
Obsah
Nikdy jste nepochopili, proč regulární výrazy nejsou ve vzorcích Excelu podporovány? Nyní jsou :) Pomocí našich vlastních funkcí můžete snadno vyhledávat, nahrazovat, extrahovat a odstraňovat řetězce odpovídající určitému vzoru.
Na první pohled má Excel vše, co byste mohli potřebovat pro práci s textovými řetězci. Hmm... a co regulární výrazy? Jejda, v Excelu nejsou žádné vestavěné funkce Regex. Ale nikdo neříká, že si nemůžeme vytvořit vlastní :)
Co je regulární výraz?
Regulární výraz (také známý jako regex nebo regexp ) je speciálně zakódovaná posloupnost znaků, která definuje vyhledávací vzor. Pomocí tohoto vzoru můžete najít odpovídající kombinaci znaků v řetězci nebo ověřit vstupní data. Pokud znáte zápis zástupných znaků, můžete si regexy představit jako pokročilou verzi zástupných znaků.
Regulární výrazy mají vlastní syntaxi, která se skládá ze speciálních znaků, operátorů a konstrukcí. Například [0-5] odpovídá libovolné číslici od 0 do 5.
Regulární výrazy se používají v mnoha programovacích jazycích včetně JavaScriptu a VBA. Ten má speciální objekt RegExp, který využijeme k vytvoření našich vlastních funkcí.
Podporuje Excel regex?
V aplikaci Excel bohužel nejsou žádné vestavěné funkce Regex. Chcete-li ve vzorcích používat regulární výrazy, musíte si vytvořit vlastní uživatelsky definovanou funkci (založenou na VBA nebo .NET) nebo nainstalovat nástroje třetích stran podporující regexy.
Tahák Excelu Regex
Ať už je vzor regexu velmi jednoduchý nebo extrémně složitý, je vytvořen pomocí běžné syntaxe. Tento návod si neklade za cíl naučit vás regulární výrazy. K tomu existuje spousta zdrojů na internetu, od bezplatných návodů pro začátečníky až po prémiové kurzy pro pokročilé uživatele.
Níže uvádíme stručný přehled hlavních vzorů RegEx, který vám pomůže zorientovat se v jejich základech. Může vám také posloužit jako tahák při studiu dalších příkladů.
Pokud jste s regulárními výrazy dobře obeznámeni, můžete rovnou přejít k funkcím RegExp.
Postavy
Jedná se o nejčastěji používané vzory, které odpovídají určitým znakům.
| Vzor | Popis | Příklad | Zápasy |
| . | Zástupný znak: odpovídá jakémukoli jednotlivému znaku kromě zalomení řádku. | .ot | tečka , hot , hrnec , @ot |
| \d | Znak číslice: jakákoli jedna číslice od 0 do 9 | \d | Na adrese a1b , zápasy 1 |
| \D | Jakýkoli znak, který NENÍ číslice | \D | Na adrese a1b , zápasy a a b |
| \s | Mezerové znaky: mezera, tabulátor, nový řádek a návrat vozíku | .\s. | Na adrese 3 centy , zápasy 3 c |
| \S | Jakýkoli jiný znak než bílý znak | \S+ | Na adrese 30 centů , zápasy 30 a centů |
| \w | Slovní znak: libovolné písmeno ASCII, číslice nebo podtržítko. | \w+ | Na adrese 5_cats*** , zápasy 5_cats |
| \W | Jakýkoli znak, který NENÍ alfanumerický znak nebo podtržítko. | \W+ | Na adrese 5_cats*** , zápasy *** |
| \t | Karta | ||
| \n | Nová linie | \n\d+ | V níže uvedeném dvouřádkovém řetězci odpovídá 10 5 koček 10 psů |
| \ | uniká speciální význam znaku, takže jej můžete vyhledat. | \. \w+\. | Uteče tečka, abyste mohli v řetězci najít doslovný znak ".". Pan. , Paní , Prof. |
Třídy postav
Pomocí těchto vzorů můžete přiřazovat prvky různých znakových sad.
| Vzor | Popis | Příklad | Zápasy |
| [postavy] | Shoduje se s libovolným jednotlivým znakem v závorce | d[oi]g | pes a dig |
| [^znaků] | Shoduje se s libovolným jednotlivým znakem, který není v závorce. | d[^oi]g | Zápasy dag, dug , d1g Neodpovídá pes a dig |
| [od-do] | Shoduje se s libovolným znakem v rozsahu mezi závorkami. | [0-9] [a-z] [A-Z] | Jakákoli jedna číslice od 0 do 9 Jakékoli jedno malé písmeno Jakékoli jedno velké písmeno |
Kvantifikátory
Kvantifikátory jsou speciální výrazy, které určují počet znaků, které mají být porovnány. Kvantifikátor se vždy vztahuje na znak, který je před ním.
