
Obsah
V tomto tutoriálu se podrobně podíváme na to, jak používat regex k porovnávání řetězců v aplikaci Excel.
Když potřebujete najít určitou hodnotu v rozsahu buněk, použijete funkci MATCH nebo XMATCH. Při hledání konkrétního řetězce v buňce se hodí funkce FIND a SEARCH. A jak zjistíte, zda buňka obsahuje informace, které odpovídají danému vzoru? Samozřejmě pomocí regulárních výrazů. Excel ale z výroby regexy nepodporuje! Žádný strach, my ho k tomu donutíme :)
Funkce Regex aplikace Excel VBA pro porovnávání řetězců
Jak je z nadpisu zřejmé, pro použití regulárních výrazů v Excelu je třeba vytvořit vlastní funkci. Naštěstí má Excel ve VBA vestavěnou funkci RegExp objekt, který můžete použít ve svém kódu, jak je uvedeno níže:
Public Function RegExpMatch(input_range As Range, pattern As String , Optional match_case As Boolean = True ) As Variant Dim arRes() As Variant 'pole pro uložení výsledků Dim iInputCurRow, iInputCurCol, cntInputRows, cntInputCols As Long 'index aktuálního řádku ve zdrojovém rozsahu, index aktuálního sloupce ve zdrojovém rozsahu, počet řádků, počet sloupců On Error GoTo ErrHandlRegExpMatch = arRes Set regex = CreateObject ("VBScript.RegExp" ) regex.pattern = pattern regex.Global = True regex.MultiLine = True If True = match_case Then regex.ignorecase = False Else regex.ignorecase = True End If cntInputRows = input_range.Rows.Count cntInputCols = input_range.Columns.Count ReDim arRes(1 To cntInputRows, 1 To cntInputCols) For iInputCurRow = 1 To cntInputRows ForiInputCurCol = 1 To cntInputCols arRes(iInputCurRow, iInputCurCol) = regex.Test(input_range.Cells(iInputCurRow, iInputCurCol).Value) Next Next RegExpMatch = arRes Exit Function ErrHandl: RegExpMatch = CVErr(xlErrValue) End FunctionVložte kód do editoru VBA a nový kód RegExpMatch Pokud nemáte s VBA velké zkušenosti, může vám pomoci tento návod: Jak vložit kód VBA do aplikace Excel.
Poznámka: Po vložení kódu nezapomeňte soubor uložit jako sešit s povolenými makry (.xlsm).
Syntaxe RegExpMatch
Na stránkách RegExpMatch Funkce kontroluje, zda některá část zdrojového řetězce odpovídá regulárnímu výrazu. Výsledkem je logická hodnota: TRUE, pokud byla nalezena alespoň jedna shoda, FALSE v opačném případě.
Naše vlastní funkce má 3 argumenty - první dva jsou povinné a poslední je nepovinný:
RegExpMatch(text, vzor, [match_case])Kde:
- Text (povinné) - jeden nebo více řetězců, ve kterých se má hledat. Lze zadat jako odkaz na buňku nebo rozsah.
- Vzor (povinné) - regulární výraz, který se má porovnat. Pokud je vzor umístěn přímo ve vzorci, musí být uzavřen do dvojitých uvozovek.
- Match_case (nepovinné) - určuje typ přiřazování. Pokud je parametr TRUE nebo je vynechán (výchozí), přiřazování rozlišuje velká a malá písmena; pokud je parametr FALSE - nerozlišuje velká a malá písmena.
Funkce funguje ve všech verzích aplikací Excel 365, Excel 2021, Excel 2019, Excel 2016, Excel 2013 a Excel 2010.
3 věci, které byste měli vědět o RegExpMatch
Než přejdeme k praktickým výpočtům, věnujte prosím pozornost následujícím bodům, které objasňují některé technické záležitosti:
- Funkce může zpracovat jednotlivé buňky nebo rozsah buněk V druhém případě jsou výsledky vráceny v sousedních buňkách ve formě dynamického pole nebo rozsahu rozlití, jak je znázorněno v tomto příkladu.
