
Obsah
Další část našich operací s textem v tabulkách je věnována extrakci. Zjistěte, jak extrahovat různá data - text, znaky, čísla, adresy URL, e-mailové adresy, datum & čas atd. - z různých pozic ve více buňkách Tabulky Google najednou.
Vzorce v tabulkách Google pro extrakci textu a čísel z řetězců
Vzorce v tabulkách Google jsou všechno. Zatímco některé kombinace přidávají text & amp; čísla a odstraňují různé znaky, některé z nich také extrahují text, čísla, oddělují znaky atd.
Výpis dat podle pozice: první/poslední/prostřední N znaků
Nejjednodušší funkce, se kterými si poradíte, když se chystáte vyjmout data z buněk Tabulky Google, jsou LEFT, RIGHT a MID. Získávají jakákoli data podle pozice.
Výpis dat ze začátku buněk v Tabulkách Google
Pomocí funkce LEFT můžete snadno vytáhnout prvních N znaků:
LEFT(řetězec,[počet_znaků])- řetězec je text, ze kterého chcete získat data.
- number_of_characters je počet znaků, které se mají vyjmout zleva.
Zde je nejjednodušší příklad: odstraňme z telefonních čísel kódy zemí:
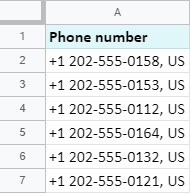
Jak vidíte, kódy zemí mají na začátku buněk 6 symbolů, takže vzorec, který potřebujete, je:
=LEFT(A2,6)
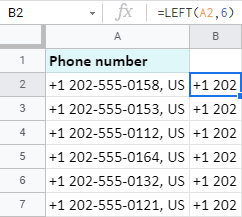
Tip: ArrayFormula umožní získat 6 znaků z celého rozsahu najednou:
=ArrayFormula(LEFT(A2:A7,6))
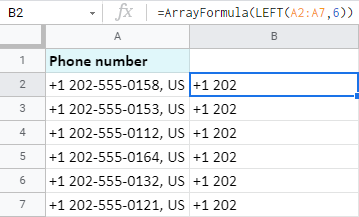
Výpis dat z konce buněk v Tabulkách Google
Chcete-li z buněk vytáhnout posledních N znaků, použijte místo toho funkci RIGHT:
RIGHT(string,[number_of_characters])- řetězec je stále text (nebo odkaz na buňku), z něhož se data získávají.
- number_of_characters je také počet znaků, které se odeberou zprava.
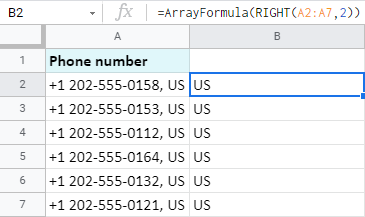
Zjistěme, že názvy zemí jsou ze stejných telefonních čísel:
Zabírají pouze 2 znaky a to je přesně to, co uvádím ve vzorci:
=PRAVO(A2,2)
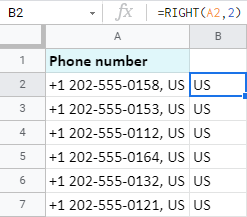
Tip: ArrayFormula vám také pomůže získat data z konce všech buněk Tabulky Google najednou:
=ArrayFormula(RIGHT(A2:A7,2))
Výpis dat ze středu buněk v tabulkách Google
Pokud existují funkce pro extrakci dat ze začátku a konce buněk, musí existovat i funkce pro extrakci dat ze středu. A ano - existuje.
Nazývá se MID:
MID(string, starting_at, extract_length)- řetězec - text, ze kterého chcete vyjmout prostřední část.
- starting_at - pozici znaku, od kterého chcete začít získávat data.
- extract_length - počet znaků, které je třeba vytáhnout.