| Vzor | Popis | Příklad | Zápasy |
| * | Nula nebo více výskytů | 1a* | 1, 1a , 1aa, 1aaa , atd. |
| + | Jeden nebo více výskytů | po+ | Na adrese hrnec , zápasy po Na adrese chudák , zápasy hovínka |
| ? | Nula nebo jeden výskyt | roa?d | silnice, tyč |
| *? | Nula nebo více výskytů, ale co nejméně. | 1a*? | Na adrese 1a , 1aa a 1aaa , zápasy 1a |
| +? | Jeden nebo více výskytů, ale co nejméně. | po+? | Na adrese hrnec a chudák , zápasy po |
| ?? | Nula nebo jeden výskyt, ale co nejméně. | roa?? | Na adrese silnice a rod , zápasy ro |
| {n} | Shoduje se s předchozím vzorem n-krát | \d{3} | Přesně 3 číslice |
| {n,} | Shoduje se s předchozím vzorem n nebo vícekrát. | \d{3,} | 3 nebo více číslic |
| {n,m} | Shoduje se s předchozím vzorem n až mkrát. | \d{3,5} | 3 až 5 číslic |
Seskupení
Konstrukce pro seskupování slouží k zachycení podřetězce ze zdrojového řetězce, aby s ním bylo možné provést nějakou operaci.
| Syntaxe | Popis | Příklad | Zápasy |
| (vzor) | Zachycení skupiny: zachytí odpovídající podřetězec a přiřadí mu pořadové číslo. | (\d+) | Na adrese 5 koček a 10 psů , zachycuje 5 (skupina 1) a 10 (skupina 2) |
| (?:vzor) | Nezachycující skupina: odpovídá skupině, ale nezachycuje ji. | (\d+)(?: psi) | Na adrese 5 koček a 10 psů , zachycuje 10 |
| \1 | Obsah skupiny 1 | (\d+)\+(\d+)=\2\+\1 | Shoduje se 5+10=10+5 a zachycuje 5 a 10 , které jsou v záchytných skupinách |
| \2 | Obsah skupiny 2 |
Kotvy
Kotvy určují pozici ve vstupním řetězci, kde se má hledat shoda.
| Kotva | Popis | Příklad | Zápasy |
| ^ | Začátek řetězce Poznámka: [^vnitř závorek] znamená "ne". | ^\d+ | Libovolný počet číslic na začátku řetězce. Na adrese 5 koček a 10 psů , zápasy 5 |
| $ | Konec řetězce | \d+$ | Libovolný počet číslic na konci řetězce. Na adrese 10 plus 5 dává 15 , zápasy 15 |
| \b | Hranice slov | \bjoy\b | Zápasy joy jako samostatné slovo, ale ne v příjemné . |
| \B | NE hranice slov | \Bjoy\B | Zápasy joy na adrese příjemné , ale ne jako samostatné slovo. |
Konstrukce střídání (OR)
Střídavý operand umožňuje logiku OR, takže můžete přiřadit buď tento, nebo tento prvek.
| Konstrukce | Popis | Příklad | Zápasy |
| Shoduje se s libovolným jednotlivým prvkem odděleným svislou čarou. | (s | Na adrese prodává mušle, odpovídá prodává a mušle |
Vyhledávání
Konstrukce typu Lookaround jsou užitečné, když chcete porovnat něco, co je nebo není následováno nebo předcházeno něčím jiným. Tyto výrazy se někdy nazývají "tvrzení s nulovou šířkou" nebo "shoda s nulovou šířkou", protože porovnávají pozici, nikoli skutečné znaky.
