
목차
스프레드시트의 텍스트를 사용한 다음 작업은 추출에 전념합니다. 텍스트, 문자, 숫자, URL, 이메일 주소, 날짜 & 시간 등 — 한 번에 여러 Google 스프레드시트 셀의 다양한 위치에서.
문자열에서 텍스트와 숫자를 추출하는 Google 스프레드시트 수식
Google의 수식 시트가 전부입니다. 일부 콤보는 텍스트 & 숫자 및 다양한 문자를 제거하고 일부는 텍스트, 숫자, 개별 문자 등을 추출하기도 합니다.
위치별로 데이터 추출: 첫 번째/마지막/중간 N자
가장 다루기 쉬운 기능 Google 스프레드시트에서 데이터를 꺼내려고 할 때 셀은 LEFT, RIGHT 및 MID입니다. 위치별로 데이터를 가져옵니다.
Google 스프레드시트의 셀 시작 부분에서 데이터 추출
LEFT 함수를 사용하여 처음 N자를 쉽게 추출할 수 있습니다.
LEFT(문자열, [number_of_characters])- string 은 데이터를 추출하려는 텍스트입니다.
- number_of_characters 는 처음부터 추출할 문자 수입니다. 왼쪽부터.
다음은 가장 간단한 예입니다. 전화번호에서 국가 코드를 빼보겠습니다.
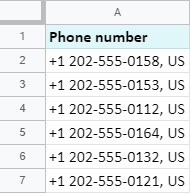
보시다시피 국가 코드는 셀 시작 부분에서 6개의 기호를 사용하므로 필요한 수식은 다음과 같습니다.
=LEFT(A2,6)
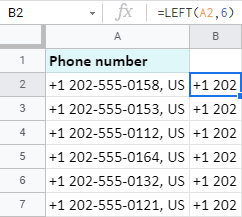
팁. ArrayFormula를 사용하면 6개의 문자를 가져올 수 있습니다.한 번에 전체 범위:
=ArrayFormula(LEFT(A2:A7,6))
Google 스프레드시트의 셀 끝에서 데이터 추출
셀에서 마지막 N자를 추출하려면 대신 RIGHT 함수를 사용하세요.
RIGHT(string,[number_of_characters])- string 은 여전히 데이터를 추출할 텍스트(또는 셀 참조)입니다.
- number_of_characters 는 또한 오른쪽에서 가져올 문자 수입니다.
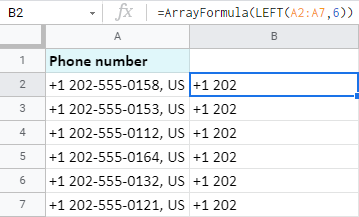
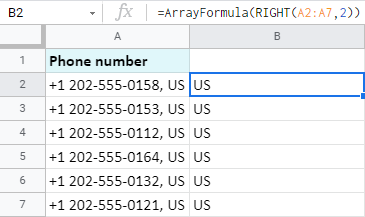
동일한 전화번호에서 해당 국가 이름을 가져오겠습니다:
단 2자만 사용하며 공식에서 언급한 바로 그 내용입니다.
=RIGHT(A2,2)
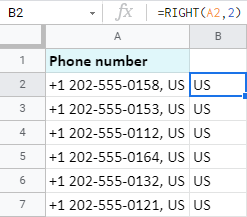
팁. ArrayFormula는 또한 모든 Google 스프레드시트 셀의 끝에서 한 번에 데이터를 추출하는 데 도움이 됩니다.
=ArrayFormula(RIGHT(A2:A7,2))
Google 스프레드시트의 중간 셀에서 데이터 추출
셀의 처음과 끝에서 데이터를 추출하는 기능이 있다면 중간에서도 데이터를 추출하는 기능이 있어야 합니다. 그리고 예 — 하나 있습니다.
이름은 MID:
MID(string, starting_at, extract_length)- string — 꺼내려는 텍스트 가운데 부분 from.
- starting_at — 데이터 가져오기를 시작하려는 문자의 위치.