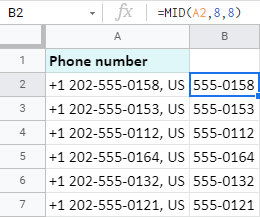
Na příkladu stejných telefonních čísel zjistíme samotná telefonní čísla bez kódů zemí a zkratek zemí:
Protože kódy zemí končí 6. znakem a 7. znak je pomlčka, vytáhnu čísla od 8. číslice. A dostanu celkem 8 číslic:
=MID(A2,8,8)
Tip. Změnou jedné buňky na celý rozsah a jejím zabalením do pole ArrayFormula získáte výsledek pro každou buňku najednou:
=ArrayFormula(MID(A2:A7,8,8))

Výpis textu/čísel z řetězců
Někdy není možné extrahovat text podle pozice (jak je uvedeno výše). Požadované řetězce se mohou nacházet v libovolné části buněk a mohou se skládat z různého počtu znaků, což vás nutí vytvořit pro každou buňku jiný vzorec.
Tabulky Google by však nebyly Tabulkami Google, kdyby neměly další funkce, které pomáhají extrahovat text z řetězců.
Podívejme se na několik možných způsobů, které tabulkové procesory nabízejí.
Výpis dat před určitým textem - LEFT+SEARCH
Kdykoli chcete získat data, která předcházejí určitému textu, použijte kombinaci kláves LEVÝ + HLEDAT:
- LEVÝ slouží k vrácení určitého počtu znaků od začátku buněk (zleva).
- HLEDAT vyhledá určité znaky/řetězce a zjistí jejich pozici.
Zkombinujte je - a LEVÝ vrátí počet znaků navržený funkcí HLEDAT.
Zde je příklad: jak extrahujete textové kódy před každým "ea"?
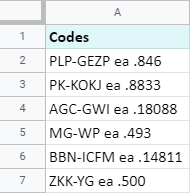
Toto je vzorec, který vám v podobných případech pomůže:
=LEFT(A2,SEARCH("ea",A2)-1)
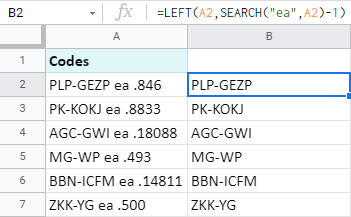
Ve vzorci je uvedeno následující:
- HLEDAT("ea",A2) vyhledá v A2 znak 'ea' a vrátí pozici, kde tento znak 'ea' začíná pro každou buňku - 10.
- Takže na 10. pozici se nachází 'e'. Ale protože chci mít vše těsně před 'ea', musím od této pozice odečíst 1. Jinak se vrátí i 'e'. Takže nakonec dostanu 9.
- LEVÝ se podívá na A2 a získá prvních 9 znaků.
Výpis dat za textem
Existují také prostředky, jak získat vše, co následuje za určitým textovým řetězcem. Tentokrát však nepomůže RIGHT. Místo toho přijde na řadu REGEXREPLACE.
Tip: REGEXREPLACE používá regulární výrazy. Pokud nejste připraveni se jimi zabývat, existuje mnohem jednodušší řešení popsané níže. REGEXREPLACE(text, regular_expression, replacement)
- text je řetězec nebo buňka, ve které chcete provést změny.
- regular_expression je kombinace znaků, která označuje hledanou část textu.
- náhradní je cokoli, co chcete získat místo tohoto text
Jak jej tedy použít k extrakci dat po určitém textu - v mém příkladu "ea"?
Snadno - podle tohoto vzorce:
=REGEXREPLACE(A2,"(.*)ea(.*)","$2")
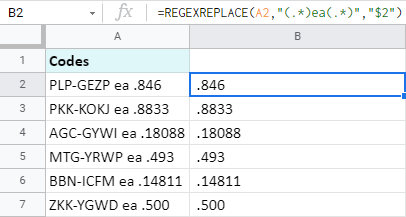
Vysvětlím vám, jak přesně tento vzorec funguje:
- A2 je buňka, ze které získávám data.
