
Obsah
Chcete co nejefektivněji zacházet s bílými znaky? Pomocí regulárních výrazů můžete odstranit všechny mezery v buňce, nahradit více mezer jedním znakem, oříznout mezery pouze mezi čísly a další.
Ať už používáte jakákoli vstupní data, jen stěží se setkáte s datovou sadou bez mezer. Ve většině případů jsou bílé znaky dobré - používáte je k vizuálnímu oddělení různých informací, abyste je mohli lépe vnímat. V některých situacích se však mohou stát zlem - mezery navíc mohou zaneřádit vaše vzorce a učinit pracovní listy téměř nepřehlednými.
Proč používat regulární výraz k ořezávání bílých znaků v aplikaci Excel?
Než se pustíme do podrobností o používání regulárních výrazů k odstraňování bílých znaků v listech aplikace Excel, rád bych se věnoval otázce, která nás napadne jako první - proč potřebujeme regexy, když Excel už má funkci TRIM?
Abychom pochopili rozdíl, podívejme se, co se v jednotlivých případech považuje za bílé znaky:
- Vestavěná funkce TRIM dokáže odstranit pouze prostorový znak který má v 7bitovém systému ASCII hodnotu 32.
- Regulární výrazy mohou identifikovat několik různých forem bílých znaků, jako je mezera ( ), tabulátor (\t), návrat vozíku (\r) a nový řádek (\n). bílý znak (\s), který odpovídá všem těmto typům a je velmi užitečný při čištění nezpracovaných vstupních dat.
Když přesně víte, co se děje v zákulisí, je mnohem snazší najít řešení, že?
Jak povolit regulární výrazy v aplikaci Excel
Je dobře známo, že hotový Excel regulární výrazy nepodporuje. Abyste je mohli používat, musíte si vytvořit vlastní funkci VBA. Naštěstí už jednu máme, jmenuje se RegExpReplace . počkejte, proč "nahradit", když mluvíme o odstranění? V jazyce Excelu je "odstranit" jen jiný výraz pro "nahradit prázdným řetězcem" :) A co když je to "nahradit"?
Chcete-li funkci přidat do aplikace Excel, zkopírujte její kód z této stránky, vložte jej do editoru VBA a uložte soubor jako. sešit s povolenými makry (.xlsm).
Zde je syntaxe funkce pro vaši informaci:
RegExpReplace(text, vzor, náhrada, [číslo_instance], [případ_zápasu])První tři argumenty jsou povinné, poslední dva jsou nepovinné.
Kde:
- Text - původní řetězec, ve kterém se má hledat.
- Vzor - regex, který se má hledat.
- Náhrada - text, který se má nahradit. Na odstranit bílé plochy , nastavíte tento argument na:
- prázdný řetězec ("") pro oříznutí absolutně všech mezer
- prostor znak (" ") pro nahrazení více mezer jedním znakem mezery.
- Instance_num (nepovinné) - číslo instance. Ve většině případů jej vynecháte, abyste nahradili všechny instance (výchozí).
- Match_case (nepovinné) - logická hodnota určující, zda se mají porovnávat (TRUE) nebo ignorovat (FALSE) velká a malá písmena textu. Pro bílé znaky je irelevantní, a proto se vynechává.
Další informace naleznete v části Funkce RegExpReplace.
Jak odstranit bílé znaky pomocí regexu - příklady
Po přidání funkce RegExpReplace do sešitu se budeme postupně zabývat různými scénáři.
Odstranění všech bílých znaků pomocí regexu
Chcete-li odstranit všechny mezery v řetězci, jednoduše vyhledejte jakýkoli bílý znak, včetně mezery, tabulátoru, návratu vozíku a řádkového posuvu, a nahraďte je prázdným řetězcem ("").
Vzor : \s+
Náhrada : ""
Za předpokladu, že zdrojový řetězec je v položce A5, vzorec v položce B5 je:
=RegExpReplace(A5, "\s+", "")
Abyste si usnadnili správu vzorů, můžete regex zadat do předdefinované buňky a do vzorce jej vložit pomocí absolutního odkazu, například $A$2, takže adresa buňky zůstane při kopírování vzorce dolů do sloupce nezměněna.
=RegExpReplace(A5, $A$2, "")
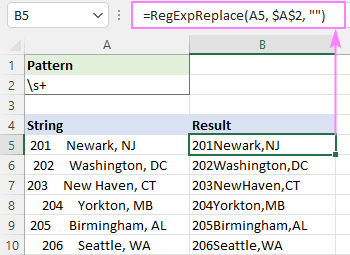
Odstranění více než jednoho bílého místa
Odstranění bílé znaky navíc (tj. více než jedna po sobě jdoucí mezera), použijte stejný regex \s+, ale nalezené shody nahraďte jedním znakem mezery.
