
विषयसूची
व्हाट्सएप को ट्रिम करने के लिए सूत्र और सूत्र-मुक्त तरीके सीखें, विशेष प्रतीकों (यहां तक कि पहले/आखिरी N वर्ण भी) और एक ही बार में कई सेल से कुछ वर्णों के पहले/बाद में समान टेक्स्ट स्ट्रिंग्स को हटा दें। <3
एक साथ कई सेल से टेक्स्ट के एक ही हिस्से को हटाना उतना ही महत्वपूर्ण और पेचीदा हो सकता है जितना कि इसे जोड़ना। भले ही आप कुछ तरीके जानते हों, लेकिन आज के ब्लॉग पोस्ट में आपको नए जरूर मिलेंगे। मैं बहुत सारे फ़ंक्शन और उनके तैयार किए गए फ़ार्मुलों को साझा करता हूं और, हमेशा की तरह, मैं सबसे आसान — फ़ॉर्मूला-मुक्त — अंतिम के लिए सहेजता हूं;)
सेल से टेक्स्ट निकालने के लिए Google पत्रक के फ़ार्मूले
मैं Google पत्रक के मानक कार्यों के साथ शुरू करने जा रहा हूं जो आपके पाठ स्ट्रिंग और वर्णों को सेल से हटा देगा। इसके लिए कोई सार्वभौमिक कार्य नहीं है, इसलिए मैं विभिन्न मामलों के लिए अलग-अलग सूत्र और उनके संयोजन प्रदान करूंगा। उसी समय शीट को संपादित करें। वास्तव में, अतिरिक्त रिक्त स्थान इतने सामान्य हैं कि Google पत्रक में सभी सफेद स्थानों को हटाने के लिए एक विशेष ट्रिम उपकरण है।
बस उन सभी Google पत्रक कक्षों का चयन करें जहाँ से आप खाली स्थान को हटाना चाहते हैं और डेटा > स्प्रैडशीट मेनू में रिक्त स्थान ट्रिम करें:
जैसे ही आप विकल्प पर क्लिक करते हैं, चयन में सभी आगे और पीछे के स्थान पूरी तरह से हटा दिए जाएंगे जबकि सभी अतिरिक्त रिक्त स्थान -शब्द, Google पत्रक के लिए यह ऐड-ऑन टाइम यूनिट को टाइमस्टैम्प से हटा देगा:
आपके पास ये सभी और 30 से अधिक अन्य टाइम-सेवर स्प्रैडशीट्स के लिए इंस्टॉल करके हो सकते हैं Google स्टोर से ऐड-ऑन। पहले 30 दिन पूरी तरह से नि:शुल्क और पूरी तरह कार्यात्मक हैं, इसलिए आपके पास यह तय करने का समय है कि क्या यह किसी निवेश के लायक है।
यदि इस ब्लॉग पोस्ट के किसी भी हिस्से से संबंधित आपके कोई प्रश्न हैं, तो मैं आपसे इसमें मिलूंगा टिप्पणी अनुभाग नीचे!
डेटा के बीच की संख्या घटाकर एक कर दी जाएगी: 
Google पत्रक में टेक्स्ट स्ट्रिंग से अन्य विशेष वर्ण हटाएं
अफ़सोस, Google पत्रक कोई टूल ऑफ़र नहीं करता अन्य पात्रों को 'ट्रिम' करने के लिए लेकिन रिक्त स्थान। आपको यहां सूत्रों से निपटना होगा।
युक्ति। या इसके बजाय हमारे टूल का उपयोग करें - पावर टूल्स व्हाइटस्पेस सहित आपके द्वारा क्लिक में निर्दिष्ट किसी भी वर्ण से आपकी सीमा को मुक्त कर देगा।
यहां मैंने अपार्टमेंट नंबर से पहले हैशटैग और बीच में डैश और ब्रैकेट के साथ फोन नंबर दिए हैं:

मैं उन विशेष वर्णों को हटाने के लिए सूत्रों का उपयोग करूंगा।
सब्स्टीट्यूट फंक्शन इसमें मेरी मदद करेगा। यह आम तौर पर एक वर्ण को दूसरे वर्ण से बदलने के लिए उपयोग किया जाता है, लेकिन आप इसे अपने लाभ के लिए बदल सकते हैं और अवांछित वर्णों को ... से बदल सकते हैं, कुछ भी नहीं :) दूसरे शब्दों में, इसे हटा दें।
आइए देखें कि फ़ंक्शन क्या तर्क देता है आवश्यकता है:
SUBSTITUTE(text_to_search, search_for, replace_with, [occurrence_number])- text_to_search या तो संसाधित किया जाने वाला टेक्स्ट है या वह सेल जिसमें वह टेक्स्ट है। आवश्यक.
