
Obsah
Naučte sa vzorce a spôsoby bez vzorcov na orezávanie bielych znakov, odstraňovanie špeciálnych symbolov (dokonca aj prvých/posledných znakov N) a rovnakých textových reťazcov pred/za určitými znakmi z viacerých buniek naraz.
Odstránenie tej istej časti textu z viacerých buniek naraz môže byť rovnako dôležité a zložité ako jeho pridanie. Aj keď niektoré spôsoby poznáte, v dnešnom príspevku určite nájdete nové. Podelím sa s vami o množstvo funkcií a ich hotových vzorcov a ako vždy, to najjednoduchšie - bez vzorcov - si nechávam na záver ;)
Vzorce pre tabuľky Google na odstránenie textu z buniek
Začnem štandardnými funkciami pre tabuľky Google, ktoré odstránia vaše textové reťazce a znaky z buniek. Neexistuje na to žiadna univerzálna funkcia, preto uvediem rôzne vzorce a ich kombinácie pre rôzne prípady.
Tabuľky Google: odstránenie bielych znakov
Biele medzery sa môžu ľahko dostať do buniek po importe alebo ak hárok upravuje viac používateľov súčasne. V skutočnosti sú medzery navyše také časté, že aplikácia Tabuľky Google má špeciálny nástroj Trim na odstránenie všetkých bielych medzier.
Stačí vybrať všetky bunky hárkov Google, z ktorých chcete odstrániť biele znaky, a vybrať Data> Orezávanie bielych znakov v ponuke tabuľky:
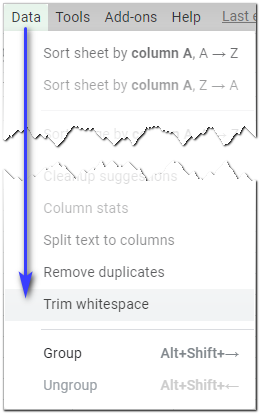
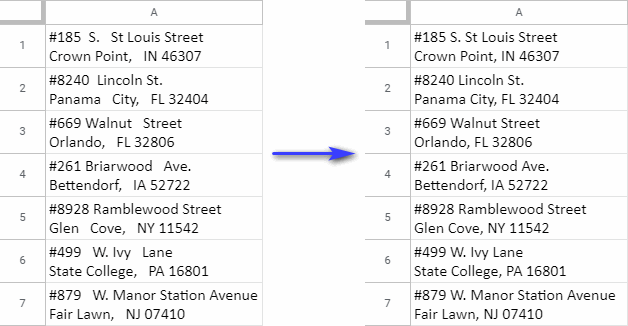
Po kliknutí na túto možnosť sa úplne odstránia všetky úvodné a koncové medzery vo výbere, zatiaľ čo všetky ďalšie medzery medzi údajmi sa zmenšia na jednu:
Odstránenie ďalších špeciálnych znakov z textových reťazcov v hárkoch Google
Bohužiaľ, tabuľky Google neponúkajú nástroj na "orezanie" iných znakov ako medzier. Musíte sa tu zaoberať vzorcami.
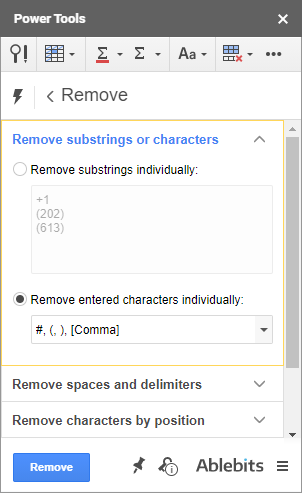
Tip. Alebo namiesto toho použite náš nástroj - Power Tools uvoľní váš rozsah od všetkých znakov, ktoré zadáte kliknutím, vrátane bielych znakov.
Tu som sa obrátil s hashtagmi pred číslami bytov a telefónnymi číslami s pomlčkami a zátvorkami medzi nimi:

Na odstránenie týchto špeciálnych znakov použijem vzorce.