Vzor : \s+
Náhrada : " "
=RegExpReplace(A5, "\s+", " ")
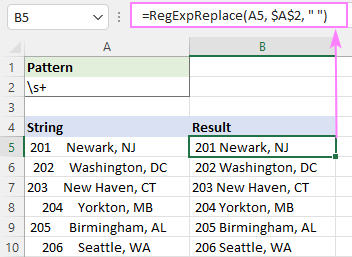
Pozor na to, že tento vzorec zachovává jeden znak mezery nejen mezi slovy, ale také na začátku a konci řetězce, což není dobré. Chcete-li se zbavit počátečních a koncových bílých znaků, vnořte výše uvedený vzorec do jiné funkce RegExpReplace, která odstraní mezery ze začátku a konce:
=RegExpReplace(RegExpReplace(A5, "\s+", " "), "^[\s]+
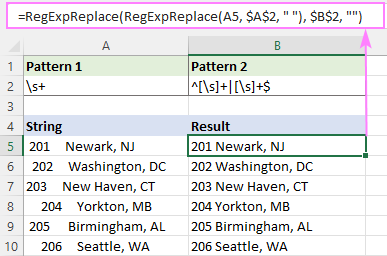
Regex pro odstranění počátečních a koncových bílých znaků
Chcete-li vyhledat bílé znaky na začátku nebo na konci řádku, použijte kotvy pro začátek ^ a konec $.
Vedoucí bílé znaky:
Vzor : ^[\s]+
Trailing bílé znaky:
Vzor : [\s]+$
Vedoucí a koncové bílé znaky:
Vzor : ^[\s]+
Ať už zvolíte jakýkoli regex, nenahrazujte shody ničím.
Náhrada : ""
Například pro odstranění všech mezer na začátku a na konci řetězce ve formátu A5 je vzorec následující:
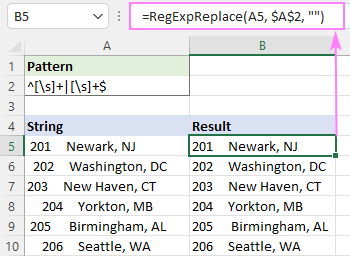
=RegExpReplace(A5, "^[\s]+
Jak je znázorněno na obrázku níže, odstraní se pouze počáteční a koncové bílé znaky. Mezery mezi slovy zůstanou zachovány a vytvoří vizuálně příjemný pohled pro oko čtenáře.
Odstranění nadbytečných bílých znaků, ale zachování zlomů řádků
Při práci s víceřádkovými řetězci se můžete chtít zbavit přebytečných mezer, ale zachovat zalomení řádků. To provedete tak, že místo znaku bílé mezery \s budete hledat mezery [ ] nebo mezery a tabulátory [\t ]. Druhý vzor se hodí, pokud jsou zdrojová data importována z jiného zdroje, např. z textového editoru.
Předpokládejme, že v níže uvedeném souboru dat chcete oříznout všechny počáteční/koncové mezery a všechny mezery kromě jedné, přičemž více řádků zůstane nedotčeno. Pro splnění tohoto úkolu budete potřebovat dvě různé funkce RegExpReplace.
První funkce nahradí více mezer jedním znakem mezery.
=RegExpReplace(A5, " +", " ")
Druhý odstraňuje mezery ze začátku a konce řádku:
=RegExpReplace(A5, "^ +
Stačí vnořit obě funkce jednu do druhé:
=RegExpReplace(RegExpReplace(A5, " +", " "), "^ +
A dosáhnete perfektního výsledku:
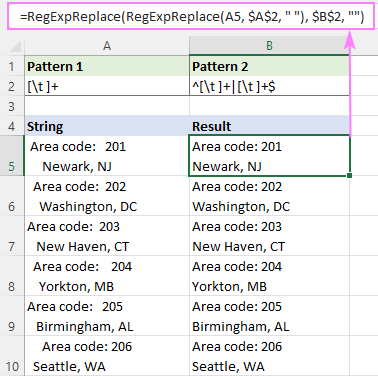
Regex pro nahrazení více mezer jedním znakem
Pokud chcete z řetězce odstranit všechny mezery a každou skupinu po sobě jdoucích mezer nahradit určitým znakem, je třeba provést tento postup:
Nejprve pomocí tohoto regexu ořízněte počáteční a koncové bílé znaky:
=RegExpReplace(A8, "^[\s]+
Poté slouží výše uvedená funkce k text argument jiného RegExpReplace, který nahradí jeden nebo více po sobě jdoucích bílých znaků zadaným znakem, např. pomlčkou:
Vzor : \s+
Náhrada : -
Předpokládáme-li, že zdrojový řetězec je ve formátu A8, má vzorec tento tvar:
=RegExpReplace(RegExpReplace(A8, "^[\s]+
Nebo můžete zadat vzory a náhrady do samostatných buněk, jak je znázorněno na obrázku:
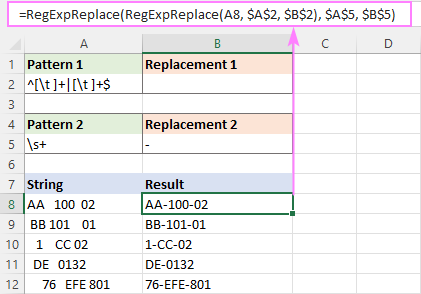
Regex pro odstranění prázdných řádků
Zde je otázka, kterou často kladou uživatelé, kteří mají v jedné buňce více řádků: "V mých buňkách je spousta prázdných řádků. Je nějaký jiný způsob, jak se jich zbavit, než projít každou buňku a ručně odstranit každý řádek?" Odpověď: To je snadné!