- "(.*)ea(.*)" je můj regulární výraz (nebo mu můžete říkat maska). Hledám znak 'ea' a všechny ostatní znaky dávám do závorek. Existují 2 skupiny znaků - vše před 'ea' je první skupina (.*) a vše za 'ea' je druhá skupina (.*). Celá samotná maska se dává do dvojitých uvozovek.
- "$2" je to, co chci získat - druhá skupina (proto její číslo 2) z předchozího argumentu.
Tip: Na této speciální stránce jsou shromážděny všechny znaky používané v regulárních výrazech.
Výpis čísel z buněk v tabulce Google Sheets
Co když chcete extrahovat pouze čísla, když jejich pozice a cokoli před & za nezáleží?
Pomohou také masky (tzv. regulární výrazy). V podstatě vezmu stejnou funkci REGEXREPLACE a změním regulární výraz:
=REGEXREPLACE(A2,"[^[:digit:]]", "")
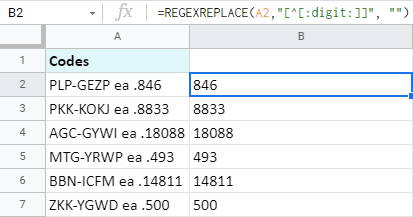
- A2 je buňka, ze které chci tato čísla získat.
- "[^[:digit:]]" je regulární výraz, který bere vše kromě číslic. Symbol ^caret je výjimka pro číslice.
- "" nahradí vše kromě číselných znaků "ničím". Nebo jinak řečeno, zcela je odstraní a v buňkách ponechá pouze čísla. Nebo čísla vytahuje :)
Výpis textu s ignorováním čísel a dalších znaků
Podobným způsobem můžete z buněk Tabulky Google vyjmout pouze abecední údaje. Zkrácení regulárního výrazu, který označuje text, se nazývá odpovídajícím způsobem - alfa:
=REGEXREPLACE(A2,"[^[:alpha:]]", "")
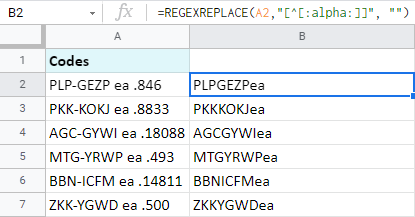
Tento vzorec bere vše kromě písmen (A-Z, a-z) a doslova to nahrazuje "ničím". Nebo jinak řečeno, bere pouze písmena.
Způsoby extrakce dat z buněk Tabulky Google bez použití vzorců
Pokud hledáte snadný způsob, jak bez použití vzorců extrahovat různé typy dat, jste na správném místě. Náš doplněk Power Tools obsahuje přesně ty nástroje, které vám pomohou.
Extrakce různých typů dat pomocí doplňků Power Tools
První nástroj, který bych vám rád představil, se jmenuje Extract. Dělá přesně to, co jste v tomto článku hledali - extrahuje různé typy dat z buněk Tabulky Google.
Uživatelsky přívětivá nastavení
Všechny případy, které jsem popsal výše, nejsou řešitelné pouze pomocí doplňku. Nástroj je uživatelsky přívětivý takže stačí vybrat rozsah, který chcete zpracovat, a zaškrtnout požadovaná políčka. Žádné vzorce, žádné regulární výrazy.
Vzpomínáte si na druhý bod tohoto článku s REGEXREPLACE a regulárními výrazy? Tady se dozvíte, jak je to pro doplněk jednoduché:
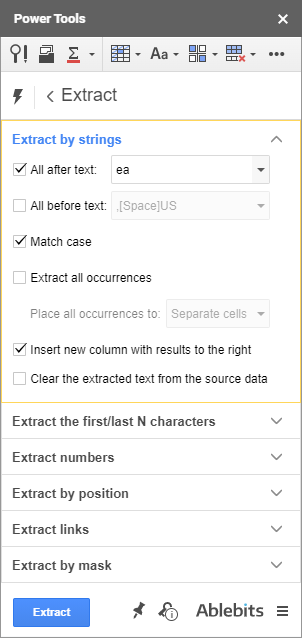
Další možnosti
Jak vidíte, existují některé další možnosti (jen zaškrtávací políčka), které můžete rychlé zapnutí/vypnutí abyste získali co nejpřesnější výsledek:
- Získání řetězců pouze požadovaných velikostí textu.