Poznámka: V příchuti VBA RegEx nejsou podporovány lookbehinds.
| Vzor | Popis | Příklad | Zápasy |
| (?=) | Pozitivní výhled | X(?=Y) | Shoduje se s výrazem X, pokud po něm následuje výraz Y (tj. pokud je výraz Y před výrazem X). |
| (?!) | Záporný lookahead | X(?!Y) | Odpovídá výrazu X, pokud po něm NENÍ uvedeno Y |
| (?<=) | Pozitivní ohlédnutí | (?<=Y)X | Shoduje se s výrazem X, pokud mu předchází výraz Y (tj. pokud je za výrazem X výraz Y). |
| (? )</td | Negativní pohled zezadu | (? Y)X</td | Shoduje se s výrazem X, pokud mu nepředchází výraz Y |
Nyní, když znáte základní informace, přejděme k tomu nejzajímavějšímu - použití regexů na reálných datech k analýze řetězců a vyhledání požadovaných informací. Pokud potřebujete více informací o syntaxi, může vám pomoci příručka společnosti Microsoft o jazyku regulárních výrazů.
Vlastní funkce RegEx pro aplikaci Excel
Jak již bylo zmíněno, Microsoft Excel nemá žádné vestavěné funkce RegEx. Abychom regulární výrazy umožnili, vytvořili jsme tři vlastní funkce VBA (tzv. uživatelsky definované funkce). Kódy můžete zkopírovat z níže uvedených odkazovaných stránek nebo z našeho ukázkového sešitu a poté je vložit do vlastních souborů Excelu.
Jak fungují funkce VBA RegExp
Tato část vysvětluje vnitřní mechaniku a může být zajímavá pro ty, kteří chtějí vědět, co se přesně děje na zadní straně.
Chcete-li začít používat regulární výrazy ve VBA, musíte buď aktivovat knihovnu odkazů na objekty RegEx, nebo použít funkci CreateObject. Abychom vám ušetřili práci s nastavováním odkazu v editoru VBA, zvolili jsme druhý přístup.
Objekt RegExp má 4 vlastnosti:
- Vzor - je vzor k porovnání ve vstupním řetězci.
- Globální - určuje, zda se mají najít všechny shody ve vstupním řetězci, nebo jen první z nich. V našich funkcích je nastavena na hodnotu True, aby se získala hodnota všechny zápasy .
- MultiLine - určuje, zda se má vzor hledat přes zlomy řádků ve víceřádkových řetězcích, nebo pouze v prvním řádku. V našich kódech je nastavena na hodnotu True, aby se hledalo v v každém řádku .
- IgnoreCase - určuje, zda regulární výraz rozlišuje velká a malá písmena (výchozí) nebo nerozlišuje velká a malá písmena (nastaveno na True). V našem případě to závisí na tom, jak nakonfigurujete nepovinný příkaz match_case Ve výchozím nastavení jsou všechny funkce rozlišování velkých a malých písmen .
Omezení VBA RegExp
Excel VBA implementuje základní regexové vzory, ale postrádá mnoho pokročilých funkcí, které jsou k dispozici v jazycích .NET, Perl, Java a dalších regexových enginech. VBA RegExp například nepodporuje inline modifikátory, jako je (?i) pro porovnávání bez rozlišení velkých a malých písmen nebo (?m) pro víceřádkový režim, lookbehinds, POSIX třídy a další.
Funkce Excel Regex Match
Na stránkách RegExpMatch funkce vyhledá ve vstupním řetězci text, který odpovídá regulárnímu výrazu, a vrátí TRUE, pokud je nalezena shoda, jinak FALSE.
RegExpMatch(text, vzor, [match_case])Kde:
- Text (povinné) - jeden nebo více řetězců pro vyhledávání.
- Vzor (povinné) - regulární výraz, který se má porovnat.
- Match_case (nepovinné) - typ shody. TRUE nebo vynecháno - rozlišuje velká a malá písmena; FALSE - nerozlišuje velká a malá písmena.
Kód funkce je zde.
Příklad: použití regulárních výrazů pro porovnávání řetězců
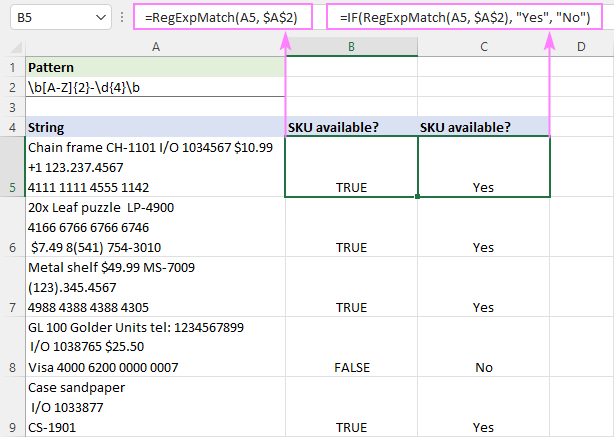
Předpokládejme, že v níže uvedeném souboru dat chcete identifikovat položky obsahující kódy SKU.