Pro porovnání prázdných řádků, které neobsahují ani jeden znak od začátku ^ aktuálního řádku až po následující řádek \n, se použije regex:
Vzor : ^\n
Pokud vizuálně prázdné řádky obsahují mezery nebo tabulátory, použijte tento regulární výraz:
Vzor : ^[\t ]*\n
Stačí nahradit regex prázdným řetězcem pomocí tohoto vzorce a všechny prázdné řádky budou najednou pryč!
=RegExpReplace(A5, $A$2, "")
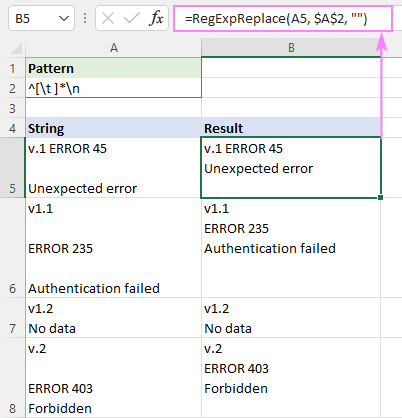
Odstranění bílých znaků pomocí nástrojů RegEx
Výše uvedené příklady ukázaly jen malou část úžasných možností, které regexy poskytují. Bohužel ne všechny funkce klasických regulárních výrazů jsou ve VBA k dispozici.
Nástroje RegEx, které jsou součástí naší sady Ultimate Suite, naštěstí tato omezení nemají, protože jsou zpracovávány pomocí enginu RegEx společnosti Microsoft pro rozhraní .NET. To umožňuje sestavovat složitější vzory, které RegExp VBA nepodporuje. Níže najdete příklad takového regulárního výrazu.
Regex pro odstranění mezery mezi čísly
Předpokládejme, že v alfanumerickém řetězci chcete odstranit bílé znaky pouze mezi čísly, takže z řetězce "A 1 2 B" se stane "A 12 B".
Chcete-li přiřadit mezi libovolné dvě číslice bílé znaky, můžete použít následující hledání:
Vzor : (?<=\d)\s+(?=\d)
Chcete-li vytvořit vzorec na základě výše uvedených regexů, proveďte dva jednoduché kroky:
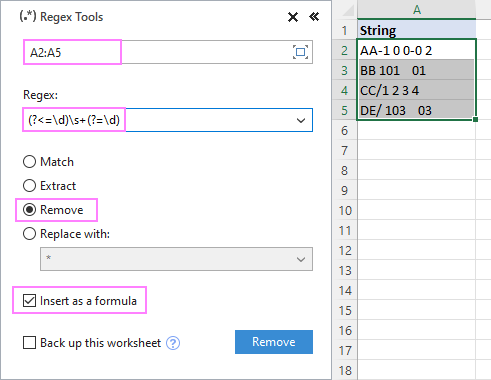
- Na Data Ablebits na kartě Text klikněte na tlačítko Nástroje Regex .
- Na Nástroje Regex vyberte zdrojová data, zadejte regex, vyberte možnost Odstranění adresy a stiskněte tlačítko Odstranění stránky .
Chcete-li získat výsledky jako vzorce, nikoli jako hodnoty, nezapomeňte zaškrtnout políčko Vložit jako vzorec zaškrtávacího políčka.
Za chvíli uvidíte AblebitsRegexRemove vložené do nového sloupce napravo od původních dat.
Případně můžete regex zadat do některé buňky, například A5, a vzorec vložit přímo do buňky pomocí příkazu Vložit funkci dialogové okno, kde AblebitsRegexRemove je zařazen do kategorie AblebitsUDFs .
Protože je tato funkce určena speciálně pro odstraňování řetězců, vyžaduje pouze dva argumenty - vstupní řetězec a regex:
=AblebitsRegexRemove(A5, $A$2)
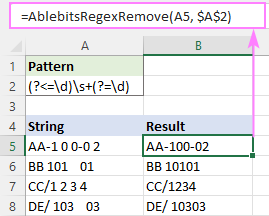
To je návod, jak odstranit mezery v Excelu pomocí regulárních výrazů. Děkuji vám za přečtení a těším se na vás na našem blogu příští týden!
Dostupné soubory ke stažení
Odstranění bílých znaků pomocí regexu - příklady (.xlsm soubor)
Ultimate Suite - zkušební verze (.exe soubor)