- Ve výchozím nastavení je funkce rozlišování velkých a malých písmen Chcete-li ignorovat velikost písmen textu, nastavte match_case argumentu na FALSE. Z důvodu omezení VBA Regexp není podporován vzor (?i), který nerozlišuje velká a malá písmena.
- Pokud není nalezen platný vzor, funkce vrátí hodnotu FALSE; pokud je vzor vzor je neplatný , dojde k chybě #VALUE!.
Níže najdete několik příkladů shody regexů, které byly vytvořeny pro demonstrační účely. Nemůžeme zaručit, že naše vzory budou bezchybně fungovat s širším rozsahem vstupních dat ve vašich skutečných pracovních listech. Před nasazením do výroby nezapomeňte naše ukázkové vzory otestovat a upravit podle svých potřeb.
Jak používat regex k porovnávání řetězců v aplikaci Excel
Pokud mají všechny řetězce, které chcete porovnat, stejný vzor, jsou regulární výrazy ideálním řešením.
Předpokládejme, že máte rozsah buněk (A5:A9) obsahující různé údaje o některých položkách. Chcete zjistit, které buňky obsahují SKU. Za předpokladu, že každý SKU se skládá ze 2 velkých písmen, pomlčky a 3 číslic, můžete je porovnat pomocí následujícího výrazu.
Vzor : \b[A-Z]{2}-\d{3}\b
Kde [A-Z]{2} znamená jakákoli 2 velká písmena od A do Z a \d{3} znamená jakékoli 3 číslice od 0 do 9. Znak \b označuje hranici slova, což znamená, že SKU je samostatné slovo, a ne součást většího řetězce, jako je 23-MAR-2022.
Po vytvoření vzoru můžeme přejít k psaní vzorce. Použití vlastní funkce se v podstatě neliší od nativního vzorce. Jakmile začnete vzorec psát, název funkce se objeví v seznamu navrženém automatickým dokončováním aplikace Excel. V aplikaci Excel s dynamickým polem (Microsoft 365 a Excel 2021) a v tradičním Excelu (2019 a starší verze) však existuje několik nuancí.
Shoda řetězce v jedné buňce
Chcete-li porovnat řetězec v jedné buňce, odkažte se na tuto buňku v prvním argumentu. Druhý argument má obsahovat regulární výraz.
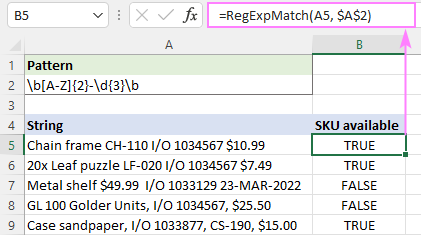
=RegExpMatch(A5, "\b[A-Z]{2}-\d{3}\b")
Vzor lze také uchovávat v předdefinované buňce, která je uzamčena absolutním odkazem ($A$2):
=RegExpMatch(A5, $A$2)
Po zadání vzorce do první buňky jej můžete přetáhnout do všech ostatních řádků.
Tato metoda skvěle funguje v všechny verze aplikace Excel .
Shoda řetězců ve více buňkách najednou
Chcete-li jedním vzorcem porovnat více řetězců, uveďte v prvním argumentu odkaz na rozsah:
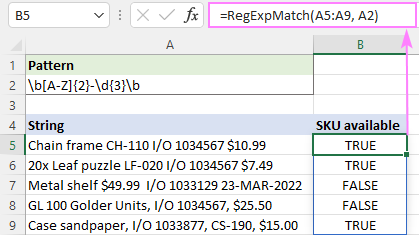
=RegExpMatch(A5:A9, "\b[A-Z]{2}-\d{3}\b")
Na adrese Excel 365 a Excel 2021 které podporují dynamická pole, to funguje tak, že do první buňky zadáte vzorec, stisknete Enter , a vzorec se automaticky přelije do následujících buněk.