Vzhledem k tomu, že každá SKU začíná dvěma velkými písmeny, za nimiž následuje pomlčka a 4 číslice, můžete je porovnat pomocí následujícího výrazu.
Vzor : \b[A-Z]{2}-\d{4}\b
Kde [A-Z]{2} znamená jakákoli 2 velká písmena od A do Z a \d{4} znamená jakékoli 4 číslice od 0 do 9. Hranice slov \b označuje, že SKU je samostatné slovo a není součástí většího řetězce.
Po vytvoření vzoru začněte psát vzorec jako obvykle a název funkce se objeví v seznamu navrženém funkcí Automatické dokončování aplikace Excel:

Za předpokladu, že původní řetězec je ve formátu A5, je vzorec následující:
=RegExpMatch(A5, "\b[A-Z]{2}-\d{3}\b")
Pro větší pohodlí můžete regulární výraz zadat v samostatné buňce a použít absolutní odkaz ($A$2). vzor Tím zajistíte, že adresa buňky zůstane při kopírování vzorce do jiných buněk nezměněna:
=RegExpMatch(A5, $A$2)
Chcete-li zobrazit vlastní textové popisky namísto TRUE a FALSE, vnořte funkci RegExpMatch do funkce IF a zadejte požadované texty do pole. value_if_true a value_if_false argumenty:
=IF(RegExpMatch(A5, $A$2), "Ano", "Ne")
Další příklady vzorců naleznete na:
- Jak přiřazovat řetězce pomocí regulárních výrazů
- Ověřování dat aplikace Excel pomocí regexů
Funkce Excel Regex Extract
Na stránkách RegExpExtract vyhledá podřetězce, které odpovídají regulárnímu výrazu, a extrahuje všechny shody nebo konkrétní shodu.
RegExpExtract(text, pattern, [instance_num], [match_case])Kde:
- Text (povinné) - textový řetězec, ve kterém se má vyhledávat.
- Vzor (povinné) - regulární výraz, který se má porovnat.
- Instance_num (nepovinné) - pořadové číslo, které určuje, která instance se má extrahovat. Pokud je vynecháno, vrátí se všechny nalezené shody (výchozí).
- Match_case (nepovinné) - určuje, zda se mají porovnávat (TRUE nebo vynecháno) nebo ignorovat (FALSE) velká a malá písmena textu.
Kód funkce najdete zde.
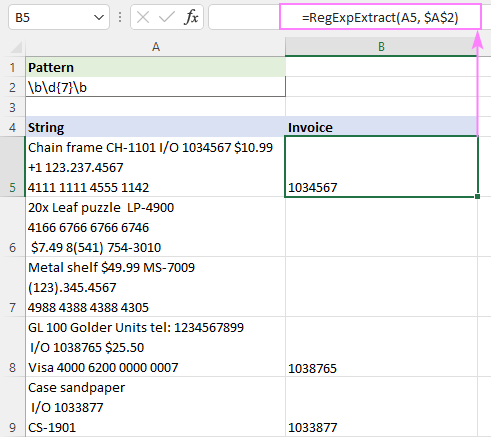
Příklad: jak extrahovat řetězce pomocí regulárních výrazů
Pokud náš příklad posuneme o něco dále, vybereme čísla faktur. K tomu použijeme velmi jednoduchý regex, který odpovídá libovolnému sedmimístnému číslu:
Vzor : \b\d{7}\b
Vložte vzor do formátu A2 a s tímto kompaktním a elegantním vzorníkem bude práce hotová:
=RegExpExtract(A5, $A$2)
Pokud je nalezen vzor, vzorec vyčte číslo faktury, pokud není nalezena shoda, není vráceno nic.
Další příklady naleznete v části: Jak extrahovat řetězce v aplikaci Excel pomocí regexu.
Funkce Excel Regex Replace
Na stránkách RegExpReplace nahradí hodnoty odpovídající regexu zadaným textem.
RegExpReplace(text, vzor, náhrada, [číslo_instance], [případ_zápasu])Kde:
- Text (povinné) - textový řetězec, ve kterém se má vyhledávat.
- Vzor (povinné) - regulární výraz, který se má porovnat.
- Náhrada (povinné) - text, kterým se nahradí odpovídající podřetězce.
- Instance_num (nepovinné) - instance, která se má nahradit. Výchozí hodnota je "všechny shody".
