
Преглед садржаја
У последњих неколико чланака, погледали смо различите начине за уклањање знакова из стрингова у Екцел-у. Данас ћемо истражити још један случај употребе – како да избришете све пре или после одређеног знака.
Избришите текст пре, после или између 2 знака помоћу Финд &амп; Замени
За манипулације подацима у више ћелија, Пронађи и замени је прави алат. Да бисте уклонили део стринга који претходи или прати одређени знак, ово су кораци које треба извршити:
- Изаберите све ћелије у којима желите да избришете текст.
- Притисните Цтрл + Х да бисте отворили дијалог Пронађи и замени .
- У пољу Пронађи шта унесите једну од следећих комбинација:
- Да бисте елиминисали текст пре датог знака , откуцајте знак којем претходи звездица (*цхар).
- Да бисте уклонили текст после одређеног знака , откуцајте знак иза којег следи звездица (цхар *).
- Да бисте избрисали подниз између два знака , откуцајте звездицу окружену са 2 знака (цхар*цхар).
- Оставите Замени са поље празно.
- Кликните на Замени све .
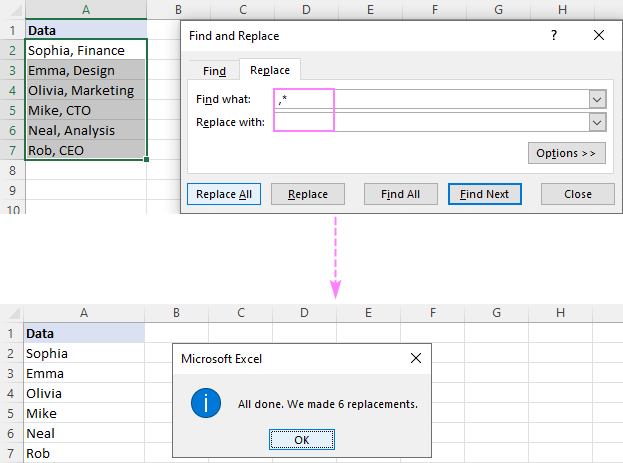
На пример, да бисте уклонили све после зареза укључујући и сам зарез, ставите зарез и знак звездице (,*) у поље Пронађи шта и добићете следећи резултат:
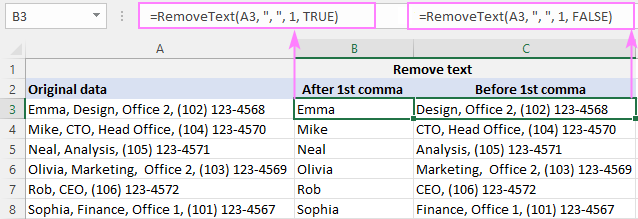
Да бисте избрисали подниз испред зареза , унесите звездицу, запета,све после 1. зареза у А2, формула у Б2 је:
=RemoveText(A3, ", ", 1, TRUE)
Да бисте избрисали све пре 1. зареза у А2, формула у Ц2 је:
=RemoveText(A3, ", ", 1, FALSE)
Пошто наша прилагођена функција прихвата стринг за граничник , ставили смо зарез и размак (", ") у 2. аргумент да бисмо поштедели невоље са сечењем водећих размака након тога.
Наша прилагођена функција ради прелепо, зар не? Али ако мислите да је то свеобухватно решење, још увек нисте видели следећи пример :)
Избришите све пре, после или између знакова
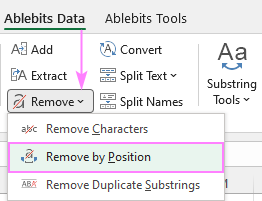
Да бисте добили још више опција за уклањање појединачних знакова или текст из више ћелија, према подударању или позицији, додајте наш Ултимате Суите у ваш Екцел алатни оквир.
Овде ћемо детаљније погледати функцију Уклони по позицији која се налази на Аблебитс Дата картица &гт; Тект гроуп &гт; Уклони .
