
Obsah
Naučte se vzorce a způsoby bez vzorců, jak ořezávat bílé znaky, odstraňovat speciální symboly (dokonce i první/poslední N znaků) a stejné textové řetězce před/za určitými znaky z více buněk najednou.
Odstranění stejné části textu z několika buněk najednou může být stejně důležité a záludné jako jeho přidání. I když některé způsoby znáte, v dnešním příspěvku určitě najdete nové. Podělím se s vámi o spoustu funkcí a jejich hotových vzorců a jako vždy si to nejjednodušší - bez vzorců - nechám na konec ;).
Vzorce pro tabulky Google pro odstranění textu z buněk
Začnu standardními funkcemi pro Tabulky Google, které odstraní vaše textové řetězce a znaky z buněk. Neexistuje pro to žádná univerzální funkce, proto uvedu různé vzorce a jejich kombinace pro různé případy.
Tabulky Google: odstranění bílých znaků
Bílé znaky se mohou snadno dostat do buněk po importu nebo v případě, že list upravuje více uživatelů současně. Mezery navíc jsou tak časté, že aplikace Tabulky Google má speciální nástroj Trim, který odstraňuje všechny bílé znaky.
Stačí vybrat všechny buňky Tabulky Google, ve kterých chcete odstranit bílé znaky, a zvolit možnost Data> Oříznout bílé znaky v nabídce tabulky:
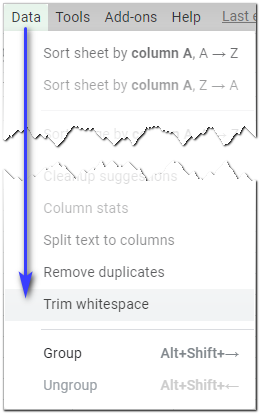
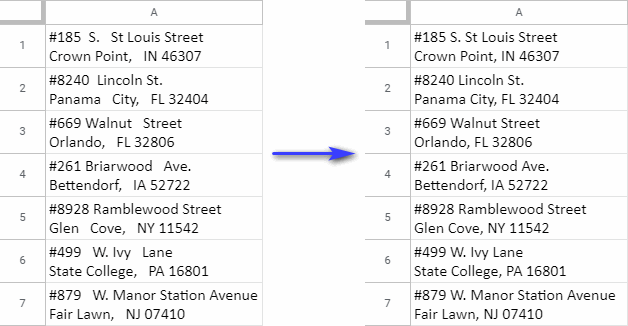
Po kliknutí na tuto možnost budou všechny počáteční a koncové mezery ve výběru zcela odstraněny, zatímco všechny další mezery mezi daty budou zmenšeny na jednu:
Odstranění dalších speciálních znaků z textových řetězců v Tabulkách Google
Bohužel Tabulky Google nenabízejí nástroj pro "ořezávání" jiných znaků než mezer. Zde se musíte vypořádat se vzorci.
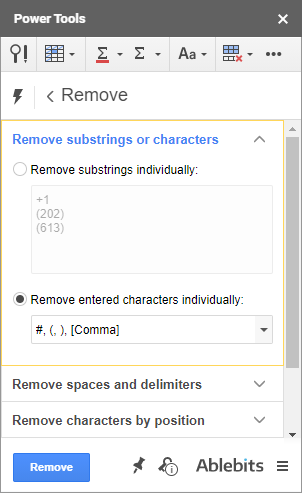
Tip. Nebo místo toho použijte náš nástroj - Power Tools uvolní rozsah od všech znaků, které zadáte kliknutím, včetně bílých znaků.
Zde jsem se obrátil s hashtagy před čísly bytů a telefonními čísly s pomlčkami a závorkami mezi nimi:

K odstranění těchto speciálních znaků použiji vzorce.
S tím mi pomůže funkce SUBSTITUTE. Obvykle se používá k nahrazení jednoho znaku jiným, ale vy to můžete obrátit ve svůj prospěch a nahradit nechtěné znaky... no, ničím :) Jinými slovy, odstranit je.
Podívejme se, jaký argument funkce vyžaduje:
SUBSTITUTE(text_do_search, search_for, replace_with, [číslo_výskytu])- text_to_search je buď text, který se má zpracovat, nebo buňka, která tento text obsahuje. Požadováno.
- search_for je znak, který chcete najít a odstranit. Požadováno.
- replace_with - znak, který vložíte místo nechtěného symbolu. Požadováno.
- occurrence_number - pokud existuje více výskytů hledaného znaku, můžete zde určit, který z nich má být nahrazen. Je to zcela nepovinné, a pokud tento argument vynecháte, všechny výskyty budou nahrazeny něčím novým ( replace_for ).