- extract_length — 숫자
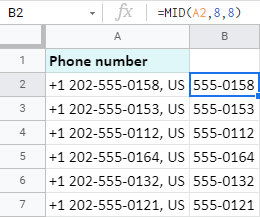
동일한 전화번호의 예를 들어 국가코드와 국가가 없는 전화번호 자체를 찾아보자abbreviation:
국가 코드는 6번째 문자로 끝나고 7번째는 대시이므로 8번째 자리부터 숫자를 가져옵니다. 그리고 총 8자리를 얻습니다:
=MID(A2,8,8)
팁. 하나의 셀을 전체 범위로 변경하고 ArrayFormula로 래핑하면 각 셀에 대한 결과가 한 번에 제공됩니다.
=ArrayFormula(MID(A2:A7,8,8))

문자열에서 텍스트/숫자 추출
때때로 위치별로 텍스트를 추출하는 것은(위에 표시된 것처럼) 옵션이 아닙니다. 필수 문자열은 셀의 어느 부분에나 있을 수 있으며 서로 다른 수의 문자로 구성되어 셀마다 다른 수식을 만들어야 합니다.
하지만 Google 스프레드시트가 없으면 Google 스프레드시트가 아닙니다. 문자열에서 텍스트를 추출하는 데 도움이 되는 다른 기능.
스프레드시트가 제공하는 몇 가지 가능한 방법을 살펴보겠습니다.
특정 텍스트 앞의 데이터 추출 — LEFT+SEARCH
언제든지 특정 텍스트 앞에 있는 데이터를 추출하려면 LEFT + SEARCH를 사용하십시오.
- LEFT 는 셀 시작 부분(왼쪽부터)에서 특정 수의 문자를 반환하는 데 사용됩니다.
- SEARCH 특정 문자/문자열을 찾고 위치를 가져옵니다.
이들을 결합하면 LEFT는 SEARCH에서 제안한 문자 수를 반환합니다.
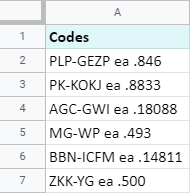
다음은 예입니다. 각 'ea' 앞에 있는 텍스트 코드를 어떻게 추출합니까?
유사한 작업에 도움이 되는 공식입니다.사례:
=LEFT(A2,SEARCH("ea",A2)-1)
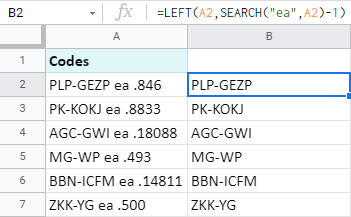
다음은 수식에서 발생하는 결과입니다.
- SEARCH("ea",A2 ) A2에서 'ea'를 찾고 각 셀에서 'ea'가 시작하는 위치인 10을 반환합니다.
- 따라서 10번째 위치는 'e'가 있는 위치입니다. 하지만 'ea' 바로 앞에 있는 모든 것을 원하기 때문에 그 위치에서 1을 빼야 합니다. 그렇지 않으면 'e'도 반환됩니다. 그래서 결국 9개를 얻습니다.
- LEFT 는 A2를 보고 처음 9자를 얻습니다.
텍스트 뒤의 데이터 추출
거기 또한 특정 텍스트 문자열 이후의 모든 항목을 가져오는 것을 의미합니다. 하지만 이번에는 RIGHT가 도움이 되지 않습니다. 대신 REGEXREPLACE가 차례를 바꿉니다.
팁. REGEXREPLACE는 정규식을 사용합니다. 처리할 준비가 되지 않은 경우 아래에 설명된 훨씬 더 쉬운 솔루션이 있습니다. REGEXREPLACE(text, regular_expression, replacement)
- text 는 변경하려는 문자열 또는 셀입니다.
- regular_expression 은 다음의 조합입니다. 찾고 있는 텍스트의 일부를 나타내는 문자
- 대체 는 해당 텍스트
그러면 특정 텍스트 뒤의 데이터를 추출하는 데 어떻게 사용합니까? 예를 들어 'ea'는 무엇입니까?
쉬움 — 이 공식을 사용하여:
=REGEXREPLACE(A2,"(.*)ea(.*)","$2")
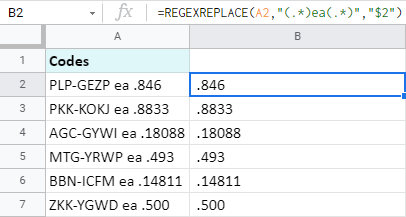
이 공식이 정확히 어떻게 작동하는지 설명하겠습니다.
- A2 는 내가 추출하는 셀입니다. .
