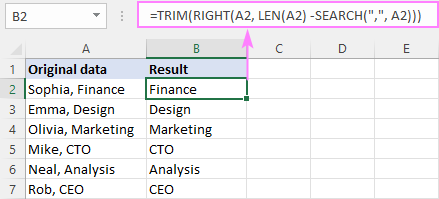
მაგალითად, მძიმის წინ ტექსტის წასაშლელად, ფორმულა არის:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
ჩვენს შემთხვევაში, მძიმეს მოსდევს ინტერვალის სიმბოლო. შედეგებში წამყვანი ადგილების თავიდან ასაცილებლად, ჩვენ ვახვევთ ძირითად ფორმულას TRIM ფუნქციაში:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
შენიშვნები:
- ორივეზემოაღნიშნული მაგალითებიდან ვივარაუდოთ, რომ თავდაპირველ სტრიქონში არის მხოლოდ ერთი ეგზემპლარი . თუ არსებობს მრავალი შემთხვევა, ტექსტი წაიშლება პირველი ინსტანციის წინ/შემდეგ.
- SEARCH ფუნქცია არ არის რეგისტრირებული , რაც ნიშნავს, რომ მას შორის განსხვავება არ არის. მცირე და დიდი ასოები. თუ თქვენი კონკრეტული სიმბოლო ასოა და გსურთ განასხვავოთ ასოები, მაშინ გამოიყენეთ case-sensitive FIND ფუნქცია SEARCH-ის ნაცვლად.
როგორ წაშალოთ ტექსტი N-ე გაჩენის შემდეგ სიმბოლოს
სიტუაციაში, როდესაც წყაროს სტრიქონი შეიცავს დელიმიტერის მრავალ ინსტანციას, შეიძლება დაგჭირდეთ ტექსტის წაშლა კონკრეტული ინსტანციის შემდეგ. ამისათვის გამოიყენეთ შემდეგი ფორმულა:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "#" , n )) -1)სადაც n არის სიმბოლოს შემთხვევა, რის შემდეგაც ხდება ტექსტის წაშლა.
ამ ფორმულის შიდა ლოგიკა მოითხოვს გარკვეული სიმბოლოების გამოყენებას რომელიც არ არის არსად წყაროს მონაცემებში, ჰეშის სიმბოლო (#) ჩვენს შემთხვევაში. თუ ეს სიმბოლო ჩნდება თქვენს მონაცემთა ნაკრებში, მაშინ გამოიყენეთ რაღაც სხვა "#"-ის ნაცვლად.
მაგალითად, A2-ში მე-2 მძიმის შემდეგ ყველაფრის წასაშლელად (და თავად მძიმით), ფორმულა არის:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
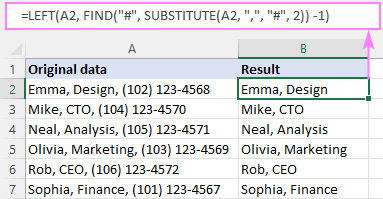
როგორ მუშაობს ეს ფორმულა:
ფორმულის მთავარი ნაწილია FIND ფუნქცია, რომელიც ითვლის n-ის პოზიციადელიმიტერი (ჩვენს შემთხვევაში მძიმით). აი როგორ:
ჩვენ ვცვლით მე-2 მძიმს A2-ში ჰეშის სიმბოლოთი (ან სხვა სიმბოლოთი, რომელიც არ არსებობს თქვენს მონაცემებში) SUBSTITUTE-ის დახმარებით:
SUBSTITUTE(A2, ",", "#", 2)
მიღებული სტრიქონი მიდის FIND-ის მე-2 არგუმენტზე, ამიტომ პოულობს "#"-ის პოზიციას ამ სტრიქონში:
FIND("#", "Emma, Design# (102) 123-4568")
FIND გვეუბნება, რომ "#" არის მე-13 სიმბოლო. სტრინგში. იმისათვის, რომ იცოდეთ მის წინ მყოფი სიმბოლოების რაოდენობა, უბრალოდ გამოაკლეთ 1 და შედეგად მიიღებთ 12-ს:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
ეს რიცხვი პირდაპირ მიდის არგუმენტზე num_chars LEFT-ს სთხოვს ამოიღოს პირველი 12 სიმბოლო A2-დან:
=LEFT(A2, 12)
ესე იგი!