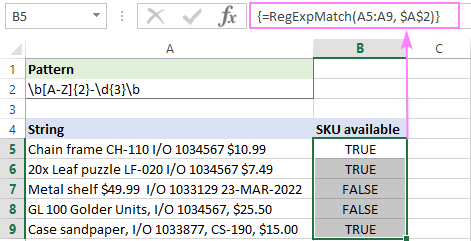
Na adrese Excel 2019 a dříve, funguje pouze jako tradiční vzorec pole CSE, který se zadává do rozsahu buněk a dokončí se stisknutím kláves Ctrl + Shift + Enter dohromady.
Regex pro přiřazení čísla
Chcete-li přiřadit libovolnou jednotlivou číslici od 0 do 9, použijte příkaz \d V závislosti na konkrétním úkolu přidejte vhodný kvantifikátor nebo vytvořte složitější vzor.
Regex pro shodu s libovolným číslem
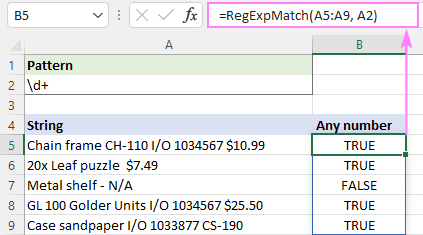
Chcete-li přiřadit libovolné číslo libovolné délky, vložte hned za znak /d kvantifikátor +, který říká, že se mají hledat čísla obsahující 1 nebo více číslic.
Vzor : \d+
=RegExpMatch(A5:A9, "\d+")
Regex pro přiřazení čísla určité délky
Pokud je vaším cílem porovnat číselné hodnoty obsahující určitý počet číslic, použijte \d spolu s příslušným kvantifikátorem.
Chcete-li například přiřadit čísla faktur, která se skládají přesně ze 7 číslic, použijte \d{7}. Mějte však na paměti, že přiřadí 7 číslic kdekoli v řetězci včetně 10místného nebo 100místného čísla. Pokud to není to, co hledáte, vložte na obě strany slovní ohraničení \b.
Vzor : \b\d{7}\b
=RegExpMatch(A5:A9, "\b\d{7}\b")
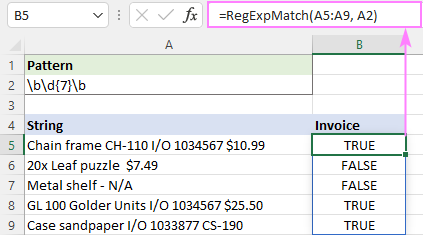
Regex pro porovnání telefonních čísel
Vzhledem k tomu, že telefonní čísla mohou být zapsána v různých formátech, vyžaduje jejich porovnání složitější regulární výraz.
V níže uvedeném souboru dat budeme hledat desetimístná čísla, která mají v prvních dvou skupinách 3 číslice a v poslední skupině 4 číslice. Skupiny mohou být odděleny tečkou, pomlčkou nebo mezerou. První skupina může, ale nemusí být uzavřena v závorkách.
Vzor: (\(\d{3}\)
Rozložením tohoto regulárního výrazu získáme následující výsledky:
- První část (\(\d{3}\)
- Část [-\.\s]? znamená 0 nebo 1 výskyt libovolného znaku v hranatých závorkách: pomlčky, tečky nebo bílého místa.
- Dále je zde ještě jedna skupina 3 číslic d{3} následovaná libovolnou pomlčkou, tečkou nebo bílým znakem [\-\.\s]?, které se vyskytují 0 nebo 1krát.
- Za poslední skupinou 4 číslic \d{4} následuje hranice slov \b, aby bylo jasné, že telefonní číslo nemůže být součástí většího čísla.