Pomôže mi s tým funkcia SUBSTITUTE. Bežne sa používa na nahradenie jedného znaku iným, ale vy to môžete obrátiť vo svoj prospech a nahradiť nechcené znaky... no, ničím :) Inými slovami, odstrániť.
Pozrime sa, aký argument funkcia vyžaduje:
SUBSTITUTE(text_do_search, search_for, replace_with, [číslo_výskytu])- text_to_search je buď text, ktorý sa má spracovať, alebo bunka, ktorá tento text obsahuje. Požadované.
- search_for je ten znak, ktorý chcete nájsť a vymazať. Požadované.
- replace_with - znak, ktorý vložíte namiesto neželaného symbolu. Požadované.
- occurrence_number - ak existuje viacero výskytov hľadaného znaku, môžete tu určiť, ktorý z nich sa má nahradiť. Je to úplne nepovinné a ak tento argument vynecháte, všetky výskyty budú nahradené niečím novým ( replace_for ).
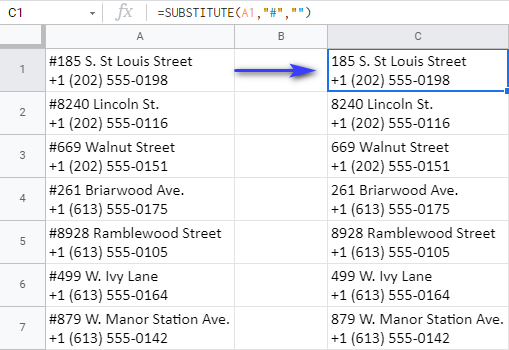
Tak sa poďme hrať. Musím nájsť hashtag ( # ) v A1 a nahradiť ho slovom "nič", ktoré je v tabuľkách označené dvojitými úvodzovkami ( "" ). S ohľadom na to všetko môžem zostaviť nasledujúci vzorec:
=SUBSTITUTE(A1, "#","")
Tip. Hashtag je tiež v dvojitých úvodzovkách, pretože takto by ste mali uvádzať textové reťazce vo vzorcoch v tabuľkách Google.
Potom skopírujte tento vzorec do stĺpca, ak to Tabuľky Google neponúkajú automaticky, a získate adresy bez hashtagov:
Ale čo tie pomlčky a zátvorky? Mali by ste vytvárať ďalšie vzorce? Vôbec nie! Ak do jedného vzorca v tabuľke Google Sheets vložíte viacero funkcií SUBSTITUTE, odstránite všetky tieto znaky z každej bunky:
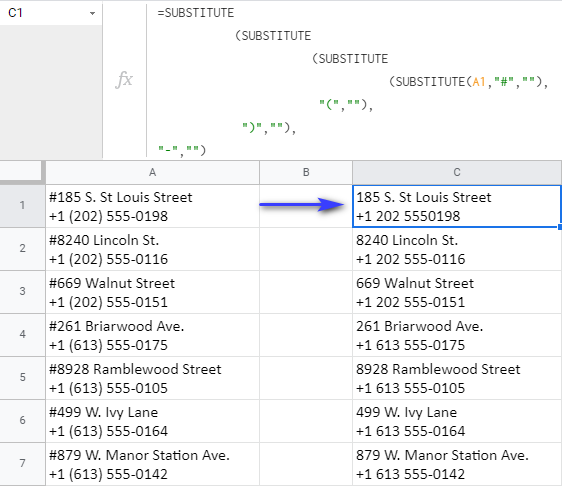
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1, "#",""),"(",""),")",""),"-","")
Tento vzorec odstraňuje znaky jeden po druhom a každý SUBSTITUTE, počnúc od stredu, sa stáva rozsahom, na ktorý sa pozrie ďalší SUBSTITUTE:
Tip. Navyše to môžete zabaliť do ArrayFormula a pokryť celý stĺpec naraz. V tomto prípade zmeňte odkaz na bunku ( A1 ) k údajom v stĺpci ( A1:A7 ):
=ArrayFormula(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1:A7, "#",""),"(",""),""),""),"-","")
Odstránenie konkrétneho textu z buniek v hárkoch Google
Hoci na odstránenie textu z buniek môžete použiť vyššie uvedenú funkciu SUBSTITUTE pre tabuľky Google, rád by som ukázal aj ďalšiu funkciu - REGEXREPLACE.