როგორ წაშალოთ ტექსტი სიმბოლოს N-ე გამოჩენამდე
ზოგადი ფორმულა ქვესტრიქნის ამოსაღებად გარკვეული სიმბოლოს წინ არის:
RIGHT(SUBSTITUTE( უჯრე , " char ", "#", n ), LEN( უჯრედი ) - FIND("#", SUBSTITUTE( უჯრედი , " char ", "#", n )) -1)მაგალითად, A2-ში მე-2 მძიმამდე ტექსტის ამოსაღებად, ფორმულა არის:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
წინასწარი სივრცის აღმოსაფხვრელად, ჩვენ კვლავ ვიყენებთ TRIM-ს. ფუნქციონირებს როგორც შეფუთვა:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
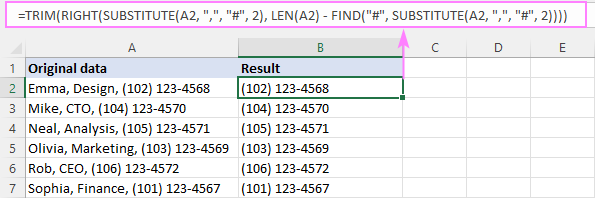
როგორ მუშაობს ეს ფორმულა:
შეჯამებით, ჩვენ გავარკვიეთ რამდენი სიმბოლოა n-ე გამყოფის შემდეგ და ამოიღეთ შესაბამისი სიგრძის ქვესტრიქონი მარჯვნიდან. ქვემოთ მოცემულია ფორმულის დაშლა:
პირველ რიგში, A2-ში მე-2 მძიმით ვცვლით ჰეშითსიმბოლო:
SUBSTITUTE(A2, ",", "#", 2)
მიღებული სტრიქონი მიდის ტექსტის არგუმენტზე RIGHT:
RIGHT("Emma, Design# (102) 123-4568", …
შემდეგ, ჩვენ გვჭირდება განსაზღვრეთ რამდენი სიმბოლო უნდა ამოიღოთ სტრიქონის ბოლოდან. ამისათვის ჩვენ ვპოულობთ ჰეშის სიმბოლოს პოზიციას ზემოთ მოცემულ სტრიქონში (რომელიც არის 13):
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
და გამოვაკლებთ მას სტრიქონის მთლიან სიგრძეს (რაც უდრის 28-ს):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
სხვაობა (15) მიდის RIGHT-ის მეორე არგუმენტზე, რომელიც ავალებს მას ამოიღოს ბოლო 15 სიმბოლო პირველი არგუმენტის სტრიქონიდან:
RIGHT("Emma, Design# (102) 123-4568", 15)
გამომავალი არის ქვესტრიქონი " (102) 123-4568", რომელიც ძალიან ახლოსაა სასურველ შედეგთან, გარდა წამყვანი სივრცისა. ამგვარად, ჩვენ ვიყენებთ TRIM ფუნქციას მის მოსაშორებლად.
როგორ წავშალოთ ტექსტი სიმბოლოს ბოლო გამოჩენის შემდეგ
იმ შემთხვევაში, თუ თქვენი მნიშვნელობები გამოყოფილია ცვლადი რაოდენობის დელიმიტერებით, თქვენ შეიძლება მოისურვოს ყველაფრის წაშლა ამ დელიმიტერის ბოლო ინსტანციის შემდეგ. ეს შეიძლება გაკეთდეს შემდეგი ფორმულით:
LEFT( cell , FIND("#", SUBSTITUTE( cell , " char ", "# ", LEN( უჯრედი ) - LEN(SUBSTITUTE( უჯრედი , " char ", "")))) -1)ვთქვათ, სვეტი A შეიცავს სხვადასხვა ინფორმაციას თანამშრომლების შესახებ, მაგრამ ბოლო მძიმის შემდეგ მნიშვნელობა ყოველთვის არის ტელეფონის ნომერი. თქვენი მიზანია წაშალოთ ტელეფონის ნომრები და შეინახოთ ყველა სხვა დეტალი.