S původním řetězcem v A5 a regulárním výrazem v A2 má vzorec tento tvar:
=RegExpMatch(A5, $A$2)
... a funguje přesně podle očekávání:
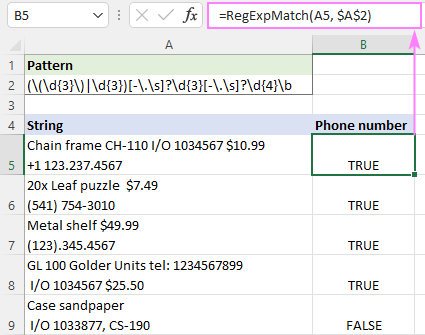
Poznámky:
- Mezinárodní kódy nejsou kontrolovány, takže mohou, ale nemusí být přítomny.
- V regulárních výrazech \s znamená jakýkoli bílý znak, například mezeru, tabulátor, návrat vozíku nebo nový řádek. Chcete-li povolit pouze mezery, použijte [-\. ] místo [-\.\s].
- [^13] bude odpovídat jakémukoli jednotlivému znaku, který není 1 nebo 3.
- [^1-3] odpovídá jakémukoli jednotlivému znaku, který není 1, 2 nebo 3 (tj. jakákoli číslice od 1 do 3).
- Výše uvedený regex funguje pouze pro jednořádkový V případě víceřádkových řetězců znaky ^ a $ odpovídají začátku a konci každého řádku namísto začátku a konce vstupního řetězce, proto regex hledá pouze v prvním řádku.
- Shoda řetězců, které nezačínejte s určitým textem , použijte regulární výraz, například ^(?!citrony).*$.
- Shoda řetězců, které neskončete s určitým textem , zahrňte do vyhledávacího vzoru kotvu koncového řetězce: ^((?!citrony$).)*$
- Uživatelské jméno může obsahovat písmena, číslice, podtržítka, tečky a pomlčky. Vzhledem k tomu, že \w odpovídá jakémukoli písmenu, číslici nebo podtržítku, dostaneme následující regex: [\w\.\-]+
- Název domény mohou obsahovat velká a malá písmena, číslice, pomlčky (ale ne na první nebo poslední pozici) a tečky (v případě subdomén). Protože podtržítka nejsou povolena, místo \w používáme 3 různé znakové sady: [A-Za-z0-9]+[A-Za-z0-9\.\-]*[A-Za-z0-9]+.
- Doména nejvyšší úrovně skládá se z tečky následované velkými a malými písmeny. Může obsahovat 2 až 24 písmen (nejdelší v současnosti existující TLD): \.[A-Za-z]{2,24}
- Zadejte odkaz na rozsah RegExpMatch, aby vrátil pole hodnot TRUE a FALSE.
- Pomocí dvojité negace (--) se logické hodnoty změní na jedničky a nuly.
- Získejte funkci SUMA, která sečte jedničky a nuly ve výsledném poli.
- Na Data Ablebits na kartě Text klikněte na tlačítko Nástroje Regex .
- Na Nástroje Regex proveďte následující kroky:
- Vyberte zdrojové řetězce.
- Zadejte svůj vzor.
- Vyberte si Zápas možnost.
- Chcete-li výsledky zobrazit jako vzorce, nikoli jako hodnoty, vyberte možnost Vložit jako vzorec zaškrtávacího políčka.
- Klikněte na Zápas tlačítko.
- Funkce může být vložené stránky přímo v buňce prostřednictvím standardu Vložit funkci dialogové okno, kde je zařazen do kategorie AblebitsUDFs .
- Ve výchozím nastavení je regulární výraz přidán do vzorce, ale můžete jej také ponechat v samostatné buňce. K tomu stačí použít odkaz na buňku jako 2. argument.
- Ve výchozím nastavení je funkce rozlišování velkých a malých písmen . Pro porovnávání bez rozlišení velkých a malých písmen použijte vzor (?i).