- "(.*)ea(.*)" 의 데이터는 내 정규 데이터입니다.식(또는 마스크라고 부를 수 있음). 나는 'ea'를 찾고 다른 모든 문자를 괄호 안에 넣습니다. 2개의 문자 그룹이 있습니다. 'ea' 앞의 모든 것이 첫 번째 그룹(.*)이고 'ea' 뒤의 모든 것이 두 번째 그룹(.*)입니다. 전체 마스크 자체는 큰따옴표로 묶습니다.
- "$2" 는 이전 인수의 두 번째 그룹(따라서 번호 2)입니다.
팁. 정규 표현식에 사용되는 모든 문자는 이 특별 페이지에 수집됩니다.
Google 스프레드시트 셀에서 숫자 추출
위치와 앞 & after는 중요하지 않습니까?
마스크(일명 정규식)도 도움이 됩니다. 실제로 동일한 REGEXREPLACE 함수를 사용하여 정규식을 변경하겠습니다.
=REGEXREPLACE(A2,"[^[:digit:]]", "")
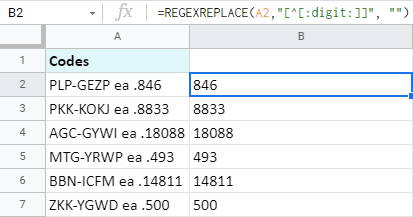
- A2 is 해당 숫자를 가져오려는 셀입니다.
- "[^[:digit:]]" 는 숫자를 제외한 모든 것을 취하는 정규식입니다. ^캐럿 기호는 숫자에 대한 예외를 만드는 것입니다.
- "" 는 숫자를 제외한 모든 문자를 "없음"으로 바꿉니다. 즉, 완전히 제거하고 셀에 숫자만 남깁니다. 또는 숫자 추출 :)
숫자 및 기타 문자를 무시하고 텍스트 추출
유사한 방식으로 Google 스프레드시트 셀에서 알파벳 데이터만 추출할 수 있습니다. 정규 표현식의 축약형그에 따라 텍스트를 나타냅니다 — alpha:
=REGEXREPLACE(A2,"[^[:alpha:]]", "")
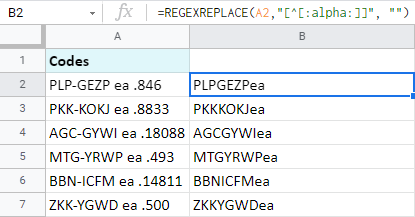
이 수식은 문자(A-Z, a-z)를 제외한 모든 문자를 문자 그대로 "없음"으로 바꿉니다. . 다시 말해 문자만 빼면 됩니다.
공식 없이 Google 스프레드시트 셀에서 데이터를 추출하는 방법
공식 없이 쉽게 데이터를 추출하는 방법을 찾고 있다면 다양한 유형의 데이터를 추출하면 제대로 찾아오셨습니다. Power Tools 추가 기능에는 작업을 위한 도구만 있습니다.
Power Tools 추가 기능을 사용하여 다양한 유형의 데이터 추출
알고 싶은 첫 번째 도구는 추출입니다. . Google 스프레드시트 셀에서 다양한 유형의 데이터를 추출합니다.
사용자 친화적인 설정
위에서 다룬 모든 경우는 그렇지 않습니다. 추가 기능으로 해결할 수 있습니다. 이 도구는 사용자 친화적 이므로 처리할 범위를 선택하고 필요한 확인란을 선택하기만 하면 됩니다. 공식이 없으면 정규식도 없습니다.
REGEXREPLACE 및 정규식에 대한 이 기사의 두 번째 요점을 기억하십니까? 애드온의 간단한 방법은 다음과 같습니다.
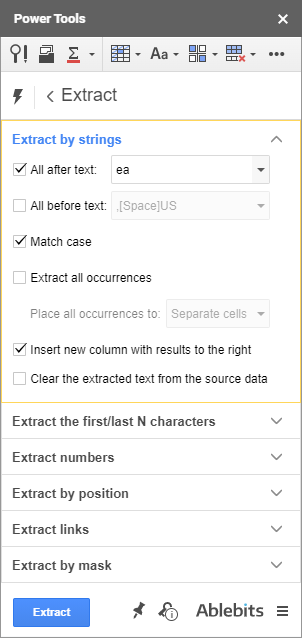
추가 옵션
보시다시피 몇 가지 추가 옵션<29이 있습니다> (체크박스만) 가장 정확한 결과를 얻기 위해 빠르게 켜고 끌 수 있습니다 :
- 필요한 텍스트 대소문자의 문자열만 가져옵니다.