У наставку ћемо покрити два најчешћи сценарији.
Уклоните све пре или после одређеног текста
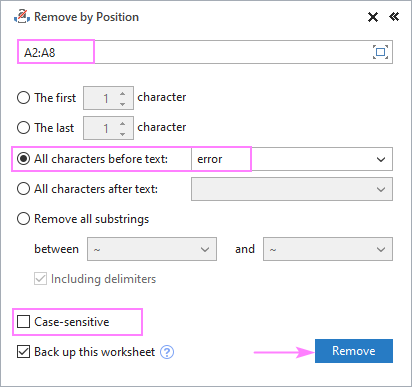
Претпоставимо да сви ваши изворни низови садрже неку уобичајену реч или текст и желите да избришете све пре или после тог текста. Да бисте то урадили, изаберите изворне податке, покрените алатку Уклони по позицији и конфигуришите је као што је приказано испод:
- Изаберите Сви знакови пре текста или Сви знакови после текста опције и откуцајте кључни текст (или знак) у следеће поље
- У зависности од тога да ли велика и мала слова треба да се третирају као различити или исти карактери, означите или опозовите избор у пољу за потврду Разликовање великих и малих слова .
- Притисните Уклони .
У овом примеру уклањамо све знакове који претходе речи „грешка“ у ћелијама А2:А8:
И добити тачно резултат који тражимо:
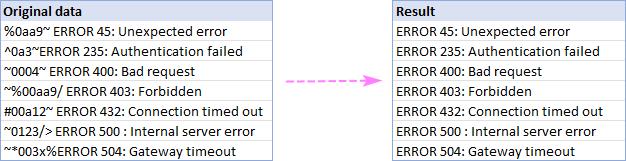
Уклоните текст између два знака
У ситуацији када се небитна информација налази између 2 специфична знака, ево како можете га брзо избрисати:
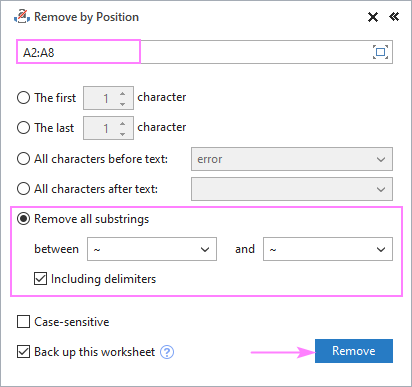
- Изаберите Уклони све поднизове и укуцајте два знака у поља испод.
- Ако треба уклонити и знакове „између“ , означите поље Укључујући разграниче .
- Кликните на Уклони .
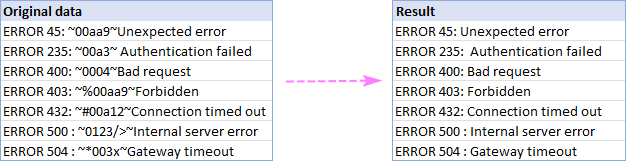
Као пример, бришемо све између два знака тилде (~) и добијамо савршено очишћене низове као резултат:
Да бисте испробали друге корисне функције укључене у овај мултифункционални алат, препоручујем вам да преузмете е верзија процене на крају овог поста. Хвала вам што читате и надамо се да се видимо на нашем блогу следеће недеље!
Доступна преузимања
Уклоните прве или последње знакове - примере (.клсм фајл)
Ултимате Суите - пробна верзија (.еке датотека)
и размак (*, ) у пољу Пронађи шта.Обратите пажњу да не замењујемо само зарез, већ и зарез и размак да бисмо спречили вођење празнине у резултатима. Ако су ваши подаци одвојени зарезима без размака, користите звездицу иза које следи зарез (*,).
Да бисте избрисали текст између две зарезе , користите звездицу окружену зарезима (,*,).