Regex, který NEodpovídá znaku
Chcete-li najít řetězce, které NEobsahují určitý znak, můžete použít třídy negovaných znaků [^ ], které odpovídají všemu, co NENÍ v závorkách. Například:
Předpokládejme, že v seznamu telefonních čísel chcete najít ta, která neobsahují kód země. Vzhledem k tomu, že každý mezinárodní kód obsahuje znak +, můžete k vyhledání řetězců, které neobsahují znak plus, použít třídu znaků [^\+]. Je důležité si uvědomit, že výše uvedený výraz odpovídá jakémukoli jednotlivému znaku, který není +. Protože telefonní číslo může být kdekoli v řetězci, nikoli v řetězci.nutně na samém začátku, je přidán kvantifikátor *, který kontroluje každý následující znak. Kotvy na začátku ^ a na konci $ zajišťují, že je zpracován celý řetězec. Výsledkem je níže uvedený regulární výraz, který říká "neshodujte se znakem + na žádné pozici v řetězci".
Vzor : ^[^\+]*$
=RegExpMatch(A5, "^[^\+]*$")
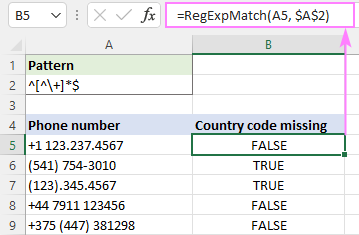
Regex, který NEodpovídá řetězci
Ačkoli neexistuje žádná speciální syntaxe regulárního výrazu pro neshodu s určitým řetězcem, můžete toto chování napodobit použitím záporného lookaheadu.
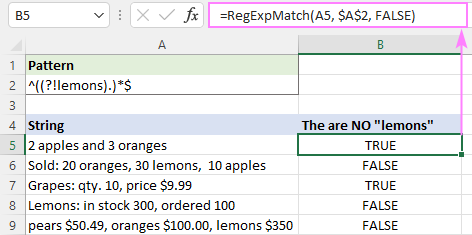
Předpokládejme, že chcete najít řetězce, které neobsahují slovo "citrony". Tento regulární výraz bude fungovat skvěle:
Vzor : ^(((?!citrony).)*$
Je zřejmé, že je zde potřeba trochu vysvětlení. Záporný lookahead (?!citrony) se podívá doprava, zda před sebou nemá slovo "citrony". Pokud tam "citrony" není, pak tečka odpovídá jakémukoli znaku kromě zalomení řádku. Výše uvedený výraz provádí pouze jednu kontrolu a kvantifikátor * ji opakuje nulakrát nebo vícekrát, od začátku řetězce ukotveného pomocí ^ do konce řetězce ukotveného pomocí$.
Abychom ignorovali velikost písmen v textu, nastavíme 3. argument na FALSE, aby naše funkce nerozlišovala velikost písmen:
=RegExpMatch(A5, $A$2, FALSE)
Tipy a poznámky:
Porovnávání bez rozlišení velkých a malých písmen
V klasických regulárních výrazech existuje speciální vzor pro porovnávání bez rozlišení velkých a malých písmen (?i), který není ve VBA RegExp podporován. Abychom toto omezení překonali, přijímá naše vlastní funkce 3. nepovinný argument s názvem match_case . Chcete-li provést porovnávání bez rozlišení velkých a malých písmen, stačí nastavit hodnotu FALSE.
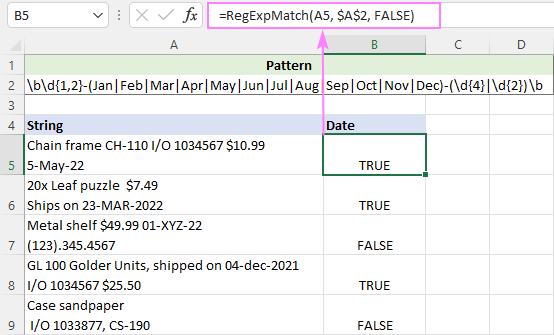
Řekněme, že si přejete identifikovat data, jako je 1.3.22 nebo 01.3.2022. Chcete-li přiřadit k datu dd-mmm-rrrr a d-mmm-yy formáty, používáme následující regulární výraz.
