
Obsah
V několika posledních článcích jsme se zabývali různými funkcemi Text - těmi, které se používají k manipulaci s textovými řetězci. Dnes se zaměříme na funkci PRAVÁ, která je určena k vrácení určitého počtu znaků z pravé strany řetězce. Stejně jako ostatní textové funkce Excelu je i funkce PRAVÁ velmi jednoduchá a přímočará, nicméně má několik nezřejmých využití, která se mohou ukázat jako užitečná přivaši práci.
Syntaxe funkce Excel RIGHT
Funkce RIGHT v aplikaci Excel vrací zadaný počet znaků od konce textového řetězce.
Syntaxe funkce RIGHT je následující:
RIGHT(text, [num_chars])Kde:
- Text (povinné) - textový řetězec, ze kterého chcete extrahovat znaky.
- Num_chars (nepovinné) - počet znaků, které se mají extrahovat, počínaje nejpravějším znakem.
- Pokud num_chars je vynechán, je vrácen 1 poslední znak řetězce (výchozí).
- Pokud num_chars je větší než celkový počet znaků v řetězci, jsou vráceny všechny znaky.
- Pokud num_chars je záporné číslo, vrátí vzorec Right chybu #VALUE!.
Chcete-li například z řetězce v buňce A2 získat poslední 3 znaky, použijte tento vzorec:
=PRAVO(A2, 3)
Výsledek by mohl vypadat podobně: 
Důležitá poznámka! Funkce Excel RIGHT vždy vrací hodnotu textový řetězec , a to i v případě, že původní hodnota je číslo. Chcete-li vynutit, aby vzorec Right vypsal číslo, použijte jej v kombinaci s funkcí VALUE, jak je ukázáno v tomto příkladu.
Jak používat funkci RIGHT v aplikaci Excel - příklady vzorců
V reálných pracovních listech se funkce RIGHT v aplikaci Excel používá samostatně jen zřídka. Ve většině případů ji budete používat společně s dalšími funkcemi aplikace Excel jako součást složitějších vzorců.
Jak získat podřetězec, který následuje po určitém znaku
V případě, že chcete extrahovat podřetězec, který následuje za určitým znakem, použijte funkci SEARCH nebo FIND k určení pozice tohoto znaku, odečtěte tuto pozici od celkové délky řetězce vrácené funkcí LEN a vytáhněte tento počet znaků z pravé strany původního řetězce.
PRAVDA( řetězec , LEN( řetězec ) - HLEDAT( znak , řetězec ))Řekněme, že buňka A2 obsahuje jméno a příjmení oddělené mezerou, a vy chcete příjmení vytáhnout do jiné buňky. Stačí vzít výše uvedený obecný vzorec a místo A2 vložit vzorec řetězec , a " " (mezera) v tempu charakter:
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2))
Vzorec poskytne následující výsledek: 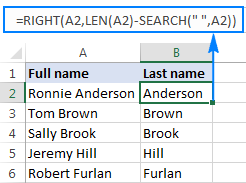
Podobným způsobem můžete získat podřetězec, který následuje za jakýmkoli jiným znakem, např. čárkou, středníkem, pomlčkou atd. Chcete-li například získat podřetězec, který následuje za pomlčkou, použijte tento vzorec:
=RIGHT(A2,LEN(A2)-SEARCH("-",A2))
Výsledek bude vypadat podobně: 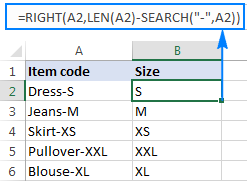
Jak extrahovat podřetězec za posledním výskytem oddělovače
Při práci se složitými řetězci, které obsahují několik výskytů stejného oddělovače, můžete často potřebovat načíst text napravo od posledního výskytu oddělovače. Pro lepší pochopení se podívejte na následující zdrojová data a požadovaný výsledek: 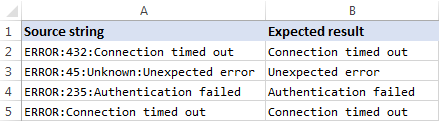
Jak vidíte na obrázku výše, sloupec A obsahuje seznam chyb. Vaším cílem je vytáhnout popis chyby, který se nachází za poslední dvojtečkou v každém řetězci. Další komplikací je, že původní řetězce mohou obsahovat různý počet případů oddělovače, např. A3 obsahuje 3 dvojtečky, zatímco A5 pouze jednu.
Klíčem k nalezení řešení je určení pozice posledního oddělovače ve zdrojovém řetězci (v tomto příkladu poslední výskyt dvojtečky). K tomu je třeba použít několik různých funkcí:
- Zjistí počet oddělovačů v původním řetězci. Je to snadná část:
- Nejprve vypočtete celkovou délku řetězce pomocí funkce LEN: LEN(A2)
- Zadruhé vypočtete délku řetězce bez oddělovačů pomocí funkce SUBSTITUTE, která nahradí všechny výskyty dvojtečky ničím: LEN(SUBSTITUTE(A2,":","")).