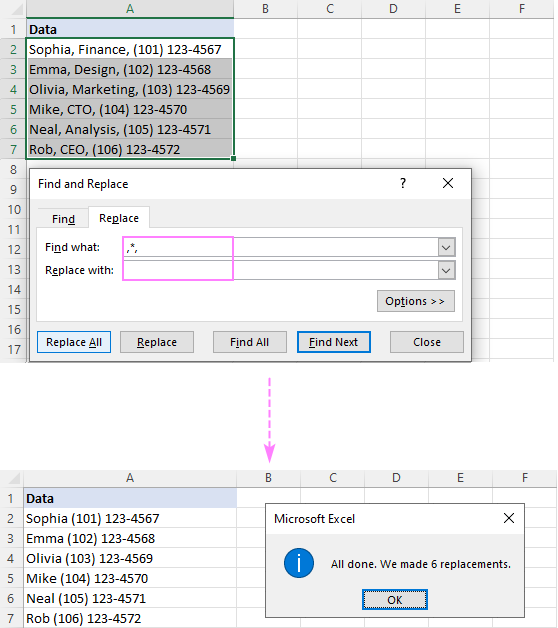
Савет. Ако бисте радије имали имена и бројеве телефона одвојене зарезом, унесите зарез (,) у поље Замени са .
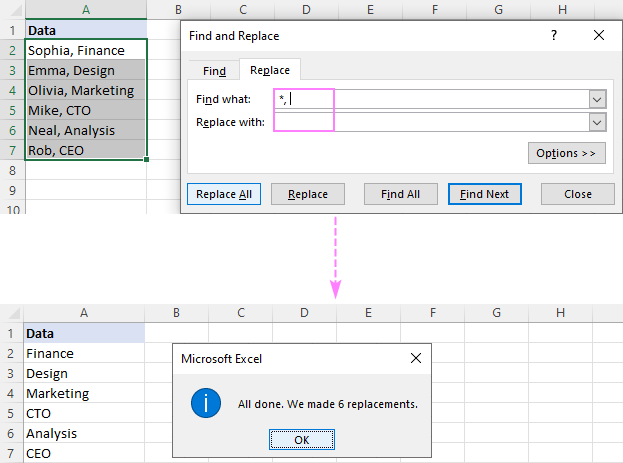
Уклоните део текста помоћу Фласх Филл
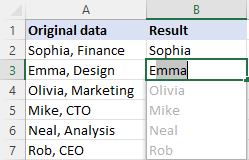
У модерним верзијама Екцел-а (2013 и новије), постоји још један лак начин за искорењивање текста који претходи или следи одређеном карактеру – функција Фласх Филл. Ево како то функционише:
- У ћелију поред прве ћелије са вашим подацима унесите очекивани резултат и притисните Ентер .
- Почните да куцате одговарајућу вредност у следећу ћелију. Када Екцел осети образац у вредностима које уносите, приказаће преглед преосталих ћелија које прате исти образац.
- Притисните тастер Ентер да бисте прихватили предлог.
Готово!
Уклоните текст помоћу формула
У Мицрософт Екцел-у, многе манипулације подацима које се изводе коришћењем уграђених функција такође могу да се изврше помоћу формуле. За разлику од претходних метода, формуле не уносе никакве промене у оригиналне податке и дају вам већу контролу над њимарезултате.
Како уклонити све после одређеног знака
Да бисте избрисали текст после одређеног знака, генеричка формула је:
ЛЕФТ( ћелија , ПРЕТРАГА (" цхар ", целл ) -1)Овде користимо функцију СЕАРЦХ да добијемо позицију карактера и проследимо га функцији ЛЕФТ, тако да извуче одговарајући број знакова од почетка стринга. Један знак се одузима од броја који враћа СЕАРЦХ да би се искључио граничник из резултата.