Tak si pojďme hrát. Musím najít hashtag ( # ) v A1 a nahraďte jej slovem "nic", které je v tabulkách označeno dvojitými uvozovkami ( "" ). S ohledem na výše uvedené mohu sestavit následující vzorec:
=SUBSTITUTE(A1, "#","")
Tip: Hashtag je také v dvojitých uvozovkách, protože takto byste měli uvádět textové řetězce ve vzorcích v tabulkách Google.
Pak tento vzorec zkopírujte dolů do sloupce, pokud to Tabulky Google nenabízejí automaticky, a získáte adresy bez hashtagů:
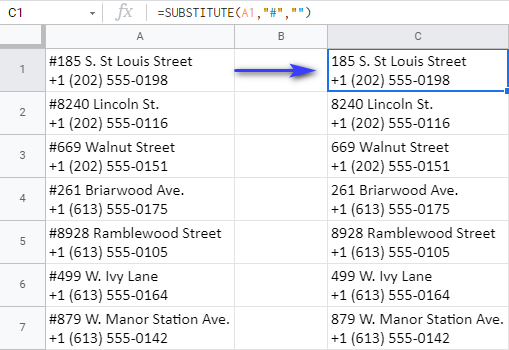
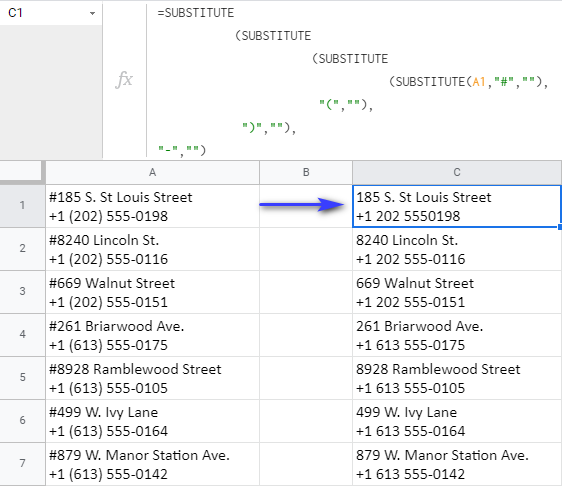
Ale co ty pomlčky a závorky? Máte vytvářet další vzorce? Vůbec ne! Pokud do jednoho vzorce v Tabulkách Google vnoříte více funkcí SUBSTITUTE, odstraníte všechny tyto znaky z každé buňky:
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1, "#",""),"(",""),")",""),"-","")
Tento vzorec odstraňuje znaky jeden po druhém a každý SUBSTITUTE, počínaje středem, se stává rozsahem, který se hledá pro další SUBSTITUTE:
Tip: Navíc můžete tuto funkci zabalit do pole ArrayFormula a pokrýt tak celý sloupec najednou. V takovém případě změňte odkaz na buňku ( A1 ) k vašim datům ve sloupci ( A1:A7 ):
=ArrayFormula(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1:A7, "#",""),"(",""),""),""),"-","")))
Odstranění určitého textu z buněk v Tabulkách Google
Ačkoli můžete pro odstranění textu z buněk použít výše zmíněnou funkci SUBSTITUTE pro Tabulky Google, rád bych vám ukázal i další funkci - REGEXREPLACE.
Jeho název je zkratkou z "regulární výraz nahradit". A já budu pomocí regulárních výrazů vyhledávat řetězce, které chci odstranit, a nahrazovat je těmito řetězci ' nic' ( "" ).
Tip: Pokud nemáte zájem používat regulární výrazy, na konci tohoto příspěvku popisuji mnohem jednodušší způsob.
Tip: Pokud hledáte způsoby, jak najít a odstranit duplicity v tabulkách Google, navštivte raději tento příspěvek na blogu. REGEXREPLACE(text, regulární_výraz, náhrada)
Jak vidíte, funkce má tři argumenty:
- text - je místo, kde hledáte textový řetězec, který chcete odstranit. Může to být samotný text ve dvojitých uvozovkách nebo odkaz na buňku/oblast s textem.
- regular_expression - váš vyhledávací vzor, který se skládá z různých kombinací znaků. Budete hledat všechny řetězce, které tomuto vzoru odpovídají. S tímto argumentem se odehrává celá zábava, pokud to tak mohu říci.
- náhradní - nový požadovaný textový řetězec.