- Nakonec od celkové délky řetězce odečtete délku původního řetězce bez oddělovačů: LEN(A2)-LEN(SUBSTITUTE(A2,":","")).
Chcete-li se ujistit, že vzorec funguje správně, můžete jej zadat do samostatné buňky a výsledkem bude číslo 2, což je počet dvojteček v buňce A2.
- Nahrazení posledního oddělovače nějakým jedinečným znakem. Abychom mohli extrahovat text, který následuje za posledním oddělovačem v řetězci, musíme tento poslední výskyt oddělovače nějakým způsobem "označit". Za tímto účelem nahraďme poslední výskyt dvojtečky znakem, který se nikde v původních řetězcích nevyskytuje, například znakem libry (#).
Pokud znáte syntaxi funkce SUBSTITUTE v Excelu, možná si vzpomenete, že má čtvrtý nepovinný argument (instance_num), který umožňuje nahradit pouze konkrétní výskyt zadaného znaku. A protože jsme již vypočítali počet oddělovačů v řetězci, stačí výše uvedenou funkci zadat jako čtvrtý argument další funkce SUBSTITUTE:
=SUBSTITUTE(A2,":", "#",LEN(A2)-LEN(SUBSTITUTE(A2,":","")))Pokud byste tento vzorec vložili do samostatné buňky, vrátil by tento řetězec: ERROR:432#Připojení bylo časově přerušeno
- Zjištění pozice posledního oddělovače v řetězci. V závislosti na tom, jakým znakem jste nahradili poslední oddělovač, použijte pro zjištění pozice tohoto znaku v řetězci buď vyhledávání bez rozlišení velkých a malých písmen, nebo vyhledávání s rozlišením velkých a malých písmen. Poslední dvojtečku jsme nahradili znakem #, takže pro zjištění její pozice použijeme následující vzorec:
=SEARCH("#", SUBSTITUTE(A2,":", "#",LEN(A2)-LEN(SUBSTITUTE(A2,":",""))))V tomto příkladu vzorec vrátí hodnotu 10, což je pozice # v nahrazovaném řetězci.
- Vrátí podřetězec napravo od posledního oddělovače. Nyní, když znáte pozici posledního oddělovače v řetězci, stačí toto číslo odečíst od celkové délky řetězce a přimět funkci RIGHT, aby vrátila tolik znaků od konce původního řetězce:
=RIGHT(A2,LEN(A2)-SEARCH("$",SUBSTITUTE(A2,":","$",LEN(A2)-LEN(SUBSTITUTE(A2,":","")))))
Jak ukazuje obrázek níže, vzorec funguje bezchybně: 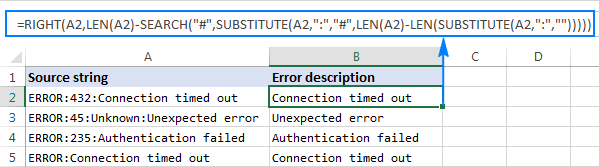
Pokud pracujete s velkým souborem dat, kde různé buňky mohou obsahovat různé oddělovače, můžete výše uvedený vzorec uzavřít do funkce IFERROR, abyste předešli možným chybám:
=IFERROR(RIGHT(A2,LEN(A2)-SEARCH("$",SUBSTITUTE(A2,":","$",LEN(A2)-LEN(SUBSTITUTE(A2,":",""))))), A2)
V případě, že určitý řetězec neobsahuje ani jeden výskyt zadaného oddělovače, bude vrácen původní řetězec, jako v řádku 6 na obrázku níže: 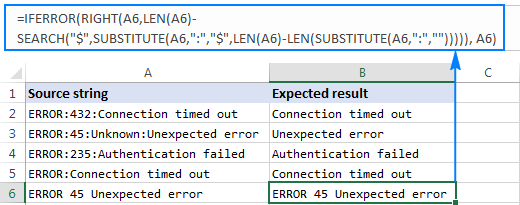
Jak odstranit prvních N znaků z řetězce
Kromě extrakce podřetězce z konce řetězce se funkce Excel RIGHT hodí v situacích, kdy chcete odstranit určitý počet znaků ze začátku řetězce.