მიზნის მისაღწევად, შეგიძლიათ წაშალოთ ტექსტი ბოლო მძიმის შემდეგ A2-ში.ფორმულა:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
დააკოპირეთ ფორმულა სვეტში და მიიღებთ ამ შედეგს:

როგორ ეს ფორმულა მუშაობს:
ფორმულის არსი იმაში მდგომარეობს, რომ ჩვენ განვსაზღვრავთ ბოლო გამიჯვნის (მძიმით) პოზიციას სტრიქონში და ვწევთ ქვესტრიქონს მარცხნიდან დელიმიტერამდე. დელიმიტერის პოზიციის დადგენა ყველაზე რთული ნაწილია და აი, როგორ მოვიქცეთ მას:
პირველ რიგში, გავარკვიეთ რამდენი მძიმეა თავდაპირველ სტრიქონში. ამისთვის ჩვენ ვცვლით თითოეულ მძიმეს არაფრით ("") და მიღებულ სტრიქონს ვემსახურებით LEN ფუნქციას:
LEN(SUBSTITUTE(A2, ",",""))
A2-ისთვის შედეგი არის 35, რაც სიმბოლოების რაოდენობაა. A2-ში მძიმის გარეშე.
გამოაკლეთ ზემოთ მოცემული რიცხვი სტრიქონის მთლიან სიგრძეს (38 სიმბოლო):
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… და მიიღებთ 3-ს, რაც არის საერთო რიცხვი მძიმეები A2-ში (და ასევე ბოლო მძიმის რიგითი ნომერი).
შემდეგ, იყენებთ FIND და SUBSTITUTE ფუნქციების უკვე ნაცნობ კომბინაციას სტრიქონში ბოლო მძიმის პოზიციის მისაღებად. ინსტანციის ნომერი (ჩვენს შემთხვევაში მე-3 მძიმით) მოწოდებულია ზემოაღნიშნული LEN SUBSTITUTE ფორმულით:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
როგორც ჩანს, მე-3 მძიმით არის 23-ე სიმბოლო A2-ში, რაც ნიშნავს, რომ ჩვენ გვჭირდება მის წინ 22 სიმბოლოს ამოღება. მაშ ასე, ზემოხსენებული ფორმულა მინუს 1 ჩავსვით LEFT-ის num_chars არგუმენტში:
LEFT(A2, 23-1)
როგორ წავშალოთ ტექსტი სიმბოლოს ბოლო გამოჩენამდე
წაშლაყველაფერი კონკრეტული სიმბოლოს ბოლო ინსტანციამდე, ზოგადი ფორმულაა:
RIGHT( უჯრედ , LEN( cell ) - FIND("#", SUBSTITUTE( cell , " char ", "#", LEN( cell ) - LEN(SUBSTITUTE( უჯრე , " char ", "")))))ჩვენს სანიმუშო ცხრილში, ბოლო მძიმამდე ტექსტის აღმოსაფხვრელად, ფორმულა იღებს ასეთ ფორმას:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
როგორც დასასრულს, ჩვენ ჩადეთ იგი TRIM ფუნქციაში წამყვანი ადგილების აღმოსაფხვრელად:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
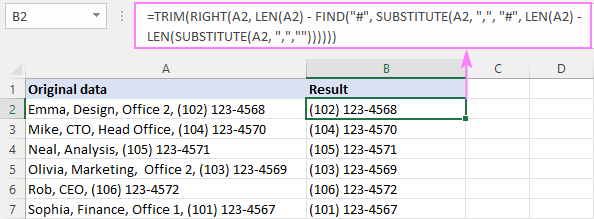
როგორ მუშაობს ეს ფორმულა:
მოკლედ, ვიღებთ ბოლო მძიმის პოზიციას, როგორც ეს იყო ახსნილი წინა მაგალითში და გამოვაკლებთ მას სტრიქონის მთლიან სიგრძეს:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
შედეგად მივიღებთ რიცხვს სიმბოლოები ბოლო მძიმის შემდეგ და გადასცე მას RIGHT ფუნქციას, ასე რომ, მას მოაქვს ამდენი სიმბოლო სტრიქონის ბოლოდან.