Předpokládejme, že mé buňky s daty obsahují také název země ( US ), pokud jsou na různých místech v buňkách:

Jak mi REGEXREPLACE pomůže s jeho odstraněním?
=REGEXREPLACE(A1,"(.*)US(.*)","$1 $2")
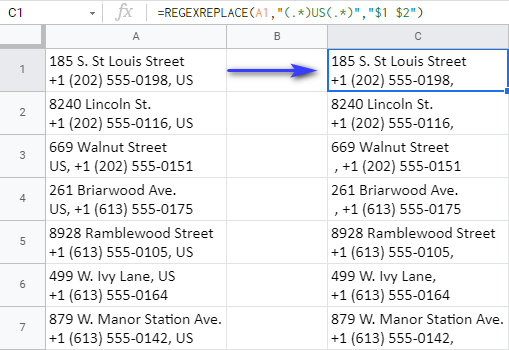
Přesně takhle funguje tento vzorec:
- prohledá obsah buňky A1
- pro shodu s touto maskou: "(.*)US(.*)"
Tato maska říká funkci, že má hledat US bez ohledu na to, kolik dalších znaků může předcházet. (.*) nebo sledujte (.*) název země.
A celá maska je podle požadavků funkce umístěna do dvojitých uvozovek :)
- poslední argument - "$1 $2" - je to, co chci získat místo toho. $1 a $2 každá z nich představuje jednu z těchto 2 skupin znaků - (.*) - z předchozího argumentu. Takto byste měli tyto skupiny uvést ve třetím argumentu, aby vzorec mohl vrátit vše, co případně stojí před a za tímto argumentem. US
Pokud jde o US sám o sobě, prostě ho neuvádím ve 3. argumentu - to znamená, že chci vrátit vše z. A1 bez . US .
Tip: Existuje speciální stránka, na kterou se můžete odkázat a na které můžete sestavit různé regulární výrazy a hledat text v různých pozicích buněk.
Tip: Pokud jde o ty zbývající čárky, pomůže vám zbavit se jich výše popsaná funkce SUBSTITUTE ;) K funkci SUBSTITUTE můžete připojit i REGEXREPLACE a vše vyřešit jedním vzorcem:
=SUBSTITUTE(REGEXREPLACE(A1,"(.*)US(.*)","$1 $2"),",","")
Odstranění textu před/za určitými znaky ve všech vybraných buňkách
Příklad 1. Funkce REGEXREPLACE pro Tabulky Google
Pokud se chcete zbavit všeho před a za určitými znaky, pomůže vám také funkce REGEXREPLACE. Nezapomeňte, že funkce vyžaduje 3 argumenty:
REGEXREPLACE(text, regulární_výraz, náhrada)A jak jsem se zmínil výše, když jsem funkci představoval, právě druhý z nich byste měli správně použít, aby funkce věděla, co má najít a odstranit.
Jak tedy odstranit adresy a ponechat v buňkách pouze telefonní čísla?
Zde je vzorec, který použiji:
=REGEXREPLACE(A1,".*\n.*(\+.*)","$1")
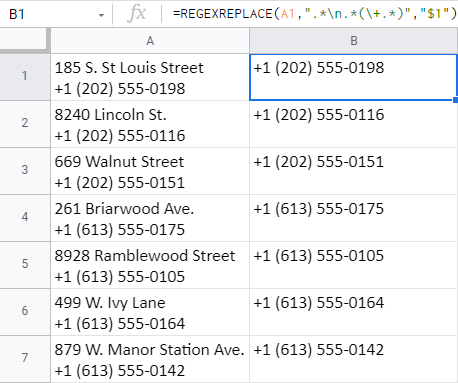
- Zde je regulární výraz, který v tomto případě používám: ".*\n.*(\+.*)"
V první části - .*\n.* - Používám zpětné lomítko+n abych zjistil, že moje buňka má více než jeden řádek. Chci tedy, aby funkce odstranila vše před a za tímto zlomem řádku (včetně něj).
Druhá část, která je v závorce (\+.*) říká, že chci zachovat znaménko plus a vše, co za ním následuje, v nezměněné podobě. Tuto část beru do závorek, abych ji seskupil a měl ji na paměti pro pozdější použití.
Tip: Zpětné lomítko se používá před znakem plus, aby se z něj stal hledaný znak. Bez něj by plus bylo jen částí výrazu, která označuje některé další znaky (jako například hvězdička).
- Pokud jde o poslední argument - $1 - funkce vrátí pouze skupinu z druhého argumentu: znaménko plus a vše, co následuje. (\+.*) .