- search_for वह वर्ण है जिसे आप ढूँढना और हटाना चाहते हैं. आवश्यक।
- replace_with — एक वर्ण जिसे आप अवांछित प्रतीक के बजाय सम्मिलित करेंगे। आवश्यक.
- occurrence_number — यदि आपके द्वारा खोजे जा रहे वर्ण के कई उदाहरण हैं, तो यहां आप निर्दिष्ट कर सकते हैं कि किसे बदलना है. यह पूरी तरह से वैकल्पिक है,और अगर आप इस तर्क को छोड़ देते हैं, तो सभी उदाहरण कुछ नए ( replace_for ) से बदल दिए जाएंगे।
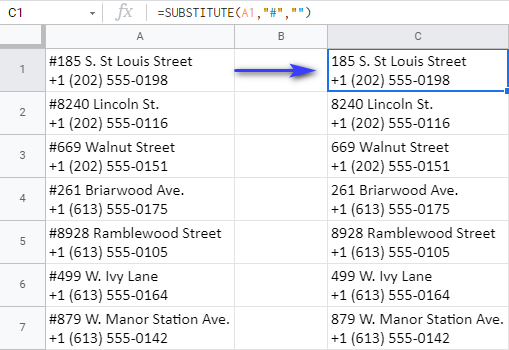
तो चलिए खेलते हैं। मुझे A1 में एक हैशटैग ( # ) ढूंढना है और इसे 'कुछ नहीं' से बदलना है जो डबल कोट्स ( "" ) के साथ स्प्रेडशीट में चिह्नित है। इन सब बातों को ध्यान में रखते हुए, मैं निम्नलिखित सूत्र बना सकता हूं:
=SUBSTITUTE(A1,"#","")
युक्ति। हैशटैग दोहरे उद्धरण चिह्नों में भी है क्योंकि इस तरह से आपको Google पत्रक फ़ार्मुलों में टेक्स्ट स्ट्रिंग्स का उल्लेख करना चाहिए।
यदि Google पत्रक स्वचालित रूप से ऐसा करने की पेशकश नहीं करता है, तो इस सूत्र को कॉलम के नीचे कॉपी करें, और आपको हैशटैग के बिना अपने पते मिल जाएंगे:
लेकिन क्या उन डैश और ब्रैकेट के बारे में? क्या आपको अतिरिक्त सूत्र बनाने चाहिए? बिल्कुल भी नहीं! यदि आप एक Google पत्रक सूत्र में एकाधिक स्थानापन्न कार्य करते हैं, तो आप प्रत्येक कक्ष से इन सभी वर्णों को हटा देंगे:
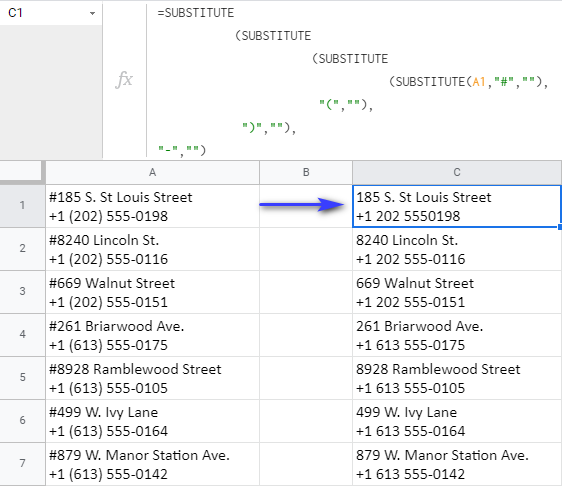
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1,"#",""),"(",""),")",""),"-","")
यह सूत्र एक-एक करके वर्णों को हटाता है और प्रत्येक स्थानापन्न, मध्य से शुरू करता है , अगले स्थानापन्न के लिए देखने की सीमा बन जाती है:
युक्ति। और तो और, आप इसे ArrayFormula में रैप कर सकते हैं और पूरे कॉलम को एक बार में कवर कर सकते हैं। इस स्थिति में, सेल संदर्भ ( A1 ) को कॉलम में अपने डेटा ( A1:A7 ) में भी बदलें:
=ArrayFormula(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1:A7,"#",""),"(",""),")",""),"-",""))
इसमें से विशिष्ट टेक्स्ट हटाएं Google पत्रक में सेल
यद्यपि आप सेल से पाठ निकालने के लिए Google पत्रक के लिए पूर्वोक्त सबस्टिट्यूट फ़ंक्शन का उपयोग कर सकते हैं, मैं दिखाना चाहूंगाएक अन्य कार्य भी — REGEXREPLACE.
इसका नाम 'रेगुलर एक्सप्रेशन रिप्लेस' का संक्षिप्त रूप है। और मैं स्ट्रिंग्स को निकालने और उन्हें ' कुछ नहीं' ( "" ) से बदलने के लिए खोजने के लिए रेगुलर एक्सप्रेशन का उपयोग करने जा रहा हूं।
युक्ति। यदि आप नियमित अभिव्यक्तियों का उपयोग करने में रुचि नहीं रखते हैं, तो मैं इस ब्लॉग पोस्ट के अंत में एक बहुत आसान तरीका बताता हूं।
युक्ति। अगर आप Google पत्रक में डुप्लीकेट खोजने और निकालने के तरीके ढूंढ रहे हैं, तो इसके बजाय इस ब्लॉग पोस्ट पर जाएं. REGEXREPLACE(टेक्स्ट, रेगुलर_एक्सप्रेशन, रिप्लेसमेंट)
जैसा कि आप देख सकते हैं, फ़ंक्शन के तीन तर्क हैं:
- टेक्स्ट — वह जगह है जहां आप टेक्स्ट ढूंढ रहे हैं निकालने के लिए स्ट्रिंग। यह स्वयं दोहरे उद्धरण चिह्नों में पाठ हो सकता है या पाठ के साथ किसी सेल/श्रेणी का संदर्भ हो सकता है।
- regular_expression — आपका खोज पैटर्न जिसमें विभिन्न वर्ण संयोजन होते हैं। आप इस पैटर्न से मेल खाने वाली सभी स्ट्रिंग्स की तलाश करेंगे। यह तर्क वह जगह है जहां सारा मज़ा होता है, अगर मैं ऐसा कह सकता हूं।
- प्रतिस्थापन - एक नया वांछित पाठ स्ट्रिंग।
आइए मान लें कि मेरे सेल डेटा के साथ हैं देश का नाम भी शामिल है ( US ) यदि सेल में अलग-अलग स्थान हैं:

REGEXREPLACE इसे हटाने में मेरी मदद कैसे करेगा?