- Match_case (nepovinné) - určuje, zda se mají porovnávat (TRUE nebo vynecháno) nebo ignorovat (FALSE) velká a malá písmena textu.
Kód funkce je k dispozici zde.
Příklad: jak nahradit nebo odstranit řetězce pomocí regexů
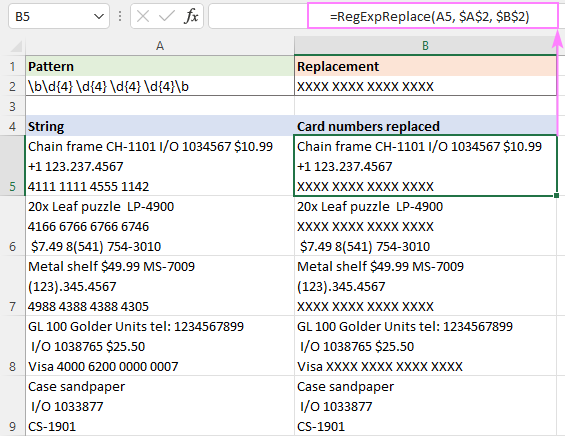
Některé z našich záznamů obsahují čísla kreditních karet. Tyto informace jsou důvěrné a možná je budete chtít něčím nahradit nebo úplně vymazat. Oba úkoly lze provést pomocí nástroje RegExpReplace Jak? V druhém případě budeme nahrazovat prázdný řetězec.
V naší ukázkové tabulce mají všechna čísla karet 16 číslic, které jsou zapsány ve 4 skupinách oddělených mezerami. Abychom je našli, zopakujeme vzor pomocí tohoto regulárního výrazu:
Vzor : \b\d{4} \d{4} \d{4} \d{4}\b
Pro nahrazení se používá následující řetězec:
Náhrada : XXXX XXXX XXXX XXXX XXXX
A zde je kompletní vzorec nahradit čísla kreditních karet s necitlivými informacemi:
=RegExpReplace(A5, "\b\d{4} \d{4} \d{4} \d{4}\b", "XXXX XXXX XXXX XXXX XXXX")
S regexem a náhradním textem v samostatných buňkách (A2 a B2) funguje vzorec stejně dobře:
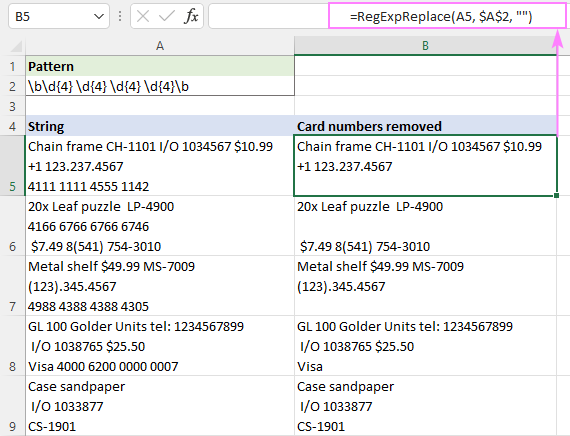
V aplikaci Excel je "odstranění" zvláštním případem "nahrazení". Chcete-li odstranit čísla kreditních karet, stačí použít prázdný řetězec ("") pro číslo kreditní karty. náhradní argument:
=RegExpReplace(A5, "\b\d{4} \d{4} \d{4} \d{4}\b", "")
Tip: Chcete-li se zbavit prázdných řádků ve výsledcích, můžete použít jinou funkci RegExpReplace, jak ukazuje tento příklad: Jak odstranit prázdné řádky pomocí regexu.
Další informace naleznete na:
- Jak nahradit řetězce v aplikaci Excel pomocí regexu
- Jak odstranit řetězce pomocí regexu
- Jak odstranit bílé znaky pomocí regexů
Nástroje Regex pro porovnávání, extrakci, nahrazování a odstraňování podřetězců
Uživatelé naší sady Ultimate Suite mohou využívat všechny možnosti regulárních výrazů, aniž by museli do sešitů vložit jediný řádek kódu. Veškerý potřebný kód je napsán našimi vývojáři a hladce integrován do aplikace Excel během instalace.
Na rozdíl od výše uvedených funkcí VBA jsou funkce sady Ultimate Suite založeny na technologii .NET, což přináší dvě hlavní výhody:
- Regulární výrazy můžete používat v běžných sešitech .xlsx, aniž byste museli přidávat kód VBA a ukládat je jako soubory s makry.