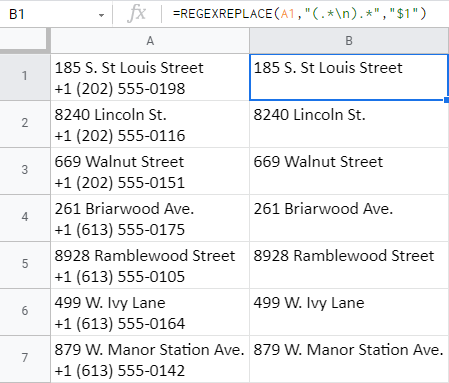
Podobným způsobem můžete odstranit všechna telefonní čísla, ale zachovat adresy:
=REGEXREPLACE(A1,"(.*\n).*","$1")
Jen tentokrát funkci řeknete, aby seskupila (a vrátila) vše před zlomem řádku a zbytek vymazala:
Příklad 2. RIGHT+LEN+FIND
Existuje několik dalších funkcí v tabulkách Google, které umožňují odstranit text před určitým znakem. Jsou to funkce RIGHT, LEN a FIND.
Poznámka: Tyto funkce pomohou pouze v případě, že záznamy, které mají být zachovány, mají stejnou délku, jako v mém případě telefonní čísla. Pokud tomu tak není, stačí místo toho použít REGEXREPLACE nebo ještě lépe jednodušší nástroj popsaný na konci.
Použití této trojice v určitém pořadí mi pomůže dosáhnout stejného výsledku a odstranit celý text před znakem - znaménkem plus:
=RIGHT(A1,(LEN(A1)-(FIND("+",A1)-1)))
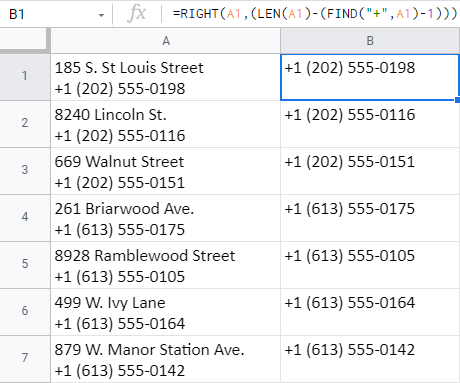
Vysvětlím vám, jak tento vzorec funguje:
- FIND("+",A1)-1 vyhledá číslo pozice znaménka plus v A1 ( 24 ) a odečte 1, takže celkový součet nezahrnuje samotné plus: 23 .
- LEN(A1)-(FIND("+",A1)-1) zkontroluje celkový počet znaků v A1 ( 40 ) a odečte od něj 23 (počítáno podle FIND): 17 .
- A pak RIGHT vrátí 17 znaků od konce (vpravo) A1.
Bohužel tento způsob v mém případě příliš nepomůže odstranit text za zlomem řádku (vymazat telefonní čísla a zachovat adresy), protože adresy jsou různě dlouhé.
No, to je v pořádku. Nástroj na konci dělá tuto práci lépe ;)
Odstranění prvních/posledních N znaků z řetězců v Tabulkách Google
Kdykoli potřebujete odstranit určitý počet různých znaků ze začátku nebo konce buňky, pomůže vám REGEXREPLACE a RIGHT/LEFT+LEN.
Poznámka: Vzhledem k tomu, že jsem tyto funkce představil již výše, budu se v tomto bodě držet zkrátka a uvedu několik hotových vzorců. Nebo si klidně odskočte k nejjednoduššímu řešení popsanému na samém konci.
Jak tedy mohu vymazat kódy z těchto telefonních čísel? Nebo jinými slovy, odstranit prvních 9 znaků z buněk:
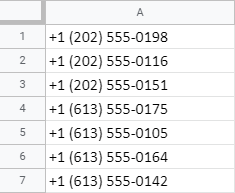
- Použijte REGEXREPLACE. Vytvořte regulární výraz, který najde a odstraní vše až do 9. znaku (včetně tohoto 9. znaku):
=REGEXREPLACE(A1,"(.{9})(.*)","$2")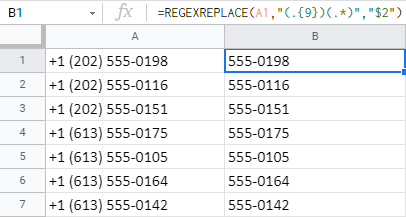 .