მორგებული ფუნქცია სიმბოლოს ორივე მხარეს ტექსტის წასაშლელად
როგორც თქვენ ნახეთ ზემოხსენებულ მაგალითებში, თქვენ შეგიძლიათ მოაგვაროთ თითქმის ნებისმიერი გამოყენების შემთხვევა Excel-ის მშობლიური f-ის გამოყენებით unctions სხვადასხვა კომბინაციებში. პრობლემა ის არის, რომ თქვენ უნდა გახსოვდეთ რამდენიმე რთული ფორმულა. ჰმ, რა მოხდება, თუ ჩვენ დავწერთ ჩვენს ფუნქციას ყველა სცენარის დასაფარად? კარგ იდეად ჟღერს. ასე რომ, დაამატეთ შემდეგი VBA კოდი თქვენს სამუშაო წიგნში (VBA Excel-ში ჩასმის დეტალური ნაბიჯები აქ არის):
ფუნქცია RemoveText(str როგორც სტრიქონი, დელიმიტერი როგორც სტრიქონი, წარმოქმნა როგორც მთელი რიცხვი, is_after Asლოგიკური ) Dim delimiter_num, start_num, delimiter_len როგორც მთელი რიცხვი Dim str_result როგორც სტრიქონის delimiter_num = 0 start_num = 1 str_result = "" delimiter_len = Len(განმსაზღვრელი) For i = 1 დასრულებამდე delimiter_num = InStrpareT, IfText(nStrpare) < delimiter_num შემდეგ start_num = delimiter_num + delimiter_len ბოლოს თუ შემდეგი i თუ 0 < delimiter_num მაშინ თუ True = არის_შემდეგ მაშინ str_result = Mid(str, 1, start_num - delimiter_len - 1) სხვა str_result = Mid(str, start_num) დასრულება თუ დასასრული If RemoveText = str_result დასრულება ფუნქციაჩვენს ფუნქციას ჰქვია RemoveT და მას აქვს შემდეგი სინტაქსი:
RemoveText(სტრიქონი, განმასხვავებელი, მოვლენა, არის_შემდეგ)სად:
String - არის ორიგინალური ტექსტის სტრიქონი. შეიძლება წარმოდგენილი იყოს უჯრედის მითითებით.
განმსაზღვრელი - სიმბოლო, რომლის წინ/შემდეგ წაიშლება ტექსტი.
შემთხვევა - მაგალითი დელიმიტერი.
Is_after - ლოგიკური მნიშვნელობა, რომელიც მიუთითებს დელიმიტერის რომელ მხარეს უნდა წაშალოს ტექსტი. შეიძლება იყოს ერთი სიმბოლო ან სიმბოლოების თანმიმდევრობა.
- TRUE - წაშალეთ ყველაფერი დელიმიტერის შემდეგ (მათ შორის თავად დელიმიტერი).
- FALSE - წაშალეთ ყველაფერი დელიმიტერამდე (მათ შორის თავად დელიმიტერი).
როგორც ფუნქციის კოდი ჩასმული იქნება თქვენს სამუშაო წიგნში, შეგიძლიათ ამოიღოთ ქვესტრიქონები უჯრედებიდან კომპაქტური და ელეგანტური ფორმულების გამოყენებით.
მაგალითად, წასაშლელად