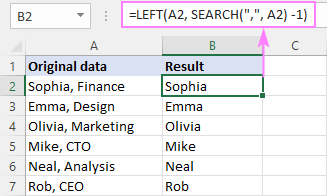
На пример, да бисте уклонили део низа после зареза, унесите формулу испод у Б2 и превуците је надоле кроз Б7 :
=LEFT(A2, SEARCH(",", A2) -1)
Како уклонити све пре одређеног знака
Да бисте избрисали део текстуалног низа пре одређеног знака, генеричка формула је:
ДЕСНО( ћелија , ЛЕН( ћелија ) - СЕАРЦХ(" цхар ", ћелија ))Овде поново израчунавамо позицију циљног карактера уз помоћ СЕАРЦХ, одузимамо је од укупне дужине стринга коју враћа ЛЕН и преносимо разлику у функцију ДЕСНО, тако да она повлачи толико знакова са краја стринг.
На пример, да бисте уклонили текст испред зареза, формула је:
=RIGHT(A2, LEN(A2) - SEARCH(",", A2))
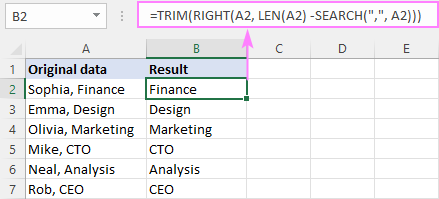
У нашем случају, иза зареза следи знак за размак. Да бисмо избегли водеће размаке у резултатима, умотавамо основну формулу у функцију ТРИМ:
=TRIM(RIGHT(A2, LEN(A2) - SEARCH(",", A2)))
Напомене:
- Обојеод горњих примера претпоставља се да постоји само једна инстанца граничника у оригиналном низу. Ако постоји више појављивања, текст ће бити уклоњен пре/после прве инстанце .
- Функција СЕАРЦХ не разликује велика и мала слова , што значи да нема разлике између мала и велика слова. Ако је ваш специфични знак слово и желите да разликујете велика и мала слова, онда користите функцију ФИНД различити на велика и мала слова уместо СЕАРЦХ.
Како да избришете текст након Н-тог појављивања знака
У ситуацији када изворни низ садржи више инстанци граничника, можда ћете имати потребу да уклоните текст након одређене инстанце. За ово користите следећу формулу:
ЛЕФТ( целл , ФИНД("#", СУБСТИТУТЕ( целл , " цхар ", "#" , н )) -1)Где је н појављивање знака након чега треба уклонити текст.
Унутрашња логика ове формуле захтева коришћење неког знака који није присутан нигде у изворним подацима, хеш симбол (#) у нашем случају. Ако се овај знак појављује у вашем скупу података, онда користите нешто друго уместо „#“.
На пример, да бисте уклонили све после 2. запете у А2 (и самог зареза), формула је:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
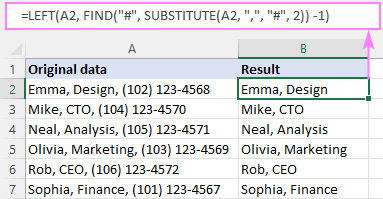
Како ова формула функционише:
Кључни део формуле је функција ФИНД која израчунава позиција н-тогграничник (запета у нашем случају). Ево како:
Други зарез у А2 замењујемо хеш симболом (или било којим другим знаком који не постоји у вашим подацима) уз помоћ СУБСТИТУТЕ:
SUBSTITUTE(A2, ",", "#", 2)
Резултирајући стринг иде до 2. аргумента ФИНД, тако да проналази позицију "#" у том низу:
FIND("#", "Emma, Design# (102) 123-4568")
ФИНД нам говори да је "#" 13. знак у низу. Да бисте сазнали број знакова који претходе њему, само одузмите 1 и добићете 12 као резултат:
FIND("#", SUBSTITUTE(A2, ",", "#", 2)) - 1
Овај број иде директно у аргумент нум_цхарс од ЛИЈЕВО тражећи да повуче првих 12 знакова из А2:
=LEFT(A2, 12)
То је то!