=REGEXREPLACE(A1,"(.*)US(.*)","$1 $2")
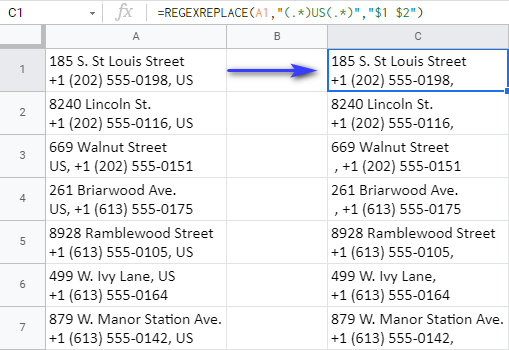
यहां बताया गया है कि सूत्र वास्तव में कैसे काम करता है:
- यह सेल की सामग्री को स्कैन करता है A1
- इस मास्क से मिलान के लिए: "(.*)US(.*)"
यह मास्क फ़ंक्शन को बताता है US के लिए देखें, इससे कोई फर्क नहीं पड़ता कि कितने अन्य वर्ण (.*) से पहले हो सकते हैं या (.*) देश के नाम का अनुसरण करें।
और फ़ंक्शन मांगों के अनुसार पूरे मास्क को डबल कोट्स में रखा गया है :)
- अंतिम तर्क - "$1 $2" - वह है जो मैं इसके बजाय प्राप्त करना चाहता हूं। $1 और $2 प्रत्येक वर्णों के उन 2 समूहों में से एक का प्रतिनिधित्व करता है — (.*) — पिछले तर्क से। आपको तीसरे तर्क में उन समूहों का उल्लेख इस तरह करना चाहिए ताकि सूत्र वह सब कुछ वापस कर सके जो संभवत: US
के पहले और बाद में US के लिए है, मैं बस नहीं तीसरे तर्क में इसका उल्लेख न करें - मतलब, मैं A1 बिना US से सब कुछ वापस करना चाहता हूं।
युक्ति। एक विशेष पृष्ठ है जिसे आप विभिन्न नियमित अभिव्यक्तियों के निर्माण के लिए संदर्भित कर सकते हैं और कोशिकाओं की विभिन्न स्थितियों में पाठ की तलाश कर सकते हैं।
युक्ति। उन शेष अल्पविरामों के लिए, ऊपर वर्णित स्थानापन्न फ़ंक्शन उनसे छुटकारा पाने में मदद करेगा;) आप REGEXREPLACE को स्थानापन्न के साथ भी संलग्न कर सकते हैं और एक सूत्र के साथ सब कुछ हल कर सकते हैं:
=SUBSTITUTE(REGEXREPLACE(A1,"(.*)US(.*)","$1 $2"),",","")
पहले/बाद में पाठ निकालें सभी चयनित सेल में कुछ वर्ण
उदाहरण 1. Google पत्रक के लिए REGEXREPLACE फ़ंक्शन
जब कुछ वर्णों से पहले और बाद में सब कुछ से छुटकारा पाने की बात आती है, तो REGEXREPLACE भी मदद करता है। याद रखें, फ़ंक्शन को 3 तर्कों की आवश्यकता होती है:
REGEXREPLACE(text,रेगुलर_एक्सप्रेशन, रिप्लेसमेंट)और, जैसा कि मैंने ऊपर उल्लेख किया है जब मैंने फ़ंक्शन पेश किया था, यह दूसरा है जिसे आपको सही तरीके से उपयोग करना चाहिए ताकि फ़ंक्शन को पता चले कि क्या खोजना और निकालना है।
तो मैं पतों को कैसे निकालूं और सेल में केवल फ़ोन नंबर रखें?