Jeho názov je skratkou z "regulárneho výrazu nahradiť". A ja budem pomocou regulárnych výrazov vyhľadávať reťazce, ktoré chcem odstrániť a nahradiť ich ' nič' ( "" ).
Tip: Ak nemáte záujem používať regulárne výrazy, na konci tohto príspevku popisujem oveľa jednoduchší spôsob.
Tip: Ak hľadáte spôsoby, ako nájsť a odstrániť duplikáty v hárkoch Google, navštívte radšej tento príspevok na blogu. REGEXREPLACE(text, regular_expression, replacement)
Ako vidíte, funkcia má tri argumenty:
- text - je miesto, kde hľadáte textový reťazec, ktorý chcete odstrániť. Môže to byť samotný text v dvojitých úvodzovkách alebo odkaz na bunku/oblasť s textom.
- regular_expression - váš vyhľadávací vzor, ktorý sa skladá z rôznych kombinácií znakov. Budete hľadať všetky reťazce, ktoré sa zhodujú s týmto vzorom. Ak to môžem povedať, práve v tomto argumente sa odohráva celá zábava.
- náhradný - nový požadovaný textový reťazec.
Predpokladajme, že moje bunky s údajmi obsahujú aj názov krajiny ( US ), ak sú na rôznych miestach v bunkách:

Ako mi REGEXREPLACE pomôže odstrániť ho?
=REGEXREPLACE(A1,"(.*)US(.*)","$1 $2")
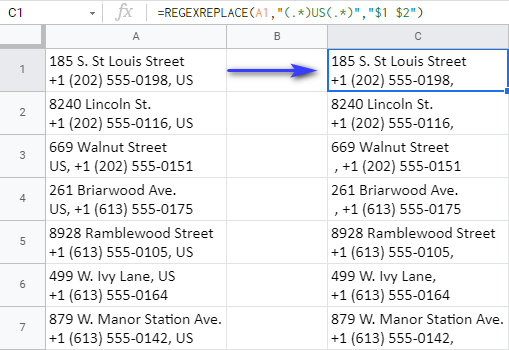
Tu je presný postup, ako tento vzorec funguje:
- prehľadá obsah bunky A1
- pre zhody s touto maskou: "(.*)US(.*)"
Táto maska hovorí funkcii, aby hľadala US bez ohľadu na počet ďalších znakov, ktoré môžu nasledovať (.*) alebo sledujte (.*) názov krajiny.
A celá maska je podľa požiadaviek funkcie umiestnená do dvojitých úvodzoviek :)
- posledný argument - "$1 $2" - je to, čo chcem získať namiesto toho. $1 a $2 každá z nich predstavuje jednu z týchto 2 skupín znakov - (.*) - z predchádzajúceho argumentu. Týmto spôsobom by ste mali tieto skupiny uviesť v treťom argumente, aby vzorec mohol vrátiť všetko, čo prípadne stojí pred a za US
Pokiaľ ide o US samotný, jednoducho ho neuvádzam v 3. argumente - to znamená, že chcem vrátiť všetko z A1 bez . US .
Tip: Existuje špeciálna stránka, na ktorú sa môžete odvolať a na ktorej môžete zostaviť rôzne regulárne výrazy a hľadať text v rôznych pozíciách buniek.