Vzor : \b\d{1,2}-(Jan
Náš výraz hledá skupinu 1 nebo 2 číslic, za nimiž následuje pomlčka, následovaná některou ze zkratek měsíce oddělenou znakem
Proč nepoužijete jednodušší vzor, například \d{1,2}-[A-Za-z]{3}-\d{2,4}\b? Abyste předešli falešně pozitivním shodám, například 01-ABC-2020.
Zadejte vzor do pole A2 a získáte následující vzorec:
=RegExpMatch(A5, $A$2, FALSE)
Regex pro porovnání platných e-mailových adres
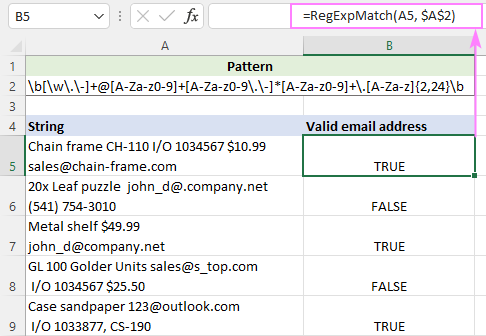
Jak je obecně známo, e-mailová adresa se skládá ze 4 částí: uživatelského jména, symbolu @, názvu domény (poštovního serveru) a domény nejvyšší úrovně (např. .com, .edu, .org atd.). Pro kontrolu platnosti e-mailové adresy budeme muset výše uvedenou strukturu replikovat pomocí regulárních výrazů.
Vzor : \b[\w\.\-]+@[A-Za-z0-9]+[A-Za-z0-9\.\-]*[A-Za-z0-9]+\.[A-Za-z]{2,24}\b
Abychom lépe pochopili, o co se jedná, podívejme se blíže na jednotlivé části:
Poznámka: Vzor předpokládá, že název domény obsahuje 2 nebo více alfanumerických znaků.
S původním textem ve formátu A5 a vzorem ve formátu A5 má vzorec tento tvar:
=RegExpMatch(A5, $A$2)
Nebo můžete pro ověření e-mailu použít jednodušší regulární výraz se sadou malých nebo velkých písmen:
Vzor : \b[\w\.\-]+@[a-z0-9]+[a-z0-9\.\-]*[a-z0-9]+\.[a-z]{2,24}\b
Ve vzorci však nerozlišujte velká a malá písmena:
=RegExpMatch(A5, $A$2, FALSE)
Vzorec IF aplikace Excel se shodou regex
Vzhledem k tomu, že vestavěné a vlastní funkce spolu dobře spolupracují, nic vám nebrání použít je společně v jednom vzorci.
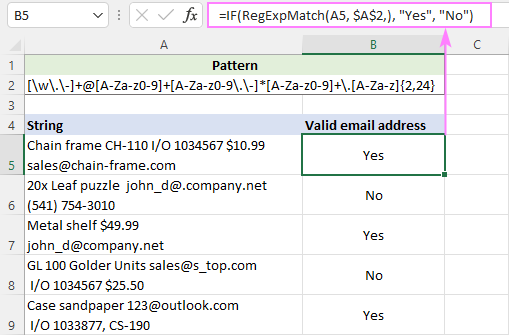
Chcete-li něco vrátit nebo vypočítat, pokud je regulární výraz splněn, a něco jiného, pokud splněn není, vložte vlastní funkci RegExpMatch do logického textu IF:
IF(RegExpMatch(...), [value_if_true], [value_if_false])Například pokud řetězec v poli A5 obsahuje platnou e-mailovou adresu, můžete vrátit hodnotu "Ano"; v opačném případě hodnotu "Ne".