यहां वह फ़ॉर्मूला है जिसका मैं उपयोग करूंगा:
=REGEXREPLACE(A1,".*\n.*(\+.*)","$1")
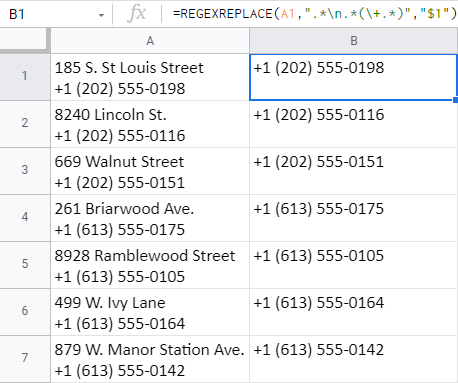
- इस मामले में मैं रेगुलर एक्सप्रेशन का उपयोग करता हूं: ".*\n.*(\+.*)"
पहले भाग में — .*\n .* — मैं यह बताने के लिए बैकस्लैश+n का उपयोग करता हूं कि मेरे सेल में एक से अधिक पंक्तियां हैं। इसलिए मैं चाहता हूं कि फ़ंक्शन उस लाइन ब्रेक (इसमें शामिल) से पहले और बाद में सब कुछ हटा दे।
दूसरा भाग जो कोष्ठक में है (\+.*) कहता है कि मैं प्लस साइन और उसके बाद आने वाली हर चीज बरकरार है। मैं इस भाग को समूहीकृत करने के लिए कोष्ठक में लेता हूँ और इसे बाद के लिए ध्यान में रखता हूँ।
युक्ति। बैकस्लैश का उपयोग प्लस से पहले किया जाता है ताकि आप इसे उस वर्ण में बदल सकें जिसे आप ढूंढ रहे हैं। इसके बिना, प्लस अभिव्यक्ति का केवल एक हिस्सा होगा जो कुछ अन्य पात्रों के लिए खड़ा होता है (उदाहरण के लिए एक तारांकन करता है)।
- अंतिम तर्क के लिए - $1 - यह फ़ंक्शन को केवल दूसरे तर्क से समूह लौटाता है: धन चिह्न और सब कुछ जो (\+.*) के बाद आता है।
इसी तरह से, आप सभी फ़ोन नंबर हटा सकते हैं, फिर भी पते रख सकते हैं:
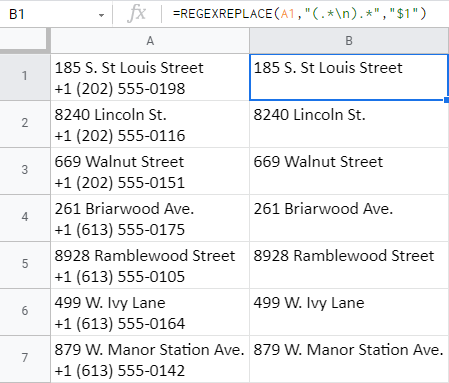
=REGEXREPLACE(A1,"(.*\n).*","$1")
केवल इस बार, आप फ़ंक्शन को समूह (और वापसी) से पहले सब कुछलाइन ब्रेक और बाकी को हटा दें:
उदाहरण 2. RIGHT+LEN+FIND
कुछ और Google पत्रक फ़ंक्शन हैं जो आपको एक निश्चित चरित्र से पहले पाठ। वे राइट, लेन और फाइंड हैं।
नोट। ये कार्य केवल तभी मदद करेंगे जब रिकॉर्ड रखने के लिए समान लंबाई हो, जैसे मेरे मामले में फोन नंबर। यदि वे नहीं हैं, तो बस इसके बजाय REGEXREPLACE का उपयोग करें या इससे भी बेहतर, अंत में वर्णित आसान टूल।
एक विशेष क्रम में इस तिकड़ी का उपयोग करने से मुझे समान परिणाम प्राप्त करने और एक वर्ण से पहले पूरे पाठ को हटाने में मदद मिलेगी - एक धन चिह्न:
=RIGHT(A1,(LEN(A1)-(FIND("+",A1)-1)))
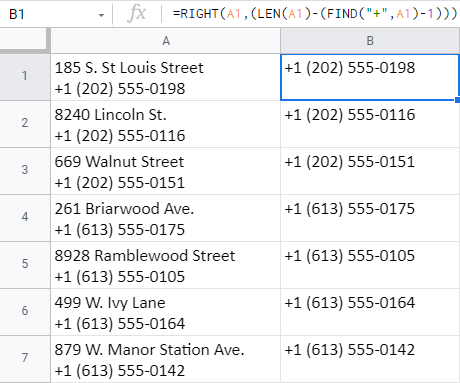
मुझे समझाने दें कि यह सूत्र कैसे काम करता है:
- FIND("+",A1)-1 A1 ( 24) में धन चिह्न की स्थिति संख्या का पता लगाता है ) और 1 घटाता है, इसलिए कुल में प्लस ही शामिल नहीं है: 23 .