Tip: Pokiaľ ide o tie zvyšné čiarky, pomôže vám zbaviť sa ich vyššie popísaná funkcia SUBSTITUTE ;) Dokonca môžete k funkcii SUBSTITUTE pripojiť aj REGEXREPLACE a všetko vyriešiť jedným vzorcom:
=SUBSTITUTE(REGEXREPLACE(A1,"(.*)US(.*)","$1 $2"),",","")
Odstránenie textu pred/za určitými znakmi vo všetkých vybraných bunkách
Príklad 1. Funkcia REGEXREPLACE pre tabuľky Google
Ak sa chcete zbaviť všetkého pred a za určitými znakmi, pomôže vám aj funkcia REGEXREPLACE. Nezabudnite, že funkcia vyžaduje 3 argumenty:
REGEXREPLACE(text, regulárny_výraz, náhrada)A ako som už spomenul vyššie pri predstavovaní funkcie, práve druhý z nich by ste mali použiť správne, aby funkcia vedela, čo má nájsť a odstrániť.
Ako teda môžem odstrániť adresy a ponechať v bunkách len telefónne čísla?
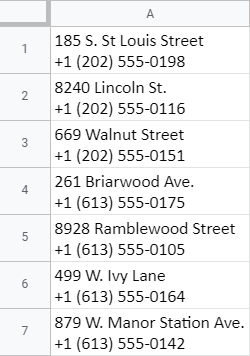
Tu je vzorec, ktorý použijem:
=REGEXREPLACE(A1,".*\n.*(\+.*)","$1")
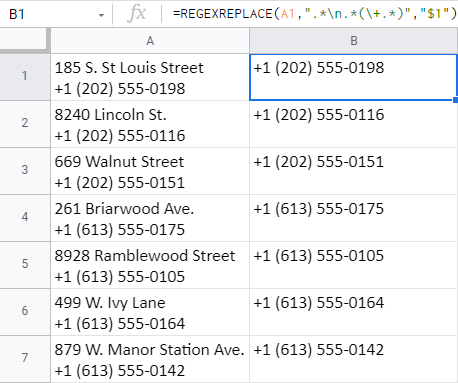
- Tu je regulárny výraz, ktorý v tomto prípade používam: ".*\n.*(\+.*)"
V prvej časti - .*\n.* - Používam spätné lomítko+n aby som zistil, že moja bunka má viac ako jeden riadok. Preto chcem, aby funkcia odstránila všetko pred a za týmto zlomom riadku (vrátane neho).
Druhá časť, ktorá je v zátvorkách (\+.*) hovorí, že chcem zachovať znamienko plus a všetko, čo za ním nasleduje, v nezmenenej podobe. Túto časť beriem do zátvoriek, aby som ju zoskupil a mal na pamäti na neskôr.
Tip: Spätné lomítko sa používa pred znakom plus, aby sa z neho stal hľadaný znak. Bez neho by bolo plus len súčasťou výrazu, ktorý by označoval niektoré iné znaky (ako napríklad hviezdička).
- Pokiaľ ide o posledný argument - $1 - funkcia vráti iba skupinu z druhého argumentu: znamienko plus a všetko, čo nasleduje (\+.*) .
Podobným spôsobom môžete odstrániť všetky telefónne čísla, ale zachovať adresy:
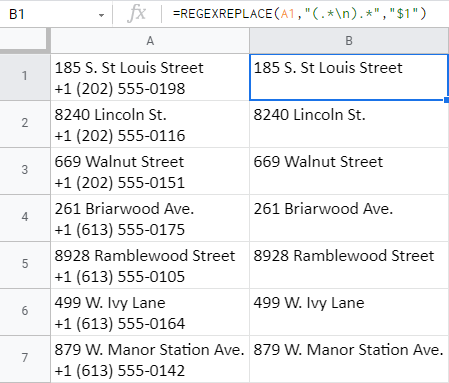
=REGEXREPLACE(A1,"(.*\n).*","$1")
Len tentoraz funkcii poviete, aby zoskupila (a vrátila) všetko, čo je pred zlomom riadku, a zvyšok vymazala:
Príklad 2. RIGHT+LEN+FIND
Existuje niekoľko ďalších funkcií v tabuľkách Google, ktoré umožňujú odstrániť text pred určitým znakom. Sú to funkcie RIGHT, LEN a FIND.
Poznámka: Tieto funkcie pomôžu len vtedy, ak sú záznamy, ktoré sa majú zachovať, rovnako dlhé, ako napríklad telefónne čísla v mojom prípade. Ak nie sú, stačí namiesto nich použiť REGEXREPLACE alebo ešte lepšie jednoduchší nástroj opísaný na konci.