=IF(RegExpMatch(A5, $A$2,), "Ano", "Ne")
Počítat, zda je regex splněn
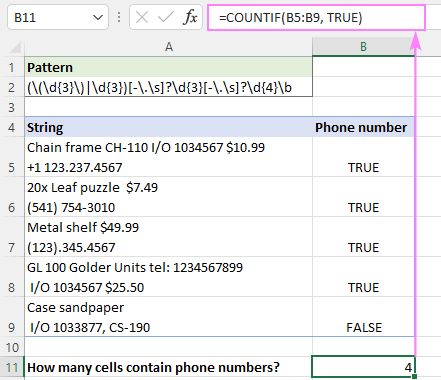
Protože nativní funkce aplikace Excel nepodporují regulární výrazy, není možné vložit regex přímo do funkce COUNTIS nebo COUNTIFS. Naštěstí můžete tuto funkci napodobit pomocí naší vlastní funkce.
Předpokládejme, že jste použili regex pro porovnání telefonních čísel a výsledky jste vypsali do sloupce B. Chcete-li zjistit, kolik buněk obsahuje telefonní čísla, stačí spočítat hodnoty TRUE v B5:B9. A to lze snadno provést pomocí standardního vzorce COUNTIF:
=COUNTIF(B5:B9, TRUE)
Nechcete mít v pracovním listu žádné další sloupce? Žádný problém. Vzhledem k tomu, že naše vlastní funkce dokáže zpracovat více buněk najednou a funkce SUM aplikace Excel dokáže sečíst hodnoty v poli, postupujte takto:
=SUM(--RegExpMatch(A5:A9, $A$2))
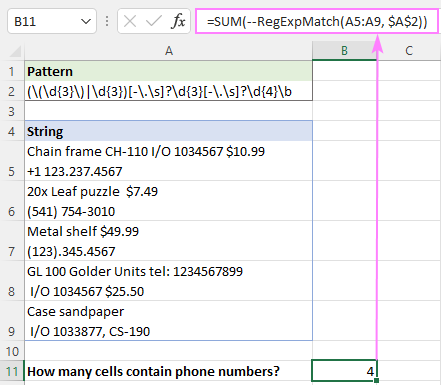
Párování regexů pomocí sady Ultimate Suite
Uživatelé naší sady Ultimate Suite mohou využívat čtyři výkonné funkce Regex, aniž by museli do svých sešitů přidávat kód VBA, protože jsou do aplikace Excel hladce integrovány během instalace doplňku. Naše vlastní funkce jsou zpracovávány standardním enginem RegEx v síti .NET a podporují plně funkční klasické regulární výrazy.
Jak používat vlastní funkci RegexMatch
Za předpokladu, že máte nainstalovanou nejnovější verzi sady Ultimate Suite (2021.4 nebo novější), můžete vzorec Regex Match vytvořit ve dvou jednoduchých krocích:
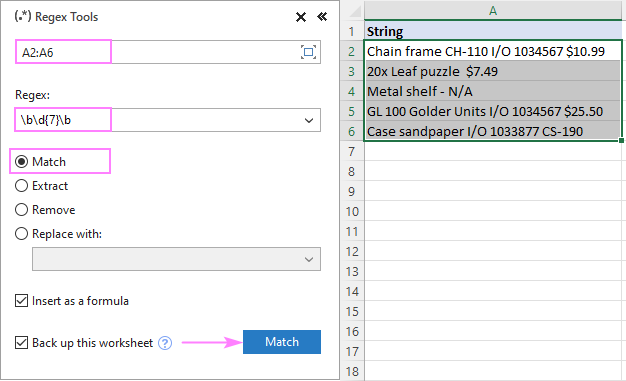
O chvíli později se AblebitsRegexMatch se vloží do nového sloupce napravo od vašich dat.
Na obrázku níže funkce kontroluje, zda řetězce ve sloupci A obsahují sedmimístná čísla, nebo ne.

Tipy:
Další informace naleznete v části Funkce AblebitsRegexMatch.
To je návod, jak provádět porovnávání regulárních výrazů v Excelu. Děkuji vám za přečtení a těším se na vás na našem blogu příští týden!
Dostupné soubory ke stažení
Příklady shody regexů aplikace Excel (.xlsm soubor)
Ultimate Suite 14denní plně funkční verze (.exe soubor)