- Vytáhněte všechny výskyty z každé buňky a umístěte je do jedné buňky nebo do samostatných sloupců.
- Vložte nový sloupec s výsledkem napravo od zdrojových dat.
- Vymazání extrahovaného textu ze zdrojových dat.
Výpis různých typů dat
Power Tools nejenže extrahuje data před/za/mezi určitými textovými řetězci a prvními/posledními N znaky, ale také:
- Čísla spolu s jejich desetinnými čísly, přičemž oddělovače desetinných míst a tisíců zůstávají neporušené:
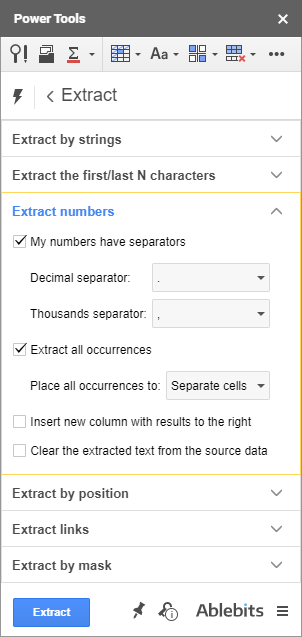
Výpis libovolného řetězce dat odkudkoli
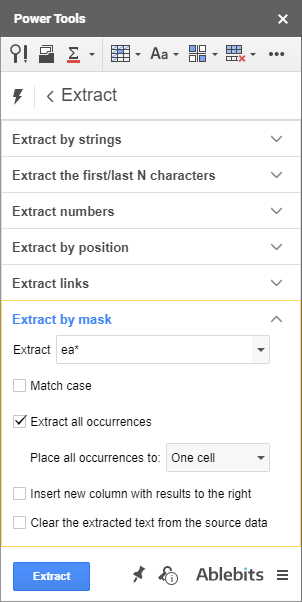
K dispozici je také možnost nastavit si vlastní přesný vzor a použít jej pro extrakci. Výpis podle masky a jeho zástupné znaky - * a ? - to zvládne:
- Vše, co se nachází mezi závorkami, můžete například zobrazit pomocí následující masky: (*)
- Nebo si pořiďte ty SKU, které mají ve svém ID pouze 5 čísel: SKU?????
- Nebo, jak ukazuji na obrázku níže, vytáhněte vše za každým "ea" v každé buňce: ea*
Extrakce data a času z časových značek
Jako bonus existuje menší nástroj, který z časových značek extrahuje datum a čas - jmenuje se Split Date & Time.
Přestože byl vytvořen především pro rozdělení časových značek, je dokonale schopen získat jednu z požadovaných jednotek samostatně:
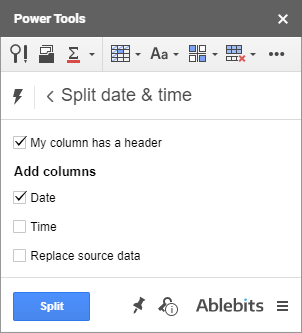
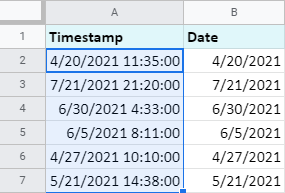
Stačí vybrat jedno ze zaškrtávacích políček podle toho, co chcete z časových značek v tabulkách Google extrahovat - datum nebo čas - a stisknout tlačítko . Split . Požadovaná jednotka se zkopíruje do nového sloupce (nebo nahradí původní data, pokud zaškrtnete i poslední políčko):
Tento nástroj je také součástí doplňku Power Tools, takže jakmile si ho nainstalujete, abyste získali jakákoli data z buněk Tabulek Google, máte to kompletně pokryté. Pokud ne, zanechte nám prosím komentář a my vám pomůžeme :)