Použitie tejto trojice v určitom poradí mi pomôže dosiahnuť rovnaký výsledok a odstrániť celý text pred znakom - znamienkom plus:
=RIGHT(A1,(LEN(A1)-(FIND("+",A1)-1)))
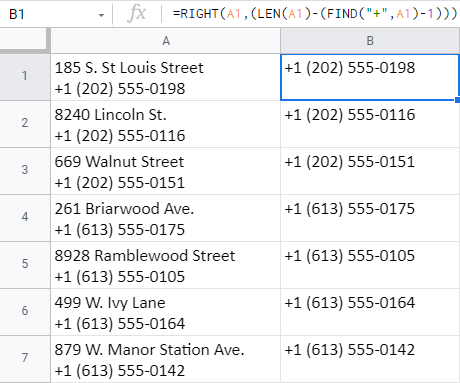
Dovoľte mi vysvetliť, ako tento vzorec funguje:
- FIND("+",A1)-1 vyhľadá číslo pozície znamienka plus v A1 ( 24 ) a odčíta 1, takže celkový súčet nezahŕňa samotné plus: 23 .
- LEN(A1)-(FIND("+",A1)-1) kontroluje celkový počet znakov v A1 ( 40 ) a odpočíta od neho 23 (počítané podľa FIND): 17 .
- A potom RIGHT vráti 17 znakov od konca (vpravo) A1.
Bohužiaľ, tento spôsob v mojom prípade príliš nepomôže odstrániť text za zlomom riadku (vymazať telefónne čísla a zachovať adresy), pretože adresy sú rôzne dlhé.
No, to je v poriadku. Nástroj na konci robí túto prácu lepšie ;)
Odstránenie prvých/posledných N znakov z reťazcov v hárkoch Google
Keď potrebujete odstrániť určitý počet rôznych znakov zo začiatku alebo konca bunky, pomôžu vám aj funkcie REGEXREPLACE a RIGHT/LEFT+LEN.
Poznámka. Keďže som tieto funkcie už predstavil vyššie, tento bod skrátim a uvediem niekoľko hotových vzorcov. Alebo pokojne preskočte na najjednoduchšie riešenie opísané na samom konci.
Ako teda môžem vymazať kódy z týchto telefónnych čísel? Alebo inými slovami, odstrániť prvých 9 znakov z buniek:
- Použite REGEXREPLACE. Vytvorte regulárny výraz, ktorý nájde a odstráni všetko až po 9. znak (vrátane tohto 9. znaku):
=REGEXREPLACE(A1,"(.{9})(.*)","$2")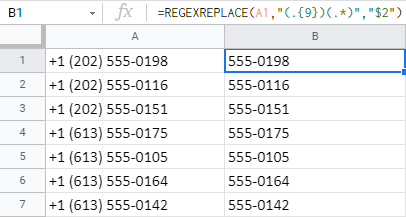 .
. Tip. Ak chcete odstrániť posledných N znakov, stačí vymeniť skupiny v regulárnom výraze:
=REGEXREPLACE(A1,"(.*)(.{9})","$1") - RIGHT/LEFT+LEN tiež počíta počet znakov na vymazanie a vracia zvyšnú časť z konca, resp. začiatku bunky:
=RIGHT(A1,LEN(A1)-9)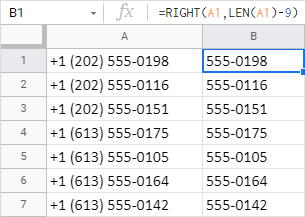
Tip. Ak chcete z buniek odstrániť posledných 9 znakov, nahraďte položku RIGHT (vpravo) položkou LEFT (vľavo):
=LEFT(A1,LEN(A1)-9) - V neposlednom rade je tu funkcia REPLACE. Funkcii poviete, aby zobrala 9 znakov začínajúcich zľava a nahradila ich ničím ( "" ):
=REPLACE(A1,1,9,"")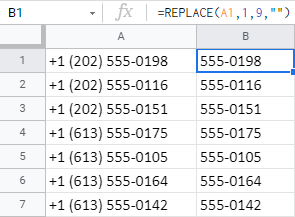
Poznámka: Keďže funkcia REPLACE vyžaduje počiatočnú pozíciu na spracovanie textu, nebude fungovať, ak potrebujete odstrániť N znakov z konca bunky.