Како избрисати текст прије Н-тог појављивања знака
Генеричка формула за уклањање подниза пре одређеног знака је:
РИГХТ(СУБСТИТУТЕ( целл , " цхар ", "#", н ), ЛЕН( целл ) - ФИНД("#", СУБСТИТУТЕ( целл , " цхар ", "#", н )) -1)На пример, да бисмо уклонили текст испред 2. зареза у А2, формула је:
=RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2)) -1)
Да бисмо елиминисали водећи размак, поново користимо ТРИМ функционише као омотач:
=TRIM(RIGHT(SUBSTITUTE(A2, ",", "#", 2), LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))))
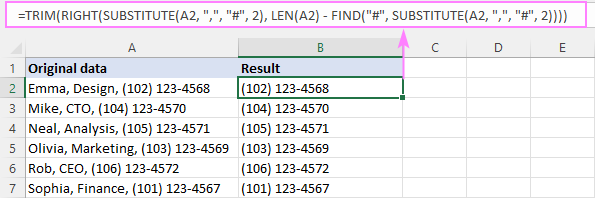
Како ова формула функционише:
Укратко, сазнајемо колико је знакова иза н-тог граничника и издвојити подниз одговарајуће дужине са десне стране. Испод је рашчламба формуле:
Прво, замењујемо 2. зарез у А2 хешомсимбол:
SUBSTITUTE(A2, ",", "#", 2)
Резултирајући стринг иде у аргумент тект ДЕСНО:
RIGHT("Emma, Design# (102) 123-4568", …
Даље, морамо дефинише колико знакова треба издвојити са краја стринга. За ово, налазимо позицију хеш симбола у горњем низу (који је 13):
FIND("#", SUBSTITUTE(A2, ",", "#", 2))
и одузмемо га од укупне дужине стринга (која је једнака 28):
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", 2))
Разлика (15) иде до другог аргумента ДЕСНО дајући му упутства да извуче последњих 15 знакова из стринга у првом аргументу:
RIGHT("Emma, Design# (102) 123-4568", 15)
Излаз је подниз " (102) 123-4568", који је веома близу жељеном исходу, осим водећих размака. Дакле, користимо функцију ТРИМ да бисмо је се решили.
Како уклонити текст након последњег појављивања знака
У случају да су ваше вредности раздвојене променљивим бројем граничника, можда желите да уклоните све после последње инстанце тог граничника. Ово се може урадити са следећом формулом:
ЛЕФТ( целл , ФИНД("#", СУБСТИТУТЕ( целл , " цхар ", "# ", ЛЕН( целл ) - ЛЕН(СУБСТИТУТЕ( целл , " цхар ", "")))) -1)Претпоставимо колону А садржи разне информације о запосленима, али вредност иза последњег зареза је увек број телефона. Ваш циљ је да уклоните бројеве телефона и задржите све остале детаље.
Да бисте постигли циљ, можете да уклоните текст после последњег зареза у А2 са овимформула:
=LEFT(A2, FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))) -1)
Копирајте формулу низ колону и добићете овај резултат:

Како ово формула функционише:
Суштина формуле је да одредимо позицију последњег граничника (зареза) у стрингу и повучемо подниз с лева нагоре до граничника. Добијање положаја граничника је најзахтјевнији део, а ево како то радимо:
Прво, сазнајемо колико зареза има у оригиналном низу. За ово, сваки зарез замењујемо ничим ("") и сервирамо резултујући стринг функцији ЛЕН:
LEN(SUBSTITUTE(A2, ",",""))
За А2, резултат је 35, што је број знакова у А2 без зареза.
Одузмите горњи број од укупне дужине стринга (38 знакова):
LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))
… и добићете 3, што је укупан број зареза у А2 (а такође и редни број последњег зареза).