- LEN(A1)-(FIND("+",A1)- 1) A1 ( 40 ) में वर्णों की कुल संख्या की जांच करता है और इसमें से 23 घटाता है (FIND द्वारा गिना जाता है): 17 ।
- और फिर राइट A1 के अंत (दाएं) से 17 वर्ण देता है।
दुर्भाग्य से, इस तरह से मेरे मामले में लाइन ब्रेक के बाद टेक्स्ट को हटाने में ज्यादा मदद नहीं मिलेगी (फ़ोन नंबर साफ़ करें और पते रखें), क्योंकि पते अलग-अलग लंबाई के हैं।
खैर, यह ठीक है। अंत में उपकरण इस काम को वैसे भी बेहतर करता है;)
Google पत्रक में स्ट्रिंग से पहले/अंतिम N वर्णों को हटा दें
जब भी आपको किसी को निकालने की आवश्यकता होकिसी सेल के आरंभ या अंत से भिन्न वर्णों की निश्चित संख्या, REGEXREPLACE और RIGHT/LEFT+LEN भी मदद करेंगे।
ध्यान दें। चूंकि मैंने पहले ही इन कार्यों को ऊपर पेश किया है, इसलिए मैं इस बिंदु को छोटा रखूंगा और कुछ तैयार सूत्र प्रदान करूंगा। या बिल्कुल अंत में वर्णित सबसे आसान समाधान के लिए स्वतंत्र महसूस करें।
तो, मैं इन फ़ोन नंबरों से कोड कैसे मिटा सकता हूँ? या, दूसरे शब्दों में, सेल से पहले 9 वर्णों को हटा दें:
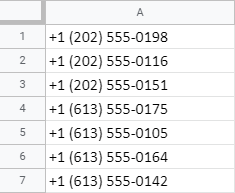
- REGEXREPLACE का उपयोग करें। एक रेगुलर एक्सप्रेशन बनाएं जो 9वें वर्ण तक (उस 9 वर्ण सहित) सब कुछ खोजेगा और हटाएगा:
=REGEXREPLACE(A1,"(.{9})(.*)","$2")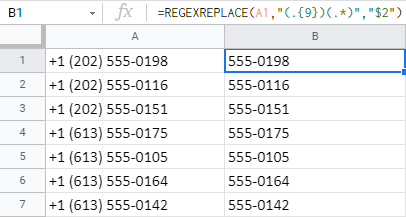 ।
। युक्ति। अंतिम N वर्णों को निकालने के लिए, बस समूहों को नियमित अभिव्यक्ति में स्वैप करें:
=REGEXREPLACE(A1,"(.*)(.{9})","$1") - Right/LEFT+LEN भी हटाए जाने वाले वर्णों की संख्या की गणना करें और शेष भाग वापस करें सेल के अंत या शुरुआत से क्रमशः:
=RIGHT(A1,LEN(A1)-9)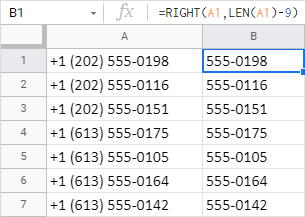
युक्ति। सेल से अंतिम 9 वर्णों को हटाने के लिए, RIGHT को LEFT से बदलें:
=LEFT(A1,LEN(A1)-9) - अंतिम लेकिन सबसे महत्वपूर्ण REPLACE फ़ंक्शन है। आप इसे बाएँ से शुरू करते हुए 9 वर्णों को लेने के लिए कहते हैं और उन्हें कुछ भी नहीं ( "" ) से बदलने के लिए कहते हैं:
=REPLACE(A1,1,9,"")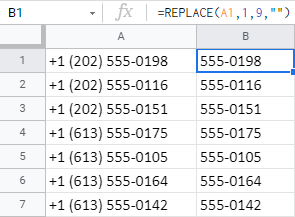
ध्यान दें। चूँकि REPLACE को पाठ को संसाधित करने के लिए एक प्रारंभिक स्थिति की आवश्यकता होती है, यदि आपको सेल के अंत से N वर्णों को हटाने की आवश्यकता होती है तो यह काम नहीं करेगा।
Google पत्रक में विशिष्ट टेक्स्ट को निकालने का फ़ॉर्मूला-मुक्त तरीका — पावर टूल्सऐड-ऑन
फंक्शंस और जब भी आपके पास मारने का समय हो तो सब अच्छा है। लेकिन क्या आप जानते हैं कि एक विशेष उपकरण है जो उपरोक्त सभी तरीकों को अपनाता है और आपको केवल आवश्यक रेडियो बटन का चयन करना है? :) कोई सूत्र नहीं, कोई अतिरिक्त कॉलम नहीं — आप एक बेहतर साथी की कामना नहीं कर सकते थे; D
आपको इसके लिए मेरा कहना मानने की ज़रूरत नहीं है, बस पावर टूल्स इंस्टॉल करें और इसे अपने लिए देखें:<3
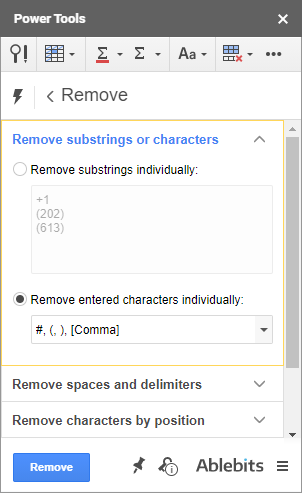
- पहला समूह आपको एक समय में सभी चयनित सेल में किसी भी स्थिति से कई सबस्ट्रिंग्स या अलग-अलग वर्णों को हटाने देता है :
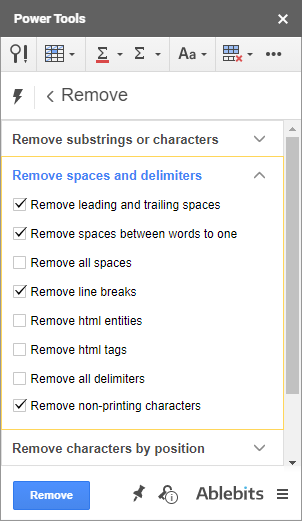
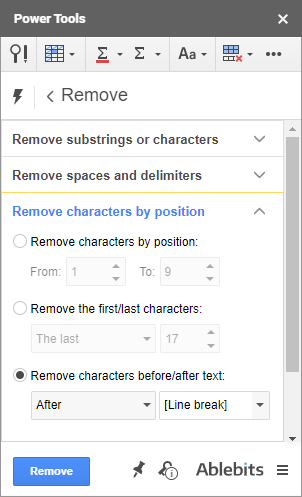
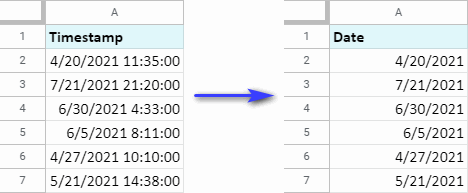
पावर टूल्स का एक अन्य उपकरण टाइमस्टैम्प से समय और दिनांक इकाइयों को हटा देगा। इसे स्प्लिट डेट कहा जाता है & समय:
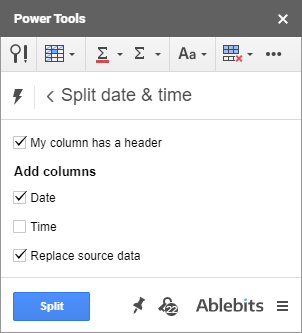
विभाजन उपकरण का समय और दिनांक इकाइयों को हटाने से क्या लेना-देना है? खैर, टाइमस्टैम्प से समय निकालने के लिए, तारीख चुनें क्योंकि यह एक हिस्सा है जिसे आप रखना चाहते हैं और ऊपर दिए गए स्क्रीनशॉट की तरह स्रोत डेटा बदलें पर भी टिक करें।
उपकरण दिनांक इकाई निकालेगा और पूरे टाइमस्टैम्प को इसके साथ बदल देगा। या, दूसरे में