V souboru dat použitém v předchozím příkladu můžete chtít odstranit slovo "ERROR", které se objevuje na začátku každého řetězce, a ponechat pouze číslo chyby a popis. Chcete-li to provést, odečtěte počet znaků, které mají být odstraněny, od celkové délky řetězce a zadejte toto číslo do příkazu num_chars argumentu funkce Excel RIGHT:
PRAVDA( řetězec , LEN( řetězec )- počet_znaků_k_odstranění )V tomto příkladu odstraníme prvních 6 znaků (5 písmen a dvojtečku) z textového řetězce v A2, takže náš vzorec bude vypadat takto:
=RIGHT(A2, LEN(A2)-6) 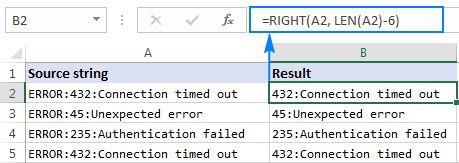
Může funkce Excel RIGHT vrátit číslo?
Jak bylo zmíněno na začátku tohoto návodu, funkce PRAVDA v Excelu vždy vrací textový řetězec, i když je původní hodnotou číslo. Co když ale pracujete s číselným souborem dat a chcete, aby byl výstup také číselný? Snadné řešení spočívá ve vnoření vzorce PRAVDA do funkce VALUE, která je speciálně navržena pro převod řetězce představujícího číslo na číslo.
Chcete-li například vytáhnout posledních 5 znaků (poštovní směrovací číslo) z řetězce v A2 a převést extrahované znaky na číslo, použijte tento vzorec:
=HODNOTA(RIGHT(A2, 5))
Na obrázku níže je vidět výsledek - všimněte si, že čísla ve sloupci B jsou zarovnána doprava, zatímco textové řetězce ve sloupci A jsou zarovnány doleva: 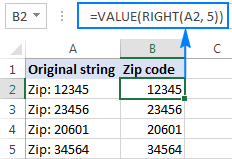
Proč funkce RIGHT nefunguje s daty?
Vzhledem k tomu, že funkce RIGHT aplikace Excel je určena pro práci s textovými řetězci, zatímco data jsou v interním systému aplikace Excel reprezentována čísly, vzorec Right není schopen získat jednotlivé části data, jako je den, měsíc nebo rok. Pokud se o to pokusíte, získáte pouze několik posledních číslic čísla představujícího datum.
Předpokládejme, že máte datum 18-Jan-2017 Pokud se pokusíte získat rok pomocí vzorce RIGHT(A1,4), výsledkem bude 2753, což jsou poslední 4 číslice čísla 42753, které v systému Excel představuje 18. leden 2017. 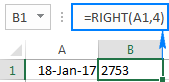
"Jak tedy získám určitou část data?", můžete se mě zeptat. Pomocí jedné z následujících funkcí:
- Funkce DAY pro výpis dne: =DAY(A1)
- Funkce MONTH pro získání měsíce: =MONTH(A1)
- Funkce YEAR pro vytažení roku: =YEAR(A1)
Následující snímek obrazovky ukazuje výsledky: 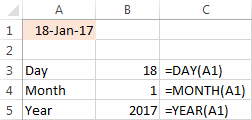
Pokud vaše data jsou reprezentována textovými řetězci , což je častý případ při exportu dat z externího zdroje, nic vám nebrání použít funkci RIGHT a vytáhnout z řetězce několik posledních znaků, které představují určitou část data: 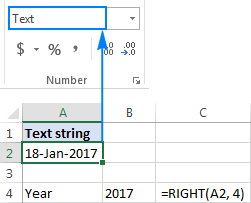
Nefunkční funkce Excel PRAVDA - důvody a řešení
Pokud v pracovním listu nefunguje správně vzorec Právo, je to s největší pravděpodobností způsobeno jedním z následujících důvodů:
- Existuje jeden nebo více koncové mezery Chcete-li rychle odstranit přebytečné mezery v buňkách, použijte buď funkci TRIM aplikace Excel, nebo doplněk Cell Cleaner.
- Na stránkách num_chars argument je méně než nula Samozřejmě, že těžko budete chtít do vzorce záměrně vkládat záporné číslo, ale pokud se ve vzorci num_chars argument je vypočítán jinou funkcí Excelu nebo kombinací různých funkcí a váš vzorec Right vrátí chybu #VALUE!, nezapomeňte zkontrolovat vnořené funkce, zda neobsahují chyby.
- Původní hodnota je a datum . Pokud jste pozorně sledovali tento návod, už víte, proč funkce PRAVÁ neumí pracovat s daty. Pokud někdo předchozí část přeskočil, najdete všechny podrobnosti v článku Proč funkce PRAVÁ v Excelu neumí pracovat s daty.
Takto se v Excelu používá funkce PRAVIDLA. Chcete-li se blíže seznámit se vzorci probíranými v tomto tutoriálu, můžete si stáhnout náš ukázkový sešit níže. Děkuji vám za přečtení a doufám, že se příští týden uvidíme na našem blogu.
Dostupné soubory ke stažení
Funkce Excel RIGHT - příklady (.xlsx soubor)