Даље, користите већ познату комбинацију функција ФИНД и СУБСТИТУТЕ да бисте добили позицију последњег зареза у низу. Број инстанце (3. зарез у нашем случају) је обезбеђен преко горе поменуте формуле ЛЕН СУБСТИТУТЕ:
FIND("#", SUBSTITUTE(A2, ",", "#", 3))
Изгледа да је 3. зарез 23. знак у А2, што значи да нам је потребно да бисте издвојили 22 знака који му претходе. Дакле, ставили смо горњу формулу минус 1 у аргумент нум_цхарс ЛЕФТ:
LEFT(A2, 23-1)
Како уклонити текст пре последњег појављивања знака
За брисањесве пре последње инстанце одређеног знака, генеричка формула је:
ДЕСНО( ћелија , ЛЕН( ћелија ) - ФИНД("#", СУБСТИТУТЕ( целл , " цхар ", "#", ЛЕН( целл ) - ЛЕН(СУБСТИТУТЕ( целл , " цхар ) ", "")))))))У нашој табели примера, да бисмо избрисали текст пре последњег зареза, формула има овај облик:
=RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",","")))))
Као завршни додир, ми угнездите га у функцију ТРИМ да бисте елиминисали водеће размаке:
=TRIM(RIGHT(A2, LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))))
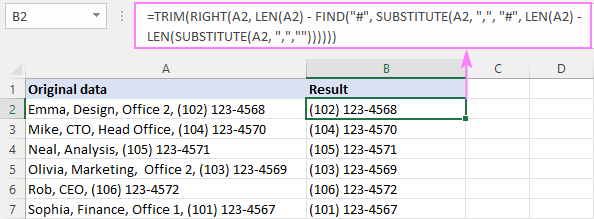
Како ова формула функционише:
Укратко, добијамо позицију последњег зареза као што је објашњено у претходном примеру и одузимамо је од укупне дужине низа:
LEN(A2) - FIND("#", SUBSTITUTE(A2, ",", "#", LEN(A2) - LEN(SUBSTITUTE(A2, ",",""))))
Као резултат, добијамо број знакове после последње зарезе и проследите је функцији ДЕСНО, тако да доноси толико знакова са краја стринга.
Прилагођена функција за уклањање текста са обе стране знака
Као које сте видели у горњим примерима, можете да решите скоро сваки случај употребе коришћењем Екцеловог изворног ф ункције у различитим комбинацијама. Проблем је у томе што морате да запамтите неколико лукавих формула. Хмм, шта ако напишемо сопствену функцију да покријемо све сценарије? Звучи као добра идеја. Дакле, додајте следећи ВБА код у своју радну свеску (детаљни кораци за уметање ВБА у Екцел су овде):
Функција РемовеТект(стр Као стринг, граничник као стринг, појављивање као цео број, ис_афтер АсБоолеан ) Дим делимитер_нум, старт_нум, делимитер_лен Као цео број Дим стр_ресулт Ас стринг делимитер_нум = 0 старт_нум = 1 стр_ресулт = "" делимитер_лен = Лен(делимитер) За и = 1 До појаве делимитер_нум = ИнСтр(старт_нум, в стр,Т) делимитер0 &лт; делимитер_нум Затим старт_нум = делимитер_нум + делимитер_лен Енд Иф Нект и Ако је 0 &лт; делимитер_нум Тада Ако је истина = ис_афтер Тада стр_ресулт = Мид(стр, 1, старт_нум - делимитер_лен - 1) Елсе стр_ресулт = Мид(стр, старт_нум) Енд Иф Енд Ако РемовеТект = стр_ресулт Крајња функцијаНаша функција се зове Уклони текст и има следећу синтаксу:
РемовеТект(стринг, делимитер, оццурренце, ис_афтер)Где:
Стринг - је оригинални текстуални низ. Може се представити референцом ћелије.
Разгранич - знак пре/после којег треба уклонити текст.
Појава - инстанца делимитер.
Ис_афтер - Боолеан вредност која показује на којој страни граничника треба уклонити текст. Може бити један знак или низ знакова.
- ТРУЕ - избришите све иза граничника (укључујући и сам граничник).
- ФАЛСЕ - избришите све пре граничника (укључујући сам граничник).
Када је код функције уметнут у вашу радну свеску, можете уклонити подстрингове из ћелија користећи компактне и елегантне формуле.
На пример, да бисте избрисали