- 각각에서 모든 항목을 꺼내십시오.셀을 하나의 셀 또는 별도의 열에 배치합니다.
- 원본 데이터 오른쪽에 결과가 포함된 새 열을 삽입합니다.
- 원본 데이터에서 추출된 텍스트를 지웁니다.
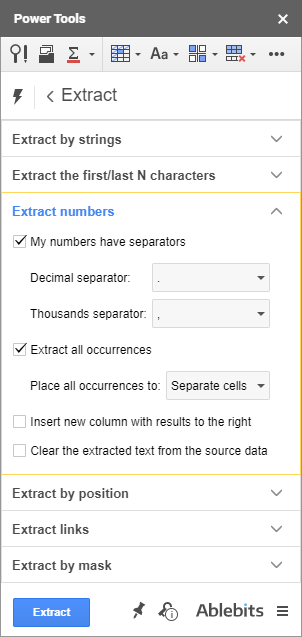
다양한 데이터 유형 추출
Power Tools는 특정 텍스트 문자열과 처음/마지막 N 문자 전후/사이의 데이터를 추출할 뿐만 아니라; 그러나 그것은 또한 다음을 제거합니다:
- 소수/천 단위 구분 기호를 그대로 유지하는 소수와 함께 숫자:
모든 곳에서 데이터 문자열 추출
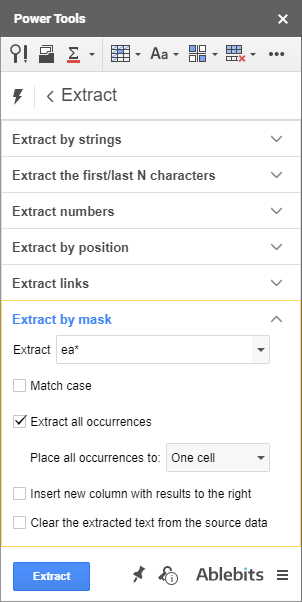
이 있습니다. 자신만의 정확한 패턴을 설정하고 추출에 사용할 수 있는 옵션도 있습니다. 마스크 및 와일드카드 문자( * 및 ? 로 추출) 다음과 같이 트릭을 수행합니다.
- 예를 들어 다음과 같이 가져올 수 있습니다. 다음 마스크를 사용하여 대괄호 사이의 모든 항목: (*)
- 또는 ID에 5개의 숫자만 있는 SKU 가져오기: SKU?????
- 또는 아래 스크린샷에서 볼 수 있듯이 각 셀의 각 'ea' 뒤에 있는 모든 항목을 가져옵니다. ea*
타임스탬프에서 날짜 및 시간 추출
보너스로 타임스탬프에서 날짜와 시간을 추출하는 더 작은 도구가 있습니다. Split Date & Time.
애초 타임스탬프를 분할하기 위해 만들었지만 완벽하게원하는 단위 중 하나를 개별적으로 가져올 수 있습니다.
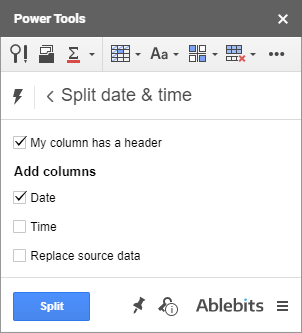
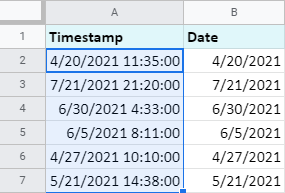
Google 스프레드시트의 타임스탬프에서 추출하려는 항목(날짜 또는 시간)에 따라 확인란 중 하나를 선택하고 분할 . 필요한 단위가 새 열에 복사됩니다(또는 마지막 확인란도 선택하면 원본 데이터가 대체됨).
이 도구는 다음의 일부이기도 합니다. Power Tools 애드온을 설치하여 Google 스프레드시트 셀에서 데이터를 가져오면 완전히 다룰 수 있습니다. 아니라면 댓글 남겨주시면 도와드리겠습니다 :)