Odstránenie konkrétneho textu v hárkoch Google bez použitia vzorca - doplnok Power Tools
Funkcie a všetko je dobré vždy, keď máte čas na zabitie. Ale viete, že existuje špeciálny nástroj, ktorý obsiahne všetky vyššie uvedené spôsoby a jediné, čo máte urobiť, je vybrať požadované tlačidlo? :) Žiadne vzorce, žiadne stĺpce navyše - lepšieho pomocníka si nemôžete priať ;D
Nemusíte mi veriť na slovo, nainštalujte si Power Tools a presvedčte sa sami:
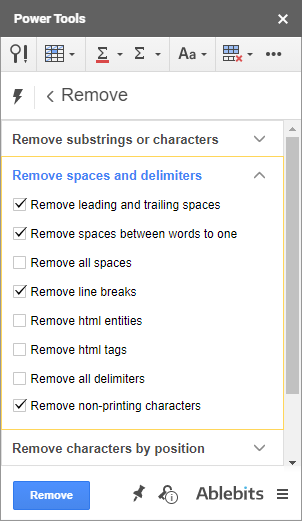
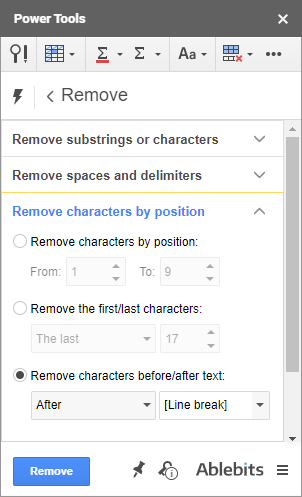
- Prvá skupina umožňuje odstrániť viacero podreťazcov alebo jednotlivých znakov z ľubovoľnej pozície vo všetkých vybraných bunkách naraz:
Ďalší nástroj z programu Power Tools odstráni z časových značiek jednotky času a dátumu. Nazýva sa Split Date & Time:
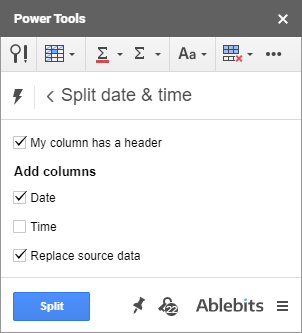
Čo má nástroj na delenie spoločné s odstraňovaním jednotiek času a dátumu? Ak chcete odstrániť čas z časových značiek, vyberte Dátum pretože je to časť, ktorú si chcete ponechať a tiež odškrtnúť Nahradiť zdrojové údaje , rovnako ako na obrázku vyššie.
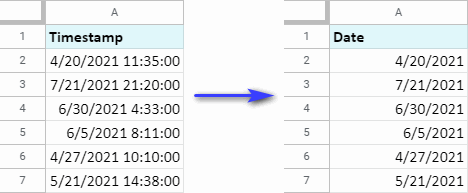
Nástroj extrahuje jednotku dátumu a nahradí ňou celú časovú pečiatku. Alebo inými slovami, tento doplnok pre tabuľky Google odstráni časovú jednotku z časovej pečiatky:
Všetky tieto funkcie a viac ako 30 ďalších nástrojov na úsporu času pre tabuľky môžete získať nainštalovaním doplnku z obchodu Google Store. Prvých 30 dní je úplne bezplatných a plne funkčných, takže máte čas rozhodnúť sa, či sa vám oplatí investovať.
Ak máte akékoľvek otázky týkajúce sa ktorejkoľvek časti tohto príspevku, uvidíme sa v sekcii komentárov nižšie!