- Mechanismus .NET Regex podporuje plně funkční klasické regulární výrazy, které umožňují vytvářet složitější vzory.
Jak používat Regex v aplikaci Excel
S nainstalovanou sadou Ultimate Suite je použití regulárních výrazů v aplikaci Excel tak jednoduché jako tyto dva kroky:
- Na Data Ablebits na kartě Text klikněte na tlačítko Nástroje Regex .
- Na Nástroje Regex proveďte následující kroky:
- Vyberte zdrojová data.
- Zadejte svůj vzor regexu.
- Vyberte požadovanou možnost: Zápas , Výpis , Odstranění adresy nebo Vyměňte stránky .
- Chcete-li získat výsledek jako vzorec, a ne jako hodnotu, vyberte možnost Vložit jako vzorec zaškrtávacího políčka.
- Stiskněte tlačítko akce.
Chceme-li například odstranit čísla kreditních karet z buněk A2:A6, nakonfigurujeme tato nastavení:
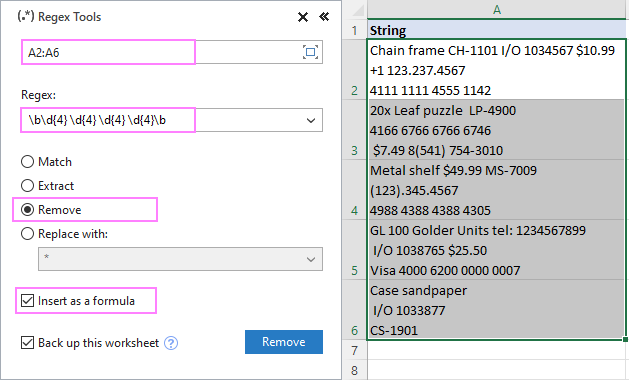
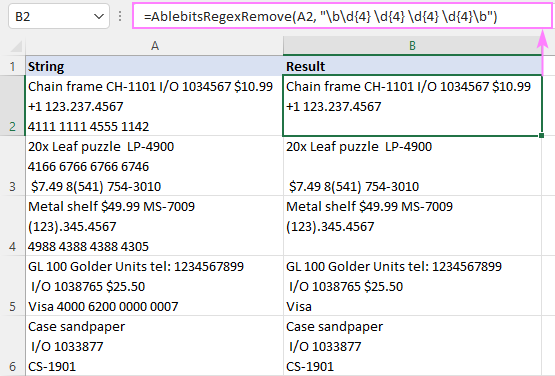
V okamžiku se funkce AblebitsRegex vloží do nového sloupce napravo od původních dat. V našem případě je vzorec následující:
=AblebitsRegexRemove(A2, "\b\d{4} \d{4} \d{4} \d{4}\b")
Jakmile je vzorec vytvořen, můžete jej upravovat, kopírovat nebo přesouvat jako jakýkoli jiný nativní vzorec.
Jak vložit vzorec Regex přímo do buňky
Funkce AblebitsRegex lze také vložit přímo do buňky bez použití rozhraní doplňku. Zde je uveden postup:
- Klikněte na fx na panelu vzorců nebo Vložit funkci na Vzorce tab.
- V Vložit funkci dialogového okna vyberte AblebitsUDFs vyberte funkci, která vás zajímá, a klikněte na tlačítko OK.
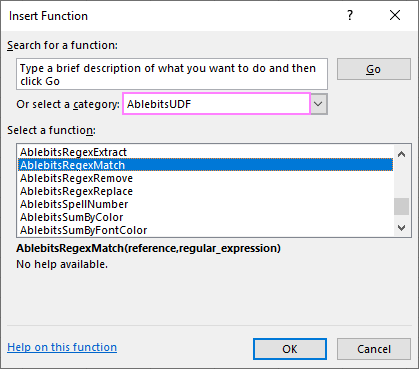
- Definujte argumenty funkce jako obvykle a klikněte na tlačítko OK. Hotovo!
Další informace naleznete v části Regex Tools for Excel.
To je návod, jak používat regulární výrazy k porovnávání, vyjímání, nahrazování a odstraňování textu v buňkách aplikace Excel. Děkuji vám za přečtení a těším se na vás na našem blogu příští týden!
Dostupné soubory ke stažení
Excel Regex - příklady vzorců (.xlsm soubor)
Ultimate Suite - zkušební verze (.exe soubor)