. Tip: Chcete-li odstranit posledních N znaků, stačí prohodit skupiny v regulárním výrazu:
=REGEXREPLACE(A1,"(.*)(.{9})","$1") - RIGHT/LEFT+LEN také počítá počet znaků, které se mají odstranit, a vrací zbývající část z konce, resp. začátku buňky:
=RIGHT(A1,LEN(A1)-9)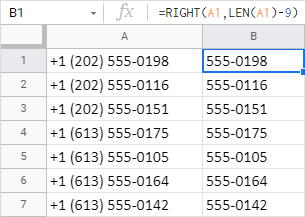
Tip: Chcete-li z buněk odstranit posledních 9 znaků, nahraďte RIGHT znakem LEFT:
=LEFT(A1,LEN(A1)-9) - V neposlední řadě je to funkce REPLACE. Řeknete jí, aby vzala 9 znaků začínajících zleva a nahradila je ničím ( "" ):
=REPLACE(A1,1,9,"")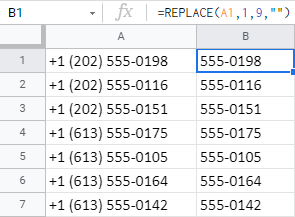
Poznámka: Protože funkce REPLACE vyžaduje počáteční pozici pro zpracování textu, nebude fungovat, pokud potřebujete odstranit N znaků z konce buňky.
Odstranění určitého textu v tabulkách Google bez použití vzorců - doplněk Power Tools
Funkce a všechno je dobré, kdykoli máte čas na zabití. Ale víte, že existuje speciální nástroj, který obsáhne všechny výše zmíněné způsoby a jediné, co musíte udělat, je vybrat požadované tlačítko? :) Žádné vzorce, žádné sloupce navíc - lepšího pomocníka si nemůžete přát ;D
Nemusíte mě brát za slovo, nainstalujte si Power Tools a přesvědčte se sami:
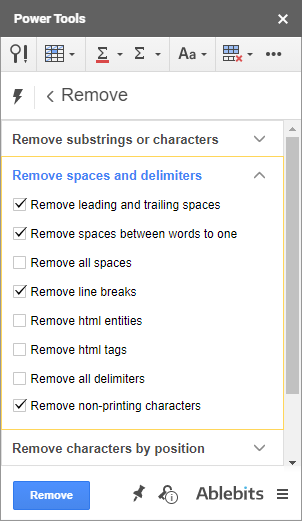
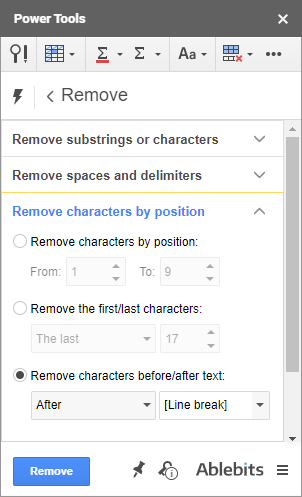
- První skupina umožňuje odstranit více podřetězců nebo jednotlivých znaků z libovolného místa ve všech vybraných buňkách najednou:
Další nástroj z řady Power Tools odstraní z časových značek jednotky času a data. Jmenuje se Split Date & Time:
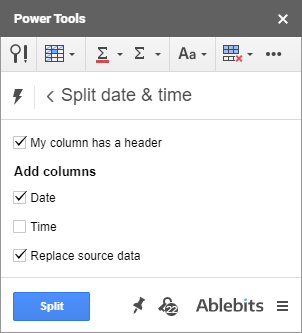
Co má nástroj pro rozdělení společného s odstraněním jednotek času a data? Chcete-li odstranit čas z časových značek, vyberte možnost Datum protože je to část, kterou chcete zachovat a také odškrtnout. Nahrazení zdrojových dat , stejně jako na výše uvedeném snímku obrazovky.
Nástroj extrahuje jednotku data a nahradí jí celé časové razítko. Jinými slovy, tento doplněk pro tabulky Google odstraní z časového razítka jednotku času:
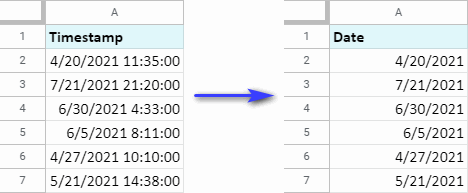
Všechny tyto funkce a více než 30 dalších funkcí, které šetří čas při práci s tabulkami, můžete mít po instalaci doplňku z obchodu Google Store. Prvních 30 dní je zcela zdarma a plně funkční, takže máte čas se rozhodnout, zda se vám vyplatí investovat.
Pokud máte nějaké dotazy týkající se kterékoli části tohoto příspěvku, uvidíme se v komentářích níže!
